


Das KI-Modell, das Text zur Synthese von 3D-Grafiken verwendet, hat ein neues SOTA!
Kürzlich hat die Forschungsgruppe von Professor Liu Yongjin von der Tsinghua-Universität eine neue Methode von Vincent 3D vorgeschlagen, die auf einem Diffusionsmodell basiert.
Sowohl die Konsistenz zwischen verschiedenen Betrachtungswinkeln als auch die Zuordnung mit Aufforderungswörtern wurden im Vergleich zu zuvor erheblich verbessert.
 Bilder
Bilder
Vincent 3D ist ein heißer Forschungsinhalt von 3D AIGC und hat in Wissenschaft und Industrie große Aufmerksamkeit erhalten.
Das vom Forschungsteam von Professor Liu Yongjin vorgeschlagene neue Modell heißt TICD (Text-Image Conditioned Diffusion) und hat im T3Bench-Datensatz das SOTA-Niveau erreicht.
Relevante Artikel wurden veröffentlicht und der Code wird bald Open Source sein.
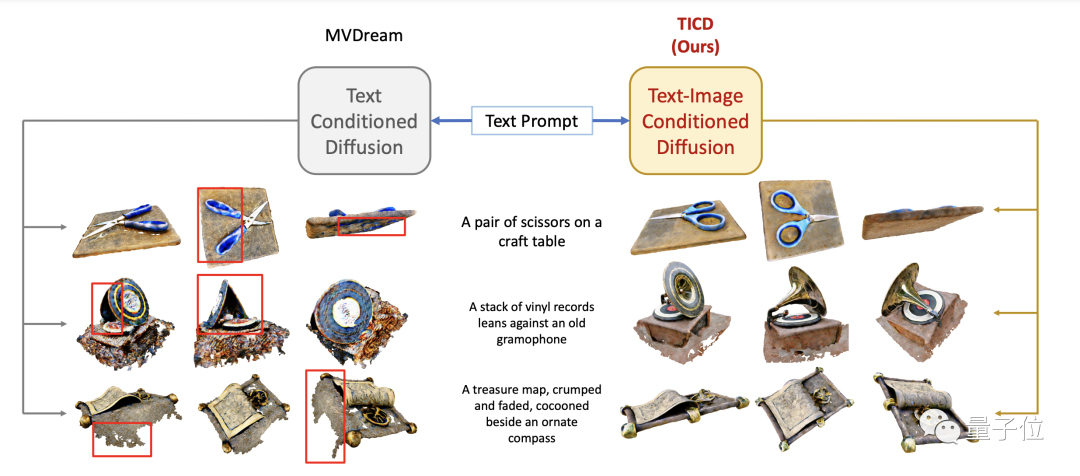
Um die Wirkung der TICD-Methode zu bewerten, führte das Forschungsteam zunächst qualitative Experimente durch und verglich einige frühere bessere Methoden.
Die Ergebnisse zeigen, dass die mit der TICD-Methode generierten 3D-Grafiken eine bessere Qualität, klarere Grafiken und einen höheren Grad an Übereinstimmung mit den Eingabeaufforderungswörtern aufweisen.
 Bilder
Bilder
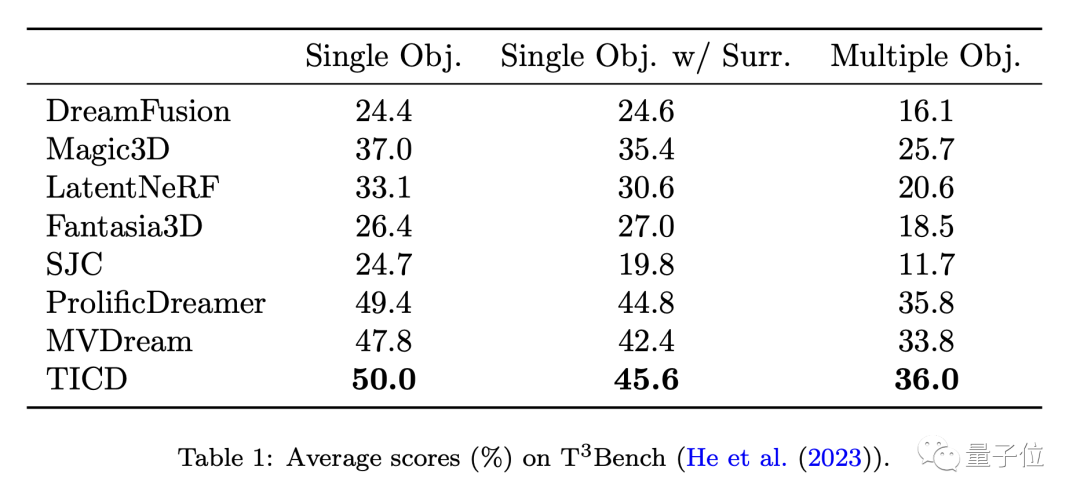
Um die Leistung dieser Modelle weiter zu bewerten, testete das Team TICD mit diesen Methoden quantitativ am T3Bench-Datensatz.
Die Ergebnisse zeigen, dass TICD in den drei Eingabeaufforderungssätzen „Einzelobjekt“, „Einzelobjekt mit Hintergrund“ und „Mehrere Objekte“ die besten Ergebnisse erzielte und damit seine Gesamtvorteile sowohl bei der Generierungsqualität als auch bei der Textausrichtung unter Beweis stellte.
 Bilder
Bilder
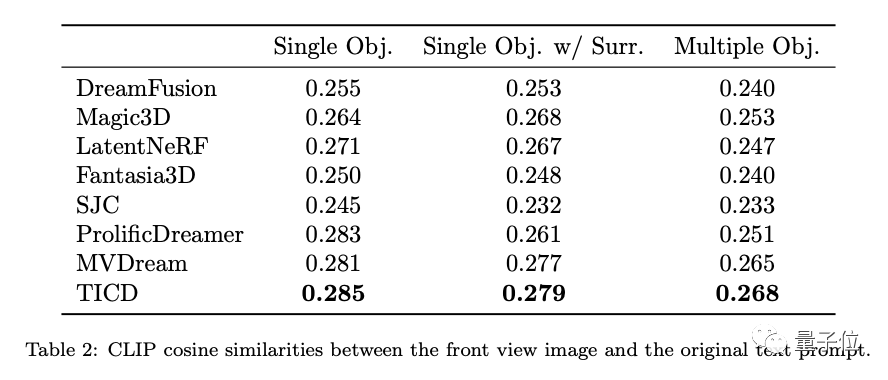
Um die Textausrichtung dieser Modelle weiter zu bewerten, testete das Forschungsteam außerdem die CLIP-Cosinus-Ähnlichkeit zwischen den vom 3D-Objekt gerenderten Bildern und den ursprünglichen Eingabeaufforderungswörtern. Die Ergebnisse waren Dennoch ist die Leistung von TICD optimal.
Wie erzielt die TICD-Methode einen solchen Effekt?
Derzeit gängige 3D-Textgenerierungsmethoden verwenden meist vorab trainierte 2D-Diffusionsmodelle, um durch Optimierung des Neural Radiation Field (NeRF) durch Score Distillation Sampling (SDS) ein brandneues 3D-Modell zu generieren.
Die von diesem vorab trainierten Diffusionsmodell bereitgestellte Überwachung ist jedoch auf den Eingabetext selbst beschränkt und schränkt die Konsistenz zwischen mehreren Ansichten nicht ein und kann Probleme wie schlecht generierte geometrische Strukturen verursachen.
Um die Multi-View-Konsistenz im Vorfeld von Diffusionsmodellen einzuführen, verfeinern einige neuere Studien 2D-Diffusionsmodelle mithilfe von Multi-View-Daten, es mangelt ihnen jedoch immer noch an einer feinkörnigen Inter-View-Kontinuität.
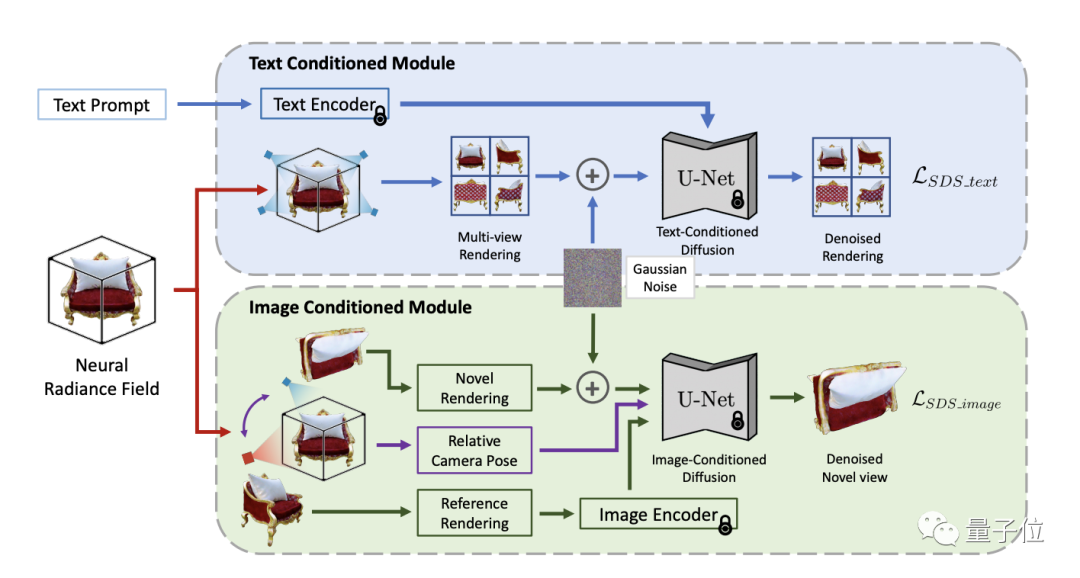
Um diese Herausforderung zu lösen, integriert die TICD-Methode textkonditionierte und bildkonditionierte Multi-View-Bilder in das NeRF-optimierte Überwachungssignal und gewährleistet so die Ausrichtung von 3D-Informationen und Aufforderungswörtern sowie die starke Korrelation zwischen verschiedenen Ansichten von Durch die Konsistenz von 3D-Objekten wird die Qualität der generierten 3D-Modelle effektiv verbessert.
 Bilder
Bilder
Im Workflow probiert TICD zunächst mehrere Sätze orthogonaler Referenzkameraperspektiven aus, verwendet NeRF zum Rendern der entsprechenden Referenzansichten und wendet dann ein textbasiertes bedingtes Diffusionsmodell auf diese Referenzansichten an, um Inhalte einzuschränken und Gesamtkonsistenz des Textes.
Wählen Sie auf dieser Grundlage mehrere Sätze von Referenzkameraperspektiven aus und rendern Sie für jede Perspektive eine Ansicht aus einer zusätzlichen neuen Perspektive. Anschließend wird die Posenbeziehung zwischen den beiden Ansichten und Perspektiven als neue Bedingung verwendet und ein bildbasiertes bedingtes Diffusionsmodell verwendet, um die Konsistenz von Details zwischen verschiedenen Perspektiven einzuschränken.
Durch die Kombination der Überwachungssignale der beiden Diffusionsmodelle kann TICD die Parameter des NeRF-Netzwerks aktualisieren und iterativ optimieren, bis das endgültige NeRF-Modell erhalten wird, und qualitativ hochwertige, geometrisch klare und textkonsistente 3D-Inhalte rendern.
Darüber hinaus kann die TICD-Methode Probleme wie das Verschwinden geometrischer Informationen, die übermäßige Erzeugung falscher geometrischer Informationen und Farbverwechslungen, die auftreten können, wenn bestehende Methoden mit bestimmten Texteingaben konfrontiert werden, wirksam beseitigen.
Papieradresse: //m.sbmmt.com/link/8553adf92deaf5279bcc6f9813c8fdcc
Das obige ist der detaillierte Inhalt vonTsinghua Wensheng kombinierte das Diffusionsmodell mit NeRF und schlug eine neue 3D-Methode zur Erzielung von SOTA vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




















