


GPT-4, das seit seiner Veröffentlichung als eines der leistungsstärksten Sprachmodelle der Welt gilt, hat leider eine Reihe von Vertrauenskrisen erlebt.
Die jüngsten Gerüchte, dass GPT-4 „faul“ geworden sei, werden noch interessanter, wenn wir den Vorfall mit der „intermittierenden Intelligenz“ Anfang dieses Jahres mit der Neugestaltung der GPT-4-Architektur durch OpenAI in Verbindung bringen. Jemand hat es getestet und festgestellt, dass GPT-4 faul wird, als ob es in den Ruhezustand übergegangen wäre, solange Sie GPT-4 sagen: „Es sind Winterferien“.
Um das Problem der schlechten Null-Stichproben-Leistung des Modells bei neuen Aufgaben zu lösen, können wir die folgenden Methoden anwenden: 1. Datenverbesserung: Erhöhen Sie die Generalisierungsfähigkeit des Modells durch Erweiterung und Transformation vorhandener Daten. Bilddaten können beispielsweise durch Drehung, Skalierung, Translation usw. oder durch Synthese neuer Datenproben verändert werden. 2. Lernen übertragen: Nutzen Sie Modelle, die für andere Aufgaben trainiert wurden, um ihre Parameter und ihr Wissen auf neue Aufgaben zu übertragen. Dies kann vorhandenes Wissen und Erfahrung nutzen, um die Leistung von GPT-4 zu verbessern. Kürzlich veröffentlichten Forscher der University of California, Santa Cruz, eine neue Entdeckung, die möglicherweise den tieferen Grund für die Leistungsverschlechterung von GPT-4 erklären kann .
 „Wir haben herausgefunden, dass LLM bei Datensätzen, die vor dem Erstellungsdatum der Trainingsdaten veröffentlicht wurden, überraschend besser abschneidet als bei Datensätzen, die danach veröffentlicht wurden.“
„Wir haben herausgefunden, dass LLM bei Datensätzen, die vor dem Erstellungsdatum der Trainingsdaten veröffentlicht wurden, überraschend besser abschneidet als bei Datensätzen, die danach veröffentlicht wurden.“
Man hat „gesehen“, dass sie bei Aufgaben gut und bei Aufgaben schlecht abschneiden neue Aufgaben. Das bedeutet, dass LLM lediglich eine Methode zur Nachahmung von Intelligenz ist, die auf ungefährem Abrufen basiert und hauptsächlich auf dem Auswendiglernen von Dingen ohne jegliches Verständnisniveau basiert.
Um es ganz klar auszudrücken: Die Generalisierungsfähigkeit von LLM ist „nicht so stark wie angegeben“ – das Fundament ist nicht solide und es wird im tatsächlichen Kampf immer Fehler geben.
Ein Hauptgrund für dieses Ergebnis ist die „Aufgabenverschmutzung“, eine Form der Datenverschmutzung. Die uns bekannte Datenverschmutzung ist die Testdatenverschmutzung, bei der es sich um die Aufnahme von Testdatenbeispielen und -bezeichnungen in die Daten vor dem Training handelt. Unter „Aufgabenkontamination“ versteht man das Hinzufügen von Beispielen für das Aufgabentraining zu den Daten vor dem Training, wodurch die Auswertung bei Methoden mit Null- oder wenigen Stichproben nicht mehr realistisch und effektiv ist.
Der Forscher führte in dem Artikel erstmals eine systematische Analyse des Problems der Datenverschmutzung durch:
 Link zum Artikel: https://arxiv.org/pdf/2312.16337.pdf
Link zum Artikel: https://arxiv.org/pdf/2312.16337.pdf
Nachdem ich das gelesen hatte, sagte jemand in der Zeitung „pessimistisch“:
Das ist das Schicksal aller Modelle des maschinellen Lernens (ML), die nicht über die Fähigkeit zum kontinuierlichen Lernen verfügen, d. h. Die Gewichte des ML-Modells werden nach dem Training eingefroren. Die Eingabeverteilung ändert sich jedoch weiterhin, und wenn sich das Modell nicht weiter an diese Änderung anpassen kann, verschlechtert es sich langsam.Das bedeutet, dass mit der ständigen Aktualisierung der Programmiersprachen auch LLM-basierte Codierungstools schlechter werden. Dies ist einer der Gründe, warum Sie sich nicht zu sehr auf ein so zerbrechliches Werkzeug verlassen müssen. Die kontinuierliche Umschulung dieser Modelle ist teuer und früher oder später wird jemand diese ineffizienten Methoden aufgeben.Derzeit gibt es keine ML-Modelle, die sich zuverlässig und kontinuierlich an sich ändernde Eingabeverteilungen anpassen können, ohne dass es zu schwerwiegenden Störungen oder Leistungseinbußen bei der vorherigen Codierungsaufgabe kommt.
Und das ist einer der Bereiche, in denen biologische neuronale Netze gut sind. Aufgrund der starken Generalisierungsfähigkeit biologischer neuronaler Netze kann das Erlernen verschiedener Aufgaben die Leistung des Systems weiter verbessern, da das aus einer Aufgabe gewonnene Wissen dazu beiträgt, den gesamten Lernprozess selbst zu verbessern, was als „Meta-Lernen“ bezeichnet wird.
Wie ernst ist das Problem der „Aufgabenverschmutzung“? Werfen wir einen Blick auf den Inhalt des Papiers.
Modelle und Datensätze
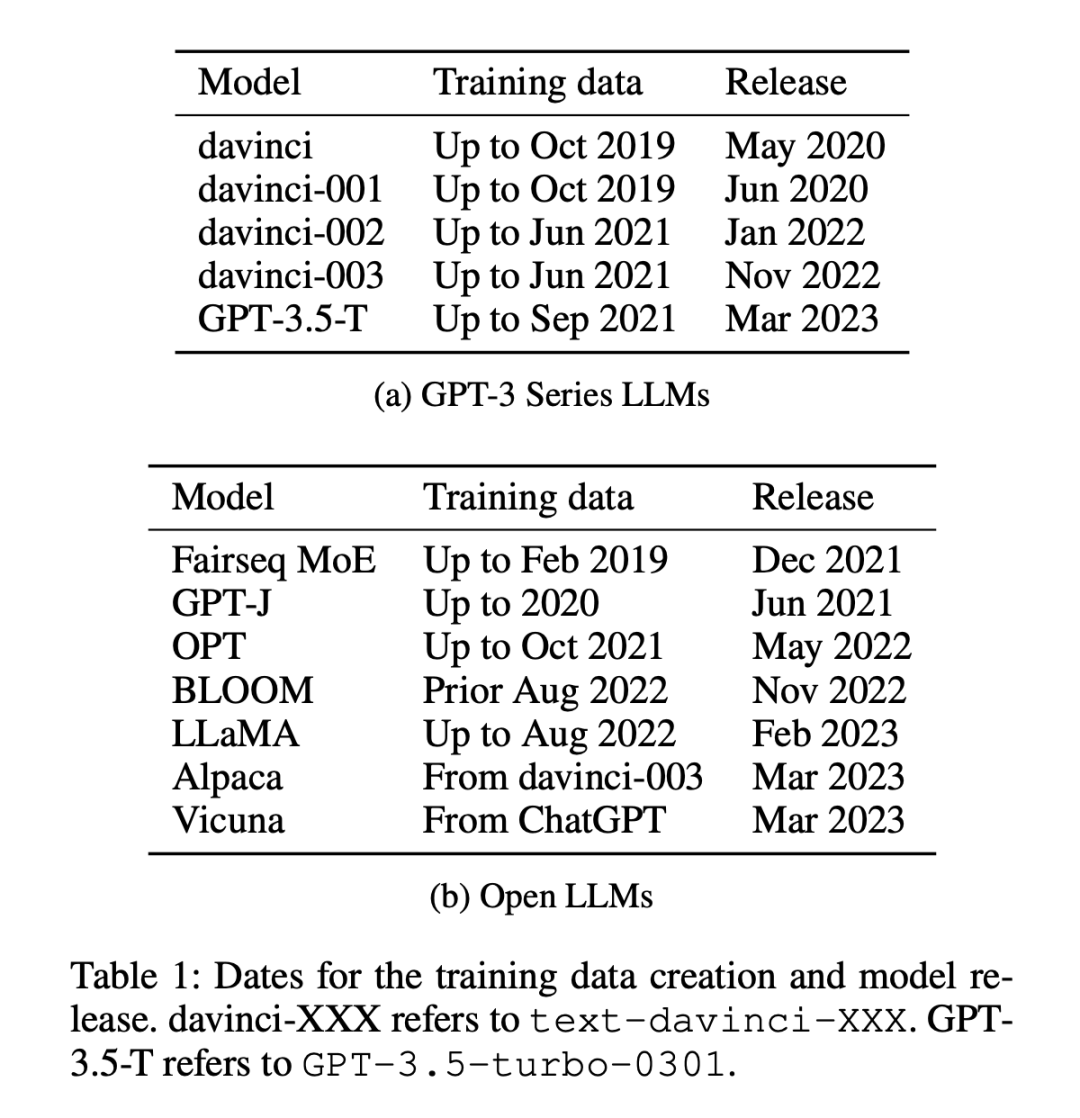
Datensätze werden in zwei Kategorien unterteilt: Datensätze, die vor oder nach dem 1. Januar 2021 veröffentlicht wurden. Forscher verwenden diese Aufteilungsmethode, um den Unterschied zwischen alten Datensätzen und neuen Datensätzen ohne Stichprobe zu analysieren Leistungsunterschiede bei wenigen Stichproben reduzieren und für alle LLMs die gleiche Partitionierungsmethode anwenden. In Tabelle 1 ist die Erstellungszeit der einzelnen Modelltrainingsdaten aufgeführt, und in Tabelle 2 ist das Veröffentlichungsdatum jedes Datensatzes aufgeführt.
Die Überlegung für den oben genannten Ansatz besteht darin, dass das Modell bei Zero-Shot- und Fence-Shot-Bewertungen Vorhersagen zu Aufgaben trifft, die es während des Trainings noch nie oder nur ein paar Mal gesehen hat. Die wichtigste Voraussetzung ist, dass das Modell zuvor keinem Kontakt ausgesetzt war die spezifische Aufgabe, die erledigt werden soll, und stellen so eine faire Beurteilung ihrer Lernfähigkeit sicher. Allerdings können fehlerhafte Modelle den Eindruck einer Kompetenz erwecken, der sie nicht oder nur ein paar Mal ausgesetzt waren, weil sie während des Vortrainings anhand von Aufgabenbeispielen trainiert wurden. In einem chronologischen Datensatz lassen sich solche Inkonsistenzen relativ einfacher erkennen, da etwaige Überschneidungen oder Anomalien offensichtlich sind.
Die Forscher verwendeten vier Methoden, um die „Aufgabenverschmutzung“ zu messen:
Die ersten drei Methoden haben eine hohe Präzision, aber eine niedrige Rückrufrate. Wenn Sie die Daten in den Trainingsdaten der Aufgabe finden, können Sie sicher sein, dass das Modell das Beispiel gesehen hat. Aufgrund von Änderungen in den Datenformaten, Änderungen in den Schlüsselwörtern, die zur Definition von Aufgaben verwendet werden, und der Größe der Datensätze ist die Tatsache, dass mit den ersten drei Methoden keine Hinweise auf eine Kontamination gefunden werden, jedoch kein Beweis dafür, dass keine Kontamination vorliegt.
Die vierte Methode, die chronologische Analyse, hat eine hohe Erinnerungsrate, aber eine geringe Präzision. Wenn die Leistung aufgrund einer Aufgabenkontamination hoch ist, besteht eine gute Chance, dies durch eine chronologische Analyse zu erkennen. Aber auch andere Faktoren können dazu führen, dass sich die Leistung mit der Zeit verbessert und daher weniger genau ist.
Daher verwendeten die Forscher alle vier Methoden, um eine Aufgabenkontamination zu erkennen, und fanden starke Hinweise auf eine Aufgabenkontamination in bestimmten Modell- und Datensatzkombinationen.
Sie führten zunächst eine Zeitanalyse für alle getesteten Modelle und Datensätze durch, da diese am wahrscheinlichsten war, um eine mögliche Kontamination zu erkennen. Anschließend nutzten sie die Inspektion von Trainingsdaten und die Extraktion von Aufgabenbeispielen, um weitere Hinweise auf eine Kontamination der Aufgabe zu finden Aufgaben und schließlich zusätzliche Analyse mithilfe von Mitgliedschaftsinferenzangriffen.
Die wichtigsten Schlussfolgerungen lauten wie folgt:
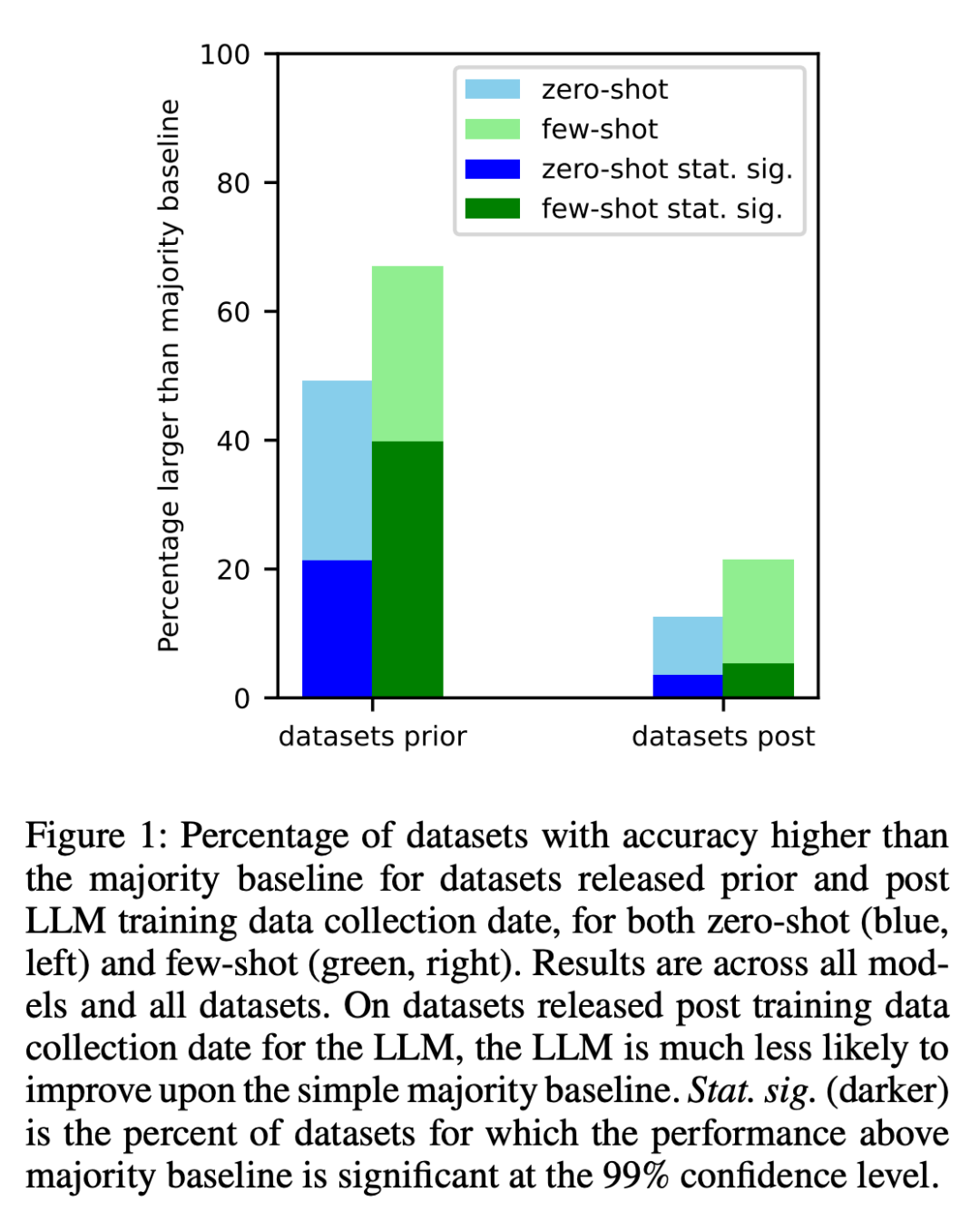
1 Die Forscher analysierten die Datensätze, die vor und nach dem Crawlen der Trainingsdaten jedes Modells im Internet erstellt wurden. Es wurde festgestellt, dass die Chancen, über den meisten Ausgangswerten zu liegen, bei Datensätzen, die vor der Erfassung der LLM-Trainingsdaten erstellt wurden, deutlich höher waren (Abbildung 1).
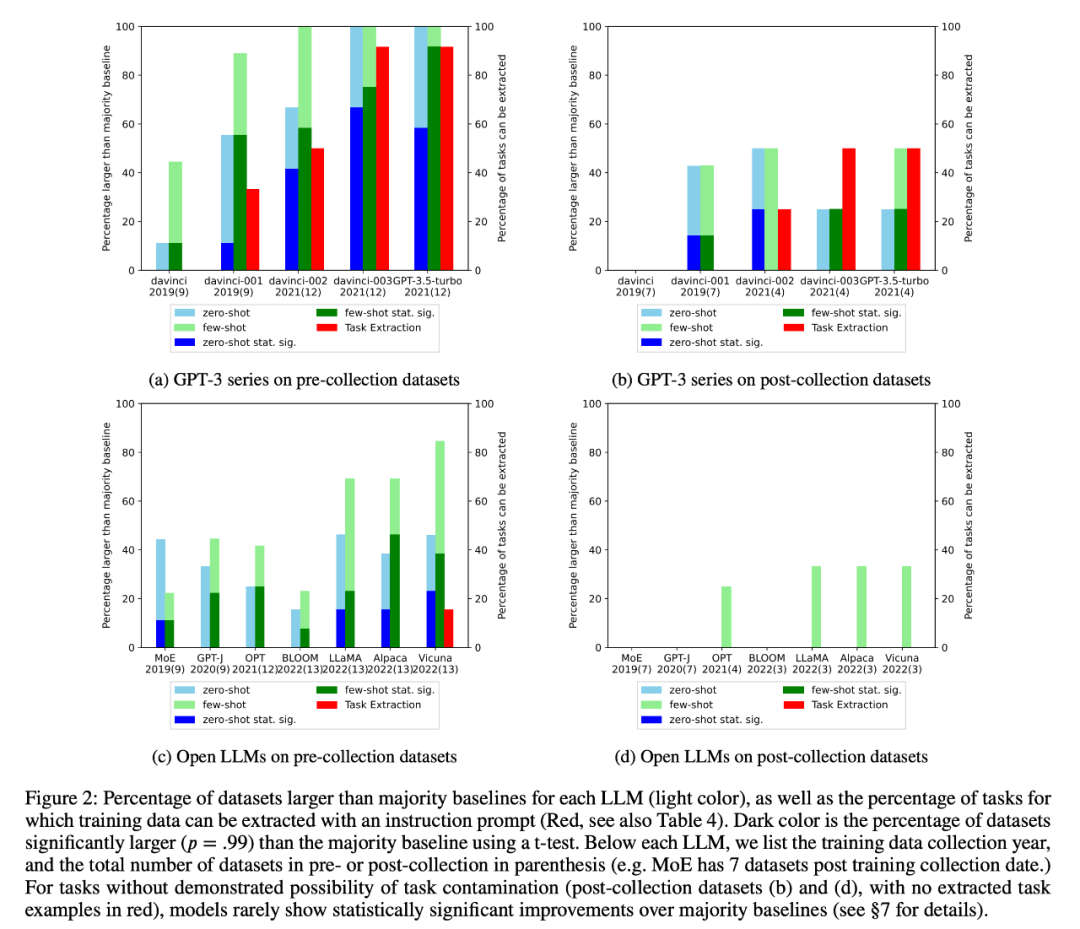
2 Der Forscher führte eine Inspektion der Trainingsdaten und eine Extraktion von Aufgabenbeispielen durch, um mögliche Aufgabenkontaminationen zu finden. Es wurde festgestellt, dass bei Klassifizierungsaufgaben, bei denen eine Aufgabenkontamination unwahrscheinlich ist, Modelle selten statistisch signifikante Verbesserungen gegenüber einfachen Mehrheitsbasislinien über eine Reihe von Aufgaben hinweg erzielen, unabhängig davon, ob es sich um Null- oder Wenig-Schuss-Aufgaben handelt (Abbildung 2).
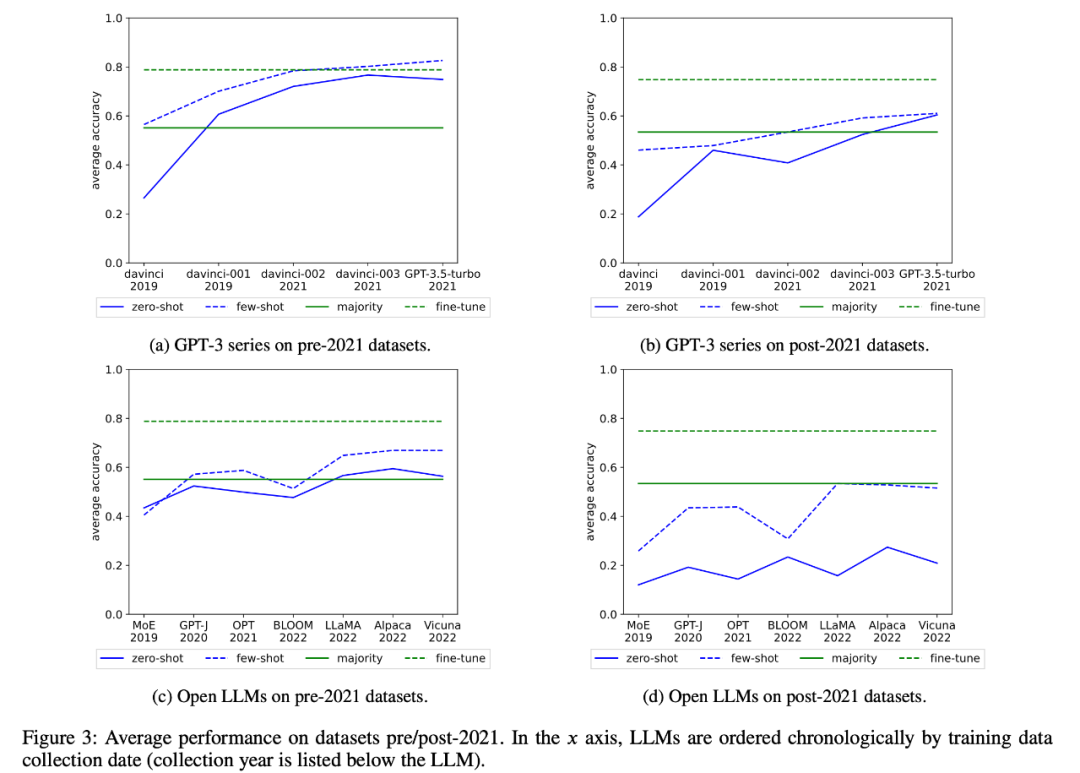
Die Forscher überprüften auch die durchschnittliche Leistung der GPT-3-Serie und des offenen LLM im Zeitverlauf, wie in Abbildung 3 dargestellt:
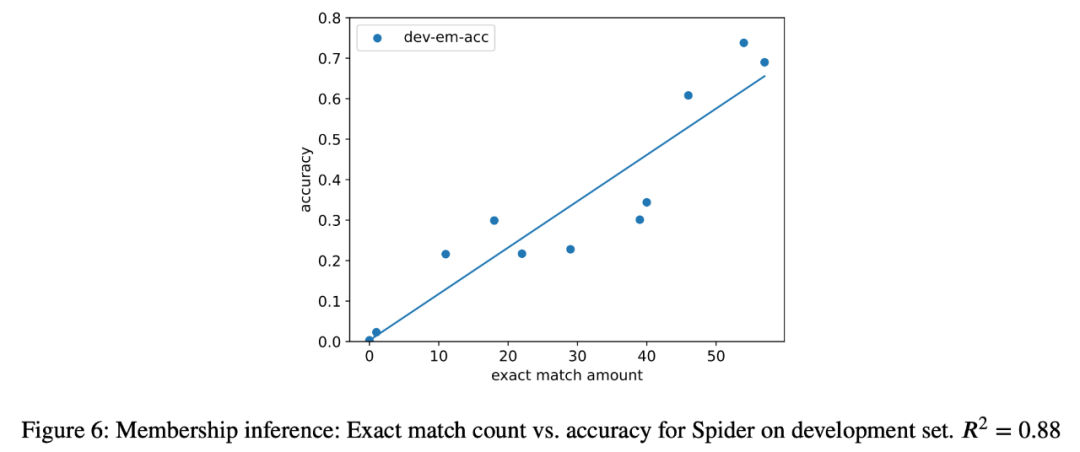
3. Die Forscher versuchten auch Member-Inferenzangriffe auf die semantische Parsing-Aufgabe bei allen Modellen in der Analyse und es wurde eine starke Korrelation (R=0,88) zwischen der Anzahl der extrahierten Instanzen und der Genauigkeit des Modells in der endgültigen Aufgabe festgestellt (Abbildung 6). ). Dies ist ein starker Beweis dafür, dass die Verbesserung der Nullschussleistung bei dieser Aufgabe auf eine Aufgabenkontamination zurückzuführen ist.
4. Die Forscher haben auch die Modelle der GPT-3-Serie sorgfältig untersucht und festgestellt, dass Trainingsbeispiele aus dem GPT-3-Modell extrahiert werden können, und in jeder Version von davinci bis GPT-3.5-turbo die Anzahl der Trainingsbeispiele, die sein können Die extrahierte Menge nimmt zu, was eng mit der Verbesserung der Zero-Shot-Leistung des GPT-3-Modells bei dieser Aufgabe zusammenhängt (Abbildung 2). Dies ist ein starker Beweis dafür, dass die Leistungsverbesserung der GPT-3-Modelle von Davinci bis GPT-3.5-Turbo bei diesen Aufgaben auf Aufgabenkontamination zurückzuführen ist.
Das obige ist der detaillierte Inhalt vonEine neue Interpretation des sinkenden Intelligenzniveaus von GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verbergen Sie die IP-Adresse
So verbergen Sie die IP-Adresse
 Der Unterschied zwischen Pfeilfunktionen und gewöhnlichen Funktionen
Der Unterschied zwischen Pfeilfunktionen und gewöhnlichen Funktionen
 So aktivieren Sie die gleiche Stadtfunktion auf Douyin
So aktivieren Sie die gleiche Stadtfunktion auf Douyin
 So öffnen Sie die Download-Berechtigung von Douyin
So öffnen Sie die Download-Berechtigung von Douyin
 So löschen Sie leere Seiten in Word
So löschen Sie leere Seiten in Word
 So übertragen Sie den Bildschirm vom Huawei-Mobiltelefon auf den Fernseher
So übertragen Sie den Bildschirm vom Huawei-Mobiltelefon auf den Fernseher
 So lösen Sie den HTTP-Status 404
So lösen Sie den HTTP-Status 404
 So stellen Sie mit vb eine Verbindung zur Datenbank her
So stellen Sie mit vb eine Verbindung zur Datenbank her








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



