


Große Sprachmodelle (LLMs) sind tiefe neuronale Netze mit großen Mengen an Parametern und Daten, die in der Lage sind, eine Vielzahl von Aufgaben im Bereich der Verarbeitung natürlicher Sprache (NLP) zu erfüllen, wie zum Beispiel das Verstehen und Generieren von Texten. In den letzten Jahren haben LLMs wie GPT-4, BART, T5 usw. mit der Verbesserung der Rechenleistung und des Datenumfangs bemerkenswerte Fortschritte gemacht und starke Generalisierungsfähigkeiten und Kreativität bewiesen.
LLMs haben auch ernsthafte Probleme beim Generieren von Text, es ist leicht, Inhalte zu produzieren, die nicht mit echten Fakten oder Benutzereingaben übereinstimmen, also Halluzinationen. Dieses Phänomen verringert nicht nur die Systemleistung, sondern beeinträchtigt auch die Erwartungen und das Vertrauen der Benutzer und birgt sogar einige Sicherheits- und ethische Risiken. Daher ist die Erkennung und Linderung von Halluzinationen bei LLMs zu einem wichtigen und dringenden Thema im aktuellen NLP-Bereich geworden.
Am 1. Januar haben mehrere Wissenschaftler der Islamic University of Science and Technology in Bangladesch, des Artificial Intelligence Institute der University of South Carolina in den USA, der Stanford University in den USA und der Amazon Artificial Intelligence Department in Die Vereinigten Staaten, SM Towhidul Islam Tonmoy, SM Mehedi Zaman und Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha und Amitava Das haben einen Artikel mit dem Titel „A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models“ veröffentlicht, der darauf abzielt Einführung und Klassifizierung von Techniken zur Halluzinationsminderung in großen Sprachmodellen (LLMs).

Sie stellten zunächst die Definition, Ursachen und Auswirkungen von Halluzinationen sowie Beurteilungsmethoden vor. Anschließend schlagen sie ein detailliertes Klassifizierungssystem vor, das Techniken zur Halluzinationsminderung in vier Hauptkategorien unterteilt: datensatzbasiert, aufgabenbasiert, rückkopplungsbasiert und abrufbasiert. Innerhalb jeder Kategorie unterteilen sie die verschiedenen Unterkategorien weiter und veranschaulichen einige repräsentative Methoden.
Die Autoren analysieren außerdem die Vor- und Nachteile, Herausforderungen und Grenzen dieser Technologien sowie zukünftige Forschungsrichtungen. Sie wiesen darauf hin, dass die aktuelle Technologie immer noch einige Probleme aufweist, beispielsweise mangelnde Allgemeingültigkeit, Interpretierbarkeit, Skalierbarkeit und Robustheit. Sie schlugen vor, dass sich die zukünftige Forschung auf die folgenden Aspekte konzentrieren sollte: Entwicklung effektiverer Methoden zur Erkennung und Quantifizierung von Halluzinationen, Nutzung multimodaler Informationen und gesundem Menschenverstand, Entwicklung flexiblerer und anpassbarerer Rahmenwerke zur Halluzinationsminderung sowie Berücksichtigung von menschlicher Beteiligung und Feedback.
Um das Halluzinationsproblem bei LLMs besser zu verstehen und zu beschreiben, schlugen sie ein Klassifizierungssystem vor, das auf der Quelle, dem Typ, dem Grad und den Auswirkungen von Halluzinationen basiert, wie in gezeigt Abbildung 1 anzeigen. Sie glauben, dass dieses System alle Aspekte von Halluzinationen bei LLMs abdecken, dabei helfen kann, die Ursachen und Merkmale von Halluzinationen zu analysieren und die Schwere und den Schaden von Halluzinationen zu bewerten.
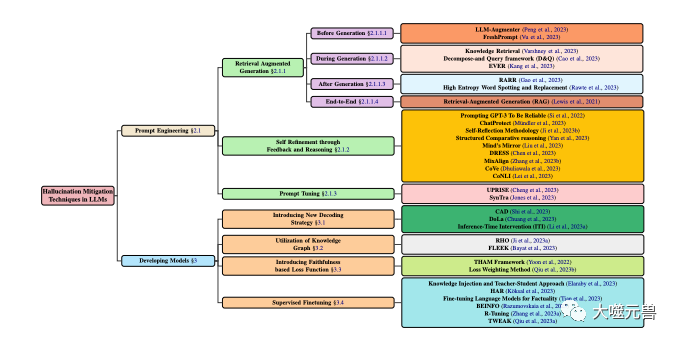 Abbildung 1
Abbildung 1
Klassifizierung von Techniken zur Halluzinationsminderung im LLM, mit Schwerpunkt auf beliebten Methoden, die Modellentwicklung und Aufforderungstechniken beinhalten. Die Modellentwicklung ist in verschiedene Methoden unterteilt, darunter neue Dekodierungsstrategien, wissensgraphbasierte Optimierung, Hinzufügen neuer Verlustfunktionskomponenten und überwachte Feinabstimmung. In der Zwischenzeit kann das Cue-Engineering Methoden zur Verbesserung des Abrufs, Feedback-basierte Strategien oder Cue-Anpassungen umfassen.
Die Quelle von Halluzinationen ist die Hauptursache von Halluzinationen in LLMs, die in die folgenden drei Kategorien zusammengefasst werden können:
Parametrisches Wissen: LLMs lernen aus groß angelegten Schulungen in die Vortrainingsphase Implizites Wissen, das aus unbeschriftetem Text gelernt wird, wie Grammatik, Semantik, gesunder Menschenverstand usw. Dieses Wissen ist üblicherweise in den Parametern von LLMs gespeichert und kann über Aktivierungsfunktionen und Aufmerksamkeitsmechanismen abgerufen werden. Parametrisches Wissen ist die Grundlage von LLMs, kann jedoch auch eine Quelle von Illusionen sein, da es möglicherweise ungenaue, veraltete oder voreingenommene Informationen enthält oder im Widerspruch zu vom Benutzer eingegebenen Informationen steht.
Nichtparametrisches Wissen: Explizites Wissen, das LLMs während der Feinabstimmungs- oder Generierungsphase aus externen annotierten Daten erhalten, wie z. B. Fakten, Beweise, Zitate usw. Dieses Wissen liegt normalerweise in strukturierter oder unstrukturierter Form vor und kann über Abruf- oder Gedächtnismechanismen abgerufen werden. Nichtparametrisches Wissen ist eine Ergänzung zu LLMs, kann aber auch eine Quelle von Illusionen sein, da es möglicherweise Rauschen, fehlerhafte oder unvollständige Daten enthält oder nicht mit dem parametrischen Wissen von LLMs übereinstimmt.
Generierungsstrategie: Bezieht sich auf einige Technologien oder Methoden, die von LLMs beim Generieren von Text verwendet werden, z. B. Dekodierungsalgorithmen, Steuercodes, Eingabeaufforderungen usw. Diese Strategien sind Werkzeuge für LLMs, können aber auch eine Quelle von Illusionen sein, da sie dazu führen können, dass LLMs sich zu sehr auf bestimmtes Wissen verlassen oder es ignorieren oder eine gewisse Voreingenommenheit oder Unruhe in den Generierungsprozess einbringen.
Arten von Halluzinationen beziehen sich auf die spezifischen Manifestationen von Halluzinationen, die durch LLMs erzeugt werden, die in die folgenden vier Kategorien unterteilt werden können:
Grammatische Halluzinationen: bezieht sich auf grammatikalische Fehler im Text, die durch LLMs erzeugt werden Oder Unregelmäßigkeiten wie Rechtschreibfehler, Zeichensetzungsfehler, Wortstellungsfehler, Tempusfehler, Subjekt-Verb-Inkonsistenz usw. Diese Illusion wird normalerweise durch ein unvollständiges Verständnis der Sprachregeln durch LLMs oder eine übermäßige Anpassung an verrauschte Daten verursacht.
Semantische Halluzination: bezieht sich auf semantische Fehler oder Unzumutbarkeiten im von LLMs erzeugten Text, wie etwa Wortbedeutungfehler, Referenzfehler, logische Fehler, Mehrdeutigkeiten, Widersprüche usw. Diese Illusion wird häufig durch ein unzureichendes Verständnis der Bedeutung von Sprache durch LLMs oder eine unzureichende Verarbeitung komplexer Daten verursacht.
Wissenshalluzination: bezieht sich auf die Tatsache, dass der von LLMs generierte Text Fehler oder Inkonsistenzen im Wissen enthält, wie z. B. sachliche Fehler, Beweisfehler, Zitierfehler, Nichtübereinstimmungen mit der Eingabe oder dem Kontext usw. Diese Illusion wird normalerweise durch den falschen Erwerb oder die unangemessene Nutzung von Wissen durch LLMs verursacht.
Kreative Halluzination (Kreative Halluzination): bezieht sich auf den von LLMs generierten Text, der kreative Fehler oder Unangemessenheiten aufweist, wie z. B. Stilfehler, emotionale Fehler, falsche Standpunkte, Unvereinbarkeit mit Aufgaben oder Zielen usw. Diese Illusion wird häufig durch die unangemessene Kontrolle der LLMs über die Erstellung oder die unzureichende Bewertung verursacht.
Der Grad der Halluzinationen bezieht sich auf die Quantität und Qualität der durch LLMs erzeugten Halluzinationen, die in die folgenden drei Kategorien unterteilt werden können:
Leichte Halluzinationen: Halluzinationen sind weniger und leichter, Beeinträchtigt nicht die allgemeine Lesbarkeit und Verständlichkeit des Textes und untergräbt nicht die Hauptaussage und den Zweck des Textes. LLMs erzeugen beispielsweise einige kleinere grammatikalische Fehler, einige semantische Mehrdeutigkeiten, einige Detailwissensfehler oder einige kreative subtile Unterschiede.
Mäßige Halluzinationen: Es gibt viele und starke Halluzinationen, die einen Teil der Lesbarkeit und Verständlichkeit des Textes beeinträchtigen und auch die sekundären Informationen und den Zweck des Textes beeinträchtigen. Normalerweise verursachen LLMs große grammatikalische Fehler oder semantische Irrationalität.
Schwere Halluzinationen: Die Halluzinationen sind sehr zahlreich und sehr schwerwiegend, beeinträchtigen die allgemeine Lesbarkeit und Verständlichkeit des Textes und zerstören auch die Hauptbotschaft und den Zweck des Textes.
Die Auswirkung von Halluzinationen bezieht sich auf die möglichen Folgen der durch LLMs erzeugten Halluzinationen auf Benutzer und Systeme, die in die folgenden drei Kategorien unterteilt werden können:
Harmlose Halluzination: Harmlose Halluzination : Auswirkungen auf Benutzer und Systeme Es hat keine negativen Auswirkungen verursacht und kann sogar einige positive Auswirkungen haben, wie z. B. mehr Spaß, Kreativität, Vielfalt usw. Beispielsweise generieren LLMs einige Inhalte, die nicht mit der Aufgabe oder dem Ziel in Zusammenhang stehen, oder einige Inhalte, die mit den Vorlieben oder Erwartungen des Benutzers übereinstimmen, oder einige Inhalte, die mit der Stimmung oder Einstellung des Benutzers übereinstimmen, oder einige Inhalte, die hilfreich sind der Kommunikations- oder Interaktionsinhalt des Benutzers.
Schädliche Halluzination: Sie hat einige negative Auswirkungen auf Benutzer und Systeme, wie z. B. eine Verringerung der Effizienz, Genauigkeit, Glaubwürdigkeit, Zufriedenheit usw. Beispielsweise generieren LLMs einige Inhalte, die nicht mit den Aufgaben oder Zielen übereinstimmen, oder einige Inhalte, die nicht mit den Vorlieben oder Erwartungen des Benutzers übereinstimmen, oder einige Inhalte, die nicht mit der Stimmung oder Einstellung des Benutzers übereinstimmen, oder einige Inhalte, die die Kommunikation des Benutzers behindern oder Interaktion.
Gefährliche Halluzination: Sie hat schwerwiegende negative Auswirkungen auf Benutzer und das System und kann beispielsweise zu Missverständnissen, Konflikten, Streitigkeiten, Verletzungen usw. führen. Beispielsweise generieren LLMs einige Inhalte, die im Widerspruch zu Fakten oder Beweisen stehen, oder einige Inhalte, die im Widerspruch zur Moral oder dem Gesetz stehen, oder einige Inhalte, die im Widerspruch zu den Menschenrechten oder der Würde stehen, oder einige Inhalte, die die Sicherheit oder Gesundheit gefährden.
Um das Problem der Halluzinationen bei LLMs besser zu lösen, müssen wir eine eingehende Analyse der Ursachen von Halluzinationen durchführen. Gemäß den oben genannten Halluzinationsquellen unterteilt der Autor die Ursachen von Halluzinationen in die folgenden drei Kategorien:
Unzureichendes oder übermäßiges Parameterwissen: In der Vortrainingsphase verwenden LLMs normalerweise eine große Menge unbeschrifteten Textes, um Sprachregeln und Wissen zu erlernen und so Parameterwissen zu bilden. B. unvollständig, ungenau, nicht aktualisiert, inkonsistent, irrelevant usw., was dazu führt, dass LLMs die eingegebenen Informationen beim Generieren von Text nicht vollständig verstehen und nutzen können oder nicht in der Lage sind, sie korrekt zu verwenden die ausgegebenen Informationen unterscheiden und auswählen und so Halluzinationen hervorrufen. Andererseits kann das Parameterwissen zu umfangreich oder zu leistungsstark sein, was dazu führt, dass LLMs sich bei der Texterstellung übermäßig auf ihr eigenes Wissen verlassen oder es bevorzugen, während sie die Eingabeinformationen ignorieren oder mit ihnen in Konflikt geraten, was zu Halluzinationen führt.
Mangel oder Fehler bei nichtparametrischem Wissen: In der Feinabstimmungs- oder Generierungsphase verwenden LLMs normalerweise einige externe annotierte Daten, um Sprachwissen zu erhalten oder zu ergänzen, und bilden so nichtparametrisches Wissen. Diese Art von Wissen kann einige Probleme aufweisen, wie z. B. Knappheit, Rauschen, Fehler, Unvollständigkeit, Inkonsistenz, Irrelevanz usw., was dazu führt, dass LLMs nicht in der Lage sind, Eingabeinformationen beim Generieren von Text effektiv abzurufen und zusammenzuführen oder diese genau zu überprüfen und zu korrigieren Informationen ausgeben und dadurch Halluzinationen hervorrufen. Nichtparametrisches Wissen kann auch zu komplex oder vielfältig sein, was es für LLMs schwierig macht, verschiedene Informationsquellen bei der Texterstellung auszubalancieren und zu koordinieren oder sich an unterschiedliche Aufgabenanforderungen anzupassen und diese zu erfüllen, was zu Illusionen führt.
Unangemessene oder unzureichende Generierungsstrategie: Wenn LLMs Text generieren, verwenden sie normalerweise einige Techniken oder Methoden, um den Generierungsprozess und die Ergebnisse zu steuern oder zu optimieren und so eine Generierungsstrategie zu entwickeln. Diese Strategien können einige Probleme aufweisen, wie z. B. unangemessen, unzureichend, instabil, unerklärlich, nicht vertrauenswürdig usw., was dazu führt, dass LLMs die Richtung und Qualität der Generierung bei der Textgenerierung nicht effektiv regulieren und leiten können, oder dass sie nicht entdecken und korrigieren können Es erzeugte rechtzeitig Fehler und erzeugte so Halluzinationen. Die Generierungsstrategie kann auch zu komplex oder veränderlich sein, was es für LLMs schwierig macht, die Konsistenz und Zuverlässigkeit der Generierung bei der Generierung von Texten aufrechtzuerhalten und sicherzustellen, oder es ist schwierig, die Auswirkungen der Generierung zu bewerten und Feedback zu geben, was zu Halluzinationen führt.
Um das Halluzinationsproblem bei LLMs besser zu lösen, müssen wir die durch LLMs erzeugten Halluzinationen effektiv erkennen und bewerten. Gemäß den oben vorgeschlagenen Arten von Halluzinationen unterteilt der Autor die Methoden zur Erkennung von Halluzinationen in die folgenden vier Kategorien:
Erkennungsmethoden für grammatikalische Halluzinationen: Verwendung einiger Tools oder Regeln zur Grammatikprüfung, um grammatikalische Fehler im von LLMs generierten Text zu identifizieren und zu korrigieren Oder unregelmäßig. Beispielsweise können einige Tools oder Regeln wie Rechtschreibprüfung, Zeichensetzungsprüfung, Wortreihenfolgeprüfung, Tempusprüfung, Subjekt-Verb-Übereinstimmungsprüfung usw. verwendet werden, um grammatikalische Illusionen in von LLMs generierten Texten zu erkennen und zu korrigieren.
Erkennungsmethode für semantische Halluzinationen: Verwenden Sie einige Werkzeuge oder Modelle zur semantischen Analyse, um semantische Fehler oder Irrationalität im von LLMs generierten Text zu verstehen und zu bewerten. Beispielsweise können einige Tools oder Modelle wie Wortbedeutungsanalyse, Referenzauflösung, logisches Denken, Mehrdeutigkeitsbeseitigung und Widerspruchserkennung verwendet werden, um semantische Illusionen in von LLMs generierten Texten zu erkennen und zu korrigieren.
Erkennungsmethode der Wissensillusion: Verwenden Sie einige Tools oder Modelle zum Abrufen oder Verifizieren von Wissen, um Wissensfehler oder Inkonsistenzen in von LLMs generierten Texten zu ermitteln und zu vergleichen. Beispielsweise können einige Tools oder Modelle wie Wissensgraphen, Suchmaschinen, Faktenprüfung, Beweisprüfung, Zitatprüfung usw. verwendet werden, um Wissensillusionen in von LLMs generierten Texten zu erkennen und zu korrigieren.
Erkennungsmethode der Schöpfungsillusion: Verwenden Sie einige Schöpfungsbewertungs- oder Feedback-Tools oder -Modelle, um Schöpfungsfehler oder Unangemessenheit im von LLMs generierten Text zu erkennen und zu bewerten. Beispielsweise können einige Tools oder Modelle wie Stilanalyse, Stimmungsanalyse, Schöpfungsbewertung, Meinungsanalyse, Zielanalyse usw. verwendet werden, um Schöpfungsillusionen in von LLMs generierten Texten zu erkennen und zu korrigieren.
Je nach Grad und Auswirkung der oben erwähnten Halluzination können wir die Bewertungskriterien der Halluzination in die folgenden vier Kategorien einteilen:
Grammatische Korrektheit: bezieht sich darauf, ob der von LLMs generierte Text grammatikalisch mit dem übereinstimmt Sprache. Regeln und Gewohnheiten wie Rechtschreibung, Zeichensetzung, Wortstellung, Zeitform, Subjekt-Verb-Übereinstimmung usw. Dieser Standard kann durch einige automatische oder manuelle Grammatikprüfungstools oder -methoden wie BLEU, ROUGE, BERTScore usw. bewertet werden.
Semantische Angemessenheit: bezieht sich darauf, ob der von LLMs generierte Text semantisch mit der Bedeutung und Logik der Sprache übereinstimmt, z. B. Wortbedeutung, Referenz, Logik, Mehrdeutigkeit, Widerspruch usw. Dieser Standard kann durch einige automatische oder manuelle semantische Analysetools oder -methoden wie METEOR, MoverScore, BERTScore usw. bewertet werden.
Wissenskonsistenz: Bezieht sich darauf, ob der von LLMs generierte Text intellektuell mit echten Fakten oder Beweisen übereinstimmt oder ob er mit eingegebenen oder kontextuellen Informationen wie Fakten, Beweisen, Referenzen, Übereinstimmungen usw. übereinstimmt. Dieser Standard kann durch einige automatische oder manuelle Wissensabruf- oder -überprüfungstools oder -methoden wie FEVER, FactCC, BARTScore usw. bewertet werden.
Kreative Angemessenheit: bezieht sich darauf, ob der von LLMs generierte Text die Anforderungen der Aufgabe oder des Ziels kreativ erfüllt oder mit den Vorlieben oder Erwartungen des Benutzers übereinstimmt oder mit den Emotionen oder Einstellungen des Benutzers übereinstimmt die Emotionen oder Einstellungen des Benutzers, ob die Kommunikation oder Interaktion des Benutzers hilfreich ist, wie z. B. Stil, Emotionen, Meinungen, Ziele usw. Dieser Standard kann durch einige automatische oder manuelle Bewertungs- oder Feedback-Tools oder -Methoden wie BLEURT, BARTScore, SARI usw. bewertet werden.
Um das Halluzinationsproblem bei LLMs besser zu lösen, müssen wir die durch LLMs verursachten Halluzinationen wirksam lindern und reduzieren. Nach verschiedenen Ebenen und Blickwinkeln unterteilt der Autor die Methoden zur Linderung von Halluzinationen in die folgenden Kategorien:
Verfeinerung nach der Generierung besteht darin, den Text zu ändern, nachdem LLMs den Text generiert haben die Illusion zu beseitigen oder zu reduzieren. Der Vorteil dieser Art von Methode besteht darin, dass sie kein erneutes Training oder Tuning von LLMs erfordert und direkt auf alle LLMs angewendet werden kann. Die Nachteile dieses Ansatzes bestehen darin, dass die Illusion möglicherweise nicht vollständig beseitigt wird oder neue Illusionen eingeführt werden oder einige der Informationen oder Kreativität des Originaltextes verloren gehen. Vertreter dieser Art von Methode sind:
RARR (Refinement with Attribution and Retrieved References): (Chrysostomou und Aletras, 2021) schlugen eine Verfeinerungsmethode basierend auf Attribution und Retrieval vor, um den von LLMs Fidelity generierten Text zu verbessern. Mithilfe eines Attributionsmodells wird ermittelt, ob jedes Wort im von LLMs generierten Text aus den Eingabeinformationen, dem Parameterwissen der LLMs oder der Generierungsstrategie der LLMs stammt. Verwenden Sie ein Abrufmodell, um einige Referenztexte im Zusammenhang mit den Eingabeinformationen aus externen Wissensquellen abzurufen. Schließlich wird ein Verfeinerungsmodell verwendet, um den von LLMs basierend auf den Attributionsergebnissen und Abrufergebnissen generierten Text zu modifizieren, um seine Konsistenz und Glaubwürdigkeit mit den Eingabeinformationen zu verbessern.
High Entropy Word Spotting and Replacement (HEWSR): (Zhang et al., 2021) schlugen eine entropiebasierte Verfeinerungsmethode zur Reduzierung von Halluzinationen in durch LLMs generierten Texten vor. Zunächst wird ein Entropieberechnungsmodell verwendet, um Wörter mit hoher Entropie in von LLMs generierten Texten zu identifizieren, d. h. Wörter mit höherer Unsicherheit bei der Generierung. Dann wird ein Ersatzmodell verwendet, um aus den Eingabeinformationen oder einer externen Wissensquelle ein passenderes Wort auszuwählen, um das Wort mit hoher Entropie zu ersetzen. Schließlich wird ein Glättungsmodell verwendet, um einige Anpassungen am ersetzten Text vorzunehmen, um seine grammatikalische und semantische Kohärenz aufrechtzuerhalten.
ChatProtect (Chat-Schutz mit Selbstwiderspruchserkennung): (Wang et al., 2021) schlug eine verfeinerte Methode vor, die auf der Selbstwiderspruchserkennung basiert, um die Sicherheit von Chat-Konversationen zu verbessern, die von LLMs generiert werden. Zunächst wird ein Widerspruchserkennungsmodell verwendet, um Selbstwidersprüche im von LLMs generierten Dialog zu identifizieren, also solche Inhalte, die im Widerspruch zum vorherigen Dialoginhalt stehen. Anschließend wird ein Ersatzmodell verwendet, um die widersprüchliche Antwort durch eine geeignetere aus einigen vordefinierten sicheren Antworten zu ersetzen. Schließlich wird ein Bewertungsmodell verwendet, um dem ersetzten Dialog einige Punkte zu geben und so seine Sicherheit und Geläufigkeit zu messen.
Selbstverbesserung durch Feedback und Argumentation besteht darin, einige Bewertungen und Anpassungen am Text vorzunehmen, während LLMs Text generieren, um Halluzinationen zu beseitigen oder zu reduzieren. Der Vorteil dieser Art von Methode besteht darin, dass sie Halluzinationen in Echtzeit überwachen und korrigieren und die Selbstlern- und Selbstregulierungsfähigkeiten von LLMs verbessern kann. Der Nachteil dieser Art von Ansatz besteht darin, dass möglicherweise zusätzliche Schulungen oder Anpassungen der LLMs erforderlich sind oder dass möglicherweise externe Informationen oder Ressourcen erforderlich sind. Vertreter dieser Art von Methode sind:
Selbstreflexionsmethodik (SRM): (Iyer et al., 2021) schlug eine perfekte Methode vor, die auf Selbstfeedback basiert, um die Zuverlässigkeit der von LLMs generierten medizinischen Fragen und Antworten zu verbessern. Die Methode verwendet zunächst ein generatives Modell, um eine erste Antwort basierend auf der Eingabefrage und dem Kontext zu generieren. Mithilfe eines Feedback-Modells wird dann basierend auf der Eingabefrage und dem Kontext eine Feedback-Frage generiert, mit der potenzielle Halluzinationen in der ersten Antwort erkannt werden. Verwenden Sie dann ein Antwortmodell, um eine Antwort basierend auf der Feedbackfrage zu generieren und die Richtigkeit der ursprünglichen Antwort zu überprüfen. Schließlich wird ein Korrekturmodell verwendet, um die ursprüngliche Antwort basierend auf den Antwortergebnissen zu korrigieren und so ihre Zuverlässigkeit und Genauigkeit zu verbessern.
Structured Comparative (SC) Reasoning: (Yan et al., 2021) schlugen eine auf strukturiertem Vergleich basierende Argumentationsmethode vor, um die Konsistenz der von LLMs generierten Textpräferenzvorhersagen zu verbessern. Diese Methode verwendet ein generatives Modell, um einen strukturierten Vergleich basierend auf den eingegebenen Textpaaren zu generieren, dh die Textpaare werden unter verschiedenen Aspekten verglichen und bewertet. Verwenden Sie ein Inferenzmodell, um auf der Grundlage strukturierter Vergleiche eine Vorhersage der Textpräferenz zu generieren, d. h. welches Textpaar bevorzugt wird. Verwenden Sie ein Bewertungsmodell, um die generierten Vergleiche mit den vorhergesagten Ergebnissen zu vergleichen und so deren Konsistenz und Glaubwürdigkeit zu verbessern.
Think While Effectively Articulated Knowledge (TWEAK): (Qiu et al., 2021a) schlägt eine Inferenzmethode vor, die auf der Verifizierung von Hypothesen basiert, um die Treue des von LLMs generierten Wissens zum Text zu verbessern. Diese Methode verwendet ein generatives Modell, um basierend auf eingegebenem Wissen einen Ausgangstext zu generieren. Verwenden Sie dann ein Hypothesenmodell, um einige Hypothesen basierend auf dem ursprünglichen Text zu generieren, dh den zukünftigen Text des Textes unter verschiedenen Aspekten vorherzusagen. Verwenden Sie dann ein Verifizierungsmodell, um die Richtigkeit jeder Hypothese basierend auf dem eingegebenen Wissen zu überprüfen. Abschließend wird ein Anpassungsmodell verwendet, um den Ausgangstext basierend auf den Verifizierungsergebnissen anzupassen, um seine Konsistenz und Glaubwürdigkeit mit dem eingegebenen Wissen zu verbessern.
Die neue Dekodierungsstrategie besteht darin, einige Änderungen oder Optimierungen an der Wahrscheinlichkeitsverteilung des Textes im Prozess der Textgenerierung durch LLMs vorzunehmen, um Illusionen zu beseitigen oder zu reduzieren. Der Vorteil dieser Art von Methode besteht darin, dass sie sich direkt auf die generierten Ergebnisse auswirken und die Flexibilität und Effizienz von LLMs verbessern kann. Der Nachteil dieser Art von Ansatz besteht darin, dass möglicherweise zusätzliche Schulungen oder Anpassungen der LLMs erforderlich sind oder dass möglicherweise externe Informationen oder Ressourcen erforderlich sind. Vertreter dieser Art von Methode sind:
Context-Aware Decoding (CAD): (Shi et al., 2021) schlug eine kontrastbasierte Decodierungsstrategie zur Reduzierung von Wissenskonflikten in durch LLMs generierten Texten vor. Diese Strategie verwendet ein Kontrastmodell, um den Unterschied in der Wahrscheinlichkeitsverteilung der Ausgabe von LLMs zu berechnen, wenn Eingabeinformationen verwendet und nicht verwendet werden. Dann wird ein Verstärkungsmodell verwendet, um diesen Unterschied zu verstärken, sodass die Wahrscheinlichkeit einer Ausgabe, die mit den Eingabeinformationen übereinstimmt, höher und die Wahrscheinlichkeit einer Ausgabe, die mit den Eingabeinformationen in Konflikt steht, geringer ist. Schließlich wird ein generatives Modell verwendet, um Text basierend auf der verstärkten Wahrscheinlichkeitsverteilung zu generieren, um seine Konsistenz und Glaubwürdigkeit mit den Eingabeinformationen zu verbessern.
Decoding by Contrasting Layers (DoLa): (Chuang et al., 2021) schlug eine auf Ebenenkontrast basierende Dekodierungsstrategie zur Reduzierung von Wissensillusionen in durch LLMs generierten Texten vor. Zunächst wird ein Schichtenauswahlmodell verwendet, um bestimmte Schichten in LLMs als Wissensschichten auszuwählen, also solche Schichten, die mehr Faktenwissen enthalten. Mithilfe eines Schichtenkontrastmodells wird dann der logarithmische Unterschied zwischen der Wissensschicht und anderen Schichten im Vokabularraum berechnet. Schließlich wird ein generatives Modell verwendet, um Text basierend auf der Wahrscheinlichkeitsverteilung nach dem Ebenenvergleich zu generieren, um seine Konsistenz und Glaubwürdigkeit mit Faktenwissen zu verbessern.
Knowledge Graph Utilization besteht darin, einige strukturierte Wissensgraphen zu verwenden, um Wissen im Zusammenhang mit den Eingabeinformationen im Prozess der Textgenerierung durch LLMs bereitzustellen oder zu ergänzen, um Halluzinationen zu beseitigen oder zu reduzieren. Der Vorteil dieser Art von Methode besteht darin, dass sie externes Wissen effektiv erwerben und integrieren und die Wissensabdeckung und Wissenskonsistenz von LLMs verbessern kann. Der Nachteil dieser Art von Ansatz besteht darin, dass möglicherweise eine zusätzliche Schulung oder Optimierung der LLMs oder einige hochwertige Wissensgraphen erforderlich sind. Zu den Vertretern dieser Art von Methode gehören:
RHO (Repräsentation verknüpfter Entitäten und Beziehungsprädikate aus einem Wissensgraphen): (Ji et al., 2021a) schlug eine auf Wissensgraphen basierende Darstellungsmethode vor, um den von LLMs generierten Dialog zu verbessern Treue der Antworten. Zunächst wird ein Wissensabrufmodell verwendet, um einige Untergraphen im Zusammenhang mit dem Eingabedialog aus einem Wissensgraphen abzurufen, d. h. einem Graphen, der einige Entitäten und Beziehungen enthält. Anschließend wird ein Wissenskodierungsmodell verwendet, um Entitäten und Beziehungen im Untergraphen zu kodieren, um ihre Vektordarstellungen zu erhalten. Anschließend wird ein Wissensfusionsmodell verwendet, um die Vektordarstellung des Wissens mit der Vektordarstellung des Dialogs zu verschmelzen, um eine verbesserte Dialogdarstellung zu erhalten. Schließlich wird ein Wissensgenerierungsmodell verwendet, um basierend auf der verbesserten Dialogdarstellung eine originalgetreue Dialogantwort zu generieren.
FLEEK (FactuaL Error Detection and Correction with Evidence Retrieved from external Knowledge): (Bayat et al., 2021) schlug eine Verifizierungs- und Korrekturmethode basierend auf Wissensgraphen vor, um die Faktizität von durch LLMs generierten Texten zu verbessern. Die Methode verwendet zunächst ein Faktenerkennungsmodell, um potenziell überprüfbare Fakten im von LLMs generierten Text zu identifizieren, also solche Fakten, für die Beweise im Wissensgraphen gefunden werden können. Mithilfe eines Fragegenerierungsmodells wird dann für jeden Sachverhalt eine Frage zur Abfrage des Wissensgraphen generiert. Verwenden Sie dann ein Wissensabrufmodell, um einige Beweise für das Problem aus dem Wissensgraphen abzurufen. Schließlich wird ein Faktenüberprüfungs- und Korrekturmodell verwendet, um die Fakten im von LLMs generierten Text auf der Grundlage von Beweisen zu überprüfen und zu korrigieren, um dessen Faktizität und Genauigkeit zu verbessern.
Die auf Treue basierende Verlustfunktion besteht darin, während des Trainings oder der Feinabstimmung von LLMs ein Maß für die Konsistenz zwischen dem generierten Text und den Eingabeinformationen oder echten Etiketten zu verwenden eine Verlustfunktion zur Eliminierung oder Reduzierung von Illusionen. Der Vorteil dieser Art von Methode besteht darin, dass sie sich direkt auf die Parameteroptimierung von LLMs auswirken und die Wiedergabetreue und Genauigkeit von LLMs verbessern kann. Der Nachteil dieser Art von Ansatz besteht darin, dass möglicherweise eine zusätzliche Schulung oder Optimierung der LLMs erforderlich ist oder dass einige qualitativ hochwertige annotierte Daten erforderlich sind. Vertreter dieser Art von Methode sind:
Text Hallucination Mitigating (THAM) Framework: (Yoon et al., 2022) schlug eine Verlustfunktion basierend auf der Informationstheorie vor, um Halluzinationen in von LLMs generierten Videogesprächen zu reduzieren. Zunächst wird ein Dialogsprachmodell verwendet, um die Wahrscheinlichkeitsverteilung des Dialogs zu berechnen. Anschließend wird ein Halluzinationssprachmodell verwendet, um die Wahrscheinlichkeitsverteilung von Halluzinationen zu berechnen, d. h. die Wahrscheinlichkeitsverteilung von Informationen, die nicht aus dem Eingabevideo gewonnen werden können. Dann wird ein gegenseitiges Informationsmodell verwendet, um die gegenseitige Information zwischen Dialog und Illusion zu berechnen, also die gegenseitige Information über den Grad der im Dialog enthaltenen Illusion. Schließlich wird ein Kreuzentropiemodell verwendet, um die Kreuzentropie des Dialogs und die tatsächliche Bezeichnung, also die Genauigkeit des Dialogs, zu berechnen. Das Ziel dieser Verlustfunktion besteht darin, die Summe aus gegenseitiger Information und Kreuzentropie zu minimieren und dadurch Illusionen und Fehler im Dialog zu reduzieren.
Faktische Fehlerkorrektur mit Beweisen aus externem Wissen (FECK): (Ji et al., 2021b) schlug eine Verlustfunktion basierend auf Wissensnachweisen vor, um die Faktizität von durch LLMs generierten Texten zu verbessern. Zunächst wird ein Wissensabrufmodell verwendet, um einige Untergraphen, die sich auf den Eingabetext beziehen, aus einem Wissensgraphen abzurufen, d. h. einem Graphen, der einige Entitäten und Beziehungen enthält. Anschließend wird ein Wissenskodierungsmodell verwendet, um Entitäten und Beziehungen im Untergraphen zu kodieren, um ihre Vektordarstellungen zu erhalten. Anschließend wird ein Wissensausrichtungsmodell verwendet, um die Entitäten und Beziehungen im von LLMs generierten Text mit den Entitäten und Beziehungen im Wissensgraphen abzugleichen, um ihren Übereinstimmungsgrad zu ermitteln. Schließlich berechnet die Verlustfunktion mithilfe eines Wissensverlustmodells den Abstand zwischen den Entitäten und Beziehungen im von LLMs generierten Text und den Entitäten und Beziehungen im Wissensgraphen, also die Abweichung von der Tatsache. Ziel dieser Verlustfunktion ist es, den Wissensverlust zu minimieren und dadurch die Faktizität und Genauigkeit des von LLMs generierten Textes zu verbessern.
Prompt Tuning ist der Prozess der Verwendung eines bestimmten Textes oder Symbols als Teil der Eingabe, um das Erzeugungsverhalten von LLMs zu steuern oder zu steuern, um Halluzinationen zu beseitigen oder zu reduzieren. Der Vorteil dieser Art von Methode besteht darin, dass sie das Parameterwissen von LLMs effektiv anpassen und steuern und die Anpassungsfähigkeit und Flexibilität von LLMs verbessern kann. Der Nachteil dieser Art von Ansatz besteht darin, dass möglicherweise eine zusätzliche Schulung oder Abstimmung der LLMs oder einige hochwertige Eingabeaufforderungen erforderlich sind. Zu den Vertretern dieser Art von Methode gehören:
UPRISE (Universal Prompt-based Refinement for Improving Semantic Equivalence): (Chen et al., 2021) schlug eine Feinabstimmungsmethode vor, die auf universellen Eingabeaufforderungen basiert, um die Semantik des generierten Textes zu verbessern durch LLMs. Zunächst wird ein Eingabeaufforderungsgenerierungsmodell verwendet, um eine allgemeine Eingabeaufforderung basierend auf dem Eingabetext zu generieren, d. Anschließend wird ein Hinweis-Feinabstimmungsmodell verwendet, um die Parameter von LLMs basierend auf dem Eingabetext und den Hinweisen zu optimieren, wodurch die Wahrscheinlichkeit erhöht wird, dass Text generiert wird, der dem Eingabetext semantisch äquivalent ist. Schließlich verwendet die Methode ein Hinweisgenerierungsmodell, um einen semantisch äquivalenten Text basierend auf den Parametern fein abgestimmter LLMs zu generieren.
SynTra (Synthetic Task for Hallucination Mitigation in Abstractive Summarization): (Wang et al., 2021) schlug eine auf synthetischen Aufgaben basierende Feinabstimmungsmethode zur Reduzierung von Halluzinationen in von LLMs generierten Zusammenfassungen vor. Zunächst wird ein synthetisches Aufgabengenerierungsmodell verwendet, um eine synthetische Aufgabe basierend auf dem Eingabetext zu generieren, d. h. ein Problem zur Erkennung von Halluzinationen in Zusammenfassungen. Anschließend wird ein synthetisches Aufgaben-Feinabstimmungsmodell verwendet, um die Parameter der LLMs basierend auf dem Eingabetext und der Aufgabe zu optimieren, wodurch die Wahrscheinlichkeit erhöht wird, Zusammenfassungen zu erstellen, die mit dem Eingabetext konsistent sind. Schließlich wird ein synthetisches Aufgabengenerierungsmodell verwendet, um eine konsistente Zusammenfassung basierend auf den Parametern der fein abgestimmten LLMs zu erstellen.
Obwohl die Technologie zur Linderung von Halluzinationen bei LLMs einige Fortschritte gemacht hat, gibt es immer noch einige Herausforderungen und Einschränkungen, die weiterer Forschung und Erforschung bedürfen. Im Folgenden sind einige der größten Herausforderungen und Einschränkungen aufgeführt:
Definition und Messung von Halluzinationen: Ohne eine einheitliche und klare Definition und Messung können verschiedene Studien unterschiedliche Standards und Metriken verwenden, um durch LLM-Halluzinationen erzeugten Text zu beurteilen und zu bewerten. Dies führt zu einigen inkonsistenten und unvergleichlichen Ergebnissen und beeinträchtigt auch das Verständnis und die Lösung von Halluzinationsproblemen bei LLMs. Daher besteht die Notwendigkeit, eine gemeinsame und zuverlässige Definition und Messung von Halluzinationen zu etablieren, um eine wirksame Erkennung und Bewertung von Halluzinationen bei LLMs zu ermöglichen.
Daten und Ressourcen zu Halluzinationen: Es mangelt an einigen hochwertigen und umfangreichen Daten und Ressourcen, um die Forschung und Entwicklung von Halluzinationen bei LLMs zu unterstützen. Beispielsweise mangelt es an einigen Datensätzen, die Halluzinationsanmerkungen enthalten, um Methoden zur Halluzinationserkennung und -minderung in LLMs zu trainieren und zu testen. Es mangelt an einigen Wissensquellen, die echte Fakten und Beweise enthalten, um das Wissen in den von LLMs generierten Texten bereitzustellen und zu überprüfen Es fehlen einige Datensätze, die Halluzinationen enthalten. Eine Plattform für Benutzerfeedback und Bewertungen, um die Auswirkungen von Halluzinationen in Texten zu sammeln und zu analysieren. Daher müssen einige hochwertige und umfangreiche Daten und Ressourcen erstellt werden, um eine effektive Forschung und Entwicklung zu Halluzinationen bei LLMs zu ermöglichen.
Ursachen und Mechanismen von Halluzinationen: Es gibt keine eingehende und umfassende Analyse der Ursachen und Mechanismen, um aufzudecken und zu erklären, warum LLMs Halluzinationen hervorrufen und wie Halluzinationen bei LLMs entstehen und sich ausbreiten. Es ist beispielsweise unklar, wie sich parametrisches Wissen, nichtparametrisches Wissen und generative Strategien in LLMs gegenseitig beeinflussen und interagieren und wie sie zu Illusionen unterschiedlicher Art, Ausmaß und Wirkung führen. Daher ist eine eingehende und umfassende Analyse der Ursachen und Mechanismen erforderlich, um eine wirksame Prävention und Kontrolle von Halluzinationen bei LLMs zu ermöglichen.
Lösung und Optimierung von Halluzinationen: Es gibt keine perfekte und universelle Lösung und Optimierungslösung, um Halluzinationen in von LLMs generierten Texten zu beseitigen oder zu reduzieren sowie die Qualität und Wirkung von durch LLMs generierten Texten zu verbessern. Es ist beispielsweise unklar, wie die Wiedergabetreue und Genauigkeit von LLMs verbessert werden kann, ohne ihre Generalisierungsfähigkeit und Kreativität zu verlieren. Daher müssen einige vollständige und universelle Lösungen und Optimierungslösungen entwickelt werden, um die Qualität und Wirkung des von LLMs generierten Textes zu verbessern.
Das obige ist der detaillierte Inhalt vonEine umfassende Studie über Techniken zur Halluzinationsminderung beim groß angelegten maschinellen Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Ist die Geschwindigkeit von PHP8.0 verbessert?
Ist die Geschwindigkeit von PHP8.0 verbessert?
 Was bedeutet PS-Maske?
Was bedeutet PS-Maske?
 Einführung in die Velocity-Syntax
Einführung in die Velocity-Syntax
 So stellen Sie den binauralen Modus des Bluetooth-Headsets wieder her
So stellen Sie den binauralen Modus des Bluetooth-Headsets wieder her
 Wie ist die Leistung von thinkphp?
Wie ist die Leistung von thinkphp?
 Was ist das World Wide Web?
Was ist das World Wide Web?
 Win11 „Mein Computer' zum Desktop-Tutorial hinzugefügt
Win11 „Mein Computer' zum Desktop-Tutorial hinzugefügt
 Was ist der Unterschied zwischen Hardware-Firewall und Software-Firewall?
Was ist der Unterschied zwischen Hardware-Firewall und Software-Firewall?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



