


Im Bereich der Computergrafik ist Dreiecksnetz die wichtigste Methode zur Darstellung geometrischer 3D-Objekte und auch die am häufigsten verwendete 3D-Ressourcenausdrucksmethode in Spielen, Filmen und Virtual-Reality-Schnittstellen. Die Industrie verwendet normalerweise Dreiecksnetze, um die Oberflächen komplexer Objekte wie Gebäude, Fahrzeuge, Tiere usw. zu simulieren. Gleichzeitig müssen auch allgemeine geometrische Transformationen, Geometrieerkennungs-, Rendering- und Schattierungsvorgänge auf der Grundlage von Dreiecksnetzen durchgeführt werden. Im Vergleich zu anderen 3D-Formdarstellungen wie Punktwolken oder Voxeln bieten Dreiecksnetze eine kohärentere Oberflächendarstellung steuerbar, einfacher zu bedienen, kompakter und kann direkt in modernen Rendering-Pipelines angewendet werden, wodurch eine höhere visuelle Qualität mit weniger Grundelementen erreicht wird Felder werden zum Generieren von 3D-Modellen verwendet. Diese Darstellungsmethoden müssen auch durch Nachbearbeitung in Netze umgewandelt werden, um sie in nachgelagerten Anwendungen zu verwenden, z. B. durch die Verwendung des Marching-Cubes-Algorithmus für die Isoflächenverarbeitung. Leider kann dieser Ansatz dazu führen Netze, die zu dicht und zu fein vernetzt sind, oft mit holprigen Fehlern, die durch übermäßiges Glätten und Isosurfacing verursacht werden, wie das unten gezeigte:
Im Vergleich dazu sind 3D-Netze, die von 3D-Modellierungsprofis modelliert wurden, kompakter in der Darstellung Gleichzeitig bleiben gestochen scharfe Details mit weniger Dreiecken erhalten. 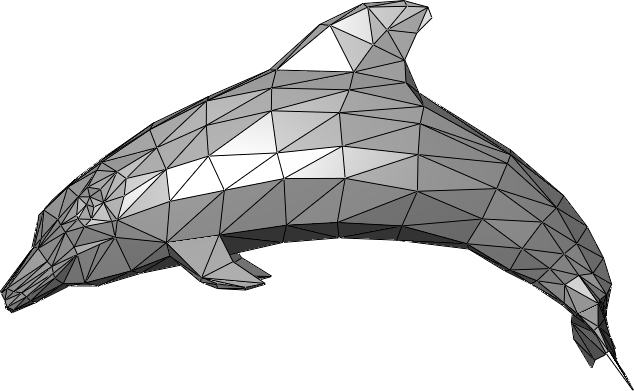
Viele Forscher hoffen seit langem, die Aufgabe der automatischen Generierung von Dreiecksnetzen zu lösen, um den Prozess der Erstellung von 3D-Assets weiter zu vereinfachen.
In einem aktuellen Artikel schlugen Forscher eine neue Lösung vor: MeshGPT, das die Netzdarstellung direkt als Satz von Dreiecken generiert.

Der Link zum Papier ist zu finden unter: https://nihalsid.github.io/mesh-gpt/static/MeshGPT.pdf
Inspiriert durch das Transformer-Sprachgenerierungsmodell haben sie a übernommen Eine Methode zur direkten Sequenzgenerierung, die Dreiecksnetze zu Dreieckssequenzen synthetisiert.
Dem Paradigma der Textgenerierung folgend lernen Forscher zunächst ein Dreiecksvokabular und Dreiecke werden als latente quantisierte Einbettungen codiert. Um die erlernten Dreieckseinbettungen zu fördern und lokale geometrische und topologische Merkmale beizubehalten, verwenden wir einen Graph-Faltungsencoder. Diese Dreieckseinbettungen werden dann von einem ResNet-Decoder dekodiert, der die Sequenz von Token verarbeitet, die die Dreiecke darstellen, um die Scheitelpunktkoordinaten der Dreiecke zu generieren. Schließlich trainierten die Forscher eine GPT-basierte Architektur basierend auf dem erlernten Vokabular, um automatisch eine Folge von Dreiecken zu generieren, die das Netz darstellen, und erzielten die Vorteile klarer Kanten und hoher Wiedergabetreue.
 Experimente in mehreren Kategorien des ShapeNet-Datensatzes zeigen, dass
Experimente in mehreren Kategorien des ShapeNet-Datensatzes zeigen, dass
im Vergleich zu bestehenden Techniken erheblich verbessert, mit einer durchschnittlichen Verbesserung der Formabdeckung um 9 % und verbesserten FID-Werten.
Auf Social-Media-Plattformen hat MeshGPT auch für hitzige Diskussionen gesorgt:
Jemand sagte einmal: „Das ist die wirklich revolutionäre Idee.“
Ein Netizens wies darauf hin, dass das Highlight Der Vorteil dieser Methode besteht darin, dass sie das größte Hindernis anderer 3D-Modellierungsmethoden überwindet, nämlich die Bearbeitungsmöglichkeiten. 
Jemand hat mutig vorausgesagt, dass vielleicht alle Probleme, die seit den 1990er Jahren nicht gelöst wurden, von Transformer inspiriert werden können:

Es gibt auch Benutzer, die in der 3D-/Filmproduktionsbranche tätig sind und Bedenken hinsichtlich ihrer Karriere geäußert haben:

Einige Leute wiesen jedoch darauf hin, dass gemäß den in der Papier, diese Methode ist immer noch Es hat nicht das Stadium einer groß angelegten Anwendung erreicht. Ein professioneller Modellierer könnte diese Netze vollständig in weniger als 5 Minuten erstellen Die Architektur. Ab diesem Punkt kann die Produktion von 3D-Assets für Spiele und andere Szenen in großem Umfang automatisiert werden.
 Als nächstes werfen wir einen Blick auf die Forschungsdetails des MeshGPT-Papiers.
Als nächstes werfen wir einen Blick auf die Forschungsdetails des MeshGPT-Papiers.
Überblick über die Methode
Inspiriert durch den Fortschritt großer Sprachmodelle entwickelten die Forscher eine sequenzbasierte Methode, die Dreiecksnetze autoregressiv als Dreieckssequenzen generiert. Diese Methode erzeugt saubere, kohärente und kompakte Netze mit scharfen Kanten und hoher Wiedergabetreue.
 Um das Dreiecksvokabular zu lernen, verwendeten die Forscher einen Graph-Faltungsencoder, der die Dreiecke des Netzes und ihre Umgebungen bearbeitet, um reichhaltige geometrische Merkmale zu extrahieren und die komplexen Details von 3D-Formen zu erfassen. Diese Merkmale werden als Einbettung in das Codebuch durch Restquantisierung quantisiert, wodurch die Sequenzlänge der Gitterdarstellung effektiv reduziert wird. Nach dem Sortieren werden diese eingebetteten Informationen von einem eindimensionalen ResNet dekodiert, das vom Rekonstruktionsverlust geleitet wird. Diese Phase legt den Grundstein für die anschließende Schulung von Transformer.
Um das Dreiecksvokabular zu lernen, verwendeten die Forscher einen Graph-Faltungsencoder, der die Dreiecke des Netzes und ihre Umgebungen bearbeitet, um reichhaltige geometrische Merkmale zu extrahieren und die komplexen Details von 3D-Formen zu erfassen. Diese Merkmale werden als Einbettung in das Codebuch durch Restquantisierung quantisiert, wodurch die Sequenzlänge der Gitterdarstellung effektiv reduziert wird. Nach dem Sortieren werden diese eingebetteten Informationen von einem eindimensionalen ResNet dekodiert, das vom Rekonstruktionsverlust geleitet wird. Diese Phase legt den Grundstein für die anschließende Schulung von Transformer.
Als nächstes nutzten die Forscher diese quantisierten geometrischen Einbettungen, um einen reinen Decoder-Transformator ähnlich wie GPT zu trainieren. Dazu extrahieren sie eine Folge geometrischer Einbettungen in Maschendreiecken und trainieren den Transformator, um den Codebuchindex der nächsten Einbettung in der Folge vorherzusagen Diese Einbettungen erzeugen neuartige und vielfältige Netzstrukturen, die effiziente, unregelmäßige Dreiecke aufweisen, die den von Menschen gezeichneten Netzen ähneln.

MeshGPT verwendet einen Graph-Faltungsencoder zur Verarbeitung von Netzoberflächen, verwendet geometrische Nachbarschaftsinformationen, um starke Merkmale zu erfassen, die die komplexen Details von 3D-Formen darstellen, und verwendet dann die Restquantisierungsmethode, um diese Merkmale zu quantisieren Codebuch-Einbettungen. Dieser Ansatz gewährleistet eine bessere Rekonstruktionsqualität im Vergleich zur einfachen Vektorquantisierung. Basierend auf dem Rekonstruktionsverlust sortiert und dekodiert MeshGPT die quantisierten Einbettungen über ResNet.

Diese Studie verwendet das Transformer-Modell, um Gittersequenzen als Token-Indizes aus der vorab trainierten Codebuch-Vokabularbibliothek zu generieren. Während des Trainings extrahiert der Bildencoder Merkmale aus Netzoberflächen und quantisiert sie in eine Reihe von Oberflächeneinbettungen. Diese Einbettungen werden gekachelt, mit Start- und End-Tokens markiert und dann in das oben beschriebene Transformer-Modell vom GPT-Typ eingespeist. Der Decoder ist mit einem Kreuzentropieverlust optimiert, der den nachfolgenden Codebuchindex für jede Einbettung vorhersagt.
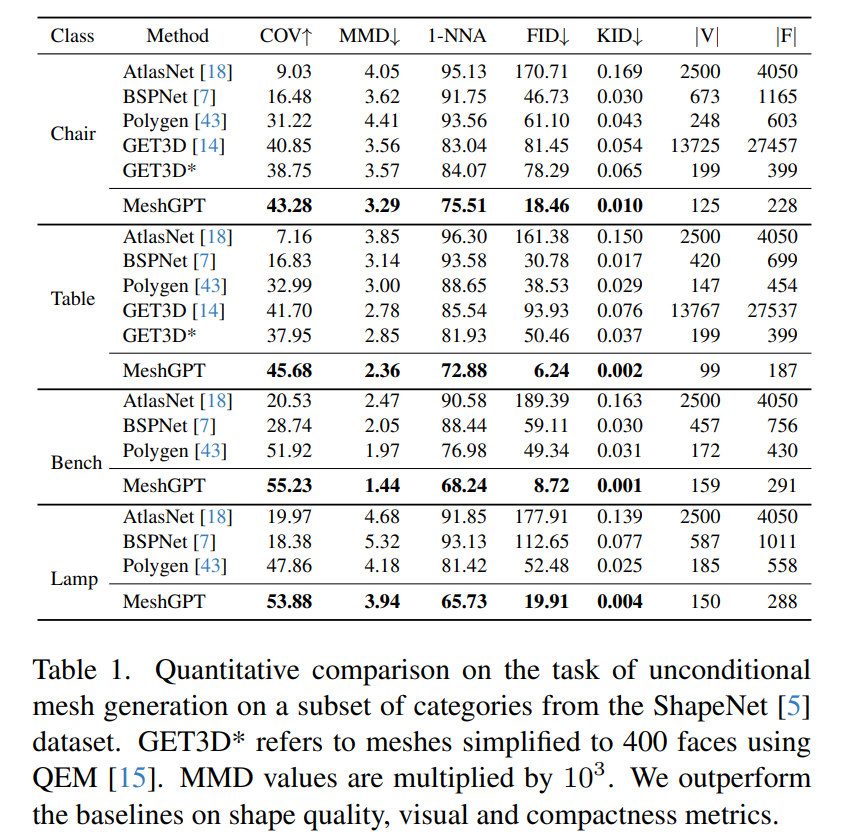
Darüber hinaus verglich die Studie MeshGPT mit der neuronalen feldbasierten SOTA-Methode GET3D.
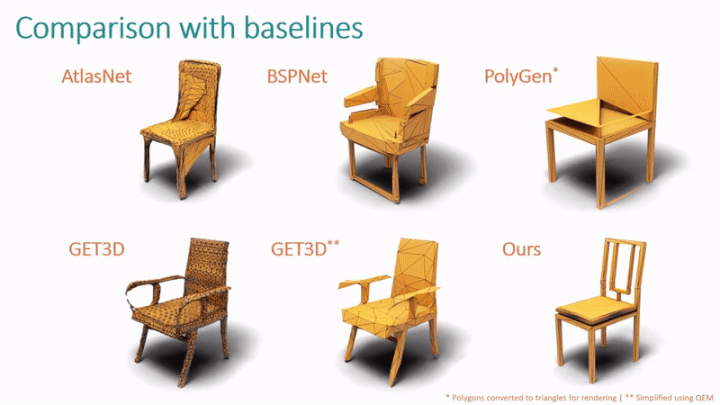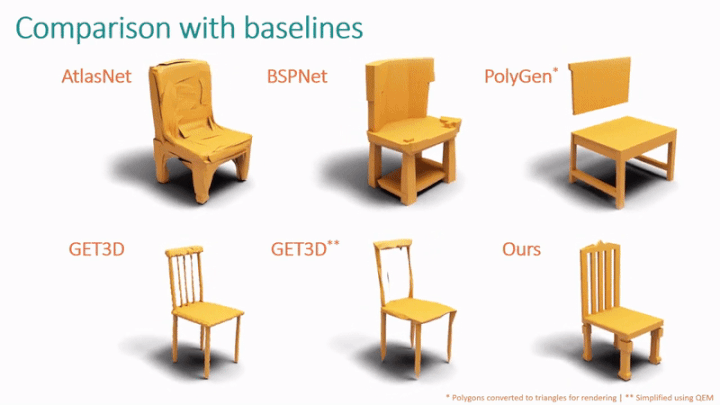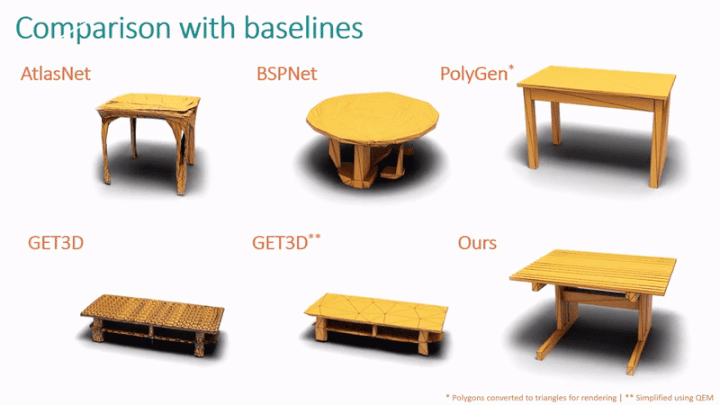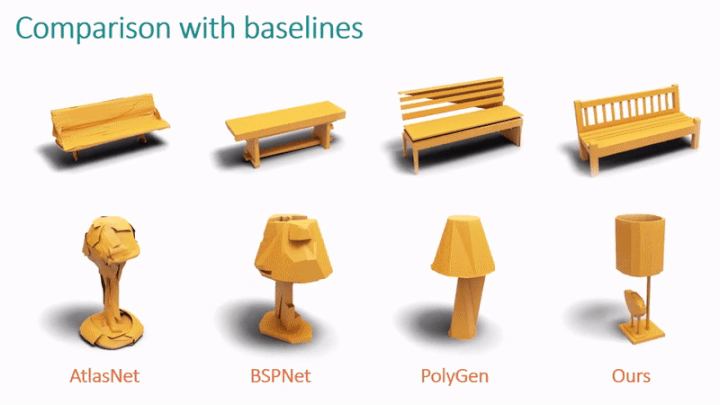
Wie in Tabelle 2 gezeigt, ermöglicht die Studie Benutzern auch, die Qualität des von MeshGPT erzeugten Netzes zu bewerten. In Bezug auf Form und Triangulationsqualität ist MeshGPT deutlich besser als AtlasNet, Polygen und BSPNet. Die meisten Benutzer bevorzugten die von MeshGPT generierte Formqualität (68 %) und Triangulationsqualität (73 %) im Vergleich zu GET3D.

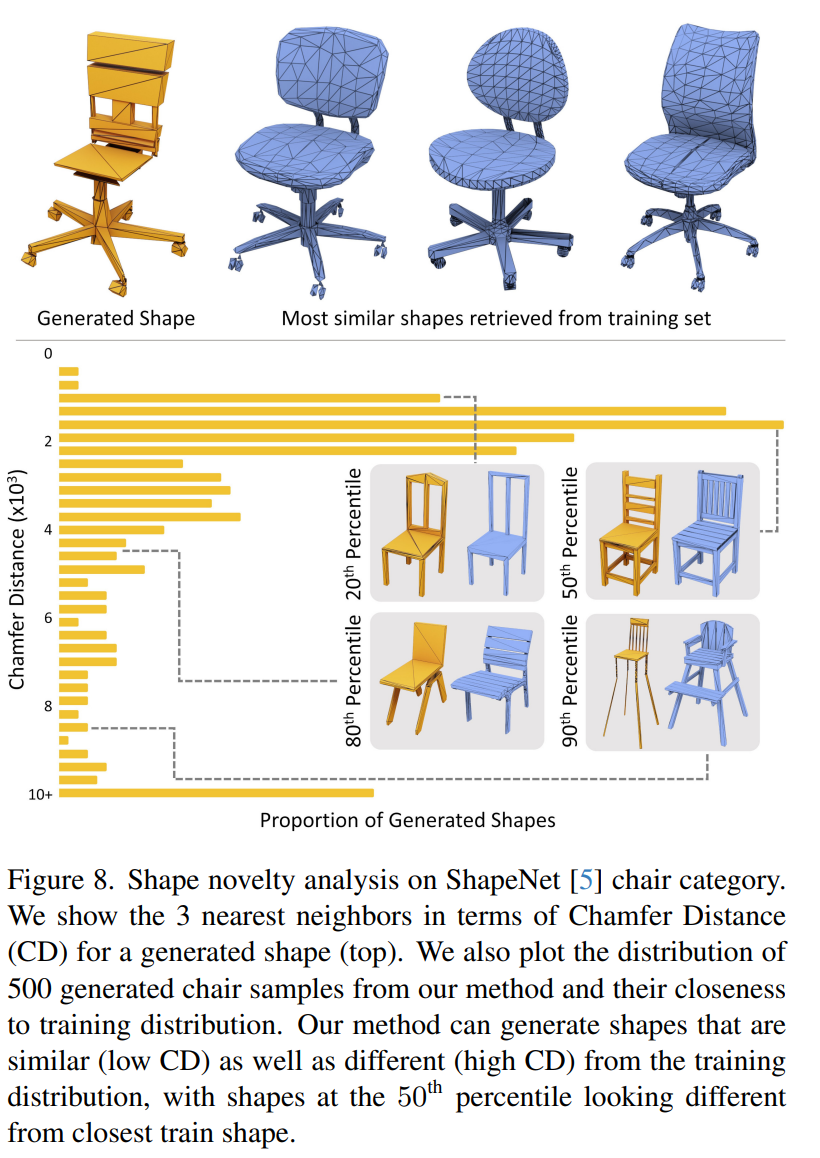
Der neu geschriebene Inhalt ist: neuartige Form. Wie in Abbildung 8 dargestellt, ist MeshGPT in der Lage, über den Trainingsdatensatz hinaus neuartige Formen zu generieren, wodurch sichergestellt wird, dass das Modell mehr kann als nur vorhandene Formen abzurufen

Formvervollständigung. Wie in Abbildung 9 unten dargestellt, kann MeshGPT auch mehrere mögliche Vervollständigungen basierend auf einer bestimmten lokalen Form ableiten und mehrere Formhypothesen generieren. 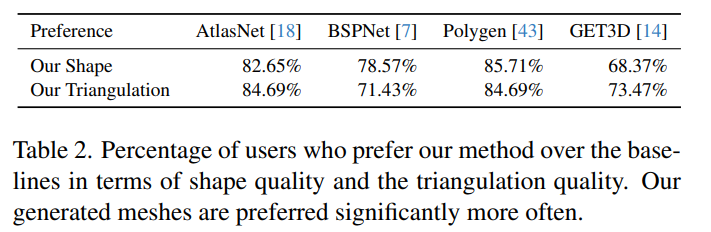
Das obige ist der detaillierte Inhalt vonTransformer revolutioniert die 3D-Modellierung und der Effekt der MeshGPT-Generierung alarmiert professionelle Modellierer und Internetnutzer: revolutionäre Idee. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



