


Open-Source-Modelle zeigen ihre kraftvolle Vitalität, nicht nur die Zahl nimmt zu, auch die Leistung wird immer besser. Auch Turing-Award-Gewinner Yann LeCun beklagte: „Open-Source-Modelle für künstliche Intelligenz sind auf dem Weg, proprietäre Modelle zu übertreffen.“ Open-Source-Merkmale behindern die Entwicklung von LLM. Obwohl einige Open-Source-Modelle Praktikern und Forschern vielfältige Auswahlmöglichkeiten bieten, legen die meisten nur die endgültigen Modellgewichte oder den Inferenzcode offen, und immer mehr technische Berichte beschränken ihren Umfang auf Design und Oberflächenstatistiken auf oberster Ebene. Diese Closed-Source-Strategie schränkt nicht nur die Entwicklung von Open-Source-Modellen ein, sondern behindert auch den Fortschritt des gesamten LLM-Forschungsbereichs in großem Maße. Dies bedeutet, dass diese Modelle umfassender und tiefer geteilt werden müssen, einschließlich Trainingsdaten. Algorithmusdetails, Implementierungsherausforderungen und Details zur Leistungsbewertung.
Forscher von Cerebras, Petuum und MBZUAI haben gemeinsam LLM360 vorgeschlagen. Hierbei handelt es sich um eine umfassende Open-Source-LLM-Initiative, die sich dafür einsetzt, der Community alles rund um das LLM-Training zur Verfügung zu stellen, einschließlich Trainingscode und -daten, Modellkontrollpunkten und Zwischenergebnissen. Ziel von LLM360 ist es, den LLM-Ausbildungsprozess für alle transparent und reproduzierbar zu machen und so die Entwicklung einer offenen und kollaborativen Forschung im Bereich der künstlichen Intelligenz zu fördern.
 Papieradresse: https://arxiv.org/pdf/2312.06550.pdf
Papieradresse: https://arxiv.org/pdf/2312.06550.pdf
Werfen wir nun einen Blick auf die Details des Artikels? Vorschulungsprozess, um sicherzustellen, dass bestehende Arbeiten besser in der Gemeinschaft verbreitet und geteilt werden können. Es enthält hauptsächlich die folgenden Teile:

1. Trainingsdatensatz und Datenverarbeitungscode
Der Inhalt, der neu geschrieben werden muss, ist: 2. Trainingscode, Hyperparameter und Konfiguration
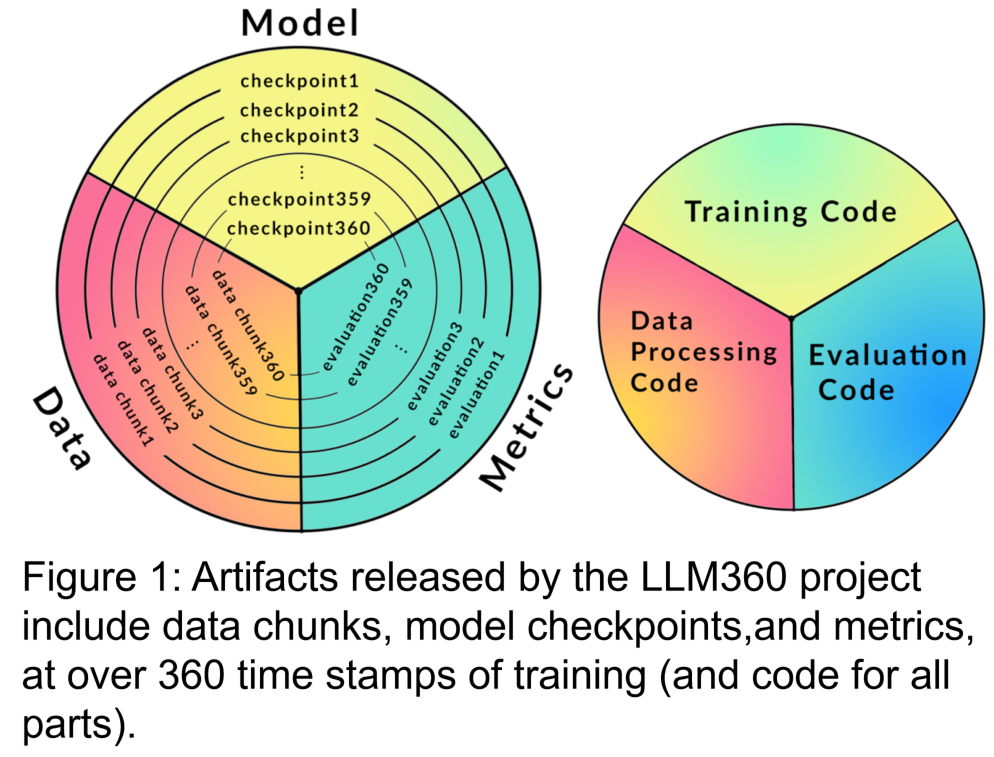
Trainingscode, Hyperparameter und Konfigurationen haben einen erheblichen Einfluss auf die Leistung und Qualität des LLM-Trainings, werden jedoch nicht immer öffentlich bekannt gegeben. In LLM360 veröffentlichen Forscher alle Trainingscodes, Trainingsparameter und Systemkonfigurationen des Pre-Training-Frameworks als Open Source.
3. Modellprüfpunkt wird umgeschrieben als: 3. Modellprüfpunkt
Es ist auch sehr nützlich, Modellprüfpunkte regelmäßig zu speichern. Sie sind nicht nur für die Fehlerbeseitigung während des Trainings von entscheidender Bedeutung, sondern sie sind auch nützlich für die Forschung nach dem Training. Diese Kontrollpunkte ermöglichen es nachfolgenden Forschern, das Modell von mehreren Ausgangspunkten aus weiter zu trainieren, was zur Reproduzierbarkeit und Verbesserung beiträgt. Tiefenforschung.
4. Leistungsindikatoren
Die Ausbildung eines LLM dauert oft Wochen bis Monate, und der Entwicklungstrend während der Ausbildung kann wertvolle Informationen liefern. Allerdings stehen detaillierte Protokolle und Zwischenmetriken der Ausbildung derzeit nur denjenigen zur Verfügung, die sie erlebt haben, was eine umfassende Forschung zu LLM erschwert. Diese Statistiken enthalten oft wichtige Erkenntnisse, die schwer zu erkennen sind. Schon eine einfache Analyse wie Varianzberechnungen zu diesen Maßen kann wichtige Erkenntnisse liefern. Das GLM-Forschungsteam schlug beispielsweise einen Gradientenschrumpfungsalgorithmus vor, der Verlustspitzen und NaN-Verluste effektiv bewältigt, indem er das Verhalten der Gradientenspezifikation analysiert.
AMBER ist das erste Mitglied der LLM360-„Familie“, und seine verfeinerten Versionen: AMBERCHAT und AMBERSAFE wurden ebenfalls veröffentlicht.

Was neu geschrieben werden muss: Daten und Modelldetails
Tabelle 2 enthält Einzelheiten zum Vortrainingsdatensatz von AMBER, der 1,26 T-Marker enthält. Dazu gehören Datenvorverarbeitungsmethoden, Formate, Datenmischungsverhältnisse sowie Architekturdetails und spezifische Pretraining-Hyperparameter des AMBER-Modells. Detaillierte Informationen finden Sie auf der Projekthomepage der LLM360-Codebasis
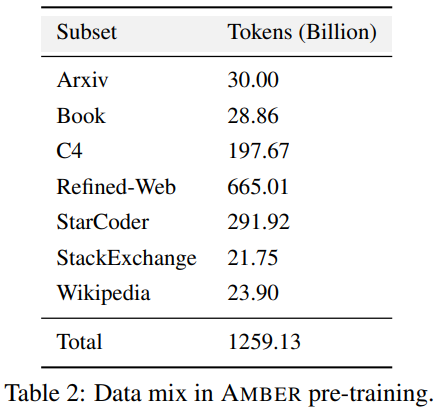
AMBER übernimmt die gleiche Modellstruktur wie LLaMA 7B4. Tabelle 3 fasst die detaillierte Strukturkonfiguration von LLM
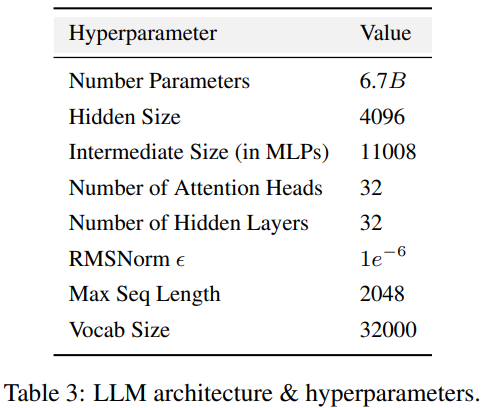
im Voraus In Bezug auf Training und Hyperparameter versuchten die Forscher ihr Bestes, den Hyperparametern von LLaMA vor dem Training zu folgen. AMBER wird mit dem AdamW-Optimierer trainiert und die Hyperparameter sind: β₁=0,9, β₂=0,95. Darüber hinaus haben Forscher mehrere fein abgestimmte Versionen von AMBER veröffentlicht: AMBERCHAT und AMBERSAFE. AMBERCHAT ist auf der Grundlage des Schulungsdatensatzes von WizardLM optimiert. Weitere Parameterdetails finden Sie im Originaltext
Um den Zweck zu erreichen, die ursprüngliche Bedeutung nicht zu ändern, muss der Inhalt ins Chinesische umgeschrieben werden. Das Folgende ist eine Neufassung von „Experimente und Ergebnisse“: Führen Sie Experimente und Ergebnisanalysen durch
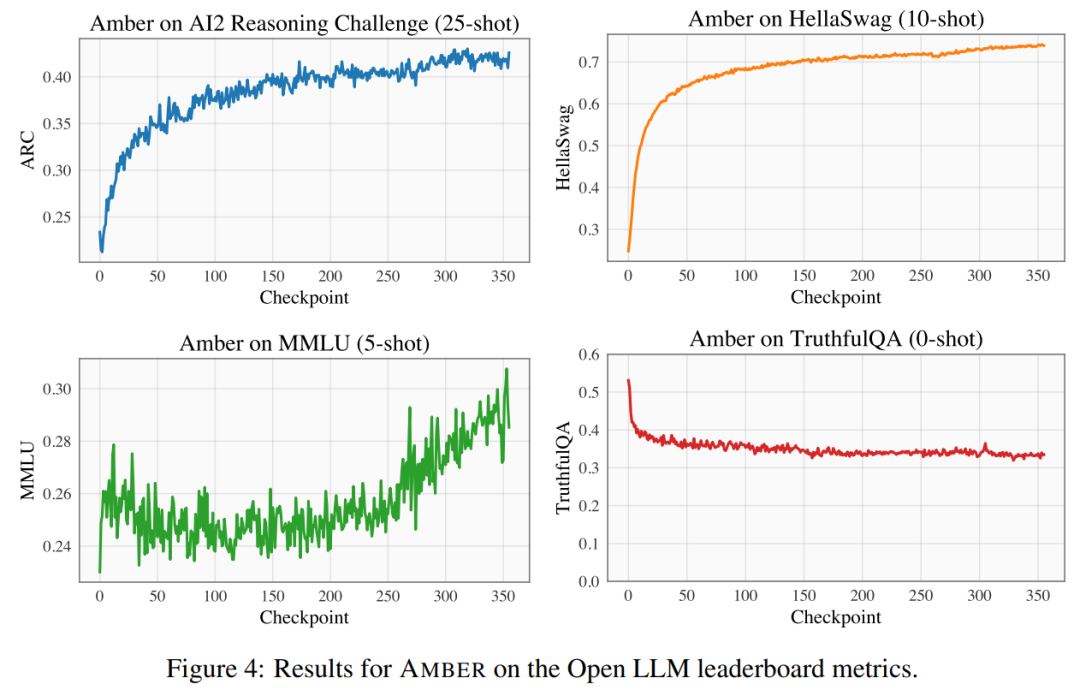
Die Forscher verwendeten vier Benchmark-Datensätze zu den Open LLM-Rankings, um die Leistung von AMBER zu bewerten. Wie in Abbildung 4 dargestellt, steigt der AMBER-Score in den HellaSwag- und ARC-Datensätzen während der Zeit vor dem Training allmählich an, während im TruthfulQA-Datensatz der Score mit fortschreitendem Training abnimmt. Im MMLU-Datensatz sank die Punktzahl von AMBER in der Anfangsphase des Vortrainings und begann dann zu steigen. In Tabelle 4 verglich der Forscher die Modellleistung von AMBER mit OpenLLaMA, RedPajama-INCITE, Falcon und MPT-Modelle, die in ähnlichen Zeiträumen trainiert wurden, wurden verglichen. Viele Modelle sind von LLaMA inspiriert. Es zeigt sich, dass AMBER bei MMLU besser abschneidet, bei ARC jedoch etwas schlechter. Die Leistung von AMBER ist im Vergleich zu anderen ähnlichen Modellen relativ stark.
CRYSTALCODER
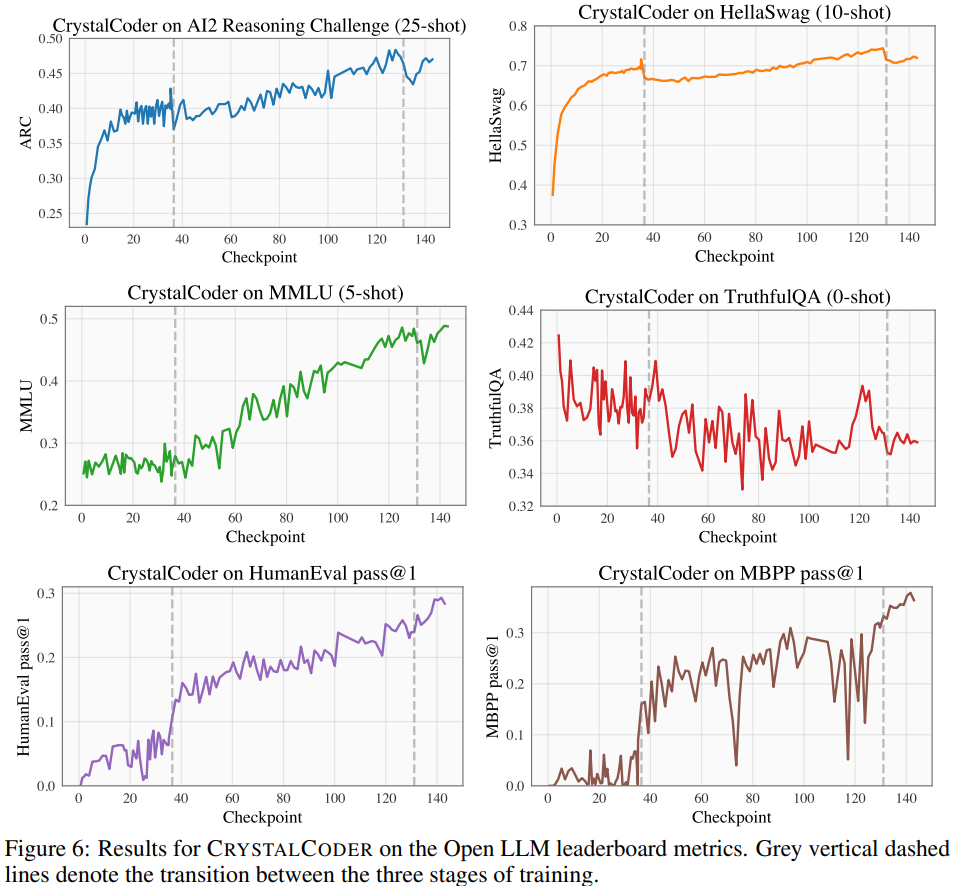
Das zweite Mitglied der LLM360-„Familie“ ist CrystalCoder. 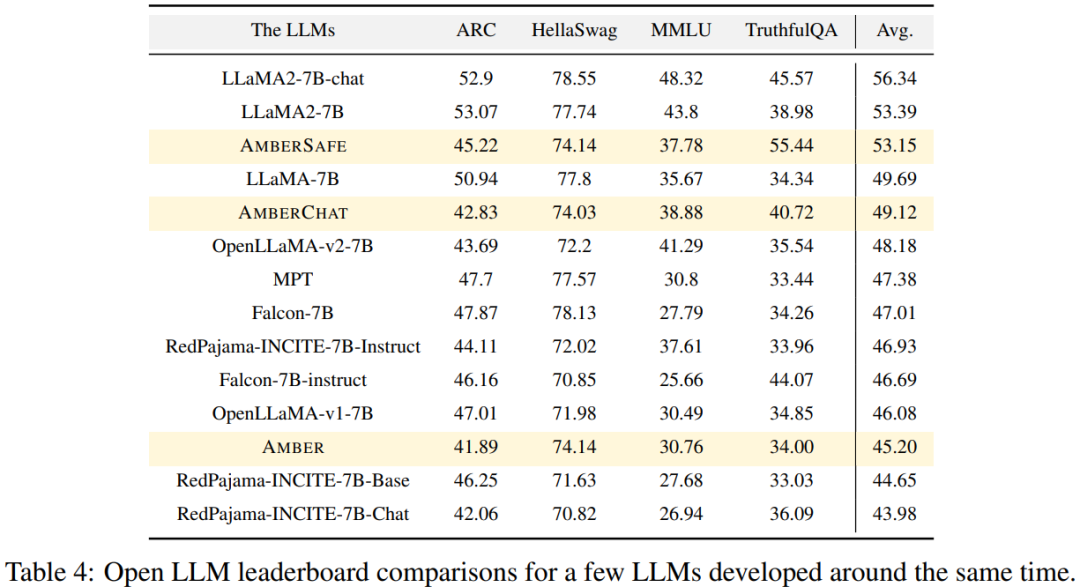
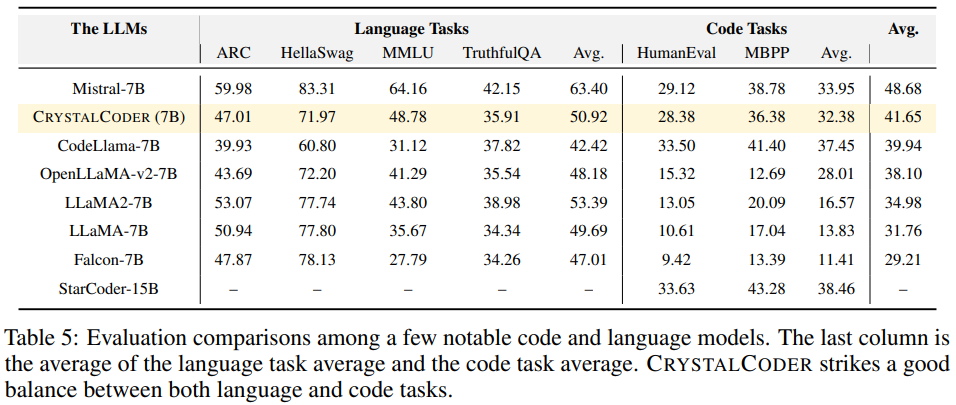
CrystalCoder ist ein 7B-Sprachmodell, das auf 1,4-T-Tokens trainiert wird und ein Gleichgewicht zwischen Codierungs- und Sprachfähigkeiten erreicht. Im Gegensatz zu den meisten früheren Code-LLMs wird CrystalCoder auf einer sorgfältigen Mischung aus Text- und Codedaten trainiert, um den Nutzen in beiden Bereichen zu maximieren. Im Vergleich zu Code Llama 2 werden die Codedaten von CrystalCoder früher im Vortrainingsprozess eingeführt. Darüber hinaus trainierten die Forscher CrystalCoder in Python und Web-Programmiersprachen, um seinen Nutzen als Programmierassistent zu verbessern.
Neu erstellte Modellarchitektur
CrystalCoder übernimmt eine Architektur, die LLaMA 7B sehr ähnlich ist, und fügt Maximum Update Parametrization (muP) hinzu. Zusätzlich zu dieser spezifischen Parametrisierung nahmen die Forscher auch einige Modifikationen vor. Darüber hinaus verwendeten die Forscher auch LayerNorm anstelle von RMSNorm, da die CG-1-Architektur eine effiziente Berechnung von LayerNorm unterstützt.
Um den Zweck zu erreichen, die ursprüngliche Bedeutung nicht zu ändern, muss der Inhalt ins Chinesische umgeschrieben werden. Das Folgende ist eine Neufassung von „Experimente und Ergebnisse“: Durchführung von Experimenten und Ergebnisanalyse
Auf dem Open LLM Leaderboard führten die Forscher Benchmark-Tests für das Modell durch, darunter vier Benchmark-Datensätze und Codierungs-Benchmark-Datensätze. Wie in Abbildung 6 dargestellt. Durch die Analyse von Zwischenkontrollpunkten des Modells ist eine eingehende Untersuchung möglich. Die Forscher hoffen, dass LLM360 der Community eine nützliche Referenz- und Forschungsressource bieten wird. Zu diesem Zweck veröffentlichten sie die erste Version des ANALYSIS360-Projekts, ein organisiertes Repository für eine vielschichtige Analyse des Modellverhaltens, einschließlich Modelleigenschaften und nachgelagerter Bewertungsergebnisse
 als Beispiel für die Analyse über eine Reihe von Modellkontrollpunkten Forscher führten eine vorläufige Studie zum Auswendiglernen im LLM durch. Neuere Untersuchungen haben gezeigt, dass LLMs große Teile der Trainingsdaten speichern können und dass diese Daten mit entsprechenden Eingabeaufforderungen abgerufen werden können. Diese Memoisierung hat nicht nur Probleme mit der Weitergabe privater Trainingsdaten, sondern kann auch die LLM-Leistung beeinträchtigen, wenn die Trainingsdaten Wiederholungen oder Besonderheiten enthalten. Die Forscher haben alle Kontrollpunkte und Daten veröffentlicht, damit eine umfassende Analyse des Auswendiglernens während der gesamten Trainingsphase durchgeführt werden kann
als Beispiel für die Analyse über eine Reihe von Modellkontrollpunkten Forscher führten eine vorläufige Studie zum Auswendiglernen im LLM durch. Neuere Untersuchungen haben gezeigt, dass LLMs große Teile der Trainingsdaten speichern können und dass diese Daten mit entsprechenden Eingabeaufforderungen abgerufen werden können. Diese Memoisierung hat nicht nur Probleme mit der Weitergabe privater Trainingsdaten, sondern kann auch die LLM-Leistung beeinträchtigen, wenn die Trainingsdaten Wiederholungen oder Besonderheiten enthalten. Die Forscher haben alle Kontrollpunkte und Daten veröffentlicht, damit eine umfassende Analyse des Auswendiglernens während der gesamten Trainingsphase durchgeführt werden kann
Das Folgende ist die in diesem Artikel verwendete Methode zur Bewertung des Auswendiglernens Die nachfolgende Länge beträgt l Die Genauigkeit des Tokens. Informationen zu den spezifischen Speicherbewertungseinstellungen finden Sie im Originalartikel.
Die Memoisierungspunktzahlverteilung von 10 ausgewählten Prüfpunkten ist in Abbildung 7 dargestellt Die Gruppe für jeden Kontrollpunkt ist in Abbildung 8 dargestellt. Sie fanden heraus, dass AMBER-Kontrollpunkte die neuesten Daten besser speichern als die vorherigen Daten. Darüber hinaus nimmt der Memoisierungswert für jeden Datenblock nach zusätzlichem Training leicht ab, steigt dann aber weiter an.
Abbildung 9 zeigt die Korrelation zwischen Sequenzen in Memoization-Scores und extrahierbaren k-Werten. Es ist ersichtlich, dass zwischen den Kontrollpunkten eine starke Korrelation besteht.
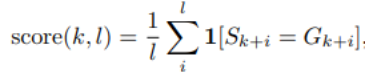 Zusammenfassung
Zusammenfassung
Der Forscher fasste die Beobachtungen und einige Implikationen von AMBER und CRYSTALCODER zusammen. Sie sagen, dass die Vorschulung eine rechenintensive Aufgabe ist, die sich viele akademische Labore oder kleine Institutionen nicht leisten können. Sie hoffen, dass LLM360 umfassendes Wissen vermitteln und den Benutzern ermöglichen kann, zu verstehen, was während des LLM-Vortrainings passiert, ohne es selbst tun zu müssen
Bitte überprüfen Sie den Originaltext für weitere Details
Das obige ist der detaillierte Inhalt vonDer LLM360 des Xingbo-Teams ist eine umfassende Open-Source-Lösung ohne Sackgassen und macht große Modelle wirklich transparent. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 Die heutigen neuesten offiziellen Nachrichten von PaiCoin sind wahr
Die heutigen neuesten offiziellen Nachrichten von PaiCoin sind wahr
 So zentrieren Sie ein Div in CSS
So zentrieren Sie ein Div in CSS
 So implementieren Sie die JSP-Paging-Funktion
So implementieren Sie die JSP-Paging-Funktion
 Werbung bewerben
Werbung bewerben
 WeChat-Kampagne abbrechen
WeChat-Kampagne abbrechen
 Big-Data-Analysetools
Big-Data-Analysetools
 Was tun, wenn das Login-Token ungültig ist?
Was tun, wenn das Login-Token ungültig ist?

























