Heutzutage wird die gesamte Hausarbeit von Robotern übernommen.
Der Roboter aus Stanford, der Töpfe benutzen kann, ist gerade aufgetaucht, und der Roboter, der Kaffeemaschinen bedienen kann, ist gerade angekommen, Abbildung-01.

Abbildung-01 Schauen Sie sich einfach das Demonstrationsvideo an und führen Sie eine 10-stündige Schulung durch, um die Kaffeemaschine kompetent bedienen zu können. Vom Einlegen der Kaffeekapsel bis zum Drücken der Starttaste ist alles in einem Rutsch erledigt.
Allerdings ist es ein schwieriges Problem, einem Roboter zu ermöglichen, selbstständig den Umgang mit verschiedenen Möbeln und Haushaltsgeräten zu erlernen, ohne dass Demonstrationsvideos erforderlich sind, wenn er ihnen begegnet. Dies erfordert vom Roboter eine starke visuelle Wahrnehmung und Entscheidungsplanungsfähigkeiten sowie präzise Manipulationsfähigkeiten.
Jetzt liefert ein dreidimensionales verkörpertes Grafik- und Text-Großmodellsystem neue Ideen für die oben genannten Probleme. Das System kombiniert ein präzises geometrisches Wahrnehmungsmodell, das auf dreidimensionalem Sehen basiert, mit einem zweidimensionalen Grafik- und Textgroßmodell, das sich gut planen lässt. Es kann komplexe langfristige Aufgaben im Zusammenhang mit Möbeln und Haushaltsgeräten lösen, ohne dass Musterdaten erforderlich sind . Diese Forschung wurde vom Team von Professor Leonidas Guibas von der Stanford University, Professor Wang He von der Peking University und dem Zhiyuan Artificial Intelligence Research Institute durchgeführt.
Papierlink: https://arxiv.org/abs/2312.01307
Projekthomepage: https://geometry.stanford.edu/projects/sage/
Code: https://github.com/ geng-haoran/SAGE
Überblick über das Forschungsproblem
Abbildung 1: Nach menschlicher Anweisung kann der Roboterarm verschiedene Haushaltsgeräte ohne Anweisung bedienen.
Kürzlich haben PaLM-E und GPT-4V die Anwendung großer Grafikmodelle bei der Planung von Roboteraufgaben gefördert, und die durch visuelle Sprache gesteuerte allgemeine Robotersteuerung ist zu einem beliebten Forschungsgebiet geworden.
Eine gängige Methode in der Vergangenheit bestand darin, ein zweischichtiges System aufzubauen. Das große Grafikmodell der oberen Schicht übernimmt die Planung und Fähigkeitsplanung, und das Steuerungsstrategiemodell der unteren Schicht ist für die physische Ausführung von Aktionen verantwortlich. Wenn Roboter jedoch mit einer Vielzahl von Haushaltsgeräten konfrontiert werden, die sie noch nie zuvor gesehen haben und bei der Hausarbeit mehrstufige Vorgänge erfordern, sind sowohl die obere als auch die untere Ebene der vorhandenen Methoden hilflos.
Nehmen Sie als Beispiel das fortschrittlichste Grafikmodell GPT-4V. Obwohl es ein einzelnes Bild mit Text beschreiben kann, ist es immer noch voller Fehler, wenn es um die Erkennung, Zählung, Positionierung und Statusschätzung betriebsbereiter Teile geht. Die roten Markierungen in Abbildung 2 sind die verschiedenen Fehler, die GPT-4V bei der Beschreibung von Bildern von Kommoden, Öfen und Standschränken gemacht hat. Aufgrund der falschen Beschreibung ist die Fähigkeitsplanung des Roboters offensichtlich unzuverlässig. Abbildung 2: GP
Das Strategiemodell für Kontrollfähigkeiten der unteren Ebene ist für die Ausführung der Aufgaben verantwortlich, die vom Grafik- und Textmodell der oberen Ebene in verschiedenen tatsächlichen Situationen vorgegeben werden. Die meisten vorhandenen Forschungsergebnisse kodieren die Greifpunkte und Betriebsmethoden einiger bekannter Objekte auf der Grundlage von Regeln starr und können im Allgemeinen nicht mit neuen Objektkategorien umgehen, die zuvor noch nicht gesehen wurden. End-to-End-Betriebsmodelle (wie RT-1, RT-2 usw.) verwenden jedoch nur die RGB-Modalität, haben keine genaue Wahrnehmung der Entfernung und lassen sich schlecht auf Änderungen in neuen Umgebungen wie der Höhe verallgemeinern.
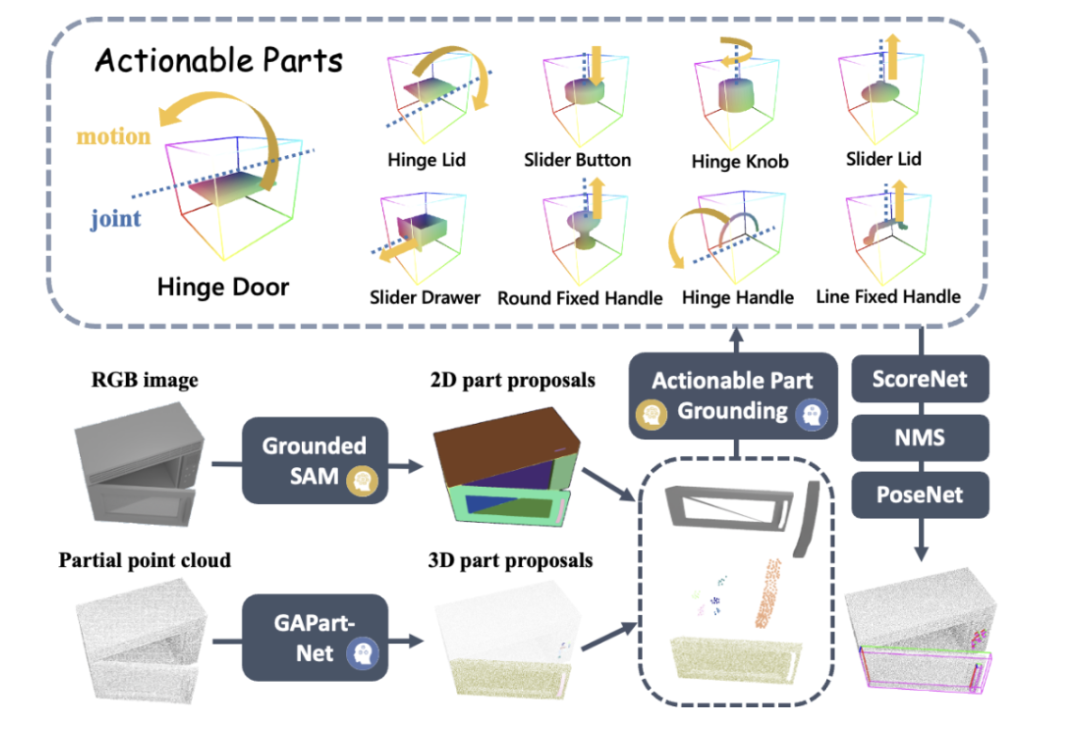
Inspiriert durch die frühere CVPR-Highlight-Arbeit GAPartNet [1] des Teams von Professor Wang He konzentrierte sich das Forschungsteam auf gemeinsame Teile (GAParts) in verschiedenen Kategorien von Haushaltsgeräten. Obwohl sich Haushaltsgeräte ständig ändern, gibt es immer einige Teile, die unverzichtbar sind. Zwischen jedem Haushaltsgerät und diesen gemeinsamen Teilen bestehen ähnliche Geometrien und Interaktionsmuster. Als Ergebnis stellte das Forschungsteam das Konzept von GAPart in der Arbeit GAPartNet [1] vor. GAPart bezieht sich auf eine generalisierbare und interaktive Komponente. GAPart erscheint auf verschiedenen Kategorien von aufklappbaren Objekten. Beispielsweise finden sich aufklappbare Türen in Tresoren, Kleiderschränken und Kühlschränken. Wie in Abbildung 3 dargestellt, kommentiert GAPartNet [1] die Semantik und Pose von GAPart für verschiedene Objekttypen. Abbildung 3: GAPart: generalisierbare und interaktive Teile [1].
Basierend auf früheren Forschungen führte das Forschungsteam auf kreative Weise GAPart basierend auf dreidimensionalem Sehen in das Objektmanipulationssystem SAGE des Roboters ein. SAGE wird Informationen für VLM und LLM durch verallgemeinerbare 3D-Teileerkennung und genaue Posenschätzung bereitstellen. Auf der Entscheidungsebene löst die neue Methode das Problem unzureichender präziser Berechnungs- und Argumentationsfunktionen des zweidimensionalen Grafikmodells. Auf der Ausführungsebene erreicht die neue Methode verallgemeinerte Operationen für jeden Teil durch eine robuste API für physikalische Operationen GAPart-Posen.
SAGE stellt das erste dreidimensionale verkörperte Grafik- und Text-Großmodellsystem dar, das neue Ideen für die gesamte Verbindung von Robotern von der Wahrnehmung über die physische Interaktion bis hin zum Feedback liefert und neue Wege für Roboter erforscht, komplexe Objekte wie z B. Möbel und Haushaltsgeräte.
Systemeinführung
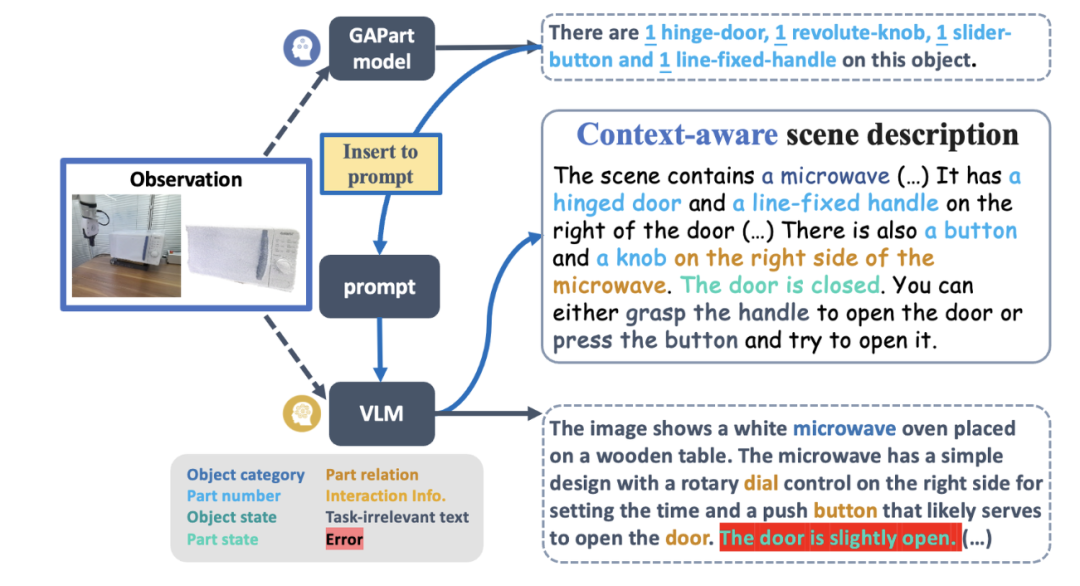
Abbildung 4 zeigt den grundlegenden Prozess von SAGE. Zunächst analysiert ein Befehlsinterpretationsmodul, das den Kontext interpretieren kann, die in den Roboter eingegebenen Anweisungen und seine Beobachtungen und wandelt diese Analysen in das nächste Roboteraktionsprogramm und die zugehörigen semantischen Teile um. Als nächstes ordnet SAGE den semantischen Teil (z. B. den Container) dem Teil zu, der bedient werden muss (z. B. die Schiebeschaltfläche) und generiert Aktionen (z. B. die Aktion „Drücken“ der Schaltfläche), um die Aufgabe abzuschließen.
Abbildung 4: Methodenübersicht.
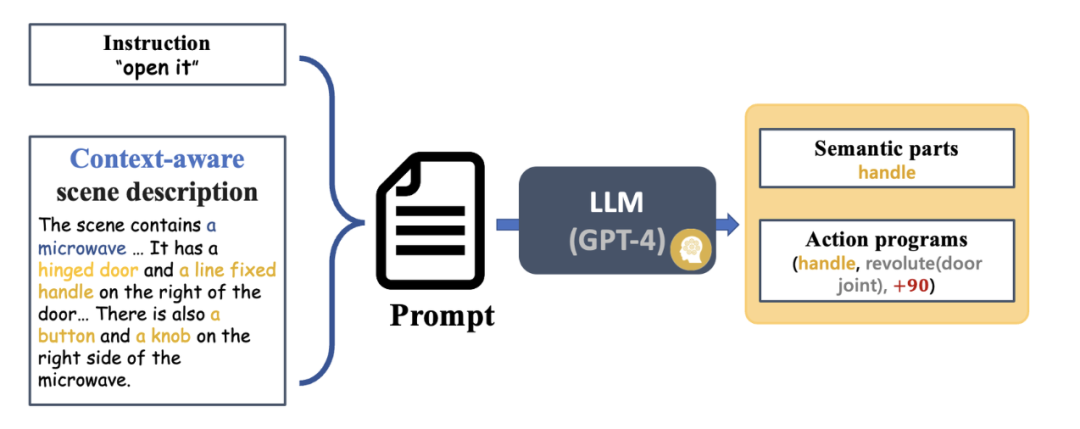
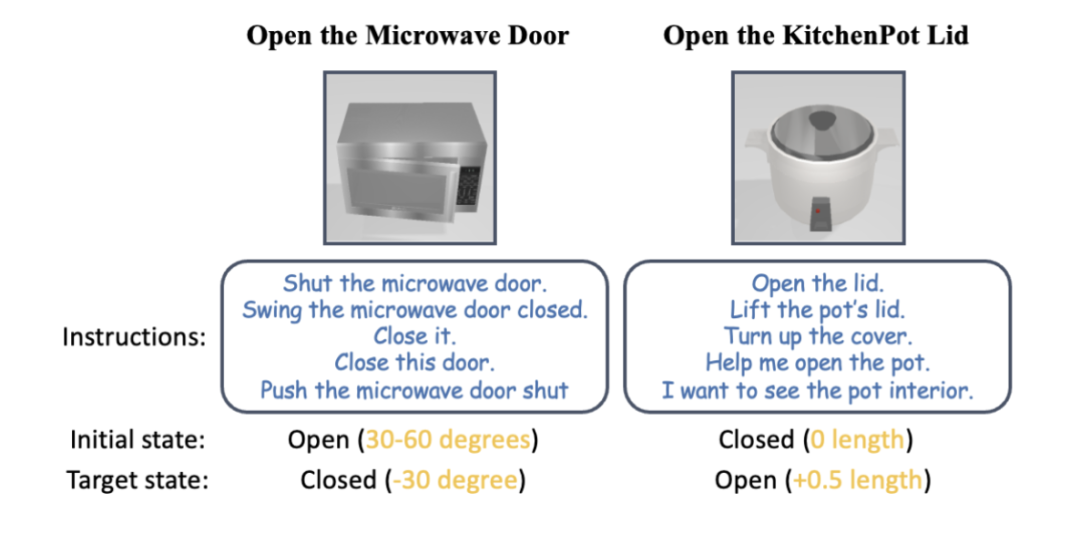
Um es für alle einfacher zu machen, den gesamten Systemprozess zu verstehen, schauen wir uns ein Beispiel an, wie ein Roboterarm einen unsichtbaren Mikrowellenherd bedient, ohne dass eine Probe erforderlich ist. Anweisungsanalyse: von visuellen und Anweisungseingaben bis hin zu ausführbaren Fertigkeitsanweisungen Nach der Eingabe von Anweisungen und RGBD-Bildbeobachtungen generiert der Interpreter zunächst eine Szenenbeschreibung mithilfe von VLM und GAPartNet [1]. Anschließend verwendet LLM (GPT-4) Anweisungen und Szenenbeschreibungen als Eingabe, um semantische Teile und Aktionsprogramme zu generieren. Alternativ können Sie unter diesem Link auch eine konkrete Bedienungsanleitung hinterlegen. LLM generiert basierend auf der Eingabe ein betriebsfähiges Teilziel. Abbildung 5: Generierung der Szenenbeschreibung (Zero-Shot am Beispiel einer Mikrowelle). Um die Aktionsgenerierung besser zu unterstützen, enthält die Szenenbeschreibung Objektinformationen, Teilinformationen und einige interaktionsbezogene Informationen. Vor der Erstellung der Szenariobeschreibung verwendet SAGE außerdem das Experten-GAPart-Modell [1], um Expertenbeschreibungen für VLM als Eingabeaufforderungen zu generieren. Dieser Ansatz, der das Beste beider Modelle vereint, funktioniert gut. Abbildung 6: Instruktionsverständnis und Bewegungsplanung (am Beispiel der Zero-Shot-Nutzung eines Mikrowellenherds). Verständnis und Wahrnehmung von Teilinteraktionsinformationen Abbildung 7: Teilverständnis. Bei der Eingabe von Beobachtungen kombiniert SAGE zweidimensionale (2D) Hinweise von GroundedSAM und dreidimensionale (3D) Hinweise von GAPartNet, die dann als spezifische Positionierung bedienbarer Teile verwendet werden. Das Forschungsteam nutzte ScoreNet, Non-Maximum Suppression (NMS) und PoseNet, um die Wahrnehmungsergebnisse der neuen Methode zu demonstrieren. Unter ihnen: (1) Für den teilbewussten Bewertungsbenchmark verwendet der Artikel direkt SAM [2]. Im operativen Ablauf verwendet der Artikel jedoch GroundedSAM, das auch semantische Teile als Eingabe berücksichtigt. (2) Wenn das große Sprachmodell (LLM) ein Ziel eines bedienbaren Teils direkt ausgibt, wird der Positionierungsprozess umgangen. Abbildung 8: Teileverständnis (am Beispiel eines Zero-Shot-Mikrowellenherds). Sobald der semantische Teil über dem bedienbaren Teil positioniert ist, generiert SAGE ausführbare Operationsaktionen für diesen Teil. Zunächst schätzt SAGE die Pose des Teils und berechnet den Artikulationszustand (Achse und Position des Teils) sowie mögliche Bewegungsrichtungen basierend auf dem Artikulationstyp (Translation oder Rotation). Basierend auf diesen Schätzungen werden dann Bewegungen für den Roboter generiert, um das Teil zu bedienen. Bei der Aufgabe, den Mikrowellenherd zu starten, sagte SAGE zunächst voraus, dass der Roboterarm als Hauptaktion eine anfängliche Greifhaltung einnehmen sollte. Anschließend werden Aktionen basierend auf der in GAPartNet [1] definierten vorgegebenen Strategie generiert. Diese Strategie wird basierend auf der Teilhaltung und dem Artikulationsstatus bestimmt. Um beispielsweise eine Tür mit Drehscharnier zu öffnen, könnte die Ausgangsposition an der Türkante oder am Griff liegen, wobei die Bewegungsbahn ein entlang des Türscharniers ausgerichteter Bogen ist. Bisher hat das Forschungsteam nur eine erste Beobachtung verwendet, um Open-Loop-Interaktionen zu generieren. Zu diesem Zeitpunkt führten sie einen Mechanismus ein, um die während der Interaktion gewonnenen Beobachtungen weiter zu nutzen, die wahrgenommenen Ergebnisse zu aktualisieren und die Abläufe entsprechend anzupassen. Um dieses Ziel zu erreichen, führte das Forschungsteam einen zweiteiligen Feedback-Mechanismus in den Interaktionsprozess ein. Es ist zu beachten, dass es beim Wahrnehmungsprozess der ersten Beobachtung zu Okklusions- und Schätzfehlern kommen kann. Abbildung 9: Die Tür kann nicht direkt geöffnet werden und diese Interaktionsrunde schlägt fehl (nehmen Sie Zero-Shot am Beispiel eines Mikrowellenherds). Um diese Probleme zu lösen, schlugen Forscher außerdem ein Modell vor, das interaktive Beobachtung (interaktive Wahrnehmung) nutzt, um den Betrieb zu verbessern. Die Verfolgung des Zielgreifers und des Teilestatus wird während der gesamten Interaktion aufrechterhalten.Bei erheblichen Abweichungen kann der Planer einen von vier Zuständen wählen: „Weiter“, „Mit nächstem Schritt fortfahren“, „Stoppen und neu planen“ oder „Erfolgreich“. Wenn Sie beispielsweise den Greifer so einstellen, dass er sich entlang einer Verbindung um 60 Grad dreht, die Tür jedoch nur 15 Grad geöffnet ist, wählt der LLM-Planer (Large Language Model) „Stoppen und neu planen“. Dieses interaktive Tracking-Modell stellt sicher, dass LLM spezifische Probleme während des Interaktionsprozesses analysieren und nach dem Rückschlag durch den Startfehler des Mikrowellenherds wieder „aufstehen“ kann. Abbildung 10: Durch interaktives Feedback und Neuplanung erkennt der Roboter den Weg zum Öffnen des Knopfes und schafft es. Das Forschungsteam erstellte zunächst einen groß angelegten Benchmark für sprachgesteuerte Interaktionstests mit artikulierten Objekten.
Abbildung 11: SAPIEN-Simulationsexperiment.
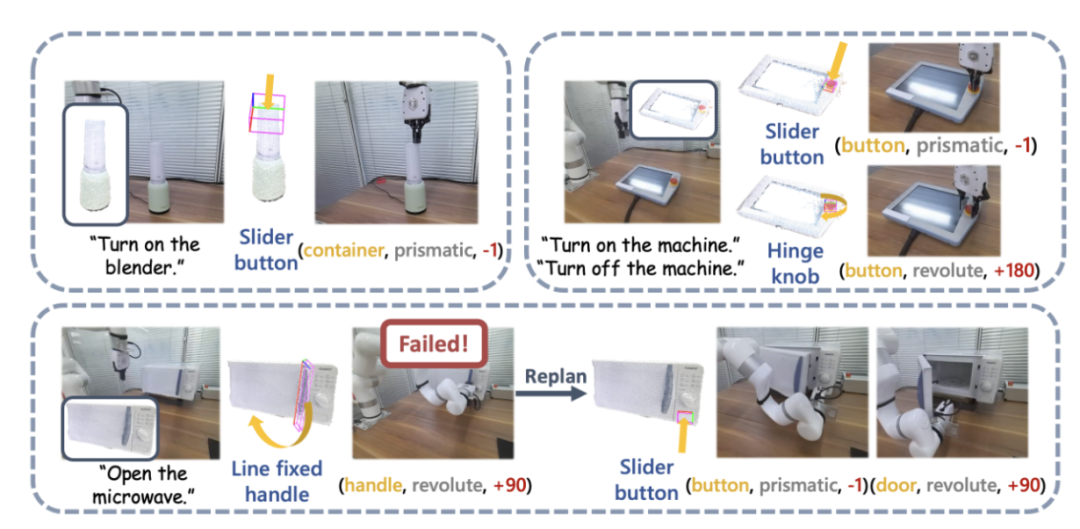
Sie nutzten die SAPIEN-Umgebung [4] zur Durchführung von Simulationsexperimenten und entwarfen 12 sprachgesteuerte Aufgaben zur Manipulation artikulierter Objekte. Für jede Kategorie von Mikrowellenherden, Aufbewahrungsmöbeln und Schränken wurden drei Aufgaben entworfen, darunter offene und geschlossene Zustände in unterschiedlichen Ausgangszuständen. Weitere Aufgaben sind „Topfdeckel öffnen“, „Taste auf der Fernbedienung drücken“ und „Mixer starten“. Experimentelle Ergebnisse zeigen, dass SAGE bei fast allen Aufgaben gute Leistungen erbringt. Abbildung 12: Demonstration einer realen Maschine. Das Forschungsteam führte außerdem groß angelegte Experimente in der realen Welt mit UFACTORY xArm 6 und einer Vielzahl unterschiedlicher Gelenkobjekte durch. Der obere linke Teil des Bildes oben zeigt ein Beispiel für das Starten eines Mixers. Die Oberseite des Mixers wird als Behälter für Saft wahrgenommen, seine eigentliche Funktion erfordert jedoch einen Knopfdruck, um ihn zu aktivieren. Das SAGE-Framework verbindet effektiv sein Semantik- und Aktionsverständnis und führt die Aufgabe erfolgreich aus. Der obere rechte Teil des Bildes oben zeigt den Roboter, der den Not-Aus-Knopf drücken (unten) muss, um den Betrieb zu stoppen, und sich drehen (oben) muss, um neu zu starten. Ein von SAGE geführter Roboterarm erledigte beide Aufgaben mit Hilfseingaben aus einem Benutzerhandbuch. Das Bild unten im Bild oben zeigt detaillierter die Aufgabe, eine Mikrowelle einzuschalten.
Abbildung 13: Weitere Beispiele für die Demonstration realer Maschinen und die Befehlsinterpretation.
Zusammenfassung
SAGE ist das erste visuelle 3D-Sprachmodell-Framework, das allgemeine Manipulationsanweisungen für komplexe artikulierte Objekte wie Möbel und Haushaltsgeräte generieren kann. Es wandelt sprachgesteuerte Aktionen in ausführbare Manipulationen um, indem es Objektsemantik und Bedienbarkeitsverständnis auf Teileebene verbindet.
Darüber hinaus untersucht der Artikel auch Methoden zur Kombination allgemeiner großräumiger Visions-/Sprachmodelle mit Domänenexpertenmodellen, um die Vollständigkeit und Korrektheit von Netzwerkvorhersagen zu verbessern, diese Aufgaben besser zu bewältigen und den neuesten Stand der Technik zu erreichen. Kunstperformance. Experimentelle Ergebnisse zeigen, dass das Framework über starke Generalisierungsfähigkeiten verfügt und eine überlegene Leistung bei verschiedenen Objektkategorien und Aufgaben zeigen kann. Darüber hinaus bietet der Artikel einen neuen Maßstab für die sprachgesteuerte Manipulation artikulierter Objekte.
Teamvorstellung
SAGE Dieses Forschungsergebnis stammt aus dem Labor von Professor Leonidas Guibas von der Stanford University, dem Embodied Perception and Interaction (EPIC Lab) von Professor Wang He von der Peking University und dem Zhiyuan Artificial Intelligence Research Institute. Die Autoren des Papiers sind der Student der Universität Peking und Gastwissenschaftler der Stanford University, Geng Haoran (Co-Autor), der Doktorand der Universität Peking, Wei Songlin (Co-Autor), die Doktoranden der Stanford University, Deng Congyue und Shen Bokui, und die Betreuer sind Professor Leonidas Guibas und Professor Wang He.
Referenzen:
[1] Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi, Siyuan Huang und He Wang. Gapartnet: Kategorieübergreifende, verallgemeinerbare Objektwahrnehmung und -manipulation über verallgemeinerbare und umsetzbare Teile. arXiv-Vorabdruck arXiv:2211.05272, 2022.
[2] Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao et al. „Alles segmentieren.“ arXiv-Vorabdruck arXiv:2304.02643 (2023).
[3] Zhang, Hao, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni und Heung-Yeung Shum Objekterkennung beenden.“ arXiv-Vorabdruck arXiv:2203.03605 (2022).
[4] Xiang, Fanbo, Yuzhe Qin, Kaichun Mo, Yikuan interaktive Umgebung.“ In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, S. 11097-11107, 2020.
Das obige ist der detaillierte Inhalt vonDas erste universelle 3D-Grafik- und Textmodellsystem für Möbel und Haushaltsgeräte, das keiner Anleitung bedarf und visuelle Modelle zur Verallgemeinerung verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!












 IIS unerwarteter Fehler 0x8ffe2740 Lösung
IIS unerwarteter Fehler 0x8ffe2740 Lösung
 flac-Format
flac-Format
 Welche E-Commerce-Plattformen gibt es?
Welche E-Commerce-Plattformen gibt es?
 Der Unterschied zwischen ++a und a++ in der C-Sprache
Der Unterschied zwischen ++a und a++ in der C-Sprache
 Wo soll ich meinen Geburtsort angeben: Provinz, Stadt oder Kreis?
Wo soll ich meinen Geburtsort angeben: Provinz, Stadt oder Kreis?
 Was ist der Unterschied zwischen 5g und 4g?
Was ist der Unterschied zwischen 5g und 4g?
 So verwenden Sie die magnetische Btbook-Suche
So verwenden Sie die magnetische Btbook-Suche
 So konfigurieren Sie die Pfadumgebungsvariable in Java
So konfigurieren Sie die Pfadumgebungsvariable in Java








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



