


Bei der CTR-Schätzung verwendet die Mainstream-Methode Feature-Einbettung + MLP, wobei Features sehr wichtig sind. Für dieselben Merkmale ist die Darstellung jedoch in verschiedenen Stichproben gleich. Diese Art der Eingabe in das nachgeschaltete Modell schränkt die Ausdrucksfähigkeit des Modells ein.
Um dieses Problem zu lösen, wurde eine Reihe verwandter Arbeiten im Bereich der CTR-Schätzung vorgeschlagen, die als Feature-Enhancement-Modul bezeichnet werden. Das Feature-Enhancement-Modul korrigiert die Ausgabeergebnisse der Einbettungsschicht basierend auf verschiedenen Samples, um sie an die Feature-Darstellung verschiedener Samples anzupassen und die Ausdrucksfähigkeit des Modells zu verbessern.
Kürzlich haben die Fudan University und Microsoft Research Asia gemeinsam einen Bericht über die Arbeit zur Funktionsverbesserung veröffentlicht, in dem die Implementierungsmethoden und Auswirkungen verschiedener Funktionserweiterungsmodule verglichen werden. Lassen Sie uns nun die Implementierungsmethoden mehrerer Feature-Enhancement-Module sowie die zugehörigen Vergleichsexperimente vorstellen, die in diesem Artikel durchgeführt werden
 Titel des Papiers: Eine umfassende Zusammenfassung und Bewertung von Feature-Refinement-Modulen für die CTR-Vorhersage
Titel des Papiers: Eine umfassende Zusammenfassung und Bewertung von Feature-Refinement-Modulen für die CTR-Vorhersage
Download-Adresse: https ://arxiv.org/pdf/2311.04625v1.pdf
Das Funktionsverbesserungsmodul soll die Ausdrucksfähigkeit der Einbettungsschicht im CTR-Vorhersagemodell verbessern und eine Differenzierung derselben Funktionen erreichen in verschiedenen Proben. Das Funktionserweiterungsmodul kann durch die folgende einheitliche Formel ausgedrückt werden: Geben Sie die ursprüngliche Einbettung ein und generieren Sie nach Übergabe einer Funktion die personalisierte Einbettung dieses Beispiels.
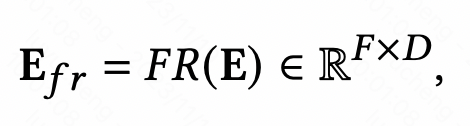 Bilder
Bilder
Die allgemeine Idee dieser Methode besteht darin, nach Erhalt der anfänglichen Einbettung jedes Features die Darstellung des Beispiels selbst zu verwenden, um die Feature-Einbettung zu transformieren und die personalisierte Einbettung des aktuellen Beispiels zu erhalten. Hier stellen wir einige klassische Modellierungsmethoden für Funktionserweiterungsmodule vor.
Eine eingabebewusste Faktorisierungsmaschine für die spärliche Vorhersage (IJCAI 2019) Dieser Artikel fügt nach der Einbettungsschicht eine Neugewichtungsschicht hinzu und gibt die anfängliche Einbettung der Probe in einen MLP ein, um eine Darstellung zu erhalten der Probe. Vektoren, normalisiert mit Softmax. Jedes Element nach Softmax entspricht einem Merkmal und stellt die Wichtigkeit dieses Merkmals dar. Dieses Softmax-Ergebnis wird mit der anfänglichen Einbettung jedes entsprechenden Merkmals multipliziert, um eine Gewichtung der Merkmalseinbettung bei Stichprobengranularität zu erreichen.
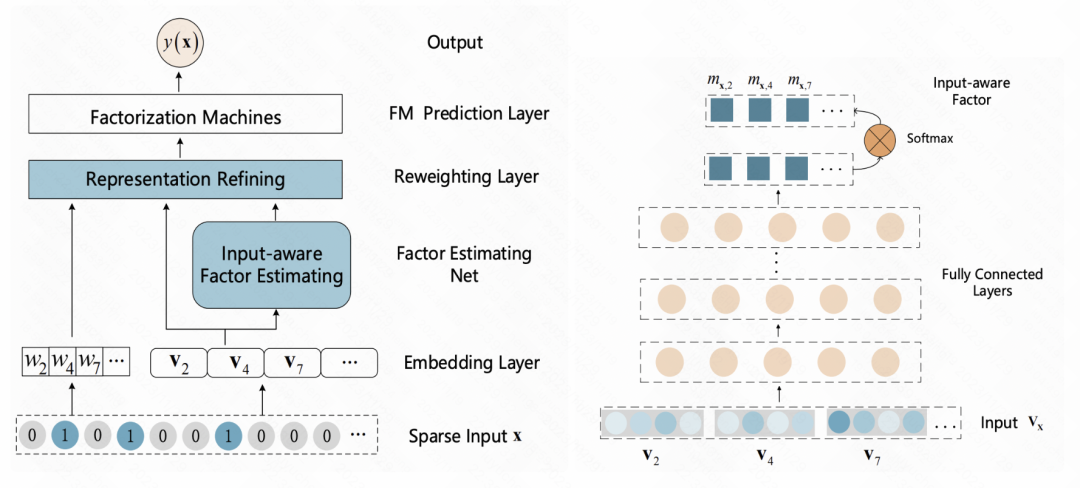 Bilder
Bilder
FiBiNET: Das Modell zur Vorhersage der Klickrate, das Merkmalswichtigkeit und Merkmalsinteraktion zweiter Ordnung kombiniert (RecSys 2019), übernimmt ebenfalls eine ähnliche Idee. Das Modell lernt für jede Stichprobe eine personalisierte Gewichtung eines Merkmals. Der gesamte Prozess ist in drei Schritte unterteilt: Auspressen, Extrahieren und Nachgewichten. In der Squeezing-Phase wird der Einbettungsvektor jedes Merkmals durch die Pooling-Methode als statistischer Skalar erhalten. In der Extraktionsphase werden diese Skalare in ein mehrschichtiges Perzeptron (MLP) eingegeben, um das Gewicht jedes Merkmals zu erhalten. Schließlich werden diese Gewichte mit dem Einbettungsvektor jedes Merkmals multipliziert, um das gewichtete Einbettungsergebnis zu erhalten, was dem Filtern der Merkmalswichtigkeit auf Stichprobenebene entspricht. IJCAI 2020) ähnelt dem vorherigen Artikel und nutzt auch die Selbstaufmerksamkeit, um Funktionen zu verbessern. Das Ganze ist in zwei Module unterteilt: vektorweise und bitweise. Vektorweise behandelt die Einbettung jedes Features als Element in der Sequenz und gibt es in den Transformer ein, um die fusionierte Feature-Darstellung zu erhalten. Der bitweise Teil verwendet mehrschichtiges MLP, um die ursprünglichen Features abzubilden. Nachdem die Eingabeergebnisse der beiden Teile addiert wurden, wird das Gewicht jedes Merkmalselements ermittelt und mit jedem Bit des entsprechenden Originalmerkmals multipliziert, um das erweiterte Merkmal zu erhalten.
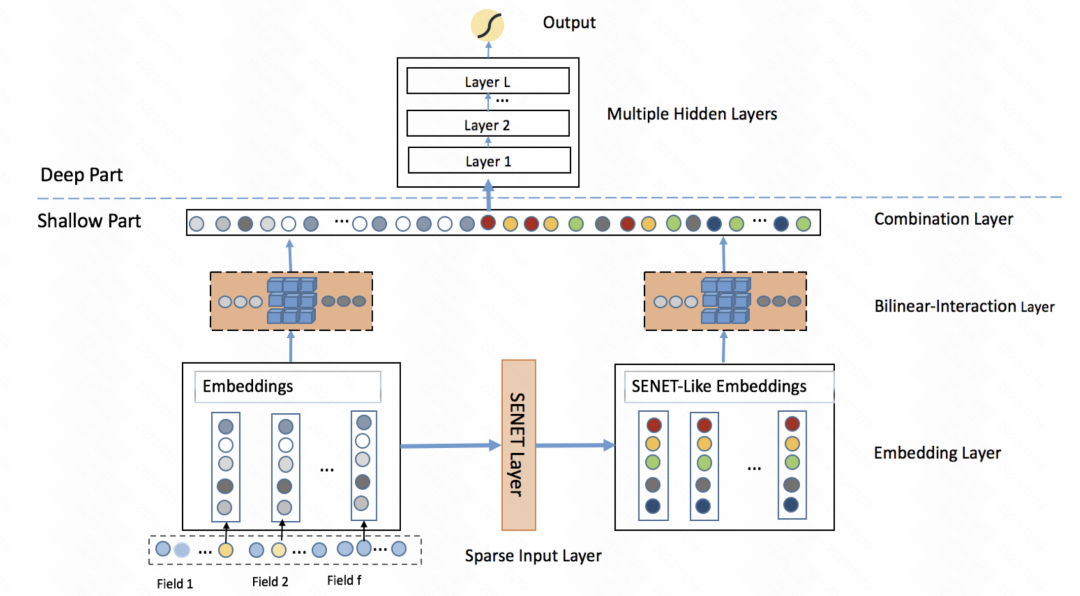 Image
Image
GateNet: Enhanced Gated Deep Network for Click-through-Rate Prediction (2020) Nutzt den anfänglichen Einbettungsvektor jedes Features, um seine unabhängige Feature-Gewichtungsbewertung über eine MLP- und Sigmoid-Funktion zu generieren, während MLP zum Kombinieren verwendet wird Alle Features werden bitweisen Gewichtungswerten zugeordnet, und die beiden werden kombiniert, um die Eingabefeatures zu gewichten. Zusätzlich zur Feature-Ebene wird in der verborgenen Ebene von MLP auch eine ähnliche Methode verwendet, um die Eingabe jeder verborgenen Ebene zu gewichten
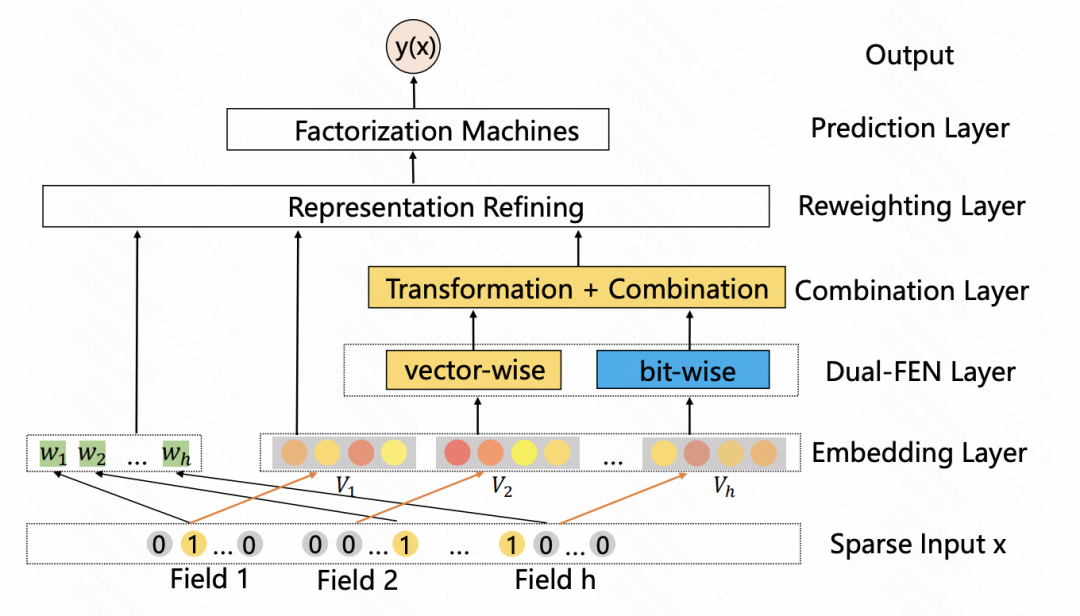 Bild
Bild
Interpretierbare Click-Through-Rate-Vorhersage durch hierarchische Aufmerksamkeit (WSDM 2020) nutzt ebenfalls Selbstaufmerksamkeit, um eine Feature-Konvertierung zu erreichen, fügt jedoch die Generierung von Features höherer Ordnung hinzu. Hier wird hierarchische Selbstaufmerksamkeit verwendet. Jede Schicht der Selbstaufmerksamkeit verwendet die Ausgabe der vorherigen Schicht als Eingabe. Jede Schicht fügt eine Merkmalskombination erster Ordnung hinzu, um eine hierarchische Merkmalsextraktion mehrerer Ordnung zu erreichen. Insbesondere wird die generierte neue Feature-Matrix nach der Durchführung der Selbstaufmerksamkeit durch Softmax geleitet, um das Gewicht jedes Features zu erhalten. Die neuen Features werden entsprechend den Gewichten der ursprünglichen Features gewichtet und anschließend ein Skalarprodukt durchgeführt mit den ursprünglichen Merkmalen, um eine Erhöhung der charakteristischen Schnittmenge der Ebenen zu erreichen.
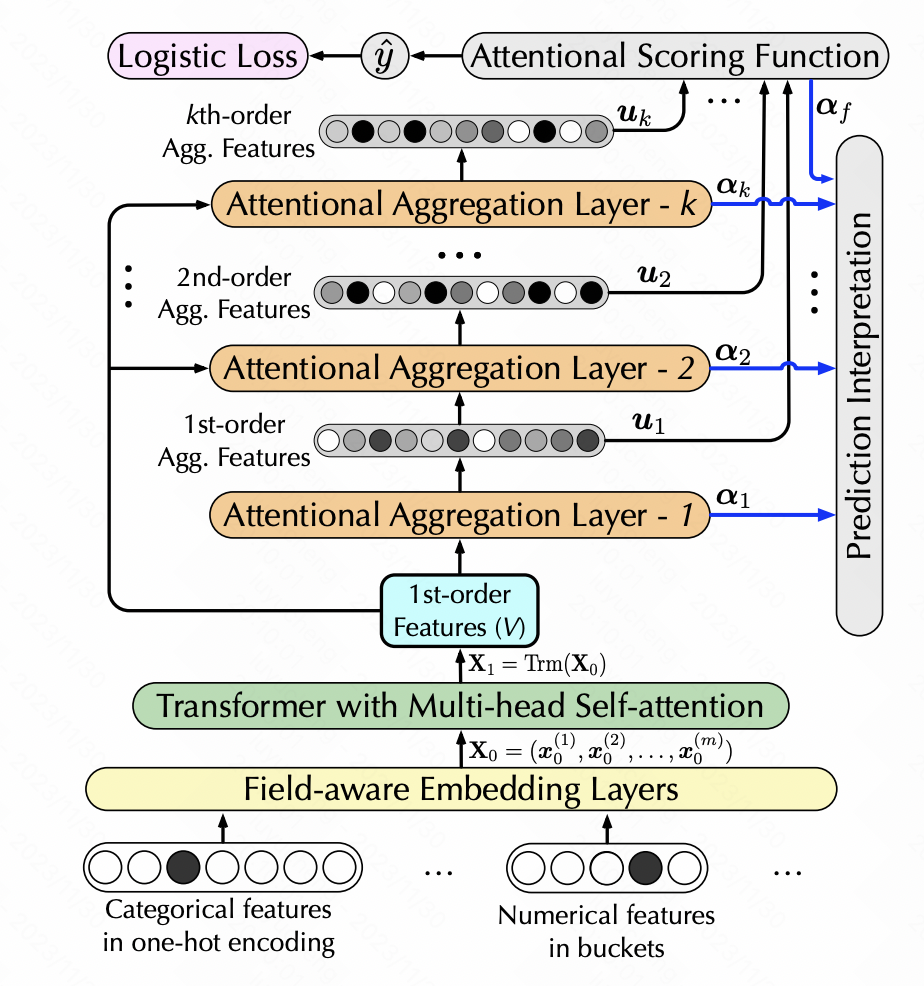 Pictures
Pictures
ContextNet: A Click-Through Rate Prediction Framework Using Contextual information to Refine Feature Embedding (2021) ist ebenfalls ein ähnlicher Ansatz, bei dem ein MLP verwendet wird, um alle Features in einer Dimension jeder Feature-Einbettungsgröße abzubilden, z Die ursprünglichen Features werden skaliert und für jedes Feature werden personalisierte MLP-Parameter verwendet. Auf diese Weise wird jedes Merkmal verbessert, indem andere Merkmale im Beispiel als obere und untere Bits verwendet werden.
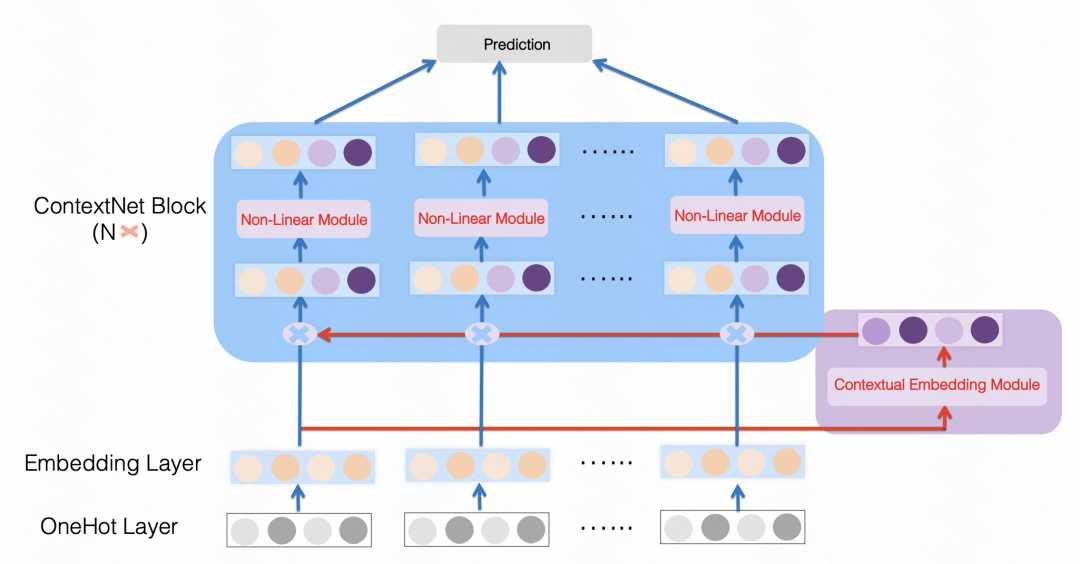 Bilder
Bilder
Enhancing CTR Prediction with Context-Aware Feature Representation Learning (SIGIR 2022) nutzt die Selbstaufmerksamkeit zur Funktionsverbesserung. Bei einer Reihe von Eingabefunktionen ist der Grad des Einflusses jeder Funktion auf andere Funktionen unterschiedlich. Durch Selbstaufmerksamkeit wird die Einbettung jedes Merkmals selbst durchgeführt, um eine Informationsinteraktion zwischen Merkmalen innerhalb der Stichprobe zu erreichen. Zusätzlich zur Interaktion zwischen Funktionen verwendet der Artikel MLP auch für die Informationsinteraktion auf Bitebene. Die oben generierte neue Einbettung wird über ein Gate-Netzwerk mit der ursprünglichen Einbettung zusammengeführt, um die endgültige verfeinerte Merkmalsdarstellung zu erhalten.
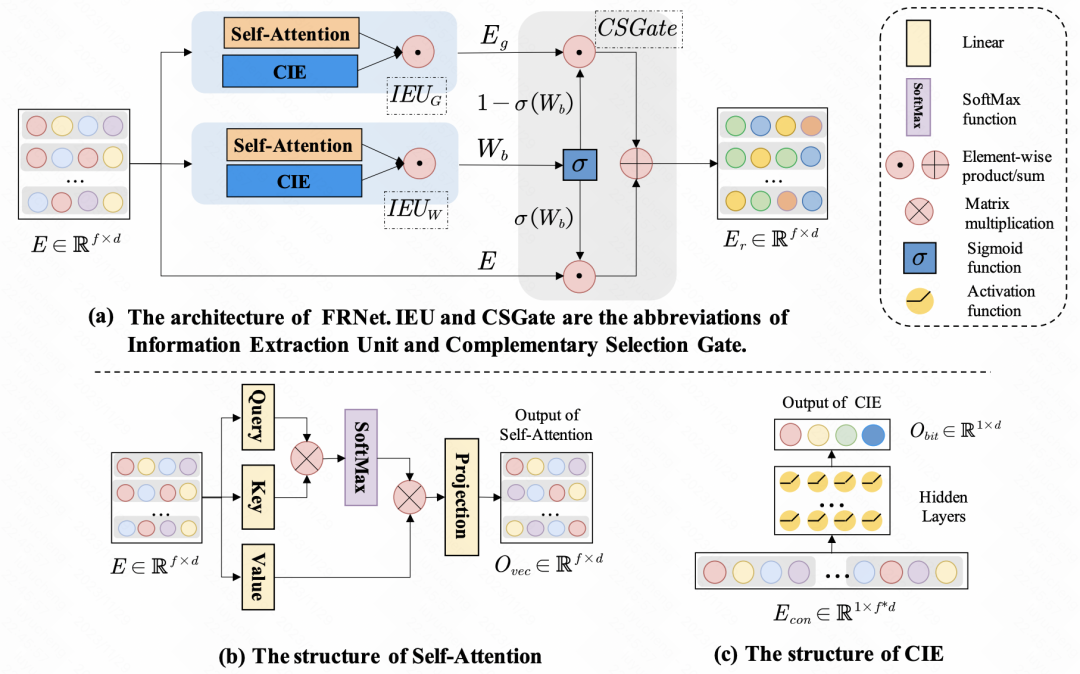 Bilder
Bilder
Nachdem wir die Auswirkungen verschiedener Methoden zur Funktionsverbesserung verglichen hatten, kamen wir zu dem Gesamtschluss: Unter vielen Modulen zur Funktionsverbesserung schneiden GFRL, FRNet-V und FRNetB am besten ab Der Effekt ist besser als bei anderen Methoden zur Funktionsverbesserung
Das obige ist der detaillierte Inhalt vonDieser Artikel fasst die klassischen Methoden und den Effektvergleich der Funktionsverbesserung und Personalisierung bei der CTR-Schätzung zusammen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in die Verwendung des gesamten VBS-Codes
Einführung in die Verwendung des gesamten VBS-Codes
 So wechseln Sie zwischen voller und halber Breite
So wechseln Sie zwischen voller und halber Breite
 So zeigen Sie zwei Divs nebeneinander an
So zeigen Sie zwei Divs nebeneinander an
 Drei häufig verwendete Kodierungsmethoden
Drei häufig verwendete Kodierungsmethoden
 Eine vollständige Liste der Tastenkombinationen für Ideen
Eine vollständige Liste der Tastenkombinationen für Ideen
 c/s-Architektur und b/s-Architektur
c/s-Architektur und b/s-Architektur
 Was ist der Unterschied zwischen MySQL und MSSQL?
Was ist der Unterschied zwischen MySQL und MSSQL?
 Was sind die Hauptfunktionen von Redis?
Was sind die Hauptfunktionen von Redis?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



