

 Technologie-Peripheriegeräte
KI
I2V-Adapter aus der SD-Community: keine Konfiguration erforderlich, Plug-and-Play, perfekt kompatibel mit dem Tusheng-Video-Plug-in
Technologie-Peripheriegeräte
KI
I2V-Adapter aus der SD-Community: keine Konfiguration erforderlich, Plug-and-Play, perfekt kompatibel mit dem Tusheng-Video-Plug-in
I2V-Adapter aus der SD-Community: keine Konfiguration erforderlich, Plug-and-Play, perfekt kompatibel mit dem Tusheng-Video-Plug-in

Die Aufgabe der Bild-zu-Video-Generierung (I2V) ist eine Herausforderung im Bereich Computer Vision, die darauf abzielt, statische Bilder in dynamische Videos umzuwandeln. Die Schwierigkeit dieser Aufgabe besteht darin, aus einem einzelnen Bild dynamische Informationen in der zeitlichen Dimension zu extrahieren und zu generieren und dabei die Authentizität und visuelle Kohärenz des Bildinhalts zu wahren. Bestehende I2V-Methoden erfordern häufig komplexe Modellarchitekturen und große Mengen an Trainingsdaten, um dieses Ziel zu erreichen.
Kürzlich wurde ein neues Forschungsergebnis „I2V-Adapter: Ein allgemeiner Bild-zu-Video-Adapter für Videodiffusionsmodelle“ unter der Leitung von Kuaishou veröffentlicht. Diese Forschung stellt eine innovative Bild-zu-Video-Konvertierungsmethode vor und schlägt ein leichtes Adaptermodul vor, den I2V-Adapter. Dieses Adaptermodul ist in der Lage, statische Bilder in dynamische Videos umzuwandeln, ohne die ursprüngliche Struktur und vorab trainierte Parameter vorhandener T2V-Modelle (Text-to-Video Generation) zu ändern. Diese Methode hat breite Anwendungsaussichten im Bereich der Bild-Video-Konvertierung und kann mehr Möglichkeiten für die Videoerstellung, Medienkommunikation und andere Bereiche eröffnen. Die Veröffentlichung der Forschungsergebnisse ist von großer Bedeutung für die Weiterentwicklung der Bild- und Videotechnologie und stellt ein wirksames Werkzeug und eine Methode für Forscher in verwandten Bereichen dar.

- Papieradresse: https://arxiv.org/pdf/2312.16693.pdf
- Projekthomepage: https://i2v-adapter.github.io/index .html
- Codeadresse: https://github.com/I2V-Adapter/I2V-Adapter-repo
Im Vergleich zu vorhandenen Methoden verfügt der I2V-Adapter über mehr trainierbare Parameter. Es wurden enorme Verbesserungen erzielt hergestellt, und die Anzahl der Parameter kann bis zu 22 Millionen erreichen, was nur 1 % der Mainstream-Lösung Stable Video Diffusion ausmacht. Gleichzeitig ist der Adapter auch mit maßgeschneiderten T2I-Modellen (wie DreamBooth, Lora) und Steuerungstools (wie ControlNet) kompatibel, die von der Stable Diffusion-Community entwickelt wurden. Durch Experimente haben die Forscher die Wirksamkeit des I2V-Adapters bei der Generierung hochwertiger Videoinhalte nachgewiesen und damit neue Möglichkeiten für kreative Anwendungen im I2V-Bereich eröffnet.

Einführung in die Methode
Zeitliche Modellierung mit stabiler Diffusion
Im Vergleich zur Bildgenerierung steht die Videogenerierung vor einer einzigartigen Herausforderung, nämlich der Modellierung der zeitlichen Kohärenz zwischen Videobildern und Geschlecht. Die meisten aktuellen Methoden basieren auf vorab trainierten T2I-Modellen wie Stable Diffusion und SDXL, indem sie Timing-Module zur Modellierung der Timing-Informationen in Videos einführen. Inspiriert von AnimateDiff, einem Modell, das ursprünglich für benutzerdefinierte T2V-Aufgaben entwickelt wurde, modelliert es Timing-Informationen durch die Einführung eines vom T2I-Modell entkoppelten Timing-Moduls und behält die Fähigkeit des ursprünglichen T2I-Modells bei, reibungslose Videos zu generieren. Daher glauben die Forscher, dass das vorab trainierte Zeitmodul als universelle Zeitdarstellung angesehen werden kann und ohne Feinabstimmung auf andere Videogenerierungsszenarien wie die I2V-Generierung angewendet werden kann. Daher verwendeten die Forscher direkt das vorab trainierte AnimateDiff-Timing-Modul und behielten seine Parameter bei.
Adapter für Aufmerksamkeitsebenen
Eine weitere Herausforderung bei der I2V-Aufgabe besteht darin, die ID-Informationen des Eingabebildes beizubehalten. Derzeit gibt es zwei Hauptlösungen: Die eine besteht darin, das Eingabebild mit einem vorab trainierten Bildcodierer zu codieren und die codierten Merkmale über einen Kreuzaufmerksamkeitsmechanismus in das Modell einzufügen, um den Entrauschungsprozess zu steuern mit dem verrauschten Eingang in der Kanaldimension verkettet und dann gemeinsam in das nachfolgende Netzwerk eingespeist. Die erstere Methode kann jedoch dazu führen, dass sich die generierte Video-ID ändert, da es für den Bildencoder schwierig ist, die zugrunde liegenden Informationen zu erfassen, während die letztere Methode häufig eine Änderung der Struktur und der Parameter des T2I-Modells erfordert, was zu hohen Schulungskosten und schlechten Ergebnissen führt Kompatibilität.
Um die oben genannten Probleme zu lösen, schlugen Forscher einen I2V-Adapter vor. Insbesondere gibt der Forscher das Eingabebild und die verrauschte Eingabe parallel in das Netzwerk ein. Im räumlichen Block des Modells fragen alle Frames zusätzlich die ersten Frame-Informationen ab, dh die Schlüssel- und Wertmerkmale stammen aus dem ersten Frame ohne Rauschen , und die Ausgabe Das Ergebnis wird zur Selbstaufmerksamkeit des Originalmodells hinzugefügt. Die Ausgabezuordnungsmatrix in diesem Modul wird mit Nullen initialisiert und nur die Ausgabezuordnungsmatrix und die Abfragezuordnungsmatrix werden trainiert. Um das Verständnis des Modells für die semantischen Informationen des Eingabebilds weiter zu verbessern, führten die Forscher einen vorab trainierten Inhaltsadapter ein (in diesem Artikel wird der IP-Adapter [8] verwendet), um die semantischen Merkmale des Bilds einzufügen.
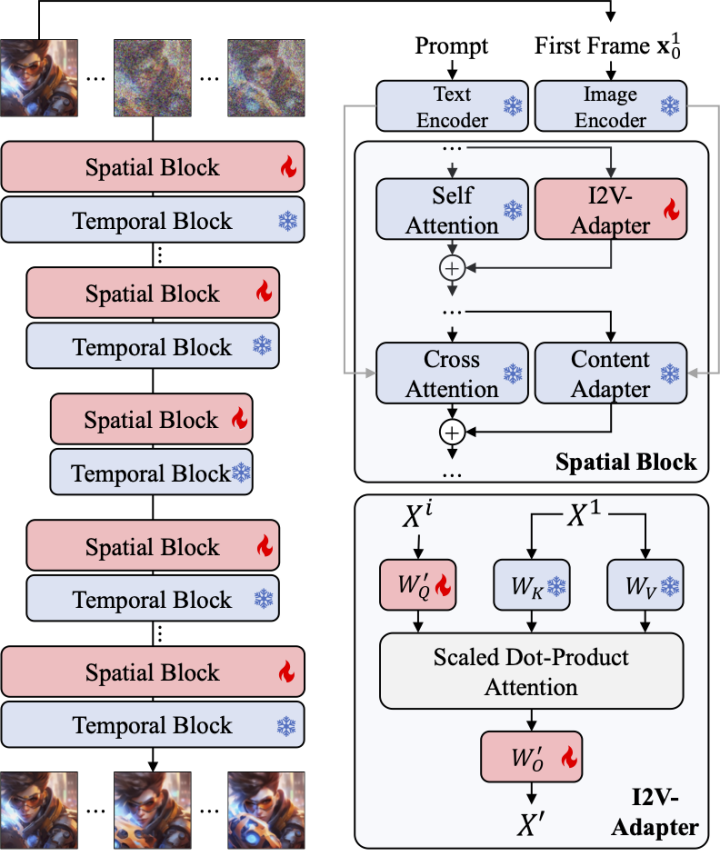
Priorität der Frame-Ähnlichkeit
Um die Stabilität der generierten Ergebnisse weiter zu verbessern, schlugen die Forscher vorab eine Inter-Frame-Ähnlichkeit vor, um ein Gleichgewicht zwischen der Stabilität und der Bewegungsintensität des generierten Videos herzustellen. Die Hauptannahme ist, dass bei einem relativ niedrigen Gaußschen Rauschpegel der verrauschte erste Rahmen und die verrauschten nachfolgenden Rahmen nahe genug beieinander liegen, wie in der folgenden Abbildung dargestellt:
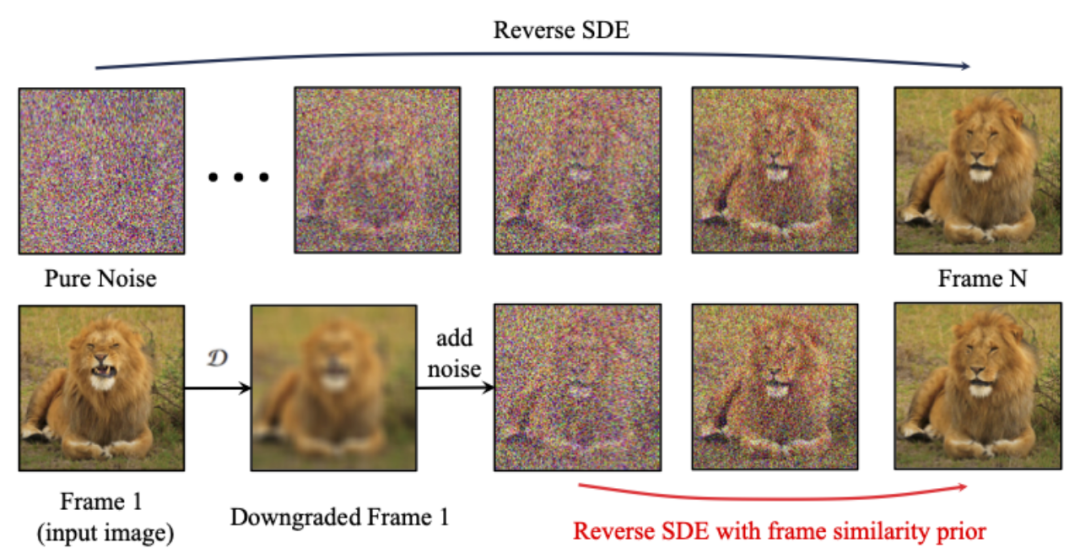
Die Forscher gingen also davon aus, dass alle Rahmenstrukturen ähnlich sind , und werden nach dem Hinzufügen einer bestimmten Menge an Gauß'schem Rauschen nicht mehr zu unterscheiden, sodass das verrauschte Eingabebild als A-priori-Eingabe für nachfolgende Frames verwendet werden kann. Um die Irreführung hochfrequenter Informationen zu beseitigen, verwendeten die Forscher auch den Gaußschen Unschärfeoperator und die zufällige Maskenmischung. Konkret wird die Operation durch die folgende Formel angegeben:

Experimentelle Ergebnisse
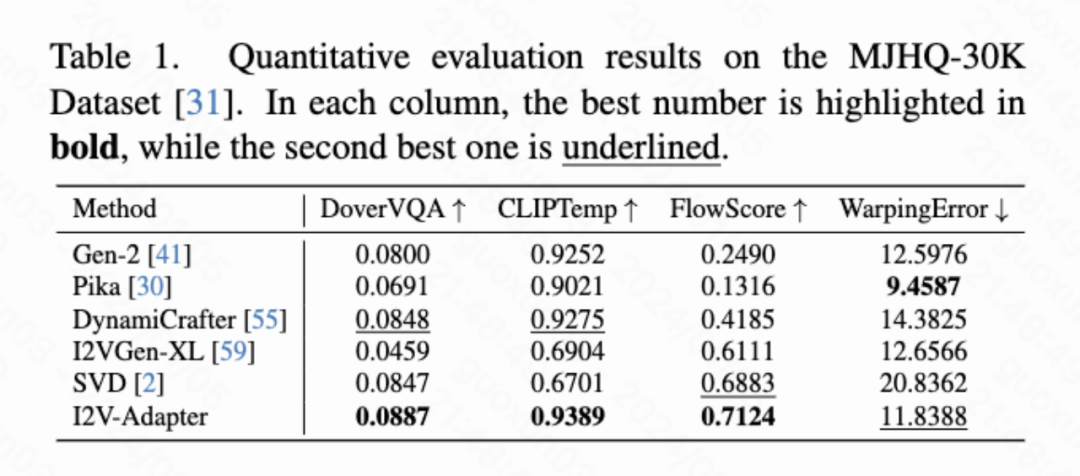
Quantitative Ergebnisse
In diesem Artikel werden vier quantitative Indikatoren berechnet, nämlich DoverVQA (ästhetische Bewertung) und CLIPTemp (erster Frame). Konsistenz), FlowScore (Bewegungsamplitude) und WarppingError (Bewegungsfehler) werden verwendet, um die Qualität des generierten Videos zu bewerten. Tabelle 1 zeigt, dass der I2V-Adapter die höchste ästhetische Bewertung erhielt und auch alle Vergleichsschemata hinsichtlich der Konsistenz des ersten Frames übertraf. Darüber hinaus weist das vom I2V-Adapter erzeugte Video die größte Bewegungsamplitude und einen relativ geringen Bewegungsfehler auf, was darauf hinweist, dass dieses Modell in der Lage ist, dynamischere Videos zu erzeugen und gleichzeitig die Genauigkeit der zeitlichen Bewegung beizubehalten.
Qualitative Ergebnisse
Bildanimation (links ist Eingabe, rechts ist Ausgabe):



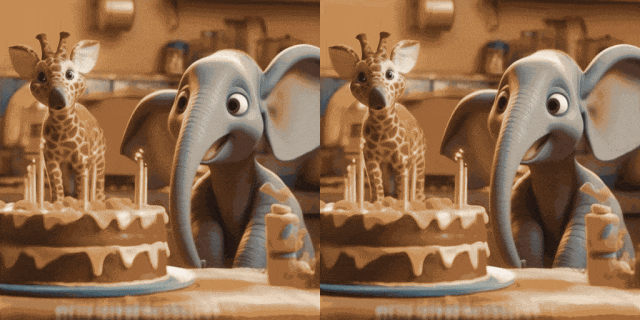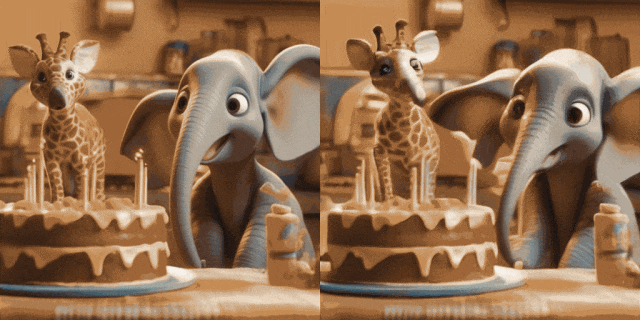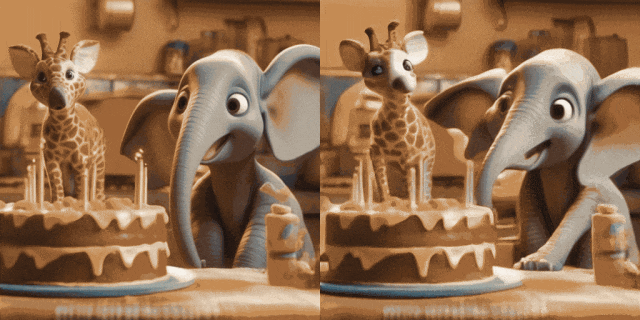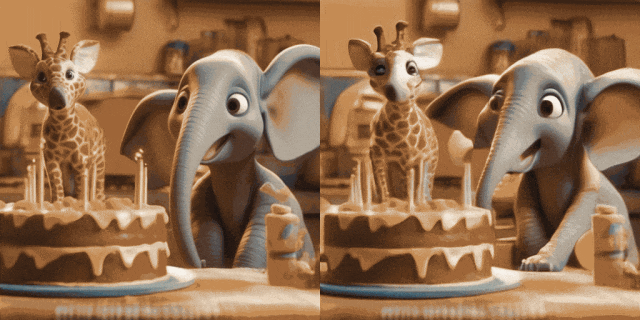 .
.
mit personalisierten T2Is (auf der linker Eingang, rechts ist Ausgang):




w/ ControlNet (links ist Eingang, rechts ist Ausgang):



Zusammenfassung
In diesem Artikel wird der I2V-Adapter vorgeschlagen, ein leichtes Plug-and-Play-Modul für Bild-zu-Video-Generierungsaufgaben. Diese Methode hält die räumlichen Block- und Bewegungsblockstrukturen und -parameter des ursprünglichen T2V-Modells fest, gibt den ersten Frame ohne Rauschen und die nachfolgenden Frames mit Rauschen parallel ein und ermöglicht allen Frames die Interaktion mit dem ersten Frame ohne Rauschen über den Aufmerksamkeitsmechanismus , also ein Video erzeugen, das zeitlich kohärent ist und mit dem ersten Bild übereinstimmt. Forscher haben die Wirksamkeit dieser Methode bei I2V-Aufgaben durch quantitative und qualitative Experimente nachgewiesen. Darüber hinaus ermöglicht das entkoppelte Design die direkte Kombination der Lösung mit Modulen wie DreamBooth, Lora und ControlNet, was die Kompatibilität der Lösung beweist und die Forschung zur maßgeschneiderten und steuerbaren Bild-zu-Video-Generierung fördert.
Das obige ist der detaillierte Inhalt vonI2V-Adapter aus der SD-Community: keine Konfiguration erforderlich, Plug-and-Play, perfekt kompatibel mit dem Tusheng-Video-Plug-in. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wo werden Videodateien im Browser-Cache gespeichert?
Feb 19, 2024 pm 05:09 PM
Wo werden Videodateien im Browser-Cache gespeichert?
Feb 19, 2024 pm 05:09 PM
In welchem Ordner speichert der Browser das Video? Wenn wir den Internetbrowser täglich nutzen, schauen wir uns häufig verschiedene Online-Videos an, z. B. Musikvideos auf YouTube oder Filme auf Netflix. Diese Videos werden während des Ladevorgangs vom Browser zwischengespeichert, sodass sie bei späterer erneuter Wiedergabe schnell geladen werden können. Die Frage ist also: In welchem Ordner werden diese zwischengespeicherten Videos tatsächlich gespeichert? Verschiedene Browser speichern zwischengespeicherte Videoordner an unterschiedlichen Orten. Im Folgenden stellen wir einige gängige Browser und deren Funktionen vor
 Ist es ein Verstoß, die Videos anderer Leute auf Douyin zu posten? Wie werden Videos ohne Rechtsverletzung bearbeitet?
Mar 21, 2024 pm 05:57 PM
Ist es ein Verstoß, die Videos anderer Leute auf Douyin zu posten? Wie werden Videos ohne Rechtsverletzung bearbeitet?
Mar 21, 2024 pm 05:57 PM
Mit dem Aufkommen von Kurzvideoplattformen ist Douyin zu einem unverzichtbaren Bestandteil des täglichen Lebens eines jeden geworden. Auf TikTok können wir interessante Videos aus aller Welt sehen. Manche Leute posten gerne die Videos anderer Leute, was die Frage aufwirft: Verstößt Douyin gegen das Posten der Videos anderer Leute? In diesem Artikel wird dieses Problem erörtert und Ihnen erklärt, wie Sie Videos ohne Rechtsverletzung bearbeiten und Probleme mit Rechtsverletzungen vermeiden können. 1. Verstößt es gegen Douyins Veröffentlichung von Videos anderer Personen? Gemäß den Bestimmungen des Urheberrechtsgesetzes meines Landes stellt die unbefugte Nutzung der Werke des Urheberrechtsinhabers ohne die Erlaubnis des Urheberrechtsinhabers einen Verstoß dar. Daher stellt das Posten von Videos anderer Personen auf Douyin ohne die Erlaubnis des ursprünglichen Autors oder Urheberrechtsinhabers einen Verstoß dar. 2. Wie bearbeite ich ein Video ohne Urheberrechtsverletzung? 1. Verwendung von gemeinfreien oder lizenzierten Inhalten: Öffentlich
 So entfernen Sie Video-Wasserzeichen in Wink
Feb 23, 2024 pm 07:22 PM
So entfernen Sie Video-Wasserzeichen in Wink
Feb 23, 2024 pm 07:22 PM
Wie entferne ich Wasserzeichen aus Videos in Wink? Es gibt ein Tool zum Entfernen von Wasserzeichen aus Videos in Wink, aber die meisten Freunde wissen nicht, wie man Wasserzeichen aus Videos in Wink entfernt Vom Herausgeber bereitgestelltes Text-Tutorial, interessierte Benutzer kommen vorbei und schauen es sich an! So entfernen Sie das Video-Wasserzeichen in Wink: 1. Öffnen Sie zunächst die Wink-App und wählen Sie im Startseitenbereich die Funktion [Wasserzeichen entfernen] aus. 2. Wählen Sie dann das Video aus, bei dem Sie das Wasserzeichen entfernen möchten in der oberen rechten Ecke nach der Bearbeitung des Videos [√] 4. Klicken Sie abschließend auf [Ein-Klick-Drucken] und dann auf [Verarbeiten].
 Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Wie kann ein Neuling mit Douyin Geld verdienen?
Mar 21, 2024 pm 08:17 PM
Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Wie kann ein Neuling mit Douyin Geld verdienen?
Mar 21, 2024 pm 08:17 PM
Douyin, die nationale Kurzvideoplattform, ermöglicht uns nicht nur, in unserer Freizeit eine Vielzahl interessanter und neuartiger Kurzvideos zu genießen, sondern gibt uns auch eine Bühne, um uns zu zeigen und unsere Werte zu verwirklichen. Wie kann man also Geld verdienen, indem man Videos auf Douyin veröffentlicht? Dieser Artikel wird diese Frage ausführlich beantworten und Ihnen dabei helfen, mit TikTok mehr Geld zu verdienen. 1. Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Nachdem Sie ein Video gepostet und eine bestimmte Anzahl an Aufrufen auf Douyin erreicht haben, haben Sie die Möglichkeit, am Werbe-Sharing-Plan teilzunehmen. Diese Einkommensmethode ist eine der bekanntesten unter Douyin-Benutzern und stellt auch für viele YouTuber die Haupteinnahmequelle dar. Douyin entscheidet anhand verschiedener Faktoren wie Kontogewicht, Videoinhalt und Publikumsfeedback, ob Möglichkeiten zum Teilen von Werbung bereitgestellt werden sollen. Die TikTok-Plattform ermöglicht es Zuschauern, ihre Lieblingsschöpfer durch das Versenden von Geschenken zu unterstützen.
 So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren_So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren
Mar 30, 2024 pm 12:26 PM
So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren_So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren
Mar 30, 2024 pm 12:26 PM
1. Öffnen Sie zunächst Weibo auf Ihrem Mobiltelefon und klicken Sie unten rechts auf [Ich] (wie im Bild gezeigt). 2. Klicken Sie dann oben rechts auf [Zahnrad], um die Einstellungen zu öffnen (wie im Bild gezeigt). 3. Suchen und öffnen Sie dann [Allgemeine Einstellungen] (wie im Bild gezeigt). 4. Geben Sie dann die Option [Video Follow] ein (wie im Bild gezeigt). 5. Öffnen Sie dann die Einstellung [Video-Upload-Auflösung] (wie im Bild gezeigt). 6. Wählen Sie abschließend [Originalbildqualität] aus, um eine Komprimierung zu vermeiden (wie im Bild gezeigt).
 2 Möglichkeiten, Zeitlupe aus Videos auf dem iPhone zu entfernen
Mar 04, 2024 am 10:46 AM
2 Möglichkeiten, Zeitlupe aus Videos auf dem iPhone zu entfernen
Mar 04, 2024 am 10:46 AM
Auf iOS-Geräten können Sie mit der Kamera-App Zeitlupenvideos aufnehmen, oder sogar 240 Bilder pro Sekunde, wenn Sie das neueste iPhone besitzen. Mit dieser Funktion können Sie High-Speed-Aktionen detailreich erfassen. Aber manchmal möchten Sie vielleicht Zeitlupenvideos mit normaler Geschwindigkeit abspielen, damit Sie die Details und das Geschehen im Video besser wahrnehmen können. In diesem Artikel erklären wir alle Methoden zum Entfernen von Zeitlupe aus vorhandenen Videos auf dem iPhone. So entfernen Sie Zeitlupe aus Videos auf dem iPhone [2 Methoden] Sie können die Fotos-App oder die iMovie-App verwenden, um Zeitlupe aus Videos auf Ihrem Gerät zu entfernen. Methode 1: Mit der Fotos-App auf dem iPhone öffnen
 Wie veröffentliche ich Xiaohongshu-Videowerke? Worauf sollte ich beim Posten von Videos achten?
Mar 23, 2024 pm 08:50 PM
Wie veröffentliche ich Xiaohongshu-Videowerke? Worauf sollte ich beim Posten von Videos achten?
Mar 23, 2024 pm 08:50 PM
Mit dem Aufkommen von Kurzvideoplattformen ist Xiaohongshu für viele Menschen zu einer Plattform geworden, auf der sie ihr Leben teilen, sich ausdrücken und Traffic gewinnen können. Auf dieser Plattform ist die Veröffentlichung von Videoarbeiten eine sehr beliebte Art der Interaktion. Wie veröffentlicht man also Xiaohongshu-Videoarbeiten? 1. Wie veröffentliche ich Xiaohongshu-Videowerke? Stellen Sie zunächst sicher, dass Sie einen Videoinhalt zum Teilen bereit haben. Sie können zum Fotografieren Ihr Mobiltelefon oder eine andere Kameraausrüstung verwenden, Sie müssen jedoch auf die Bildqualität und die Klarheit des Tons achten. 2. Bearbeiten Sie das Video: Um die Arbeit attraktiver zu gestalten, können Sie das Video bearbeiten. Sie können professionelle Videobearbeitungssoftware wie Douyin, Kuaishou usw. verwenden, um Filter, Musik, Untertitel und andere Elemente hinzuzufügen. 3. Wählen Sie ein Cover: Das Cover ist der Schlüssel, um Benutzer zum Klicken zu bewegen. Wählen Sie ein klares und interessantes Bild als Cover, um Benutzer zum Klicken zu bewegen.
 So konvertieren Sie vom UC-Browser heruntergeladene Videos in lokale Videos
Feb 29, 2024 pm 10:19 PM
So konvertieren Sie vom UC-Browser heruntergeladene Videos in lokale Videos
Feb 29, 2024 pm 10:19 PM
Wie wandele ich vom UC-Browser heruntergeladene Videos in lokale Videos um? Viele Mobiltelefonbenutzer verwenden gerne den UC-Browser. Sie können nicht nur im Internet surfen, sondern auch verschiedene Videos und Fernsehprogramme online ansehen und ihre Lieblingsvideos auf ihr Mobiltelefon herunterladen. Eigentlich können wir heruntergeladene Videos in lokale Videos konvertieren, aber viele Leute wissen nicht, wie das geht. Daher stellt Ihnen der Editor speziell eine Methode zur Verfügung, mit der Sie die vom UC-Browser zwischengespeicherten Videos in lokale Videos konvertieren können. Methode zum Konvertieren von im UC-Browser zwischengespeicherten Videos in lokale Videos 1. Öffnen Sie den UC-Browser und klicken Sie auf die Option „Menü“. 2. Klicken Sie auf „Download/Video“. 3. Klicken Sie auf „Video zwischengespeichert“. 4. Drücken Sie lange auf ein beliebiges Video. Wenn die Optionen angezeigt werden, klicken Sie auf „Verzeichnis öffnen“. 5. Markieren Sie diejenigen, die Sie herunterladen möchten
