


2024 ist das Jahr der rasanten Entwicklung großer Sprachmodelle (LLM). In der Ausbildung von LLM sind Alignment-Methoden ein wichtiges technisches Mittel, einschließlich Supervised Fine-Tuning (SFT) und Reinforcement Learning mit menschlichem Feedback, das auf menschlichen Präferenzen basiert (RLHF). Diese Methoden haben eine entscheidende Rolle bei der Entwicklung von LLM gespielt, aber Alignment-Methoden erfordern eine große Menge manuell annotierter Daten. Angesichts dieser Herausforderung ist die Feinabstimmung zu einem dynamischen Forschungsgebiet geworden, in dem Forscher aktiv an der Entwicklung von Methoden arbeiten, mit denen menschliche Daten effektiv genutzt werden können. Daher wird die Entwicklung von Ausrichtungsmethoden weitere Durchbrüche in der LLM-Technologie fördern.
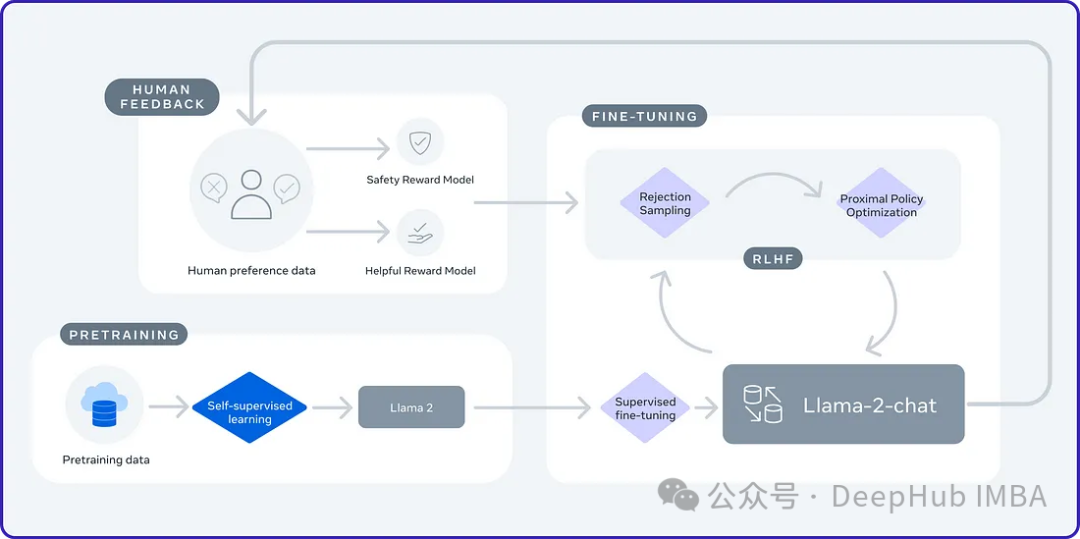
Die University of California hat kürzlich eine Studie durchgeführt und eine neue Technologie namens SPIN (Self Play Fine TuNing) eingeführt. SPIN greift auf erfolgreiche Selbstspielmechanismen in Spielen wie AlphaGo Zero und AlphaZero zurück, um LLM (Language Learning Model) die Teilnahme am Selbstspiel zu ermöglichen. Diese Technologie macht professionelle Annotatoren überflüssig, egal ob es sich um Menschen oder fortgeschrittenere Modelle (wie GPT-4) handelt. Der Trainingsprozess von SPIN umfasst das Trainieren eines neuen Sprachmodells und die Unterscheidung seiner eigenen generierten Antworten von menschengenerierten Antworten durch eine Reihe von Iterationen. Das ultimative Ziel besteht darin, ein Sprachmodell zu entwickeln, das Antworten generiert, die nicht von menschlichen Antworten zu unterscheiden sind. Der Zweck dieser Forschung besteht darin, die Selbstlernfähigkeit des Sprachmodells weiter zu verbessern und es dem menschlichen Ausdruck und Denken näher zu bringen. Die Ergebnisse dieser Forschung dürften neue Durchbrüche bei der Entwicklung der Verarbeitung natürlicher Sprache bringen.
Selbstspiel ist eine Lerntechnik, die die Herausforderung und Komplexität der Lernumgebung erhöht, indem sie gegen Kopien von sich selbst spielt. Dieser Ansatz ermöglicht es einem Agenten, mit verschiedenen Versionen seiner selbst zu interagieren und so seine Fähigkeiten zu verbessern. AlphaGo Zero ist ein gelungener Fall von Selbstspiel.

Selbstspiele haben sich als wirksame Methode beim Multi-Agent Reinforcement Learning (MARL) erwiesen. Die Anwendung auf die Erweiterung großer Sprachmodelle (LLMs) ist jedoch ein neuer Ansatz. Durch die Anwendung des Selbstspiels auf große Sprachmodelle kann ihre Fähigkeit, kohärenteren und informationsreicheren Text zu generieren, weiter verbessert werden. Von dieser Methode wird erwartet, dass sie die Weiterentwicklung und Verbesserung von Sprachmodellen vorantreibt.
Selbstspiel kann in kompetitiven oder kooperativen Umgebungen eingesetzt werden. Im Wettbewerb konkurrieren Kopien des Algorithmus miteinander, um ein Ziel zu erreichen; in der Zusammenarbeit arbeiten Kopien zusammen, um ein gemeinsames Ziel zu erreichen. Es kann mit überwachtem Lernen, verstärkendem Lernen und anderen Technologien kombiniert werden, um die Leistung zu verbessern.
SPIN ist wie ein Spiel für zwei Spieler. In diesem Spiel:
Die Rolle des Mastermodells (neues LLM) besteht darin, zu lernen, zwischen von einem Sprachmodell (LLM) generierten Antworten und von Menschen erstellten Antworten zu unterscheiden. In jeder Iteration trainiert das Mastermodell den LLM aktiv, um seine Fähigkeit zu verbessern, Reaktionen zu erkennen und zu unterscheiden.
Das Gegnermodell (altes LLM) hat die Aufgabe, Reaktionen zu erzeugen, die denen von Menschen ähneln. Es wird durch das LLM der vorherigen Iteration generiert, wobei ein Selbstspielmechanismus verwendet wird, um eine Ausgabe basierend auf früheren Erkenntnissen zu generieren. Das Ziel des Gegnermodells besteht darin, eine Reaktion zu erzeugen, die so realistisch ist, dass das neue LLM nicht sicher sein kann, dass sie maschinell generiert wurde.
Ist dieser Prozess nicht sehr ähnlich zu GAN, aber immer noch nicht derselbe?
Die Dynamik von SPIN beinhaltet die Verwendung eines überwachten Feinabstimmungsdatensatzes (SFT), der aus Eingabe (x) und Ausgabe (y) besteht ) Paare. Diese Beispiele werden von Menschen kommentiert und dienen als Grundlage für das Training des Hauptmodells zur Erkennung menschenähnlicher Reaktionen. Zu den öffentlichen SFT-Datensätzen gehören Dolly15K, Baize, Ultrachat usw.
Um das Hauptmodell darauf zu trainieren, zwischen Sprachmodellen (LLM) und menschlichen Antworten zu unterscheiden, verwendet SPIN eine objektive Funktion. Diese Funktion misst die erwartete Wertlücke zwischen den realen Daten und der vom Gegnermodell erzeugten Antwort. Das Ziel des Hauptmodells besteht darin, diese Erwartungswertlücke zu maximieren. Dazu gehört die Zuweisung hoher Werte zu Hinweisen, die mit Antworten aus realen Daten gepaart sind, und die Zuweisung niedriger Werte zu Antwortpaaren, die vom Gegnermodell generiert werden. Diese Zielfunktion wird als Minimierungsproblem formuliert.
Die Aufgabe des Mastermodells besteht darin, die Verlustfunktion zu minimieren, die die Differenz zwischen den paarweisen Zuweisungswerten aus den realen Daten und den paarweisen Zuweisungswerten aus den Antworten des Gegenmodells misst. Während des Trainingsprozesses passt das Mastermodell seine Parameter an, um diese Verlustfunktion zu minimieren. Dieser iterative Prozess wird fortgesetzt, bis das Mastermodell in der Lage ist, LLM-Antworten effektiv von menschlichen Antworten zu unterscheiden.
Die Aktualisierung des Gegnermodells beinhaltet die Verbesserung der Fähigkeit des Mastermodells, das während des Trainings gelernt hat, zwischen realen Daten und Antworten des Sprachmodells zu unterscheiden. Da sich das Master-Modell verbessert und sein Verständnis für bestimmte Funktionsklassen verbessert, müssen wir auch Parameter wie das Gegnermodell aktualisieren. Wenn der Meisterspieler mit denselben Aufforderungen konfrontiert wird, nutzt er sein erlerntes Unterscheidungsvermögen, um deren Wert einzuschätzen.
Das Ziel des gegnerischen Modellspielers besteht darin, das Sprachmodell so zu verbessern, dass seine Antworten nicht von den realen Daten des Meisterspielers zu unterscheiden sind. Dies erfordert die Einrichtung eines Prozesses zur Anpassung der Parameter des Sprachmodells. Das Ziel besteht darin, die Bewertung der Antwort des Sprachmodells durch das Mastermodell zu maximieren und gleichzeitig die Stabilität aufrechtzuerhalten. Dies erfordert einen Balanceakt, um sicherzustellen, dass Verbesserungen nicht zu weit vom ursprünglichen Sprachmodell abweichen.
Es klingt etwas verwirrend, fassen wir es kurz zusammen:
Es gibt nur ein Modell während des Trainings, aber das Modell ist in das Modell der vorherigen Runde (altes LLM/Gegnermodell) und das Hauptmodell (wird trainiert) unterteilt. Verwendung: Die Ausgabe des trainierten Modells wird mit der Ausgabe der vorherigen Modellrunde verglichen, um das Training des aktuellen Modells zu optimieren. Hier benötigen wir jedoch ein trainiertes Modell als Gegenmodell, sodass der SPIN-Algorithmus nur zur Feinabstimmung der Trainingsergebnisse geeignet ist.
SPIN generiert synthetische Daten aus vorab trainierten Modellen. Diese synthetischen Daten werden dann verwendet, um das Modell auf neue Aufgaben abzustimmen.

Das Obige ist der Pseudocode des Spin-Algorithmus im Originalpapier. Er scheint etwas schwierig zu verstehen, um seine Funktionsweise besser zu erklären.
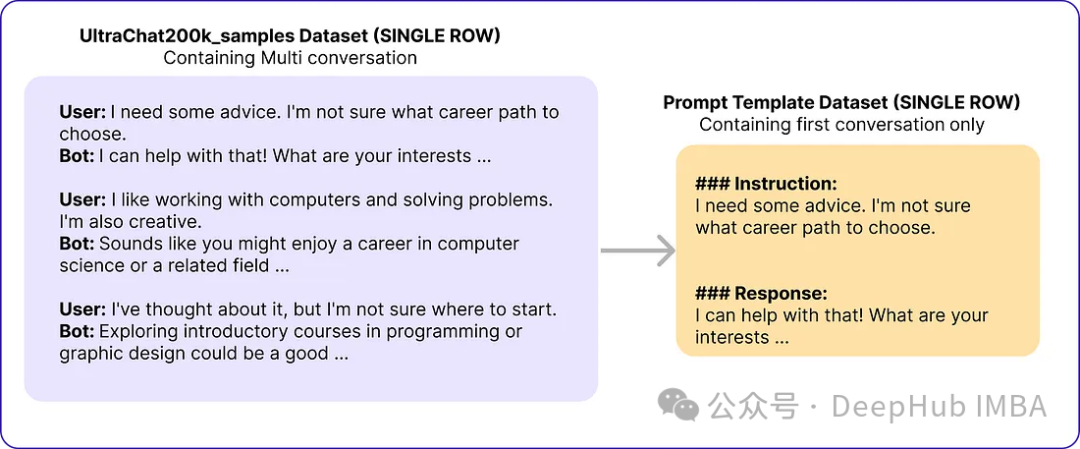
Das Originalpapier verwendet Zephyr-7B-SFT-Full als Basismodell. Für den Datensatz verwendeten sie eine Teilmenge des größeren Ultrachat200k-Korpus, der aus etwa 1,4 Millionen Konversationen besteht, die mit der Turbo-API von OpenAI generiert wurden. Sie haben zufällig 50.000 Hinweise ausgewählt und ein Basismodell verwendet, um synthetische Antworten zu generieren.
# Import necessary libraries from datasets import load_dataset import pandas as pd # Load the Ultrachat 200k dataset ultrachat_dataset = load_dataset("HuggingFaceH4/ultrachat_200k") # Initialize an empty DataFrame combined_df = pd.DataFrame() # Loop through all the keys in the Ultrachat dataset for key in ultrachat_dataset.keys():# Convert each dataset key to a pandas DataFrame and concatenate it with the existing DataFramecombined_df = pd.concat([combined_df, pd.DataFrame(ultrachat_dataset[key])]) # Shuffle the combined DataFrame and reset the index combined_df = combined_df.sample(frac=1, random_state=123).reset_index(drop=True) # Select the first 50,000 rows from the shuffled DataFrame ultrachat_50k_sample = combined_df.head(50000)Die Eingabeaufforderungsvorlage des Autors „### Anweisung: {prompt}nn### Antwort:“
# for storing each template in a list templates_data = [] for index, row in ultrachat_50k_sample.iterrows():messages = row['messages'] # Check if there are at least two messages (user and assistant)if len(messages) >= 2:user_message = messages[0]['content']assistant_message = messages[1]['content'] # Create the templateinstruction_response_template = f"### Instruction: {user_message}\n\n### Response: {assistant_message}" # Append the template to the listtemplates_data.append({'Template': instruction_response_template}) # Create a new DataFrame with the generated templates (ground truth) ground_truth_df = pd.DataFrame(templates_data)Dann haben wir Daten erhalten, die den folgenden ähneln:
Der SPIN-Algorithmus aktualisiert das Sprachmodell (LLM) um Iterationsparameter, um sie mit der Ground-Truth-Antwort konsistent zu halten. Dieser Prozess wird fortgesetzt, bis es schwierig ist, die generierte Antwort von der Grundwahrheit zu unterscheiden, wodurch ein hohes Maß an Ähnlichkeit (geringerer Verlust) erreicht wird.
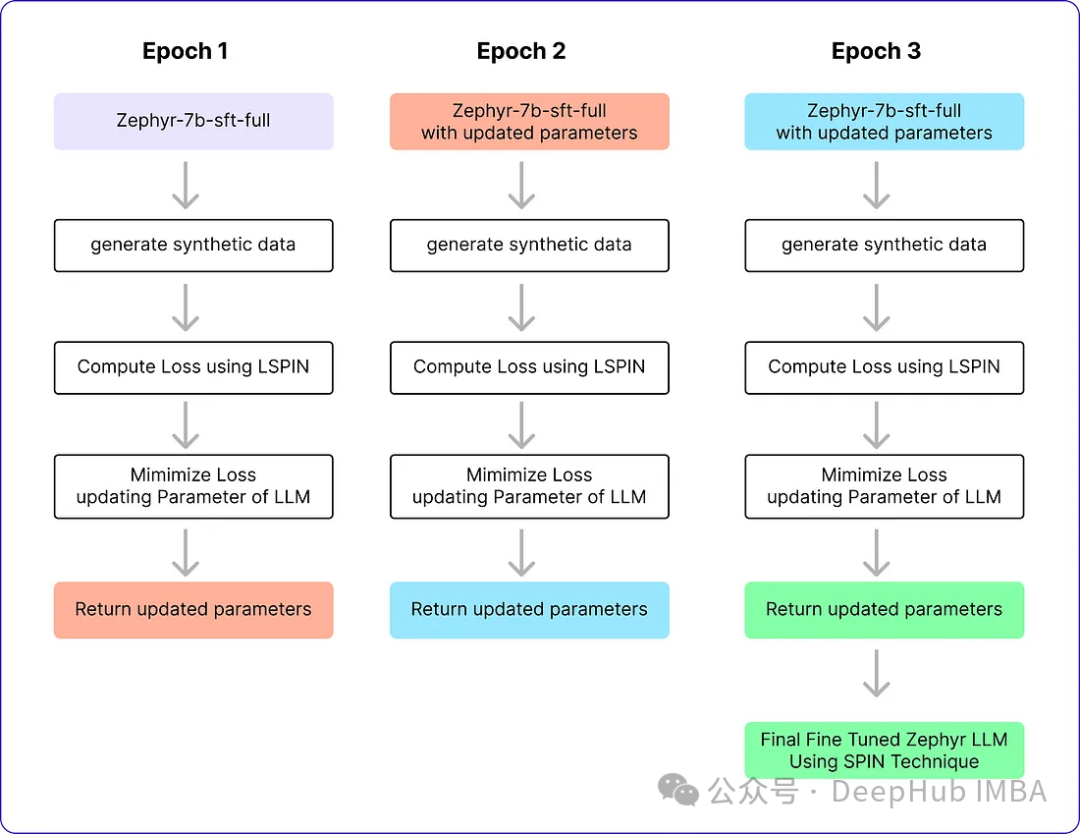
Der SPIN-Algorithmus hat zwei Schleifen. Die innere Schleife wurde basierend auf der Anzahl der von uns verwendeten Proben ausgeführt, und die äußere Schleife wurde insgesamt drei Iterationen lang ausgeführt, da die Autoren feststellten, dass sich die Leistung des Modells danach nicht änderte. Die Alignment Handbook-Bibliothek wird als Codebibliothek für die Feinabstimmungsmethode verwendet und in Kombination mit dem DeepSpeed-Modul werden die Schulungskosten reduziert. Sie trainierten Zephyr-7B-SFT-Full mit dem RMSProp-Optimierer, ohne Gewichtsabfall für alle Iterationen, wie er normalerweise zur Feinabstimmung von llm verwendet wird. Die globale Batchgröße ist auf 64 festgelegt, wobei die Genauigkeit von bfloat16 verwendet wird. Die maximale Lernrate für die Iterationen 0 und 1 ist auf 5e-7 festgelegt, und die maximale Lernrate für die Iterationen 2 und 3 sinkt auf 1e-7, wenn sich die Schleife dem Ende der Selbstspiel-Feinabstimmung nähert. Schließlich wird β = 0,1 gewählt und die maximale Sequenzlänge auf 2048 Token festgelegt. Im Folgenden sind diese Parameter aufgeführt
# Importing the PyTorch library import torch # Importing the neural network module from PyTorch import torch.nn as nn # Importing the DeepSpeed library for distributed training import deepspeed # Importing the AutoTokenizer and AutoModelForCausalLM classes from the transformers library from transformers import AutoTokenizer, AutoModelForCausalLM # Loading the zephyr-7b-sft-full model from HuggingFace tokenizer = AutoTokenizer.from_pretrained("alignment-handbook/zephyr-7b-sft-full") model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Initializing DeepSpeed Zero with specific configuration settings deepspeed_config = deepspeed.config.Config(train_batch_size=64, train_micro_batch_size_per_gpu=4) model, optimizer, _, _ = deepspeed.initialize(model=model, config=deepspeed_config, model_parameters=model.parameters()) # Defining the optimizer and setting the learning rate using RMSprop optimizer = deepspeed.optim.RMSprop(optimizer, lr=5e-7) # Setting up a learning rate scheduler using LambdaLR from PyTorch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda epoch: 0.2 ** epoch) # Setting hyperparameters for training num_epochs = 3 max_seq_length = 2048 beta = 0.1Diese innere Schleife ist für die Generierung von Antworten verantwortlich, die mit realen Daten übereinstimmen müssen, bei denen es sich um den Code eines Trainingsstapels handelt
# zephyr-sft-dataframe (that contains output that will be improved while training) zephyr_sft_output = pd.DataFrame(columns=['prompt', 'generated_output']) # Looping through each row in the 'ultrachat_50k_sample' dataframe for index, row in ultrachat_50k_sample.iterrows():# Extracting the 'prompt' column value from the current rowprompt = row['prompt'] # Generating output for the current prompt using the Zephyr modelinput_ids = tokenizer(prompt, return_tensors="pt").input_idsoutput = model.generate(input_ids, max_length=200, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95) # Decoding the generated output to human-readable textgenerated_text = tokenizer.decode(output[0], skip_special_tokens=True) # Appending the current prompt and its generated output to the new dataframe 'zephyr_sft_output'zephyr_sft_output = zephyr_sft_output.append({'prompt': prompt, 'generated_output': generated_text}, ignore_index=True)Dies ist ein Hinweis Beispiele für reale Werte und Modellausgaben.

Neuer df zephyr_sft_output, der Hinweise und die entsprechenden Ausgaben enthält, die vom Basismodell Zephyr-7B-SFT-Full generiert wurden.
Vor dem Codieren des Minimierungsproblems ist es wichtig zu verstehen, wie die bedingte Wahrscheinlichkeitsverteilung der von llm generierten Ausgabe berechnet wird. Das Originalpapier verwendet einen Markov-Prozess, bei dem die bedingte Wahrscheinlichkeitsverteilung pθ (y∣x) durch Zerlegung wie folgt ausgedrückt werden kann:

Diese Zerlegung bedeutet, dass die Wahrscheinlichkeit der Ausgabesequenz bei gegebener Eingabesequenz durch Division ausgedrückt werden kann Die gegebene Eingabesequenz jedes Ausgabetokens wird durch Multiplizieren der Wahrscheinlichkeit des vorherigen Ausgabetokens berechnet. Die Ausgabesequenz lautet beispielsweise „Ich lese gerne Bücher“ und die Eingabesequenz lautet „Ich lese gerne Bücher“. Angesichts der Eingabesequenz kann die bedingte Wahrscheinlichkeit der Ausgabesequenz wie folgt berechnet werden:

Die bedingte Wahrscheinlichkeit des Markov-Prozesses Es werden Wahrscheinlichkeitsverteilungen zur Berechnung der Grundwahrheit und Zephyr-LLM-Antworten verwendet, die dann zur Berechnung der Verlustfunktion verwendet werden. Aber zuerst müssen wir die bedingte Wahrscheinlichkeitsfunktion kodieren.
# Conditional Probability Function of input text def compute_conditional_probability(tokenizer, model, input_text):# Tokenize the input text and convert it to PyTorch tensorsinputs = tokenizer([input_text], return_tensors="pt") # Generate text using the model, specifying additional parametersoutputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True) # Assuming 'transition_scores' is the logits for the generated tokenstransition_scores = model.compute_transition_scores(outputs.sequences, outputs.scores, normalize_logits=True) # Get the length of the input sequenceinput_length = inputs.input_ids.shape[1] # Assuming 'transition_scores' is the logits for the generated tokenslogits = torch.tensor(transition_scores) # Apply softmax to obtain probabilitiesprobs = torch.nn.functional.softmax(logits, dim=-1) # Extract the generated tokens from the outputgenerated_tokens = outputs.sequences[:, input_length:] # Compute conditional probabilityconditional_probability = 1.0for prob in probs[0]:token_probability = prob.item()conditional_probability *= token_probability return conditional_probability
Verlustfunktion Es enthält vier wichtige bedingte Wahrscheinlichkeitsvariablen. Jede dieser Variablen hängt von zugrunde liegenden realen Daten oder zuvor erstellten synthetischen Daten ab.

而lambda是一个正则化参数,用于控制偏差。在KL正则化项中使用它来惩罚对手模型的分布与目标数据分布之间的差异。论文中没有明确提到lambda的具体值,因为它可能会根据所使用的特定任务和数据集进行调优。
def LSPIN_loss(model, updated_model, tokenizer, input_text, lambda_val=0.01):# Initialize conditional probability using the original model and input textcp = compute_conditional_probability(tokenizer, model, input_text) # Update conditional probability using the updated model and input textcp_updated = compute_conditional_probability(tokenizer, updated_model, input_text) # Calculate conditional probabilities for ground truth datap_theta_ground_truth = cp(tokenizer, model, input_text)p_theta_t_ground_truth = cp(tokenizer, model, input_text) # Calculate conditional probabilities for synthetic datap_theta_synthetic = cp_updated(tokenizer, updated_model, input_text)p_theta_t_synthetic = cp_updated(tokenizer, updated_model, input_text) # Calculate likelihood ratioslr_ground_truth = p_theta_ground_truth / p_theta_t_ground_truthlr_synthetic = p_theta_synthetic / p_theta_t_synthetic # Compute the LSPIN lossloss = lambda_val * torch.log(lr_ground_truth) - lambda_val * torch.log(lr_synthetic) return loss
如果你有一个大的数据集,可以使用一个较小的lambda值,或者如果你有一个小的数据集,则可能需要使用一个较大的lambda值来防止过拟合。由于我们数据集大小为50k,所以可以使用0.01作为lambda的值。
这就是Pytorch训练的一个基本流程,就不详细解释了:
# Training loop for epoch in range(num_epochs): # Model with initial parametersinitial_model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full") # Update the learning ratescheduler.step() # Initialize total loss for the epochtotal_loss = 0.0 # Generating Synthetic Data (Inner loop)for index, row in ultrachat_50k_sample.iterrows(): # Rest of the code ... # Output == prompt response dataframezephyr_sft_output # Computing loss using LSPIN functionfor (index1, row1), (index2, row2) in zip(ultrachat_50k_sample.iterrows(), zephyr_sft_output.iterrows()):# Assuming 'prompt' and 'generated_output' are the relevant columns in zephyr_sft_outputprompt = row1['prompt']generated_output = row2['generated_output'] # Compute LSPIN lossupdated_model = model # It will be replacing with updated modelloss = LSPIN_loss(initial_model, updated_model, tokenizer, prompt) # Accumulate the losstotal_loss += loss.item() # Backward passloss.backward() # Update the parametersoptimizer.step() # Update the value of betaif epoch == 2:beta = 5.0我们运行3个epoch,它将进行训练并生成最终的Zephyr SFT LLM版本。官方实现还没有在GitHub上开源,这个版本将能够在某种程度上产生类似于人类反应的输出。我们看看他的运行流程
SPIN可以显著提高LLM在各种基准测试中的性能,甚至超过通过直接偏好优化(DPO)补充额外的GPT-4偏好数据训练的模型。
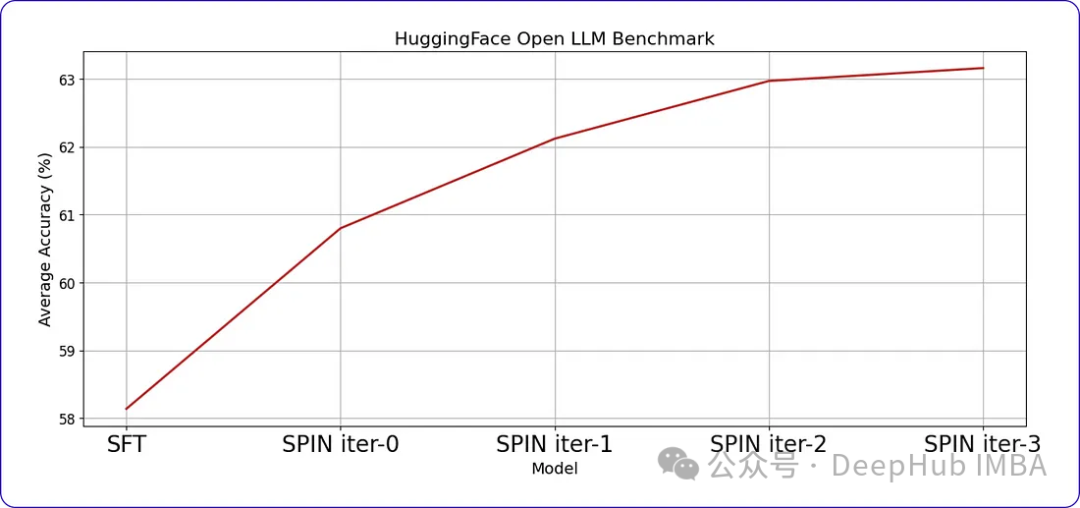
当我们继续训练时,随着时间的推移,进步会变得越来越小。这表明模型达到了一个阈值,进一步的迭代不会带来显著的收益。这是我们训练数据中样本提示符每次迭代后的响应。

Das obige ist der detaillierte Inhalt vonOptimierung von LLM mithilfe der SPIN-Technologie für das Feinabstimmungstraining für das Selbstspiel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 So erstellen Sie eine GIF-Animation in PS
So erstellen Sie eine GIF-Animation in PS
 So verwenden Sie debug.exe
So verwenden Sie debug.exe
 Welche Big-Data-Speicherlösungen gibt es?
Welche Big-Data-Speicherlösungen gibt es?
 Antiviren Software
Antiviren Software
 Warum ist mein Telefon nicht ausgeschaltet, aber wenn mich jemand anruft, werde ich aufgefordert, es auszuschalten?
Warum ist mein Telefon nicht ausgeschaltet, aber wenn mich jemand anruft, werde ich aufgefordert, es auszuschalten?
 Der Unterschied zwischen vue3.0 und 2.0
Der Unterschied zwischen vue3.0 und 2.0








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



