



Mit der Entwicklung des Internets können Unternehmen immer mehr Daten erhalten. Diese Daten helfen Unternehmen, Benutzer besser zu verstehen, sogenannte Kundenprofile, und können die Benutzererfahrung verbessern. Allerdings können diese Daten eine große Menge unbeschrifteter Daten enthalten. Wenn alle Daten manuell beschriftet werden, treten zwei Probleme auf. Erstens ist die manuelle Etikettierung zeitaufwändig und ineffizient. Mit zunehmender Datenmenge müssen mehr Mitarbeiter eingestellt werden, es wird länger dauern und die Kosten werden höher. Zweitens ist es mit zunehmender Anzahl von Benutzern schwierig, mit dem Wachstum der Daten durch manuelle Kennzeichnung Schritt zu halten. Teil 01:
Was ist halbüberwachtes Lernen? Etiketten Die Daten enthalten unbeschriftete Daten zum Trainieren des Modells. Beim halbüberwachten Lernen wird normalerweise ein Attributraum basierend auf beschrifteten Daten erstellt und anschließend effektive Informationen aus unbeschrifteten Daten extrahiert, um den Attributraum zu füllen (oder zu rekonstruieren). Daher wird der anfängliche Trainingssatz des halbüberwachten Lernens normalerweise in den beschrifteten Datensatz D1 und den unbeschrifteten Datensatz D2 unterteilt. Anschließend wird das halbüberwachte Lernmodell durch grundlegende Schritte wie Vorverarbeitung und Merkmalsextraktion trainiert und anschließend das trainierte Modell wird in der Produktionsumgebung verwendet, um Benutzern Dienste bereitzustellen.Teil 02. Annahmen des halbüberwachten Lernens
Um die „nützlichen“ Informationen in den gekennzeichneten Daten effektiv zu ergänzen, werden einige Annahmen zur Datenaufteilung und anderen Aspekten getroffen. Die Grundannahme des halbüberwachten Lernens besteht darin, dass p (x) die Informationen von p (y | x) enthält, dh die unbeschrifteten Daten sollten Informationen enthalten, die für die Beschriftungsvorhersage nützlich sind und sich von den beschrifteten Daten unterscheiden oder schwierig sind um aus den gekennzeichneten Daten Informationen zu gewinnen, die aus den Daten extrahiert wurden. Darüber hinaus gibt es einige Annahmen, die dem Algorithmus dienen. Die Ähnlichkeitshypothese (Glättungshypothese) bedeutet beispielsweise, dass in dem durch Datenproben konstruierten Attributraum ähnliche oder ähnliche Stichproben die gleiche Bezeichnung haben. Die Hypothese der Trennung niedriger Dichte bedeutet, dass es eine Entscheidungsgrenze gibt, die unterschiedliche Bezeichnungen unterscheiden kann Es gibt nur wenige Datenbeispiele. 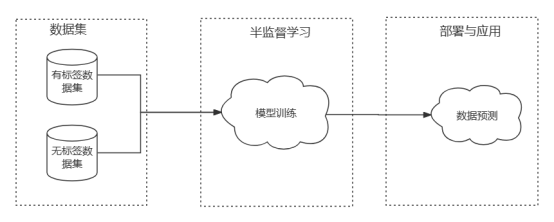
Teil 03,
Klassifizierung halbüberwachter LernalgorithmenEs gibt viele halbüberwachte Lernalgorithmen, die grob in
unterteilt werden können induktives Lernen (Induktives Modell) , der Unterschied zwischen den beiden liegt in der Auswahl des Testdatensatzes, der für die Modellbewertung verwendet wird. Halbüberwachtes Direkt-Push-Lernen bedeutet, dass der Datensatz, der zur Vorhersage der Bezeichnung benötigt wird, der unbeschriftete Datensatz ist, der für das Training verwendet wird. Der Zweck des Lernens besteht darin, die Genauigkeit der Vorhersageergebnisse weiter zu verbessern. Induktives Lernen sagt Bezeichnungen für völlig unbekannte Datensätze voraus. Darüber hinaus sind die Schritte gängiger halbüberwachter Lernalgorithmen: Der erste Schritt besteht darin, ein Modell für beschriftete Daten zu trainieren, dieses Modell dann zum Beschriften unbeschrifteter Daten zu verwenden und dann die Pseudobezeichnungen und die zu kombinieren Beschriftete Daten werden zu einem neuen Trainingssatz kombiniert, ein neues Modell wird auf diesem Trainingssatz trainiert und schließlich wird das Modell zum Beschriften des Vorhersagedatensatzes verwendet.
Teil 04, Zusammenfassung 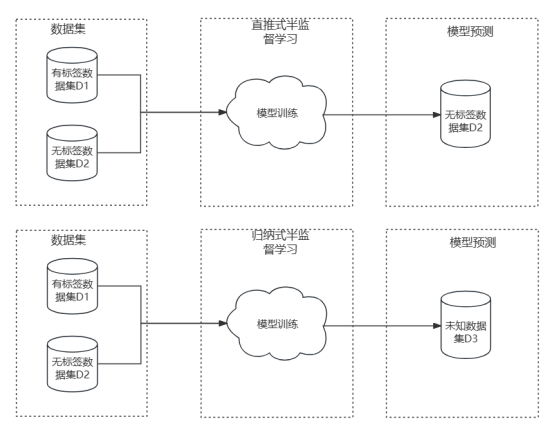
Das größte Problem des halbüberwachten Lernens besteht darin, dass die Leistung des Modells in vielen Fällen vom gekennzeichneten Datensatz abhängt und die Qualitätsanforderungen für den gekennzeichneten Datensatz hoch sind. Selbst beim halbüberwachten Lernen unterscheidet sich die Vorhersagegenauigkeit des überwachten Lernmodells nicht wesentlich von den Ergebnissen des überwachten Modells, das auf dem markierten Datensatz basiert. Im Gegenteil, das halbüberwachte Modell verbraucht mehr Ressourcen, um effektiv zu extrahieren Informationen aus den unbeschrifteten Daten. Daher besteht die Entwicklungsrichtung des halbüberwachten Lernens darin, die Robustheit des Algorithmus und die Effektivität der Datenextraktion zu verbessern.
Das obige ist der detaillierte Inhalt vonUmgeschriebener Titel: Erkundung der Anwendungsbereiche des halbüberwachten Lernens und der damit verbundenen Szenarien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Der Unterschied zwischen leichtgewichtigen Anwendungsservern und Cloud-Servern
Der Unterschied zwischen leichtgewichtigen Anwendungsservern und Cloud-Servern
 So verwenden Sie die Wertfunktion
So verwenden Sie die Wertfunktion
 So beheben Sie einen Analysefehler
So beheben Sie einen Analysefehler
 Was ist Hadoop?
Was ist Hadoop?
 Ausfallzeit des Windows 10-Dienstes
Ausfallzeit des Windows 10-Dienstes
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server












