


In diesem NeurIPS23-Artikel schlugen Forscher der Universität Leuven, der National University of Singapore und des Institute of Automation der Chinesischen Akademie der Wissenschaften eine visuelle „Gehirnlesetechnologie“ vor, die die menschliche Gehirnaktivität mit hoher Auflösung analysieren kann Bild, das Sie mit Ihren eigenen Augen sehen.
Auf dem Gebiet der kognitiven Neurowissenschaften erkennen die Menschen, dass die menschliche Wahrnehmung nicht nur durch objektive Reize, sondern auch stark durch vergangene Erfahrungen beeinflusst wird. Diese Faktoren wirken zusammen, um eine komplexe Aktivität im Gehirn zu erzeugen. Daher wird die Dekodierung visueller Informationen aus der Gehirnaktivität zu einer wichtigen Aufgabe. Unter diesen spielt die funktionelle Magnetresonanztomographie (fMRT) als effiziente nicht-invasive Technologie eine Schlüsselrolle bei der Wiederherstellung und Analyse visueller Informationen, insbesondere der Bildkategorien. Aufgrund der Rauscheigenschaften von fMRT-Signalen und des Gehirnsehens Aufgrund der Komplexität der Darstellung steht diese Aufgabe vor erheblichen Herausforderungen. Um dieses Problem anzugehen, schlägt dieser Artikel ein zweistufiges fMRI-Darstellungs-Lernrahmen vor, der darauf abzielt, Rauschen in der Gehirnaktivität zu identifizieren und zu entfernen, und sich auf die Analyse neuronaler Aktivierungsmuster konzentriert, die für die visuelle Rekonstruktion von entscheidender Bedeutung sind, um Bilder auf hoher Ebene aus dem Gehirn erfolgreich zu rekonstruieren Aktivität. Auflösung und semantisch genaue Bilder.
 Papierlink: https://arxiv.org/abs/2305.17214
Papierlink: https://arxiv.org/abs/2305.17214
Projektlink: https://github.com/soinx0629/vis_dec_neurips/
Die im Papier vorgeschlagene Methode basiert auf dualem kontrastivem Lernen , modellübergreifend Das Zustandsinformations-Crossover- und Diffusionsmodell hat im Vergleich zu den besten Vorgängermodellen eine Verbesserung der Bewertungsindikatoren für relevante fMRT-Datensätze um fast 40 % erzielt. Die Qualität, Lesbarkeit und semantische Relevanz der generierten Bilder sind allen bestehenden Methoden überlegen. Spürbare Verbesserung. Diese Arbeit hilft, den visuellen Wahrnehmungsmechanismus des menschlichen Gehirns zu verstehen und trägt zur Förderung der Forschung zur visuellen Gehirn-Computer-Schnittstellentechnologie bei. Die relevanten Codes waren Open Source.
Obwohl die funktionelle Magnetresonanztomographie (fMRT) häufig zur Analyse neuronaler Reaktionen eingesetzt wird, ist die genaue Rekonstruktion visueller Bilder aus ihren Daten immer noch eine Herausforderung, vor allem weil fMRT-Daten Rauschen aus mehreren Quellen enthalten, das neuronale Aktivierungsmuster maskieren und die Dekodierungsschwierigkeiten erhöhen kann. Darüber hinaus ist der durch visuelle Stimulation ausgelöste neuronale Reaktionsprozess komplex und mehrstufig, sodass das fMRT-Signal eine nichtlineare komplexe Überlagerung darstellt, die schwer umzukehren und zu dekodieren ist.
Herkömmliche neuronale Dekodierungsmethoden wie die Ridge-Regression werden zwar verwendet, um fMRT-Signale mit entsprechenden Reizen zu verknüpfen, sind jedoch häufig nicht in der Lage, die nichtlineare Beziehung zwischen Reizen und neuronalen Reaktionen effektiv zu erfassen. In jüngster Zeit wurden Deep-Learning-Techniken wie Generative Adversarial Networks (GANs) und Latent Diffusion Models (LDMs) eingesetzt, um diese komplexe Beziehung genauer zu modellieren. Allerdings bleibt es eine der größten Herausforderungen auf diesem Gebiet, die sehbezogene Gehirnaktivität vom Rauschen zu isolieren und sie genau zu entschlüsseln.
Um diese Herausforderungen anzugehen, schlägt diese Arbeit ein zweistufiges fMRI-Darstellungs-Lernrahmen vor, mit dem Rauschen in Gehirnaktivitäten effektiv identifiziert und entfernt werden kann und der sich auf die Analyse neuronaler Aktivierungsmuster konzentriert, die für die visuelle Rekonstruktion von entscheidender Bedeutung sind. Diese Methode generiert hochauflösende und semantisch genaue Bilder mit einer Top-1-Genauigkeit von 39,34 % für 50 Kategorien und übertrifft damit den aktuellen Stand der Technik.
Eine Methodenübersicht ist eine kurze Beschreibung einer Reihe von Schritten oder Prozessen. Es wird verwendet, um zu erklären, wie man ein bestimmtes Ziel erreicht oder eine bestimmte Aufgabe erledigt. Der Zweck einer Methodenübersicht besteht darin, dem Leser oder Benutzer ein Gesamtverständnis des gesamten Prozesses zu vermitteln, damit er die Schritte besser verstehen und befolgen kann. In einer Methodenübersicht geben Sie normalerweise die Abfolge der Schritte, die benötigten Materialien oder Werkzeuge sowie möglicherweise auftretende Probleme oder Herausforderungen an. Durch die klare und prägnante Beschreibung der Methodenübersicht kann der Leser oder Benutzer die erforderliche Aufgabe leichter verstehen und erfolgreich abschließen. DC-MAE)Um gemeinsame Gehirnaktivitätsmuster und individuelles Rauschen zwischen verschiedenen Personengruppen zu unterscheiden, stellt dieser Artikel die DC-MAE-Technologie vor, um fMRT-Darstellungen mithilfe unbeschrifteter Daten vorab zu trainieren. DC-MAE besteht aus einem Encoder  und einem Decoder
und einem Decoder  , wobei
, wobei  das maskierte fMRI-Signal als Eingabe verwendet und
das maskierte fMRI-Signal als Eingabe verwendet und  darauf trainiert wird, das unmaskierte fMRI-Signal vorherzusagen. Der sogenannte „Doppelkontrast“ bedeutet, dass das Modell den Kontrastverlust beim Lernen der fMRT-Darstellung optimiert und an zwei verschiedenen Kontrastprozessen teilnimmt.
darauf trainiert wird, das unmaskierte fMRI-Signal vorherzusagen. Der sogenannte „Doppelkontrast“ bedeutet, dass das Modell den Kontrastverlust beim Lernen der fMRT-Darstellung optimiert und an zwei verschiedenen Kontrastprozessen teilnimmt.
In der ersten Stufe des kontrastiven Lernens werden die Proben  in jeder Charge, die n fMRT-Proben v enthält, zufällig zweimal maskiert, wodurch zwei verschiedene maskierte Versionen
in jeder Charge, die n fMRT-Proben v enthält, zufällig zweimal maskiert, wodurch zwei verschiedene maskierte Versionen  und
und 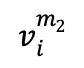 als positive Probenpaare zum Vergleich erzeugt werden. Anschließend konvertieren 1D-Faltungsschichten diese beiden Versionen in eingebettete Darstellungen, die jeweils in den fMRI-Encoder eingespeist werden. Der Decoder
als positive Probenpaare zum Vergleich erzeugt werden. Anschließend konvertieren 1D-Faltungsschichten diese beiden Versionen in eingebettete Darstellungen, die jeweils in den fMRI-Encoder eingespeist werden. Der Decoder  empfängt diese codierten latenten Darstellungen und erstellt Vorhersagen
empfängt diese codierten latenten Darstellungen und erstellt Vorhersagen  und
und  . Optimieren Sie das Modell durch den ersten von der InfoNCE-Verlustfunktion berechneten Kontrastverlust, d. h. den Kreuzkontrastverlust:
. Optimieren Sie das Modell durch den ersten von der InfoNCE-Verlustfunktion berechneten Kontrastverlust, d. h. den Kreuzkontrastverlust:

In der zweiten Stufe des kontrastiven Lernens bilden jedes demaskierte Originalbild  und sein entsprechendes maskiertes Bild
und sein entsprechendes maskiertes Bild 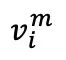 ein Paar natürlicher positiver Proben. Das
ein Paar natürlicher positiver Proben. Das 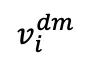 hier stellt das vom Decoder vorhergesagte Bild dar . Der zweite Kontrastverlust, der Eigenkontrastverlust, wird nach folgender Formel berechnet:
hier stellt das vom Decoder vorhergesagte Bild dar . Der zweite Kontrastverlust, der Eigenkontrastverlust, wird nach folgender Formel berechnet:

Durch die Optimierung des Eigenkontrastverlusts kann eine Okklusionsrekonstruktion erreicht werden. Unabhängig davon, ob es sich um
kann eine Okklusionsrekonstruktion erreicht werden. Unabhängig davon, ob es sich um  oder
oder  handelt, stammt die negative Probe
handelt, stammt die negative Probe  aus derselben Charge von Instanzen.
aus derselben Charge von Instanzen.  und werden gemeinsam wie folgt optimiert:
und werden gemeinsam wie folgt optimiert:  , wobei die Hyperparameter
, wobei die Hyperparameter  und
und  verwendet werden, um das Gewicht jedes Verlustterms anzupassen.
verwendet werden, um das Gewicht jedes Verlustterms anzupassen.
Zweite Stufe: Abstimmung mithilfe modalübergreifender Anleitung
Angesichts des niedrigen Signal-Rausch-Verhältnisses und der stark faltbaren Natur von fMRT-Aufzeichnungen ist es für Lernende von fMRT-Funktionen wichtig, sich auf diejenigen zu konzentrieren, die für die visuelle Verarbeitung am relevantesten sind Und es ist entscheidend, das aussagekräftigste Gehirnaktivierungsmuster zu rekonstruieren
Nach der ersten Stufe des Vortrainings wird der fMRI-Autoencoder mit Bildunterstützung angepasst, um eine fMRT-Rekonstruktion zu erreichen, und auch die zweite Stufe folgt diesem Prozess. Konkret werden eine Probe  und die entsprechende fMRT-aufgezeichnete neuronale Reaktion
und die entsprechende fMRT-aufgezeichnete neuronale Reaktion  aus einer Charge von n Proben ausgewählt.
aus einer Charge von n Proben ausgewählt.  und
und  werden durch Blockieren und zufällige Maskierung verarbeitet, in
werden durch Blockieren und zufällige Maskierung verarbeitet, in  bzw.
bzw.  umgewandelt und dann in den Bild-Encoder
umgewandelt und dann in den Bild-Encoder  bzw. fMRI-Encoder eingegeben, um
bzw. fMRI-Encoder eingegeben, um  und
und  zu erzeugen. Um fMRI
zu erzeugen. Um fMRI zu rekonstruieren, wird das Queraufmerksamkeitsmodul verwendet, um
zu rekonstruieren, wird das Queraufmerksamkeitsmodul verwendet, um  und
und  zusammenzuführen:
zusammenzuführen:

W und b repräsentieren das Gewicht bzw. die Vorspannung der entsprechenden linearen Schicht.  ist der Skalierungsfaktor und
ist der Skalierungsfaktor und  ist die Dimension des Schlüsselvektors. CA ist die Abkürzung für Cross-Attention. Nachdem
ist die Dimension des Schlüsselvektors. CA ist die Abkürzung für Cross-Attention. Nachdem  zu
zu  hinzugefügt wurde, wird es in den fMRI-Decoder eingegeben, um
hinzugefügt wurde, wird es in den fMRI-Decoder eingegeben, um  zu rekonstruieren, und wir erhalten
zu rekonstruieren, und wir erhalten  :
:

Ähnliche Berechnungen werden auch im Bild-Autoencoder durchgeführt und die Ausgabe  des Bild-Encoders
des Bild-Encoders  wird mit kombiniert das Cross-Attention-Modul
wird mit kombiniert das Cross-Attention-Modul  Die Ausgaben von werden kombiniert und dann zum Dekodieren des Bildes
Die Ausgaben von werden kombiniert und dann zum Dekodieren des Bildes  verwendet, was
verwendet, was  ergibt:
ergibt: 
fMRI und Bild-Autoencoder werden gemeinsam trainiert, indem die folgende Verlustfunktion optimiert wird:

Beim Erzeugen von Bildern Es kann ein latentes Diffusionsmodell verwendet werden (LDM)

Nach Abschluss der ersten und zweiten Stufe des FRL-Trainings verwenden Sie den fMRI-Funktions-Lernencoder , um ein latentes Diffusionsmodell (LDM) zu steuern, um Bilder aus der Gehirnaktivität zu generieren. Wie in der Abbildung gezeigt, umfasst das Diffusionsmodell einen Vorwärtsdiffusionsprozess und einen Rückwärtsdiffusionsprozess. Der Vorwärtsprozess degradiert das Bild schrittweise in normales Gaußsches Rauschen, indem nach und nach Gaußsches Rauschen mit unterschiedlicher Varianz eingeführt wird.
Diese Studie generiert Bilder, indem visuelles Wissen aus einem vorab trainierten Label-to-Image-Latent-Diffusionsmodell (LDM) extrahiert und fMRT-Daten als Bedingung verwendet wird. Hier wird ein Cross-Attention-Mechanismus eingesetzt, um fMRI-Informationen in LDM zu integrieren, basierend auf Empfehlungen aus stabilen Diffusionsstudien. Um die Rolle bedingter Informationen zu stärken, werden hier die Methoden der Kreuzaufmerksamkeit und der Zeitschrittkonditionierung eingesetzt. In der Trainingsphase werden der VQGAN-Encoder  und der durch die erste und zweite Stufe von FRL trainierte fMRI-Encoder verwendet, um das Bild u und fMRI v zu verarbeiten, und der fMRI-Encoder wird feinabgestimmt, während der LDM unverändert bleibt Die Funktion lautet:
und der durch die erste und zweite Stufe von FRL trainierte fMRI-Encoder verwendet, um das Bild u und fMRI v zu verarbeiten, und der fMRI-Encoder wird feinabgestimmt, während der LDM unverändert bleibt Die Funktion lautet: 
wobei  das Rauschschema des Diffusionsmodells ist. In der Inferenzphase beginnt der Prozess mit Standard-Gauß-Rauschen im Zeitschritt T, und das LDM folgt sequentiell dem umgekehrten Prozess, um das Rauschen der verborgenen Darstellung schrittweise zu entfernen, abhängig von den gegebenen fMRI-Informationen. Wenn der Zeitschritt Null erreicht ist, wird die verborgene Darstellung mithilfe des VQGAN-Decoders
das Rauschschema des Diffusionsmodells ist. In der Inferenzphase beginnt der Prozess mit Standard-Gauß-Rauschen im Zeitschritt T, und das LDM folgt sequentiell dem umgekehrten Prozess, um das Rauschen der verborgenen Darstellung schrittweise zu entfernen, abhängig von den gegebenen fMRI-Informationen. Wenn der Zeitschritt Null erreicht ist, wird die verborgene Darstellung mithilfe des VQGAN-Decoders  in ein Bild umgewandelt.
in ein Bild umgewandelt.
Experiment
Rekonstruktionsergebnisse

Durch den Vergleich mit früheren Studien wie DC-LDM, IC-GAN und SS-AE und in der Auswertung von GOD- und BOLD5000-Datensätzen zeigt diese Studie, dass die Das vorgeschlagene Modell übertrifft diese Modelle in der Genauigkeit deutlich, mit einer Verbesserung von 39,34 % bzw. 66,7 % im Vergleich zu DC-LDM bzw. IC-GAN. Die Auswertung an vier anderen Themen des GOD-Datensatzes zeigt, dass dies auch bei DC-LDM der Fall ist Das in dieser Studie vorgeschlagene Modell kann am Testsatz angepasst werden und ist hinsichtlich der Top-1-Klassifizierungsgenauigkeit von 50 Punkten deutlich besser als DC-LDM, was beweist, dass das vorgeschlagene Modell bei verschiedenen Themen zuverlässig und überlegen ist ' Gehirnaktivität.
Die Forschungsergebnisse zeigen, dass die Verwendung des vorgeschlagenen Lernrahmens für die fMRI-Darstellung und des vorab trainierten LDM die visuelle Aktivität des Gehirns besser rekonstruieren kann und weit über das aktuelle Ausgangsniveau hinausgeht. Diese Arbeit trägt dazu bei, das Potenzial neuronaler Dekodierungsmodelle weiter zu erforschen
Das obige ist der detaillierte Inhalt vonNeurIPS23 |. „Brain Reading' entschlüsselt die Gehirnaktivität und rekonstruiert die visuelle Welt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So ändern Sie devc++ auf Chinesisch
So ändern Sie devc++ auf Chinesisch
 Sonst-Verwendung in der Python-Schleifenstruktur
Sonst-Verwendung in der Python-Schleifenstruktur
 Der Unterschied zwischen Ankern und Zielen
Der Unterschied zwischen Ankern und Zielen
 Verwendung der isnumber-Funktion
Verwendung der isnumber-Funktion
 Was sind die häufigsten Tomcat-Schwachstellen?
Was sind die häufigsten Tomcat-Schwachstellen?
 Lösung außerhalb des zulässigen Bereichs
Lösung außerhalb des zulässigen Bereichs
 So gleichen Sie Zahlen in regulären Ausdrücken ab
So gleichen Sie Zahlen in regulären Ausdrücken ab
 Was ist der Handel mit digitalen Währungen?
Was ist der Handel mit digitalen Währungen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



