


| Einführung | Vor kurzem habe ich eine Echtzeitsynchronisierung der Protokolle durchgeführt. Es gab jedoch keine Probleme mit der Nachrichtenwarteschlange, dem Client und dem lokalen Computer Erwarten Sie, dass das Problem nach dem Hochladen des zweiten Protokolls auftrat: |
Eine bestimmte Maschine im Cluster (oben) sieht eine große Last. Die Maschinen im Cluster haben die gleiche Hardwarekonfiguration und die gleiche bereitgestellte Software, aber diese eine Maschine hat ein Lastproblem. Es wird zunächst vermutet, dass es sich um eine Hardware handelt Problem.
Gleichzeitig müssen wir auch den Schuldigen für die abnormale Belastung herausfinden und dann Lösungen auf Software- und Hardwareebene finden.

Sie können von oben sehen, dass der Lastdurchschnitt hoch, %wa hoch und %us niedrig ist:
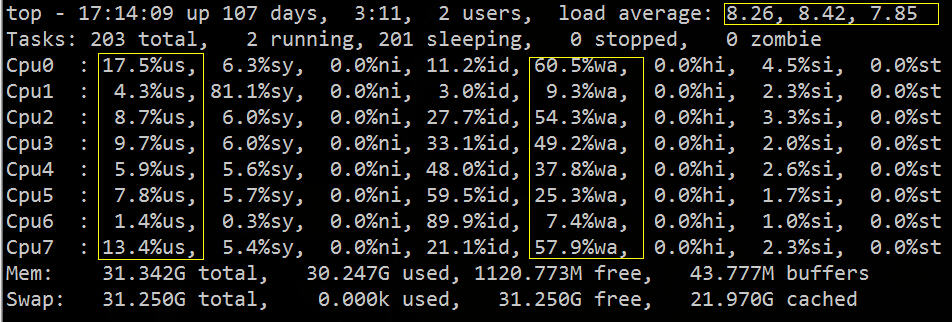
Aus dem obigen Bild können wir grob schließen, dass IO auf einen Engpass gestoßen ist. Als nächstes können wir verwandte IO-Diagnosetools zur spezifischen Überprüfung und Fehlerbehebung verwenden.
Häufig verwendete Kombinationsmethoden sind wie folgt:
•Verwenden Sie vmstat, sar, iostat, um zu erkennen, ob es sich um einen CPU-Engpass handelt
•Verwenden Sie free und vmstat, um zu erkennen, ob ein Speicherengpass vorliegt
•Verwenden Sie iostat und dmesg, um zu erkennen, ob es sich um einen Festplatten-E/A-Engpass handelt
•Verwenden Sie netstat, um Engpässe bei der Netzwerkbandbreite zu erkennen
Die Bedeutung des Befehls vmstat besteht darin, den Status des virtuellen Speichers („Virtual Memor Statics“) anzuzeigen, er kann jedoch auch über den Gesamtbetriebsstatus des Systems wie Prozesse, Speicher, E/A usw. berichten.
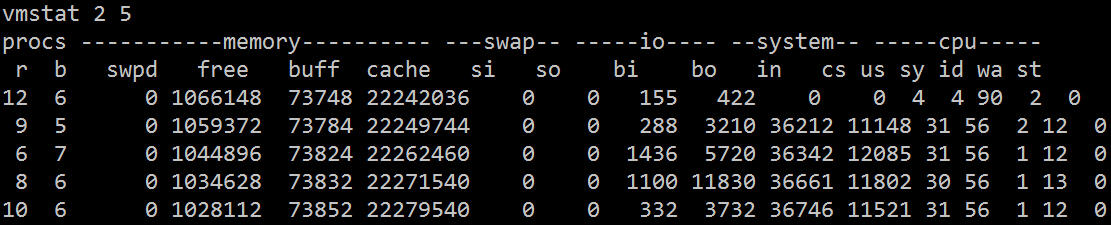
Die zugehörigen Felder werden wie folgt beschrieben:
Procs
•r: Die Anzahl der Prozesse in der Ausführungswarteschlange. Dieser Wert kann auch verwendet werden, um zu bestimmen, ob die CPU erhöht werden muss. (langfristig größer als 1)
•b: Die Anzahl der Prozesse, die auf E/A warten, d. h. die Anzahl der Prozesse im unterbrechungsfreien Ruhezustand, die die Anzahl der Aufgaben anzeigt, die ausgeführt werden und auf CPU-Ressourcen warten. Wenn dieser Wert die Anzahl der CPUs überschreitet, kommt es zu einem CPU-Engpass
Speicher
•swpd: Verwenden Sie die Größe des virtuellen Speichers. Wenn der Wert von swpd nicht 0 ist, die Werte von SI und SO jedoch für längere Zeit 0 sind, hat diese Situation keinen Einfluss auf die Systemleistung.
•frei: Freie physische Speichergröße.
•buff: Die Größe des als Puffer verwendeten Speichers.
•cache: Die als Cache verwendete Speichergröße bedeutet, dass sich viele Dateien im Cache befinden. Wenn Dateien, auf die häufig zugegriffen wird, zwischengespeichert werden können, ist die Lese-E/A-Bi der Festplatte sehr klein.
Swap (Wechselzone)
•si: Die pro Sekunde aus dem Swap-Bereich in den Speicher geschriebene Größe, die von der Festplatte in den Speicher übertragen wird.
•so: Die Speichergröße, die pro Sekunde in den Auslagerungsbereich geschrieben und vom Speicher auf die Festplatte übertragen wird.
Hinweis: Wenn der Speicher ausreichend ist, sind diese beiden Werte beide 0. Wenn diese beiden Werte über einen längeren Zeitraum größer als 0 sind, wird die Systemleistung beeinträchtigt, und die Festplatten-IO- und CPU-Ressourcen werden beeinträchtigt verzehrt werden. Einige Freunde denken, dass der Speicher nicht ausreicht, wenn sie sehen, dass der freie Speicher (frei) sehr klein oder nahe bei 0 ist. Sie können dies nicht nur betrachten, sondern auch si usw. kombinieren. Es gibt auch nur sehr wenige si usw. (Meistens ist es 0), dann machen Sie sich keine Sorgen, die Systemleistung wird zu diesem Zeitpunkt nicht beeinträchtigt.
IO (Eingabe und Ausgabe)
(Die Blockgröße der Linux-Version beträgt jetzt 1 KB)
•bi: Anzahl der pro Sekunde gelesenen Blöcke
•bo: Anzahl der pro Sekunde geschriebenen Blöcke
Hinweis: Beim Lesen und Schreiben von Zufallsdatenträgern gilt: Je größer diese beiden Werte sind (z. B. 1024 KB überschreiten), desto größer ist der Wert, an dem Sie erkennen können, dass die CPU auf E/A wartet.
System
•in: Anzahl der Interrupts pro Sekunde, einschließlich Taktinterrupts.
•cs: Anzahl der Kontextwechsel pro Sekunde.
Hinweis: Je größer die beiden oben genannten Werte sind, desto größer ist die vom Kernel verbrauchte CPU-Zeit.
CPU
(ausgedrückt als Prozentsatz)
•us: Prozentsatz der Ausführungszeit des Benutzerprozesses (Benutzerzeit). Wenn der Wert von uns relativ hoch ist, bedeutet dies, dass der Benutzerprozess viel CPU-Zeit verbraucht. Wenn die Auslastung jedoch über einen längeren Zeitraum 50 % überschreitet, sollten wir eine Optimierung oder Beschleunigung des Programmalgorithmus in Betracht ziehen.
•sy: Prozentsatz der Ausführungszeit des Kernel-Systemprozesses (Systemzeit). Wenn der Wert von sy hoch ist, bedeutet dies, dass der Systemkern viele CPU-Ressourcen verbraucht. Dies ist keine harmlose Leistung und wir sollten den Grund überprüfen.
•wa: Prozentsatz der E/A-Wartezeit. Wenn der Wert von wa hoch ist, bedeutet dies, dass die E/A-Wartezeit schwerwiegend ist. Dies kann durch eine große Anzahl zufälliger Zugriffe auf die Festplatte verursacht werden oder es liegt möglicherweise ein Engpass (Blockvorgang) auf der Festplatte vor.
•id: Prozentsatz der Leerlaufzeit
Wie Sie aus vmstat ersehen können, wird die meiste Zeit der CPU mit dem Warten auf E/A verschwendet, was durch eine große Anzahl zufälliger Festplattenzugriffe oder durch eine Festplattenbandbreite von mehr als 1024 KB verursacht werden kann, was auf einen E/A-Engpass hinweisen sollte.
2,2 IostatLassen Sie uns ein professionelleres Festplatten-IO-Diagnosetool verwenden, um die relevanten Statistiken anzuzeigen.
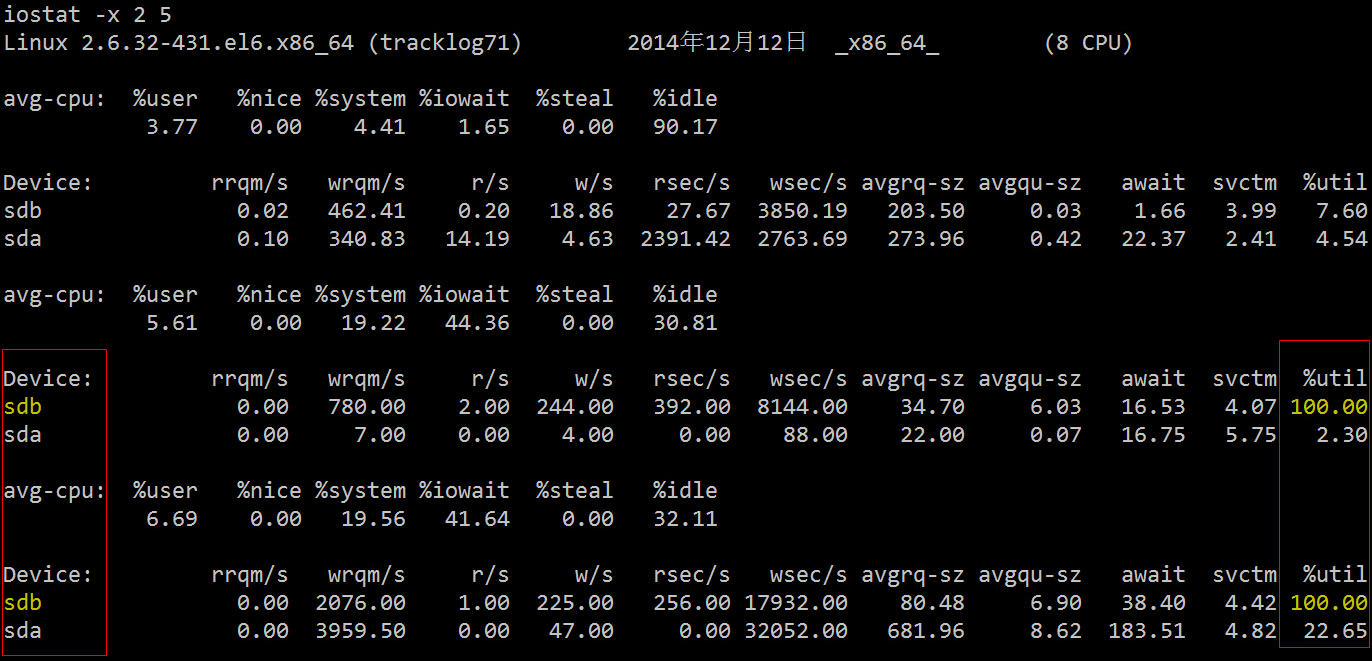
Die zugehörigen Felder werden wie folgt beschrieben:
•rrqm/s: Die Anzahl der Merge-Lesevorgänge pro Sekunde. Das ist Delta(rmerge)/s
•wrqm/s: Die Anzahl der Merge-Schreibvorgänge pro Sekunde. Das ist Delta(wmerge)/s
•r/s: Die Anzahl der pro Sekunde abgeschlossenen Lesevorgänge vom E/A-Gerät. Das ist Delta(rio)/s
•w/s: Anzahl der pro Sekunde abgeschlossenen Schreibvorgänge auf das E/A-Gerät. Das ist Delta(wio)/s
•rsec/s: Anzahl der pro Sekunde gelesenen Sektoren. Das ist Delta(rsect)/s
•wsec/s: Anzahl der pro Sekunde geschriebenen Sektoren. Das ist Delta(wsect)/s
•rkB/s: K Bytes, die pro Sekunde gelesen werden. Ist die Hälfte von rsect/s, da jeder Sektor 512 Byte groß ist. (muss berechnet werden)
•wkB/s: Anzahl der pro Sekunde geschriebenen K-Bytes. ist die Hälfte von wsect/s. (muss berechnet werden)
•avgrq-sz: Durchschnittliche Datengröße (Sektoren) pro Geräte-E/A-Vorgang. delta(rsect+wsect)/delta(rio+wio)
•avgqu-sz: Durchschnittliche E/A-Warteschlangenlänge. Das ist delta(aveq)/s/1000 (da die Einheit von aveq Millisekunden ist).
•await: durchschnittliche Wartezeit (Millisekunden) für jeden Geräte-E/A-Vorgang. Das ist delta(ruse+wuse)/delta(rio+wio)
•svctm: Durchschnittliche Servicezeit (Millisekunden) pro Geräte-E/A-Vorgang. Das ist Delta(use)/delta(rio+wio)
•%util: Wie viel Prozent einer Sekunde werden für E/A-Vorgänge verwendet oder wie viel Sekunden lang ist die E/A-Warteschlange nicht leer. Das ist Delta(Nutzung)/s/1000 (da die Nutzungseinheit Millisekunden ist)
Sie können sehen, dass die SDB-Auslastung auf den beiden Festplatten 100 % erreicht hat und ein schwerwiegender E/A-Engpass vorliegt. Der nächste Schritt besteht darin, herauszufinden, welcher Prozess Daten auf diese Festplatte liest und schreibt.
2.3 iotop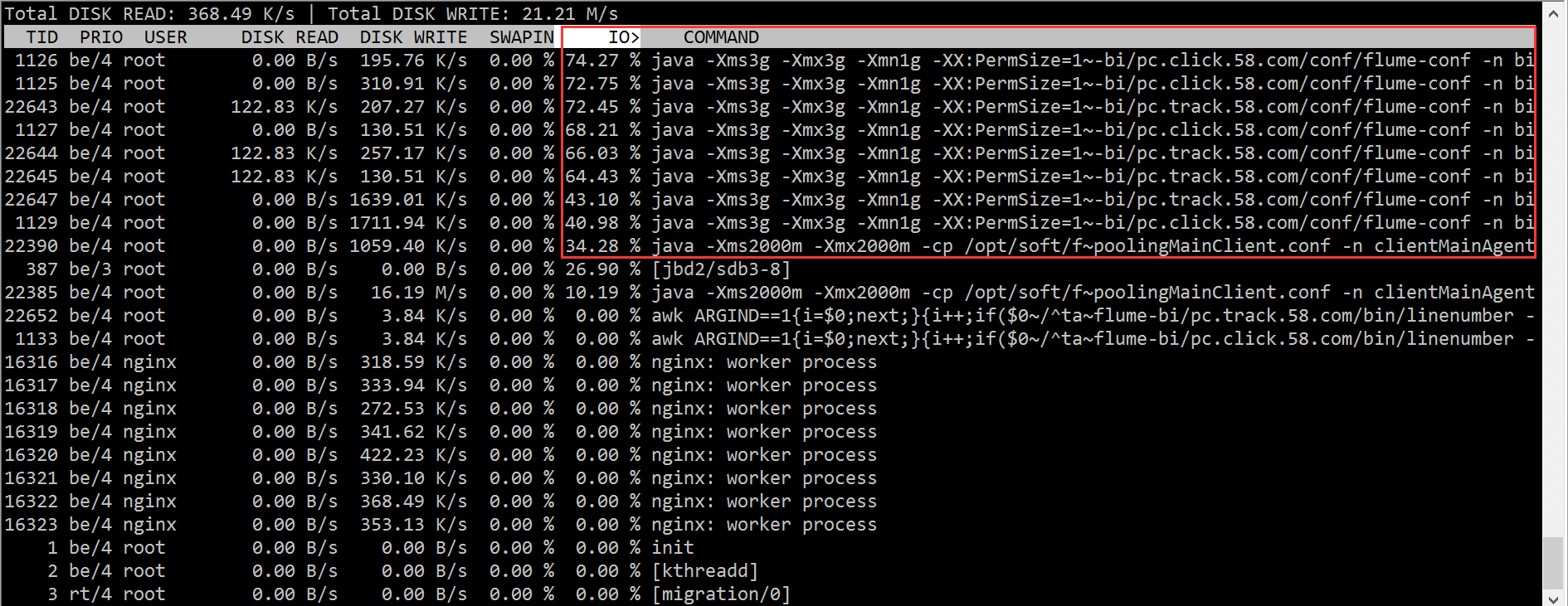
Den iotop-Ergebnissen zufolge haben wir das Problem mit dem Flume-Prozess, der eine große Anzahl von IO-Wartezeiten verursachte, schnell lokalisiert.
Aber wie ich eingangs sagte, sind die Maschinenkonfigurationen im Cluster dieselben und die bereitgestellten Programme sind genau die gleichen wie die, die von rsync verwendet werden. Könnte es sein, dass die Festplatte kaputt ist?
Dies muss von einem Betriebs- und Wartungsstudenten überprüft werden. Die endgültige Schlussfolgerung lautet:
Sdb ist ein Dual-Disk-RAID1, die verwendete RAID-Karte ist „LSI Logic/Symbios Logic SAS1068E“ und es gibt keinen Cache. Der Druck von fast 400 IOPS hat das Hardware-Limit erreicht. Die von anderen Maschinen verwendete RAID-Karte ist „LSI Logic / Symbios Logic MegaRAID SAS 1078“, die über einen 256 MB Cache verfügt und den Hardware-Engpass nicht erreicht hat. Die Lösung besteht darin, die Maschine durch eine größere IOPS zu ersetzen zu einer Maschine mit PERC6 /i Maschinen mit integrierten RAID-Controllerkarten. Es ist zu beachten, dass die RAID-Informationen in der RAID-Karte und der Festplatten-Firmware gespeichert sind. Die RAID-Informationen auf der Festplatte und das Informationsformat auf der RAID-Karte müssen übereinstimmen. Andernfalls kann die RAID-Karte sie nicht erkennen und die Festplatte muss es sein formatiert.
IOPS hängt im Wesentlichen von der Festplatte selbst ab, aber es gibt viele Möglichkeiten, IOPS zu verbessern. Das Hinzufügen von Hardware-Cache und die Verwendung von RAID-Arrays sind gängige Methoden. Wenn es sich um ein Szenario wie DB mit hohen IOPS handelt, ist es mittlerweile beliebt, SSDs als Ersatz für herkömmliche mechanische Festplatten zu verwenden.
Aber wie bereits erwähnt, besteht unser Ziel sowohl bei der Software als auch bei der Hardware darin, herauszufinden, ob wir jeweils die kostengünstigste Lösung finden können:
Da wir nun den Hardware-Grund kennen, können wir versuchen, die Lese- und Schreibvorgänge auf eine andere Festplatte zu verschieben und dann die Auswirkung sehen:
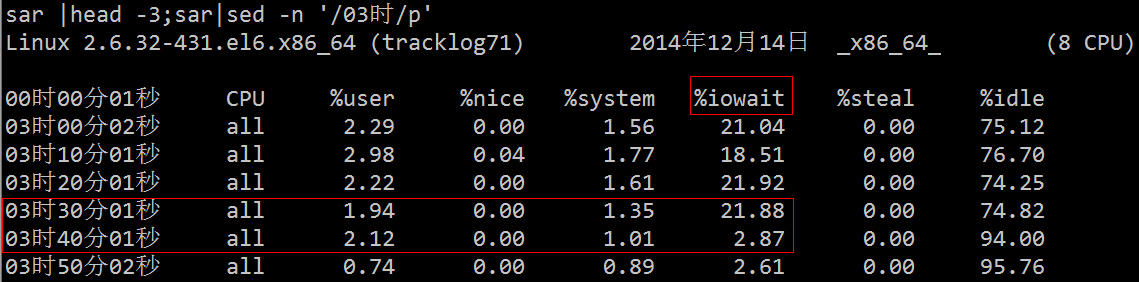
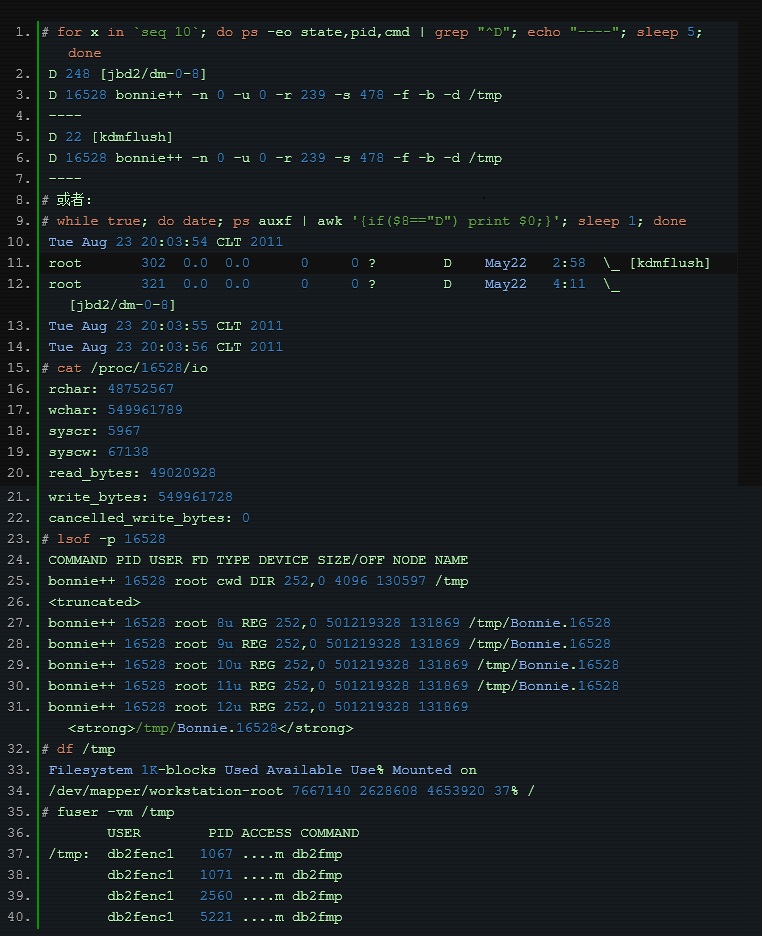
Tatsächlich können wir zusätzlich zur Verwendung der oben genannten professionellen Tools zur Lokalisierung dieses Problems direkt den Prozessstatus verwenden, um die relevanten Prozesse zu finden.
Wir wissen, dass der Prozess die folgenden Zustände hat:
•D ununterbrochener Schlaf (normalerweise IO)
•R läuft oder ausführbar (in der Ausführungswarteschlange)
•S unterbrechbarer Schlaf (Warten auf den Abschluss eines Ereignisses)
•T gestoppt, entweder durch ein Jobkontrollsignal oder weil es verfolgt wird.
•W-Paging (nicht gültig seit dem 2.6.xx-Kernel)
•X tot (sollte niemals gesehen werden)
•Z nicht mehr existierender („Zombie“)-Prozess, beendet, aber nicht von seinem übergeordneten Prozess geerntet.
Der Zustand von D ist im Allgemeinen der sogenannte „nicht unterbrechbare Schlaf“, der durch Warte-IO verursacht wird. Wir können von diesem Punkt aus beginnen und das Problem dann Schritt für Schritt lokalisieren:
Das obige ist der detaillierte Inhalt vonEntdecken Sie neue Wege – Diagnosetool für IO-Warten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































