


GPT-4 ist seit seiner Geburt ein „Top-Schüler“ und erzielte in verschiedenen Prüfungen (Benchmarks) hohe Punktzahlen. Doch jetzt erreichte es in einem neuen Test nur 15 Punkte, verglichen mit 92 beim Menschen.
Dieser Satz von Testfragen namens „GAIA“ wurde von Teams von Meta-FAIR, Meta-GenAI, HuggingFace und AutoGPT erstellt. Er wirft einige Probleme auf, die eine Reihe grundlegender Fähigkeiten zur Lösung erfordern, wie z. B. Argumentation, Multi- Modalitätsverarbeitung, Webbrowsing und allgemeine Fähigkeiten zur Werkzeugnutzung. Diese Probleme sind für den Menschen sehr einfach, für die fortschrittlichste KI jedoch äußerst herausfordernd. Wenn alle darin enthaltenen Probleme gelöst werden können, wird das fertige Modell zu einem wichtigen Meilenstein in der KI-Forschung.

Das Designkonzept von GAIA unterscheidet sich von vielen aktuellen KI-Benchmarks. Letztere neigen dazu, Aufgaben zu entwerfen, die für Menschen immer schwieriger werden. Dies spiegelt tatsächlich die Unterschiede im Verständnis der AGI wider. Das Team hinter GAIA glaubt, dass die Entstehung von AGI davon abhängt, ob das System bei den oben genannten „einfachen“ Problemen eine ähnliche Robustheit wie normale Menschen zeigen kann.

Der neu geschriebene Inhalt lautet wie folgt: Bild 1: Beispiel einer GAIA-Frage. Zur Bewältigung dieser Aufgaben sind große Modelle mit bestimmten Grundfunktionen wie Argumentation, Multimodalität oder Werkzeugnutzung erforderlich. Die Antwort ist klar und kann konstruktionsbedingt nicht im Klartext der Trainingsdaten gefunden werden. Einige Probleme sind mit zusätzlichen Beweisen wie Bildern versehen, die reale Anwendungsfälle widerspiegeln und eine bessere Kontrolle des Problems ermöglichen
Obwohl LLMs für Menschen schwierige Aufgaben erfolgreich erledigen können, ist die Leistung der leistungsfähigsten LLMs auf GAIA unbefriedigend . Selbst ausgestattet mit den Tools hatte GPT4 eine Erfolgsquote von nicht mehr als 30 % bei den einfachsten Aufgaben und 0 % bei den schwierigsten Aufgaben. Unterdessen lag die durchschnittliche Erfolgsquote bei menschlichen Befragten bei 92 %.
Wenn also ein System das Problem in GAIA lösen kann, können wir es im t-AGI-System bewerten. t-AGI ist ein detailliertes AGI-Bewertungssystem, das vom OpenAI-Ingenieur Richard Ngo entwickelt wurde und 1-Sekunden-AGI, 1-Minuten-AGI, 1-Stunden-AGI usw. umfasst. Es wird verwendet, um zu untersuchen, ob ein KI-System innerhalb einer begrenzten Zeit arbeiten kann . Erledige Aufgaben, die Menschen normalerweise in der gleichen Zeit erledigen können. Die Autoren sagen, dass Menschen beim GAIA-Test normalerweise etwa 6 Minuten brauchen, um die einfachsten Fragen zu beantworten, und etwa 17 Minuten, um die komplexesten Fragen zu beantworten.
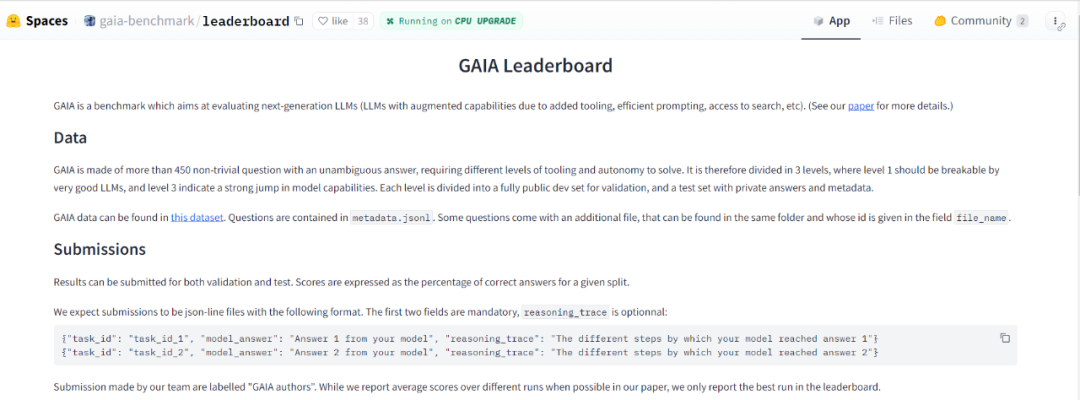
Der Autor nutzte die GAIA-Methode, um 466 Fragen und deren Antworten zu entwerfen. Sie veröffentlichten ein Entwicklerset mit 166 Fragen und Antworten sowie weiteren 300 Fragen ohne Antworten. Dieser Benchmark wird in Form einer Bestenliste veröffentlicht. arxiv ... ? GAIA sei ein Maßstab für das Testen künstlicher Intelligenzsysteme im Hinblick auf das allgemeine Assistentenproblem, sagten die Forscher. GAIA versucht, die Mängel einer Vielzahl früherer LLM-Bewertungen zu umgehen. Dieser Benchmark besteht aus 466 von Menschen entworfenen und kommentierten Fragen. Die Fragen sind textbasiert und einige werden von Dateien (z. B. Bildern oder Tabellenkalkulationen) begleitet. Sie decken eine Vielzahl von Hilfsaufgaben ab, darunter tägliche persönliche Aufgaben, Naturwissenschaften und Allgemeinwissen usw.
 Diese Fragen haben eine kurze, einzelne und leicht überprüfbare richtige Antwort
Diese Fragen haben eine kurze, einzelne und leicht überprüfbare richtige Antwort
GAIA entstand sowohl aus der Notwendigkeit heraus, die Benchmarks für künstliche Intelligenz zu verbessern, als auch aus den derzeit weithin beobachteten Mängeln der LLM-Bewertung.
Das erste Prinzip bei der Gestaltung von GAIA besteht darin, konzeptionell einfache Probleme in Angriff zu nehmen. Auch wenn diese Probleme für den Menschen mühsam sein mögen, verändern sie sich in der realen Welt ständig und stellen eine Herausforderung für aktuelle Systeme der künstlichen Intelligenz dar. Dies ermöglicht es uns, uns auf grundlegende Fähigkeiten wie schnelle Anpassung durch Argumentation, multimodales Verständnis und potenziell vielfältige Werkzeugnutzung zu konzentrieren, anstatt auf spezielle Fähigkeiten sich ständig veränderndes Web), um genaue Antworten zu erhalten. Um die Beispielfrage in Abbildung 1 zu beantworten, sollte ein LLM normalerweise im Internet nach Studien suchen und dann nach dem richtigen Registrierungsort suchen. Dies steht im Gegensatz zum Trend früherer Benchmark-Systeme, die für den Menschen immer schwieriger wurden und/oder in Klartext oder künstlichen Umgebungen betrieben wurden.
Das zweite Prinzip von GAIA ist die Interpretierbarkeit. Wir haben eine begrenzte Anzahl von Fragen sorgfältig zusammengestellt, um die Verwendung des neuen Benchmarks einfacher zu gestalten als bei einer großen Anzahl von Fragen. Das Konzept dieser Aufgabe ist einfach (92 % menschliche Erfolgsquote), sodass Benutzer den Inferenzprozess des Modells leicht verstehen können. Für das Problem der ersten Ebene in Abbildung 1 besteht der Argumentationsprozess hauptsächlich darin, die richtige Website zu überprüfen und die richtige Nummer zu melden. Dieser Prozess ist leicht zu überprüfen. Das dritte Prinzip von GAIA ist die Robustheit gegenüber dem Gedächtnis: Das Ziel von GAIA ist eine geringere Wahrscheinlichkeit zu erraten als die meisten aktuellen Benchmarks. Um eine Aufgabe abzuschließen, muss das System eine Reihe von Schritten planen und erfolgreich abschließen. Denn konstruktionsbedingt werden die resultierenden Antworten in den aktuellen Pre-Training-Daten nicht im Klartext generiert. Verbesserungen der Genauigkeit spiegeln den tatsächlichen Fortschritt im System wider. Aufgrund ihrer Vielfältigkeit und der Größe des Aktionsraums können diese Aufgaben nicht brutal erzwungen werden, ohne zu schummeln, beispielsweise durch das Auswendiglernen grundlegender Fakten. Obwohl eine Datenverunreinigung zu zusätzlicher Genauigkeit führen kann, mindern die erforderliche Genauigkeit der Antworten, das Fehlen der Antworten in den Daten vor dem Training und die Möglichkeit, die Inferenzspur zu untersuchen, dieses Risiko.
Im Gegensatz dazu erschweren Multiple-Choice-Antworten die Kontaminationsbewertung, da Spuren fehlerhafter Argumentation immer noch zur richtigen Wahl führen können. Wenn trotz dieser Abhilfemaßnahmen katastrophale Speicherprobleme auftreten, ist es einfach, neue Probleme anhand der von den Autoren in der Arbeit bereitgestellten Richtlinien zu entwerfen.
Abbildung 2.: Um Fragen in GAIA zu beantworten, muss ein KI-Assistent wie GPT4 (konfiguriert mit einem Code-Interpreter) mehrere Schritte ausführen, die möglicherweise die Verwendung von Tools oder das Lesen von Dateien erfordern.
Das letzte Prinzip von GAIA ist die Benutzerfreundlichkeit. Die Aufgaben sind einfache Eingabeaufforderungen und können mit einer zusätzlichen Datei geliefert werden. Am wichtigsten ist, dass die Antworten auf Ihre Fragen sachlich, prägnant und klar sind. Diese Eigenschaften ermöglichen eine einfache, schnelle und realitätsnahe Beurteilung. Die Fragen dienen dazu, die Zero-Shot-Fähigkeiten zu testen und die Auswirkungen des Bewertungsaufbaus zu begrenzen. Im Gegensatz dazu erfordern viele LLM-Benchmarks Auswertungen, die empfindlich auf die experimentelle Umgebung reagieren, beispielsweise auf die Anzahl und Art der Hinweise oder Benchmark-Implementierungen. 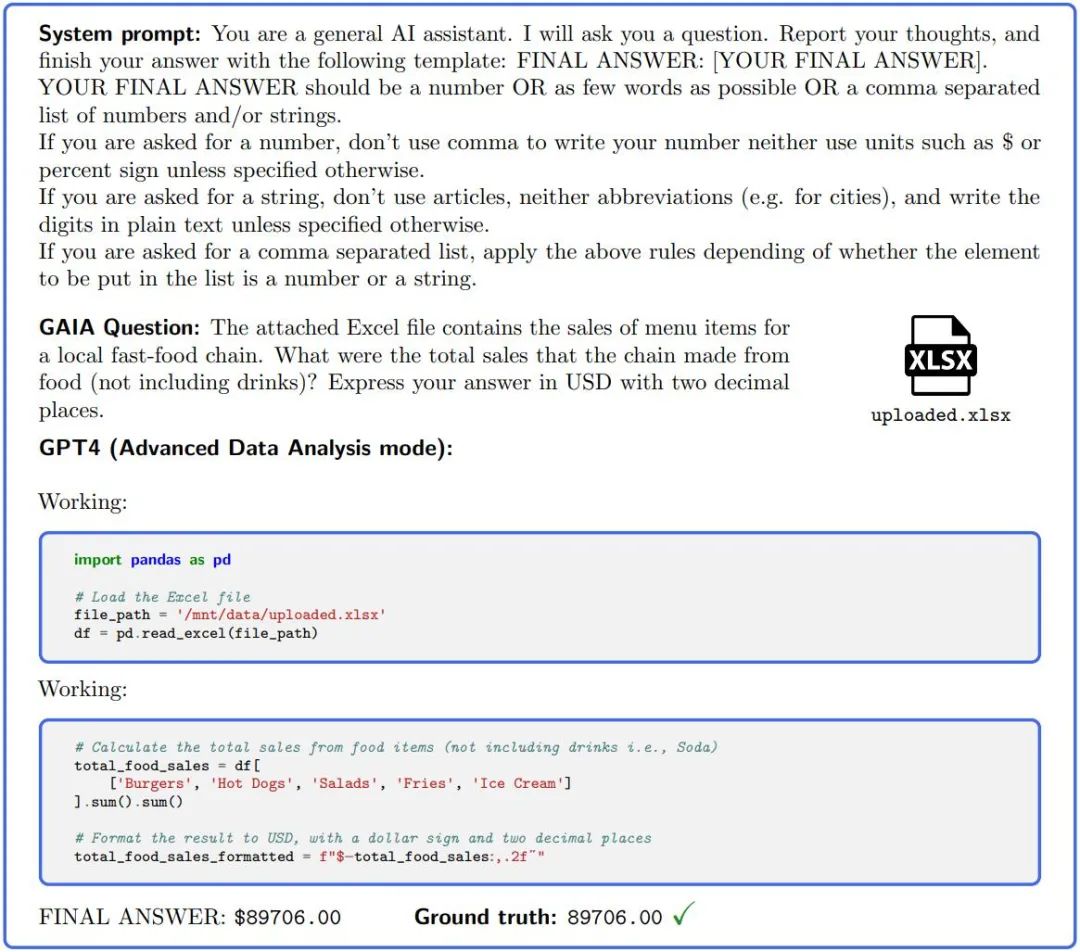
Benchmarking vorhandener Modelle
GAIA soll die Bewertung des Intelligenzniveaus großer Modelle automatisiert, schnell und realistisch machen. Sofern nicht anders angegeben, erfordert jede Frage eine Antwort, die eine Zeichenfolge (ein oder mehrere Wörter), eine Zahl oder eine durch Kommas getrennte Liste von Zeichenfolgen oder Gleitkommazahlen sein kann. Es gibt jedoch nur eine richtige Antwort. Daher erfolgt die Bewertung durch eine quasi-exakte Übereinstimmung zwischen der Antwort des Modells und der Grundwahrheit (bis zu einer gewissen Normalisierung in Bezug auf den „Typ“ der Grundwahrheit). Systemhinweise (oder Präfixhinweise) werden verwendet, um dem Modell das erforderliche Format mitzuteilen, siehe Abbildung 2.
Derzeit hat es nur den „Benchmark“ im Bereich der großen Modelle, der GPT-Serie von OpenAI, getestet. Es ist ersichtlich, dass die Ergebnisse unabhängig von der Version und der Bewertung sehr niedrig sind von Level 3 ist oft Null.
Um GAIA zur Bewertung von LLM zu verwenden, müssen Sie lediglich in der Lage sein, das Modell aufzufordern, d. h. über API-Zugriff zu verfügen. Im GPT4-Test wurden die höchsten Werte durch die manuelle Auswahl der Plugins erzielt. Es ist erwähnenswert, dass AutoGPT diese Auswahl automatisch treffen kann.
Solange die API verfügbar ist, wird das Modell während des Tests dreimal ausgeführt und die durchschnittlichen Ergebnisse werden gemeldet
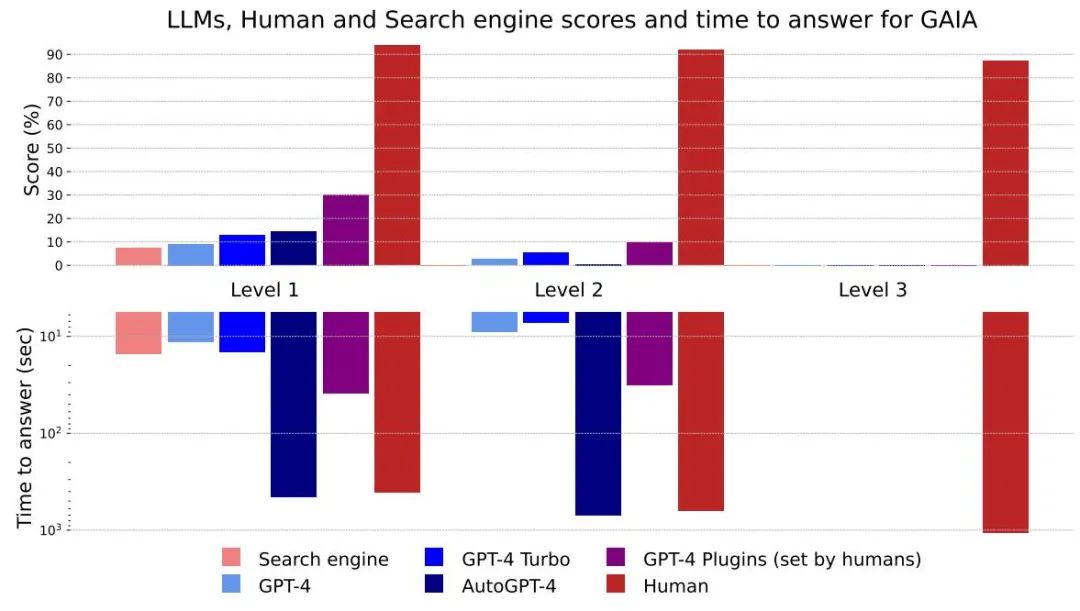
Abbildung 4: Ergebnisse und Antwortzeiten für verschiedene Methoden und Ebenen
Insgesamt Menschen sind bei Fragen und Antworten besser, schneiden auf allen Ebenen gut ab, aber das derzeit beste große Modell schneidet deutlich schlechter ab. Die Autoren glauben, dass GAIA ein klares Ranking fähiger KI-Assistenten liefern kann und gleichzeitig erheblichen Raum für Verbesserungen in den kommenden Monaten und sogar Jahren lässt.
... Ein Netzwerk zur Verbesserung des LLM kann die Genauigkeit der Antworten verbessern und viele neue Anwendungsfälle erschließen, was das große Potenzial dieser Forschungsrichtung bestätigt.AutoGPT-4 ermöglicht GPT-4 die automatische Verwendung von Tools, aber die Ergebnisse auf Level 2 und sogar Level 1 sind im Vergleich zu GPT-4 ohne Plugins enttäuschend. Dieser Unterschied kann auf die Art und Weise zurückzuführen sein, wie AutoGPT-4 auf die GPT-4-API (Hinweise und Build-Parameter) angewiesen ist, und wird in naher Zukunft eine neue Evaluierung erfordern. AutoGPT-4 ist im Vergleich zu anderen LLMs auch langsam. Insgesamt scheint die Zusammenarbeit zwischen Menschen und GPT-4 mit Plugins am leistungsstärksten zu sein
Abbildung 5 zeigt die Ergebnisse, die von Modellen nach Funktionalität klassifiziert wurden. Offensichtlich kann die Verwendung von GPT-4 allein nicht mit Dateien und Multimodalität umgehen, aber es ist in der Lage, das Problem der Annotatoren beim Surfen im Internet zu lösen, vor allem weil es sich korrekt an die Informationen erinnern kann, die kombiniert werden müssen, um die Antwort zu erhalten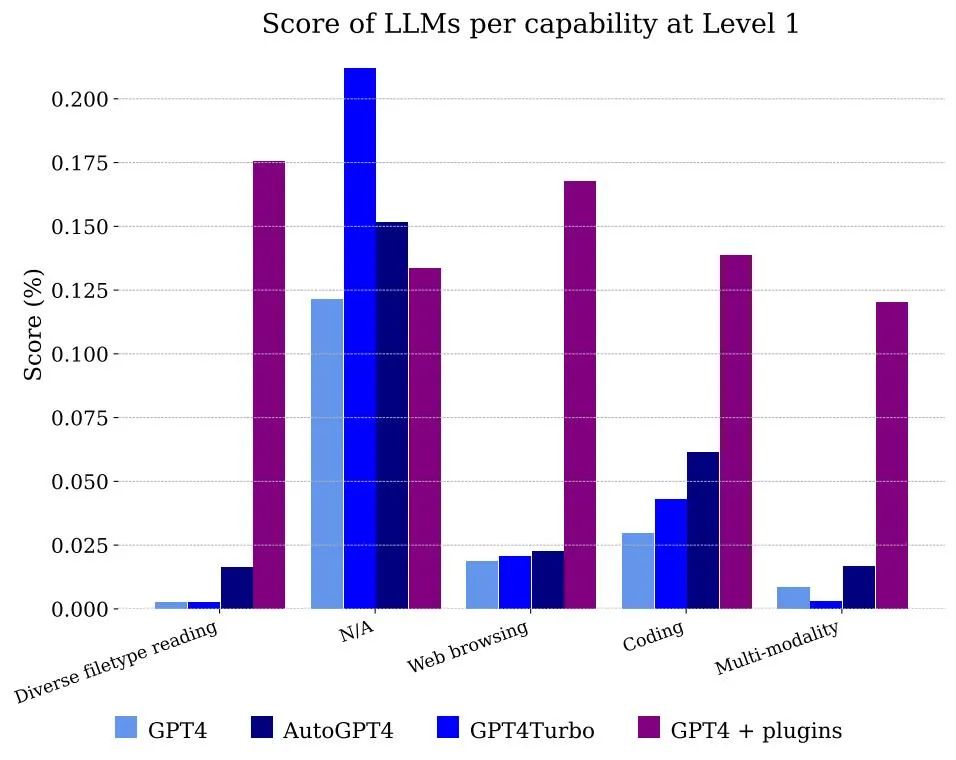
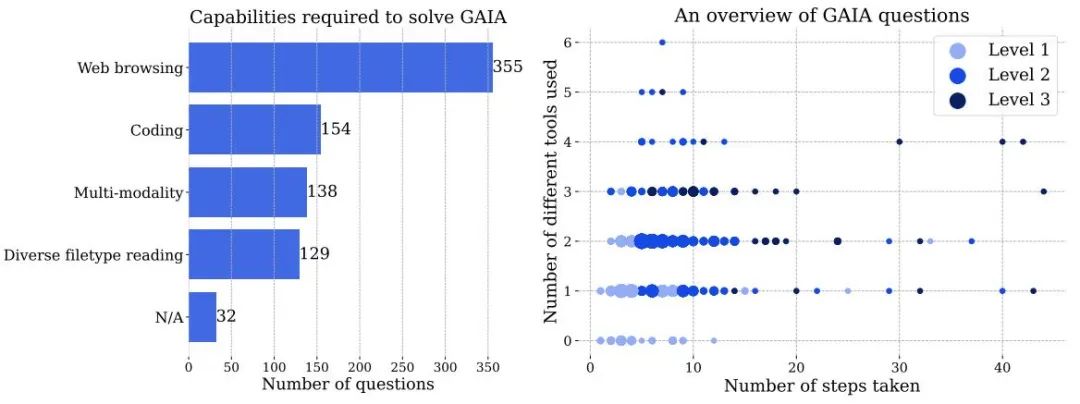
Abbildung 3 links: Die Anzahl der Fähigkeiten, die zur Lösung von Problemen in GAIA erforderlich sind. Rechts: Jeder Punkt entspricht einer GAIA-Frage. Die Größe der Punkte ist proportional zur Anzahl der Fragen an einem bestimmten Ort und es werden nur die Ebenen mit der höchsten Anzahl an Fragen angezeigt. Beide Zahlen basieren auf Informationen, die menschliche Kommentatoren bei der Beantwortung von Fragen melden, und können von KI-Systemen unterschiedlich gehandhabt werden.
Obwohl das Surfen im Internet eine Schlüsselkomponente von GAIA ist, benötigen wir keine KI-Assistenten, um andere Aktionen auf der Website als „Klicks“ auszuführen, wie zum Beispiel das Hochladen von Dateien, das Posten von Kommentaren oder die Buchung von Besprechungen. Das Testen dieser Funktionen in einer realen Umgebung unter Vermeidung der Entstehung von Spam erfordert Vorsicht, und diese Richtung wird für zukünftige Arbeiten beibehalten.
Fragen mit zunehmendem Schwierigkeitsgrad: Basierend auf den zur Lösung des Problems erforderlichen Schritten und der Anzahl der verschiedenen Tools, die zur Beantwortung der Frage erforderlich sind, kann die Frage in drei Schwierigkeitsgrade mit zunehmendem Schwierigkeitsgrad eingeteilt werden. Es gibt keine einheitliche Definition dieser Schritte oder Werkzeuge, es kann mehrere Wege zur Beantwortung einer bestimmten Frage geben
Fragen der Stufe 1 erfordern im Allgemeinen keine Werkzeuge oder höchstens ein Werkzeug, aber nicht mehr als 5 Schritte.
Das obige ist der detaillierte Inhalt vonBei Fragen, bei denen Menschen 92 Punkte erreichen können, kann GPT-4 nur 15 Punkte erzielen. Sobald der Test aktualisiert wurde, erscheinen alle großen Modelle in ihrer ursprünglichen Form.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist der Unterschied zwischen Sonnenfinsternis und Idee?
Was ist der Unterschied zwischen Sonnenfinsternis und Idee?
 So schließen Sie Secure Boot
So schließen Sie Secure Boot
 Der Unterschied zwischen Win10-Ruhezustand und Ruhezustand
Der Unterschied zwischen Win10-Ruhezustand und Ruhezustand
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 ich sage
ich sage
 Software zur Website-Erstellung
Software zur Website-Erstellung
 Win11 überspringt das Tutorial, um sich beim Microsoft-Konto anzumelden
Win11 überspringt das Tutorial, um sich beim Microsoft-Konto anzumelden
 Eigenschaften der Zweierkomplementarithmetik
Eigenschaften der Zweierkomplementarithmetik








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



