Heute möchte ich Ihnen die gängigen Clustering-Methoden für unüberwachtes Lernen beim maschinellen Lernen vorstellen.
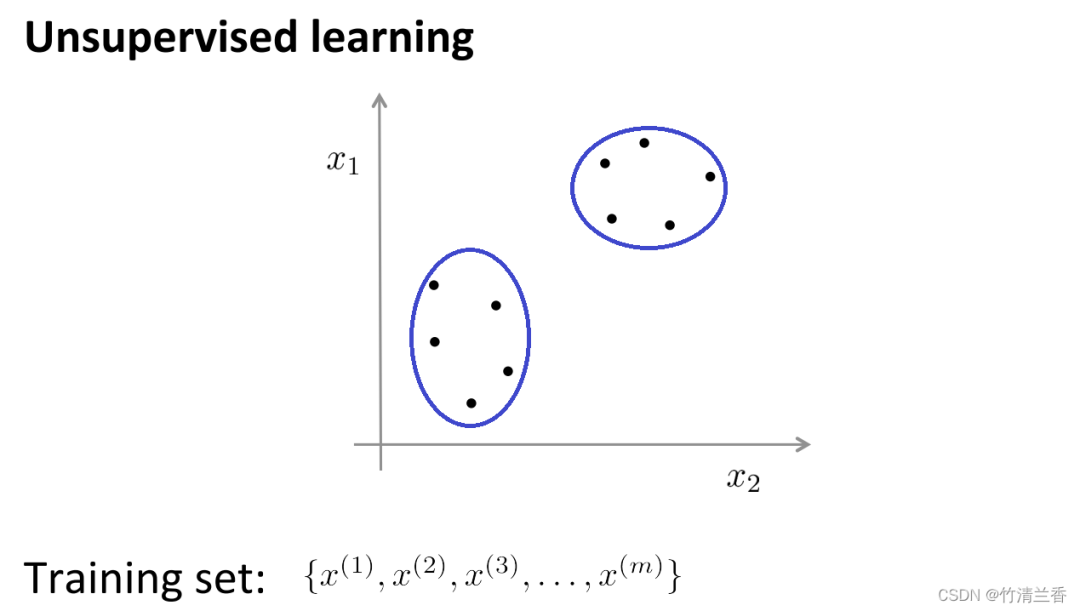
Beim unüberwachten Lernen tragen unsere Daten keine Etiketten. Was wir also beim unüberwachten Lernen tun müssen, ist, diese Reihe unbeschrifteter Daten zu erstellen Eingabe in den Algorithmus, und dann kann der Algorithmus einige in den Daten implizite Strukturen finden. Mithilfe der Daten in der folgenden Abbildung kann eine Struktur gefunden werden, die darin besteht, dass die Punkte im Datensatz in zwei separate Punktmengen unterteilt werden können . (Cluster), der Algorithmus, der diese Cluster (Cluster) umkreisen kann, wird Clustering-Algorithmus genannt.
Anwendung des Clustering-Algorithmus
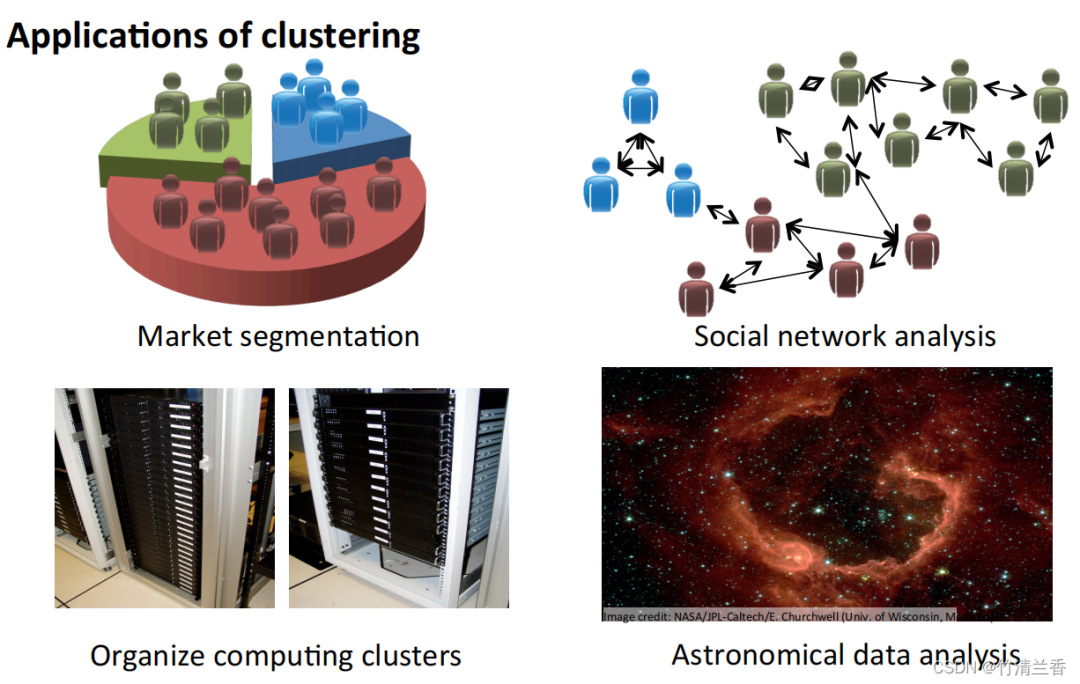
- Marktsegmentierung: Gruppieren Sie die Kundeninformationen in der Datenbank nach Markt, um so separate Umsatz- oder Serviceverbesserungen nach verschiedenen Märkten zu erzielen.
- Analyse sozialer Netzwerke: Finden Sie eine enge Gruppe, indem Sie den am häufigsten kontaktierten Personen und ihren häufigsten Kontakten eine E-Mail senden.
- Computercluster organisieren: In Rechenzentren arbeiten Computercluster häufig zusammen und können zur Neuorganisation von Ressourcen, zur Neuordnung von Netzwerken, zur Optimierung von Rechenzentren und zur Kommunikation von Daten verwendet werden.
- Verstehen Sie die Zusammensetzung der Milchstraße: Nutzen Sie diese Informationen, um etwas über Astronomie zu lernen.
Das Ziel der Clusteranalyse besteht darin, Beobachtungen in Gruppen („Cluster“) zu unterteilen, sodass paarweise Unterschiede zwischen Beobachtungen, die demselben Cluster zugeordnet sind, tendenziell kleiner sind als die Unterschiede zwischen Beobachtungen in verschiedenen Clustern. Clustering-Algorithmen werden in drei verschiedene Typen unterteilt: kombinatorische Algorithmen, Hybridmodellierung und Mustersuche.
Mehrere gängige Clustering-Algorithmen sind:
K-Means-Clustering- Hierarchisches Clustering
- Agglomeratives Clustering
- Affinity Propagation
- Mean Shift Clustering
- Bisecting K-Means
- DBSCAN
- OPTIK
- BIRKE
-
K-Means
Der K-Means-Algorithmus ist derzeit eine der beliebtesten Clustering-Methoden.
K-means wurde 1957 von Stuart Lloyd von Bell Labs vorgeschlagen. Es wurde ursprünglich für die Pulscodemodulation verwendet. Erst 1982 wurde der Algorithmus der Öffentlichkeit vorgestellt. Im Jahr 1965 veröffentlichte Edward W. Forgy denselben Algorithmus, weshalb K-Means manchmal auch Lloyd-Forgy genannt wird.
Clustering-Probleme erfordern normalerweise die Verarbeitung einer Reihe unbeschrifteter Datensätze und erfordern einen Algorithmus, der diese Daten automatisch in eng verwandte Teilmengen oder Cluster aufteilt. Derzeit ist der K-Means-Algorithmus der beliebteste und am weitesten verbreitete Clustering-Algorithmus oben) und wir Wenn Sie es in zwei Cluster aufteilen möchten, führen Sie nun den K-Means-Algorithmus aus. Die spezifische Operation ist wie folgt:
Der erste Schritt besteht darin, zwei Punkte zufällig zu generieren (da Sie Cluster bilden möchten). Die Daten werden in zwei Kategorien unterteilt (rechts im Bild oben). Diese beiden Punkte werden Clusterschwerpunkte genannt.
Der zweite Schritt besteht darin, die innere Schleife des K-Means-Algorithmus auszuführen. Der K-Means-Algorithmus ist ein iterativer Algorithmus, der zwei Dinge tut: Die erste ist die Clusterzuweisung und die zweite ist die Verschiebung des Schwerpunkts.
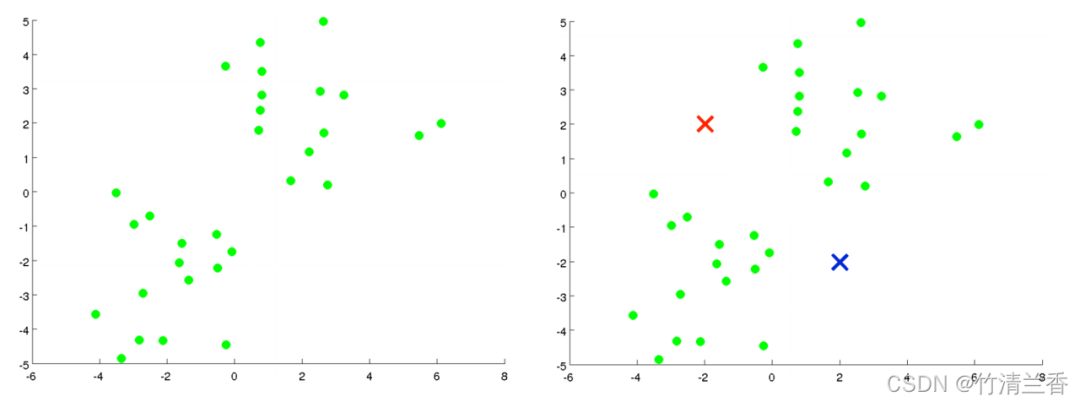
Der erste Schritt in der inneren Schleife besteht darin, eine Clusterzuweisung durchzuführen, dh jede Probe zu durchlaufen und dann jeden Punkt entsprechend der Entfernung von jedem Punkt zum Clusterzentrum (von wem) verschiedenen Clusterzentren zuzuweisen. Dies bedeutet in diesem Fall, den Datensatz zu durchlaufen und jeden Punkt rot oder blau zu färben.
- Der zweite Schritt der inneren Schleife besteht darin, das Clusterzentrum so zu verschieben, dass sich die roten und blauen Clusterzentren an die durchschnittliche Position der Punkte bewegen, zu denen sie gehören.
- Machen Sie alle Punkte entsprechend dem neuen Clusterzentrum neu Clusterzuweisungen werden basierend auf der Entfernung vorgenommen, und dieser Vorgang wird wiederholt, bis sich die Position des Clusterzentrums mit der Iteration nicht mehr ändert und die Farbe des Punktes sich nicht mehr ändert. Zu diesem Zeitpunkt kann man sagen, dass K-means die Aggregation abgeschlossen hat. Dieser Algorithmus leistet ziemlich gute Arbeit beim Auffinden von zwei Clustern in den Daten
Vorteile des K-Means-Algorithmus:
Einfach und leicht zu verstehen, schnelle Berechnungsgeschwindigkeit und für große Datensätze geeignet.
Nachteile:
- Zum Beispiel ist die Verarbeitungsfähigkeit für nicht sphärische Cluster schlecht, sie wird leicht durch die Auswahl des anfänglichen Clusterzentrums beeinflusst und die Anzahl der Cluster K muss angegeben werden im Voraus.
- Wenn außerdem Rauschen oder Ausreißer zwischen Datenpunkten auftreten, ordnet der K-Means-Algorithmus diese möglicherweise den falschen Clustern zu.
Hierarchisches Clustering
Hierarchisches Clustering ist der Vorgang des Clusterns von Stichprobensätzen entsprechend einer bestimmten Ebene. Die Ebene bezieht sich hier tatsächlich auf die Definition eines bestimmten Abstands
Der ultimative Zweck des Clusterings besteht darin, die Anzahl der Klassifizierungen zu reduzieren. Daher ähnelt es im Verhalten dem Dendrogrammprozess, bei dem man sich schrittweise vom Blattknoten zum Wurzelknoten nähert . Diese Art von Verhalten wird auch als „Bottom-Up“ bezeichnet.
Beliebter ist, dass hierarchische Cluster die initialisierten Cluster als Baumknoten behandeln. Bei jedem Iterationsschritt werden zwei ähnliche Cluster zu einem neuen großen Cluster zusammengeführt Dieser Vorgang wird wiederholt, bis schließlich nur noch ein Cluster (Wurzelknoten) übrig bleibt.
Hierarchische Clustering-Strategien sind in zwei grundlegende Paradigmen unterteilt: Aggregation (Bottom-Up) und Division (Top-Down).
Das Gegenteil von hierarchischem Clustering ist divisives Clustering, auch bekannt als DIANA (Divise Analysis), dessen Verhaltensprozess „von oben nach unten“ erfolgt.
Die Ergebnisse des K-Means-Algorithmus hängen von dem für die Suche ausgewählten Cluster ab . Zuordnung der Klassenanzahl und Startkonfiguration. Im Gegensatz dazu erfordern hierarchische Clustering-Methoden eine solche Spezifikation nicht. Stattdessen muss der Benutzer ein Maß für die Unähnlichkeit zwischen (disjunkten) Beobachtungsgruppen angeben, das auf der paarweisen Unähnlichkeit zwischen den beiden Beobachtungsgruppen basiert. Wie der Name schon sagt, erzeugen hierarchische Clustering-Methoden eine hierarchische Darstellung, bei der Cluster auf jeder Ebene durch Zusammenführen von Clustern auf der nächstniedrigeren Ebene erstellt werden. Auf der untersten Ebene enthält jeder Cluster eine Beobachtung. Auf der höchsten Ebene enthält nur ein Cluster alle Daten. Vorteile: Entfernung und Regelähnlichkeit sind einfach zu definieren und unterliegen nur wenigen Einschränkungen.
Die Anzahl der Cluster muss nicht vorab festgelegt werden ;
kann die hierarchische Beziehung von Klassen entdecken
-
kann in andere Formen gruppiert werden.
-
Die Rechenkomplexität ist zu hoch;
Singuläre Werte können auch große Auswirkungen haben;
Der Algorithmus gruppiert sich wahrscheinlich zu Ketten.
-
Agglomeratives Clustering
- Der neu geschriebene Inhalt lautet: Agglomeratives Clustering ist ein Bottom-up-Clustering-Algorithmus, der jeden Datenpunkt als anfänglichen Cluster behandelt und ihn schrittweise zusammenführt. Sie bilden größere Cluster, bis die Stoppbedingung erfüllt ist. Bei diesem Algorithmus wird jeder Datenpunkt zunächst als separater Cluster betrachtet, und dann werden Cluster nach und nach zusammengeführt, bis alle Datenpunkte zu einem großen Cluster zusammengeführt werden.
- Vorteile:
Geeignet für verschiedene Formen und Größen Cluster, und es ist nicht erforderlich, die Anzahl der Cluster im Voraus anzugeben.
Der Algorithmus kann zur einfachen Analyse und Visualisierung auch eine Clustering-Hierarchie ausgeben.
Nachteile: -
Die Rechenkomplexität ist hoch, insbesondere bei der Verarbeitung großer Datensätze sind große Mengen an Rechenressourcen und Speicherplatz erforderlich.
Dieser Algorithmus reagiert auch empfindlich auf die Auswahl der anfänglichen Cluster, was zu unterschiedlichen Clustering-Ergebnissen führen kann.
Affinity Propagation
- Geänderter Inhalt: Affinity Propagation Algorithm (AP) wird normalerweise als Affinity Propagation Algorithm oder Proximity Propagation Algorithm übersetzt ars " (repräsentative Punkte) und "Cluster" (Cluster) in den Daten. Im Gegensatz zu herkömmlichen Clustering-Algorithmen wie K-Means muss bei Affinity Propagation weder die Anzahl der Cluster im Voraus angegeben noch die Clusterzentren zufällig initialisiert werden. Stattdessen wird das endgültige Clustering-Ergebnis durch Berechnen der Ähnlichkeit zwischen Datenpunkten ermittelt.
Vorteile:
- Es ist nicht erforderlich, die Anzahl der endgültigen Clusterfamilien anzugeben.
- Vorhandene Datenpunkte werden als endgültiges Clusterzentrum verwendet, anstatt ein neues Clusterzentrum zu generieren.
- Das Modell reagiert nicht auf den Anfangswert der Daten.
- Es besteht keine Anforderung an die Symmetrie der anfänglichen Ähnlichkeitsmatrixdaten.
- Im Vergleich zur K-Center-Clustering-Methode ist der quadratische Fehler des Ergebnisses kleiner.
Nachteile:
- Dieser Algorithmus hat eine hohe Rechenkomplexität und erfordert viel Speicherplatz und Rechenressourcen;
- hat schwache Verarbeitungsfähigkeiten für Rauschpunkte und Ausreißer.
Mean Shift Clustering
Shifting Clustering ist ein dichtebasierter, nichtparametrischer Clustering-Algorithmus. Seine Grundidee besteht darin, den Ort mit der höchsten Dichte an Datenpunkten (als „lokales Maximum“ oder „Peak“ bezeichnet) zu finden. , um Cluster in den Daten zu identifizieren. Der Kern dieses Algorithmus besteht darin, die lokale Dichte jedes Datenpunkts zu schätzen und anhand der Ergebnisse der Dichteschätzung die Richtung und Entfernung der Bewegung des Datenpunkts zu berechnen
Vorteile:
- Keine Notwendigkeit um die Anzahl der Cluster anzugeben. Außerdem werden gute Ergebnisse für Cluster mit komplexen Formen erzielt.
- Der Algorithmus ist auch in der Lage, verrauschte Daten effektiv zu verarbeiten.
Nachteile:
- Die Rechenkomplexität ist hoch, insbesondere bei der Verarbeitung großer Datensätze, die eine große Menge an Rechenressourcen und Speicherplatz erfordern.
- Dieser Algorithmus erfordert auch anfängliche Parameter Die Auswahl ist relativ empfindlich und erfordert eine Parameteranpassung und -optimierung.
Bisecting K-Means
Bisecting K-Means ist ein hierarchischer Clustering-Algorithmus, der auf dem K-Means-Algorithmus basiert. Seine Grundidee besteht darin, alle Datenpunkte in einen Cluster zu unterteilen und den Cluster dann in zwei Untercluster zu unterteilen . Wenden Sie den K-Means-Algorithmus separat auf jeden Untercluster an und wiederholen Sie diesen Vorgang, bis die vorgegebene Anzahl von Clustern erreicht ist.
Der Algorithmus behandelt zunächst alle Datenpunkte als anfänglichen Cluster, wendet dann den K-Means-Algorithmus auf den Cluster an, teilt den Cluster in zwei Untercluster auf und berechnet die Summe der quadratischen Fehler (SSE) für jeden Untercluster. Cluster. Anschließend wird der Subcluster mit der größten Fehlerquadratsumme ausgewählt und erneut in zwei Subcluster aufgeteilt. Dieser Vorgang wird wiederholt, bis die vorgegebene Anzahl an Clustern erreicht ist.
Vorteile:
- verfügt über eine hohe Genauigkeit und Stabilität, kann große Datensätze effektiv verarbeiten und muss nicht die anfängliche Anzahl von Clustern angeben.
- Der Algorithmus ist auch in der Lage, eine Clustering-Hierarchie zur einfachen Analyse und Visualisierung auszugeben.
Nachteile:
- Die Rechenkomplexität ist hoch, insbesondere bei der Verarbeitung großer Datensätze sind große Mengen an Rechenressourcen und Speicherplatz erforderlich.
- Darüber hinaus reagiert dieser Algorithmus auch empfindlich auf die Auswahl der anfänglichen Cluster, was zu unterschiedlichen Clustering-Ergebnissen führen kann.
DBSCAN
Der dichtebasierte räumliche Clustering-Algorithmus DBSCAN (Density-Based Spatial Clustering of Applications with Noise) ist eine typische Clustering-Methode mit Rauschen
Die Dichtemethode ist nicht von Abstandseigenschaften abhängig, sondern abhängig auf Dichte. Daher kann der Nachteil behoben werden, dass entfernungsbasierte Algorithmen nur „kugelförmige“ Cluster finden können. Die Kernidee des DBSCAN-Algorithmus lautet: Wenn seine Dichte einen bestimmten Schwellenwert erreicht, gehört er zu einem Cluster ; andernfalls wird es als Rauschpunkt betrachtet.
Vorteile:
- Diese Art von Algorithmus kann die Mängel distanzbasierter Algorithmen überwinden, die nur „kreisförmige“ (konvexe) Cluster finden können;
- kann Cluster jeder Form finden und ist unempfindlich gegenüber verrauschte Daten;
- Die Anzahl der Klassencluster muss nicht angegeben werden.
- Der Algorithmus enthält nur zwei Parameter: den Scanradius (eps) und die Mindestanzahl der enthaltenen Punkte (min_samples).
Nachteile:
- Rechenkomplexität, ohne Optimierung beträgt die zeitliche Komplexität des Algorithmus O(N^{2}), normalerweise können R-Baum, k-d-Baum, Ball verwendet werden;
- Baumindex zur Beschleunigung von Berechnungen und Reduzierung der zeitlichen Komplexität des Algorithmus auf O(Nlog(N));
- wird stark von EPS beeinflusst. Wenn die Dichte der Datenverteilung in einer Klasse ungleichmäßig ist und das EPS klein ist, wird der Cluster mit geringer Dichte in mehrere Cluster mit ähnlichen Eigenschaften aufgeteilt. Wenn das EPS groß ist, werden die Cluster, die näher und dichter sind, zu einem Cluster zusammengeführt. Bei hochdimensionalen Daten ist die Auswahl von EPS aufgrund des Fluchs der Dimensionalität schwieriger. Aufgrund des Fluchs der Dimensionalität ist die Distanzmetrik nicht wichtig.
- ist für den Konzentrationsunterschied des Datensatzes nicht geeignet. Sehr groß, da es schwierig ist, EPS und Metrik auszuwählen.
- OPTICS
OPTICS (Ordering Points To Identify the Clustering Structure) ist ein dichtebasierter Clustering-Algorithmus, der die Anzahl der Cluster automatisch bestimmen, auch Cluster beliebiger Form erkennen und verrauschte Daten verarbeiten kann
Die Kernidee des OPTICS-Algorithmus besteht darin, die Entfernung zwischen einem bestimmten Datenpunkt und anderen Punkten zu berechnen, um seine Erreichbarkeit anhand der Dichte zu bestimmen und eine dichtebasierte Entfernungskarte zu erstellen. Durch Scannen dieser Entfernungskarte wird dann automatisch die Anzahl der Cluster bestimmt und jeder Cluster wird geteilt um verrauschte Daten effektiv zu verarbeiten.
Der Algorithmus ist auch in der Lage, eine Clustering-Hierarchie zur einfachen Analyse und Visualisierung auszugeben.
Nachteile:
-
Die Rechenkomplexität ist hoch, insbesondere bei der Verarbeitung großer Datensätze sind viele Rechenressourcen und Speicherplatz erforderlich.
-
Dieser Algorithmus kann bei Datensätzen mit großen Dichteunterschieden zu schlechten Clustering-Ergebnissen führen.
BIRCHBIRCH (Balanced Iterative Reduction and Hierarchical Clustering) ist ein auf hierarchischem Clustering basierender Clustering-Algorithmus, der große Datensätze effizient verarbeiten und gute Ergebnisse für Cluster jeder Form erzielen kann. Die Kernidee des Der BIRCH-Algorithmus besteht darin, die Datengröße durch hierarchisches Clustering des Datensatzes schrittweise zu reduzieren und schließlich die Clusterstruktur zu erhalten. Der BIRCH-Algorithmus verwendet eine dem B-Tree ähnliche Struktur namens CF-Baum, mit der Untercluster schnell eingefügt und gelöscht und automatisch ausgeglichen werden können, um die Qualität und Effizienz von Clustern sicherzustellen. Vorteile:
- Kann große Datensätze schnell verarbeiten und liefert gute Ergebnisse für Cluster beliebiger Formen.
Dieser Algorithmus verfügt auch über eine gute Fehlertoleranz für verrauschte Daten und Ausreißer.
Nachteile:
Bei Datensätzen mit großen Dichteunterschieden kann es zu schlechten Clustering-Ergebnissen kommen;
Der Effekt auf hochdimensionale Datensätze ist auch nicht so gut wie bei anderen Algorithmen .
Das obige ist der detaillierte Inhalt vonNeun Clustering-Algorithmen zur Erforschung des unbeaufsichtigten maschinellen Lernens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 Was soll ich tun, wenn mein iPad nicht aufgeladen werden kann?
Was soll ich tun, wenn mein iPad nicht aufgeladen werden kann?
 So registrieren Sie sich für Firmen-Alipay
So registrieren Sie sich für Firmen-Alipay
 Was soll ich tun, wenn ich mein Breitband-Passwort vergesse?
Was soll ich tun, wenn ich mein Breitband-Passwort vergesse?
 Tutorial für Ouyi-Neulinge
Tutorial für Ouyi-Neulinge
 So verwenden Sie die Max-Funktion
So verwenden Sie die Max-Funktion
 RGB in hexadezimales RGB umwandeln
RGB in hexadezimales RGB umwandeln
 So lösen Sie das Problem „Warten auf Gerät'.
So lösen Sie das Problem „Warten auf Gerät'.
 Was ist der Unterschied zwischen xls und xlsx
Was ist der Unterschied zwischen xls und xlsx








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



