


State Space Model (SSM) ist eine Technologie, die viel Aufmerksamkeit erregt hat und als Alternative zu Transformer gilt. Im Vergleich zu Transformer kann SSM bei der Verarbeitung langer Kontextaufgaben eine lineare Zeitbegründung erreichen und verfügt über paralleles Training und hervorragende Leistung. Insbesondere Mamba, das auf selektivem SSM und hardwarebewusstem Design basiert, hat eine herausragende Leistung gezeigt und ist zu einer der leistungsstarken Alternativen zur aufmerksamkeitsbasierten Transformer-Architektur geworden.
Kürzlich untersuchen Forscher auch die Kombination von SSM und Mamba mit anderen Methoden, um leistungsfähigere Architekturen zu schaffen. Beispielsweise berichtete Machine Heart einmal, dass „Mamba Transformer ersetzen kann, sie aber auch in Kombination verwendet werden können.“
Kürzlich hat ein polnisches Forschungsteam herausgefunden, dass bei Kombination von SSM mit einem hybriden Expertensystem (MoE/Mixture of Experts) mit einer groß angelegten Expansion von SSM zu rechnen ist. MoE ist eine Technologie, die häufig zur Erweiterung von Transformer verwendet wird. Das aktuelle Mixtral-Modell verwendet diese Technologie. Bitte lesen Sie den Artikel „Heart of the Machine“.Das Forschungsergebnis dieses polnischen Forschungsteams ist MoE-Mamba, ein Modell, das Mamba und eine hybride Expertenschicht kombiniert.
Papieradresse: https://arxiv.org/pdf/2401.04081.pdf

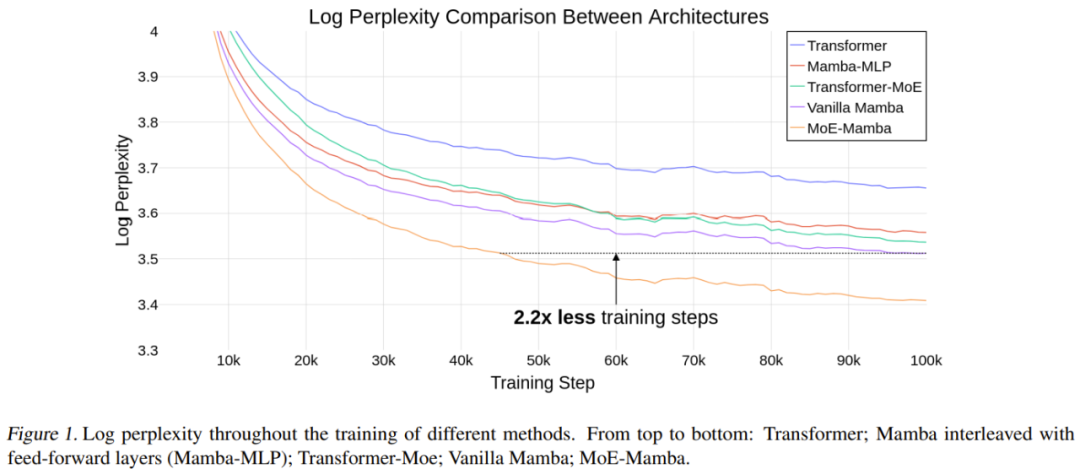
Das Team führte experimentelle Demonstrationen durch und die Ergebnisse zeigten, dass MoE-Mamba im Vergleich zu Mamba 2,2-mal weniger Trainingsschritte bei gleichen Leistungsanforderungen erforderte, was die potenziellen Vorteile der neuen Methode im Vergleich zu Transformer und Transformer-MoE verdeutlicht. Diese vorläufigen Ergebnisse weisen auch auf eine vielversprechende Forschungsrichtung hin: SSM könnte auf Dutzende Milliarden Parameter skalierbar sein.
Verwandte Forschung
State Space Model (SSM) ist eine Art Architektur, die für die Sequenzmodellierung verwendet wird. Die Ideen zu diesen Modellen stammen aus dem Bereich der Kybernetik und können als Kombination von RNN und CNN betrachtet werden. Obwohl sie erhebliche Vorteile haben, weisen sie auch einige Probleme auf, die sie daran hindern, die dominierende Architektur für Sprachmodellierungsaufgaben zu werden. Jüngste Forschungsdurchbrüche haben es Deep SSM jedoch ermöglicht, auf Milliarden von Parametern zu skalieren und gleichzeitig die Recheneffizienz und starke Leistung beizubehalten.
Mamba
Mamba ist ein auf SSM basierendes Modell, das eine lineare Zeitinferenzgeschwindigkeit (für die Kontextlänge) erreichen kann und durch hardwarebewusstes Design auch einen effizienten Trainingsprozess erreicht. Mamba verwendet einen arbeitseffizienten parallelen Scan-Ansatz, der die Auswirkungen der Schleifensequenzierung abschwächt, während durch Fusions-GPU-Vorgänge die Implementierung eines erweiterten Status überflüssig wird. Für die Backpropagation notwendige Zwischenzustände werden nicht gespeichert, sondern beim Rückwärtsdurchlauf neu berechnet, wodurch der Speicherbedarf reduziert wird. Der Vorteil von Mamba gegenüber dem Aufmerksamkeitsmechanismus ist besonders in der Inferenzphase von Bedeutung, da dadurch nicht nur die Rechenkomplexität reduziert wird, sondern auch die Speichernutzung nicht von der Kontextlänge abhängt.
Mamba kann den grundlegenden Kompromiss zwischen Effizienz und Effektivität von Sequenzmodellen lösen, was die Bedeutung der Zustandskomprimierung hervorhebt. Ein effizientes Modell muss einen kleinen Zustand haben, und ein effektives Modell muss einen Zustand haben, der alle Schlüsselinformationen des Kontexts enthält. Im Gegensatz zu anderen SSMs, die zeitliche und Eingabeinvarianz erfordern, führt Mamba einen Auswahlmechanismus ein, der steuert, wie Informationen entlang der Sequenzdimension weitergegeben werden. Diese Designentscheidung wurde durch ein intuitives Verständnis erstklassiger Syntheseaufgaben wie selektiver Replikation und Induktion inspiriert, die es dem Modell ermöglichen, kritische Informationen zu erkennen und zu behalten und gleichzeitig irrelevante Informationen herauszufiltern.
Untersuchungen haben ergeben, dass Mamba in der Lage ist, längere Kontexte (bis zu 1 Million Token) effizient zu nutzen, und mit zunehmender Kontextlänge wird sich auch die Verwirrung vor dem Training verbessern. Das Mamba-Modell besteht aus gestapelten Mamba-Blöcken und hat in vielen verschiedenen Bereichen wie NLP, Genomik, Audio usw. sehr gute Ergebnisse erzielt. Seine Leistung ist mit dem bestehenden Transformer-Modell vergleichbar und übertrifft dieses. Daher ist Mamba zu einem starken Kandidatenmodell für das allgemeine Sequenzmodellierungs-Backbone-Modell geworden. Weitere Informationen finden Sie unter „Fünffacher Durchsatz, umfassende Leistung rund um Transformer: Neue Architektur Mamba sprengt den KI-Kreis.“Mixed Experts
Mixed Experts (MoE)-Techniken können die Anzahl der Parameter des Modells erheblich erhöhen, ohne die für die Modellinferenz und das Training erforderlichen FLOPs zu beeinträchtigen. MoE wurde erstmals 1991 von Jacobs et al. vorgeschlagen und 2017 von Shazeer et al. für NLP-Aufgaben eingesetzt.
MoE hat einen Vorteil: Die Aktivierungen sind sehr spärlich – für jeden verarbeiteten Token wird nur ein kleiner Teil der Parameter des Modells verwendet. Aufgrund seiner Rechenanforderungen ist die Vorwärtsschicht im Transformer zu einem Standardziel für mehrere MoE-Techniken geworden.Die Forschungsgemeinschaft hat verschiedene Methoden vorgeschlagen, um das Kernproblem von MoE zu lösen, bei dem es sich um den Prozess der Zuweisung von Token an Experten handelt, der auch Routing-Prozess genannt wird. Derzeit gibt es zwei grundlegende Routing-Algorithmen: Token Choice und Expert Choice. Ersteres leitet jedes Token an eine bestimmte Anzahl (K) von Experten weiter, während letzteres eine feste Anzahl von Token an jeden Experten weiterleitet.
Fedus et al. schlugen in der Arbeit „Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity“ von 2022 eine Token-Choice-Architektur vor, die jeden Token an einen einzelnen Experten weiterleitet (K=1). und sie nutzten diese Methode, um die Parametergröße von Transformer erfolgreich auf 1,6 Billionen zu erweitern. Auch dieses Team in Polen verwendete dieses MoE-Design in seinen Experimenten.
Vor kurzem hat MoE auch damit begonnen, in die Open-Source-Community einzudringen, beispielsweise OpenMoE.
Projektadresse: https://github.com/XueFuzhao/OpenMoE
Besonders erwähnenswert ist, dass Mistrals Open-Source-Mixtral 8×7B eine mit LLaMa 2 70B vergleichbare Leistung aufweist, aber Inferenzberechnungen erfordert Das Budget ist nur etwa ein Sechstel davon.
Modellarchitektur
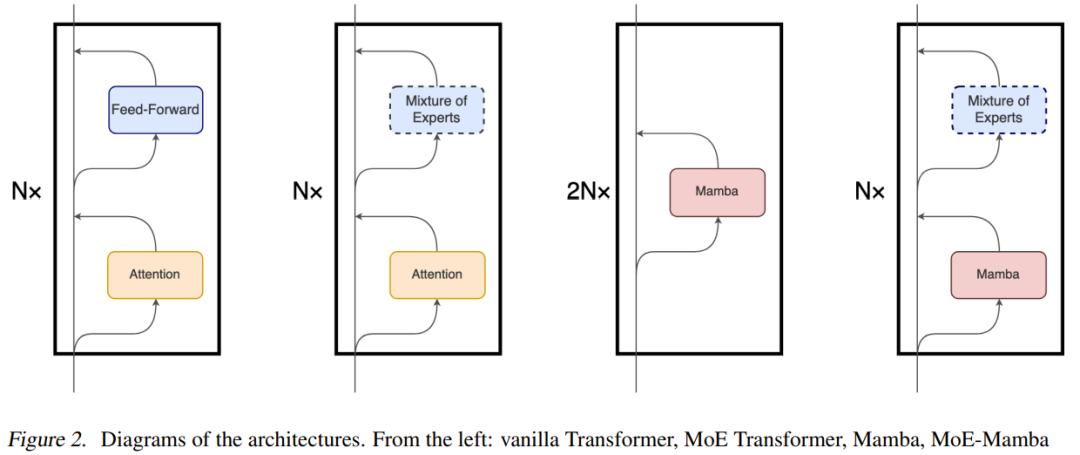
Obwohl sich der Hauptmechanismus von Mamba stark vom in Transformer verwendeten Aufmerksamkeitsmechanismus unterscheidet, behält Mamba die übergeordnete, modulbasierte Struktur des Transformer-Modells bei. Bei diesem Paradigma werden eine oder mehrere Schichten identischer Module übereinander gestapelt und die Ausgabe jeder Schicht einem Reststrom hinzugefügt, siehe Abbildung 2. Der Endwert dieses Reststroms wird dann verwendet, um das nächste Token für die Sprachmodellierungsaufgabe vorherzusagen.
Das Team stellte jedoch auch fest, dass dieses Design dem Design von „Mamba: Linear-Time Sequence Modeling with Selective State Spaces“ etwas ähnelt; letzteres stapelt abwechselnd Mamba-Schichten und Feedforward-Schichten, aber das Ergebnis Das Modell ist der einfachen Mamba etwas unterlegen. Dieses Design wird in Abbildung 1 als Mamba-MLP bezeichnet.
Wichtige Ergebnisse
Das Team verglich 5 verschiedene Aufbauten: Basic Transformer, Mamba, Mamba-MLP, MoE und MoE-Mamba.
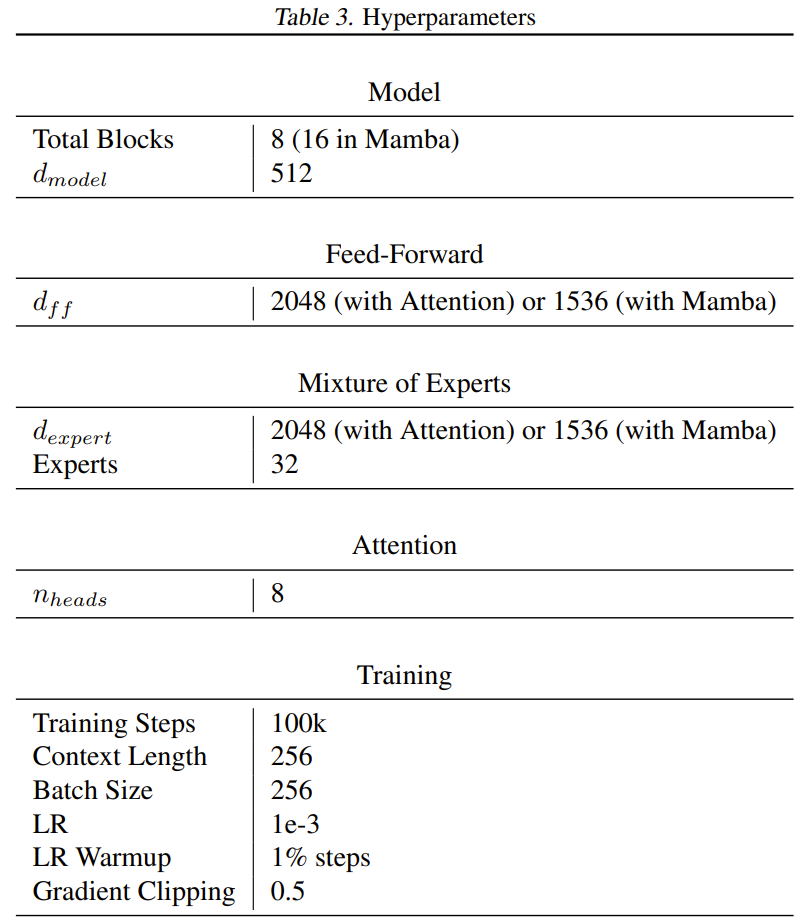
In den meisten Transformern enthält die Feedforward-Schicht 8 dm² Parameter, während das Mamba-Papier Mamba kleiner macht (ca. 6 dm²), sodass die Anzahl der Parameter von zwei Mamba-Schichten der einer Feedforward-Schicht und einer Aufmerksamkeitsschicht entspricht das gleiche. Um in Mamba und dem neuen Modell ungefähr die gleiche Anzahl aktiver Parameter pro Token zu erhalten, reduzierte das Team die Größe jeder Expert-Forward-Schicht auf 6 dm². Mit Ausnahme der Einbettungs- und Nichteinbettungsebenen verwenden alle Modelle etwa 26 Millionen Parameter pro Token. Der Trainingsprozess verwendet 6,5 Milliarden Token und die Anzahl der Trainingsschritte beträgt 100.000.
Der für das Training verwendete Datensatz ist der englische C4-Datensatz, und die Aufgabe besteht darin, den nächsten Token vorherzusagen. Text wird mit dem GPT2-Tokenizer tokenisiert. Tabelle 3 enthält die vollständige Liste der Hyperparameter.
Ergebnisse
Tabelle 1 enthält die Trainingsergebnisse. MoE-Mamba schneidet deutlich besser ab als das reguläre Mamba-Modell.
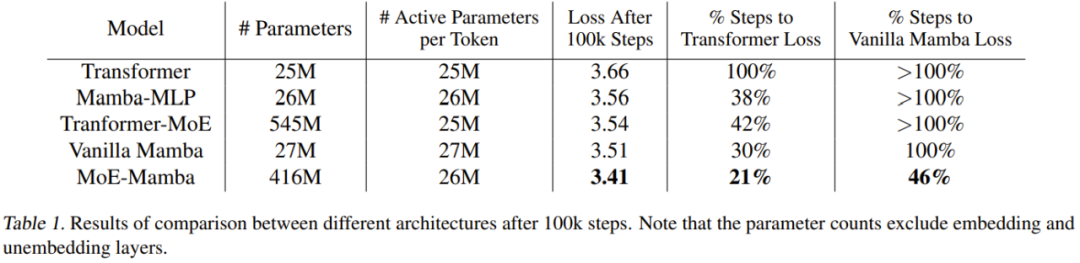
Es ist erwähnenswert, dass MoE-Mamba in nur 46 % der Trainingsschritte die gleichen Ergebnisse wie gewöhnliche Mamba erzielt. Da die Lernrate für normales Mamba angepasst ist, kann davon ausgegangen werden, dass MoE-Mamba eine bessere Leistung erbringt, wenn der Trainingsprozess für MoE-Mamba optimiert wird.
Um zu beurteilen, ob Mamba mit zunehmender Expertenzahl gut skaliert, verglichen die Forscher Modelle mit unterschiedlicher Expertenzahl.
Abbildung 3 zeigt die Trainingslaufschritte bei unterschiedlicher Expertenanzahl.
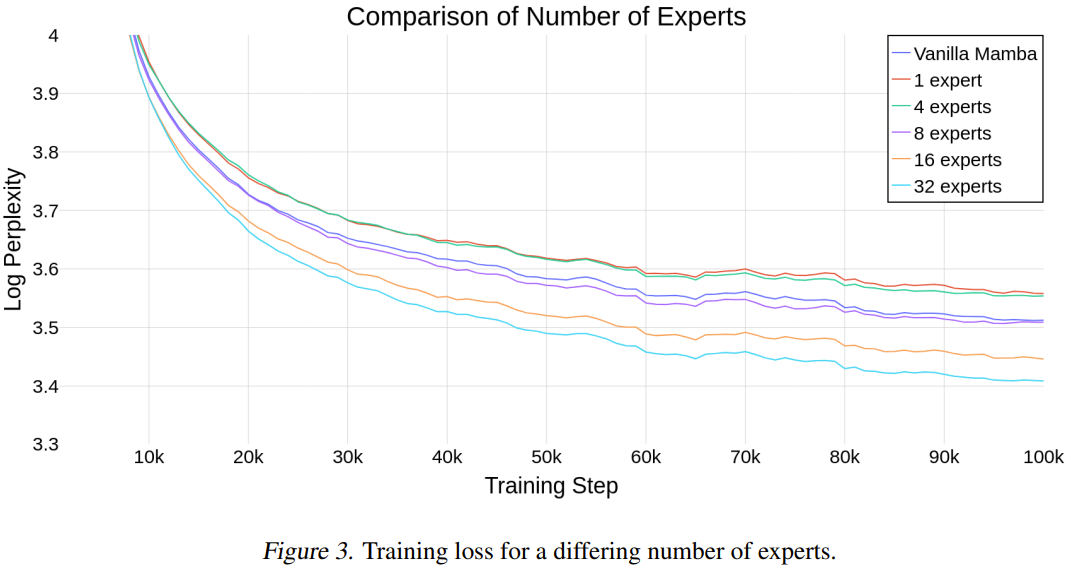
Tabelle 2 zeigt die Ergebnisse nach 100.000 Schritten.
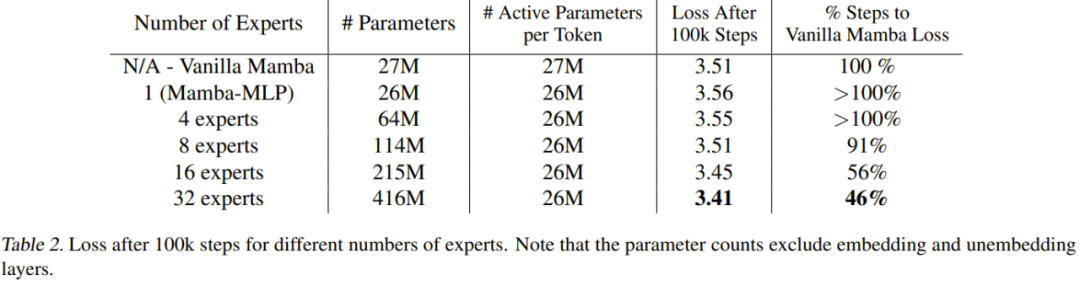
Diese Ergebnisse zeigen, dass die neu vorgeschlagene Methode gut mit der Anzahl der Experten skaliert. Wenn die Anzahl der Experten 8 oder mehr beträgt, ist die Endleistung des neuen Modells besser als die des normalen Mamba. Da Mamba-MLP schlechter ist als einfaches Mamba, ist zu erwarten, dass MoE-Mamba mit einer kleinen Anzahl von Experten schlechter abschneidet als Mamba. Die besten Ergebnisse lieferte die neue Methode bei einer Expertenzahl von 32.
Das obige ist der detaillierte Inhalt vonMoE und Mamba arbeiten zusammen, um Zustandsraummodelle auf Milliarden von Parametern zu skalieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































