


Deep Learning ist ein Zweig des maschinellen Lernens, der darauf abzielt, die Fähigkeiten des Gehirns bei der Datenverarbeitung zu simulieren. Es löst Probleme durch den Aufbau künstlicher neuronaler Netzwerkmodelle, die es Maschinen ermöglichen, ohne Aufsicht zu lernen. Dieser Ansatz ermöglicht es Maschinen, komplexe Muster und Merkmale automatisch zu extrahieren und zu verstehen. Durch Deep Learning können Maschinen aus großen Datenmengen lernen und hochpräzise Vorhersagen und Entscheidungen liefern. Dadurch konnte Deep Learning große Erfolge in Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache und Spracherkennung erzielen.
Um die Funktion neuronaler Netze zu verstehen, betrachten Sie die Übertragung von Impulsen in Neuronen. Nachdem Daten vom Dendritenterminal empfangen wurden, werden sie im Zellkern gewichtet (mit w multipliziert) und dann entlang des Axons weitergeleitet und mit einer anderen Nervenzelle verbunden. Axone (x) sind der Ausgang eines Neurons und werden zum Eingang eines anderen Neurons, wodurch die Informationsübertragung zwischen den Nerven sichergestellt wird.
Um am Computer zu modellieren und zu trainieren, müssen wir den Algorithmus der Operation verstehen und durch Eingabe des Befehls die Ausgabe erhalten.
Hier drücken wir es mathematisch wie folgt aus:
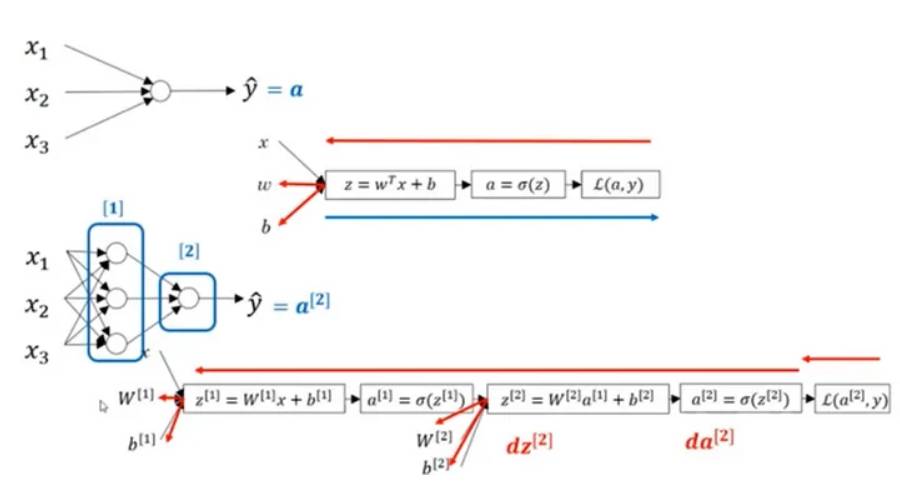
In der obigen Abbildung ist ein zweischichtiges neuronales Netzwerk dargestellt, das eine verborgene Schicht aus 4 Neuronen und eine Ausgabeschicht mit einem einzelnen Neuron enthält. Es ist zu beachten, dass die Anzahl der Eingabeschichten keinen Einfluss auf den Betrieb des neuronalen Netzwerks hat. Die Anzahl der Neuronen in diesen Schichten und die Anzahl der Eingabewerte werden durch die Parameter w und b dargestellt. Insbesondere ist die Eingabe in die verborgene Ebene x und die Eingabe in die Ausgabeebene ist der Wert von a.
Hyperbolischer Tangens, ReLU, Leaky ReLU und andere Funktionen können Sigmoid als differenzierbare Aktivierungsfunktion ersetzen und in der Schicht verwendet werden, und die Gewichte werden durch die Ableitungsoperation bei der Backpropagation aktualisiert.
Die ReLU-Aktivierungsfunktion wird häufig beim Deep Learning verwendet. Da die Teile der ReLU-Funktion, die kleiner als 0 sind, nicht differenzierbar sind, lernen sie während des Trainings nicht. Die Leaky-ReLU-Aktivierungsfunktion löst dieses Problem. Sie ist in Teilen kleiner als 0 differenzierbar und lernt auf jeden Fall. Dies macht Leaky ReLU in einigen Szenarien effektiver als ReLU.
Das obige ist der detaillierte Inhalt vonAnalyse künstlicher neuronaler Netzlernmethoden im Deep Learning. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So löschen Sie meine WeChat-Adresse
So löschen Sie meine WeChat-Adresse
 So ermitteln Sie die Summe gerader Elemente in einem Array in PHP
So ermitteln Sie die Summe gerader Elemente in einem Array in PHP
 MySQL-Fehler 10060
MySQL-Fehler 10060
 So schließen Sie das von window.open geöffnete Fenster
So schließen Sie das von window.open geöffnete Fenster
 Verwendung der Geschwindigkeitsanmerkung
Verwendung der Geschwindigkeitsanmerkung
 So überprüfen Sie, ob Port 445 geschlossen ist
So überprüfen Sie, ob Port 445 geschlossen ist
 Überprüfen Sie die Portbelegungsfenster
Überprüfen Sie die Portbelegungsfenster
 So richten Sie Textfelder in HTML aus
So richten Sie Textfelder in HTML aus








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



