

 Technologie-Peripheriegeräte
KI
Hat das 13B-Modell im vollständigen Showdown mit GPT-4 den Vorteil? Stecken ungewöhnliche Umstände dahinter?
Technologie-Peripheriegeräte
KI
Hat das 13B-Modell im vollständigen Showdown mit GPT-4 den Vorteil? Stecken ungewöhnliche Umstände dahinter?
Hat das 13B-Modell im vollständigen Showdown mit GPT-4 den Vorteil? Stecken ungewöhnliche Umstände dahinter?

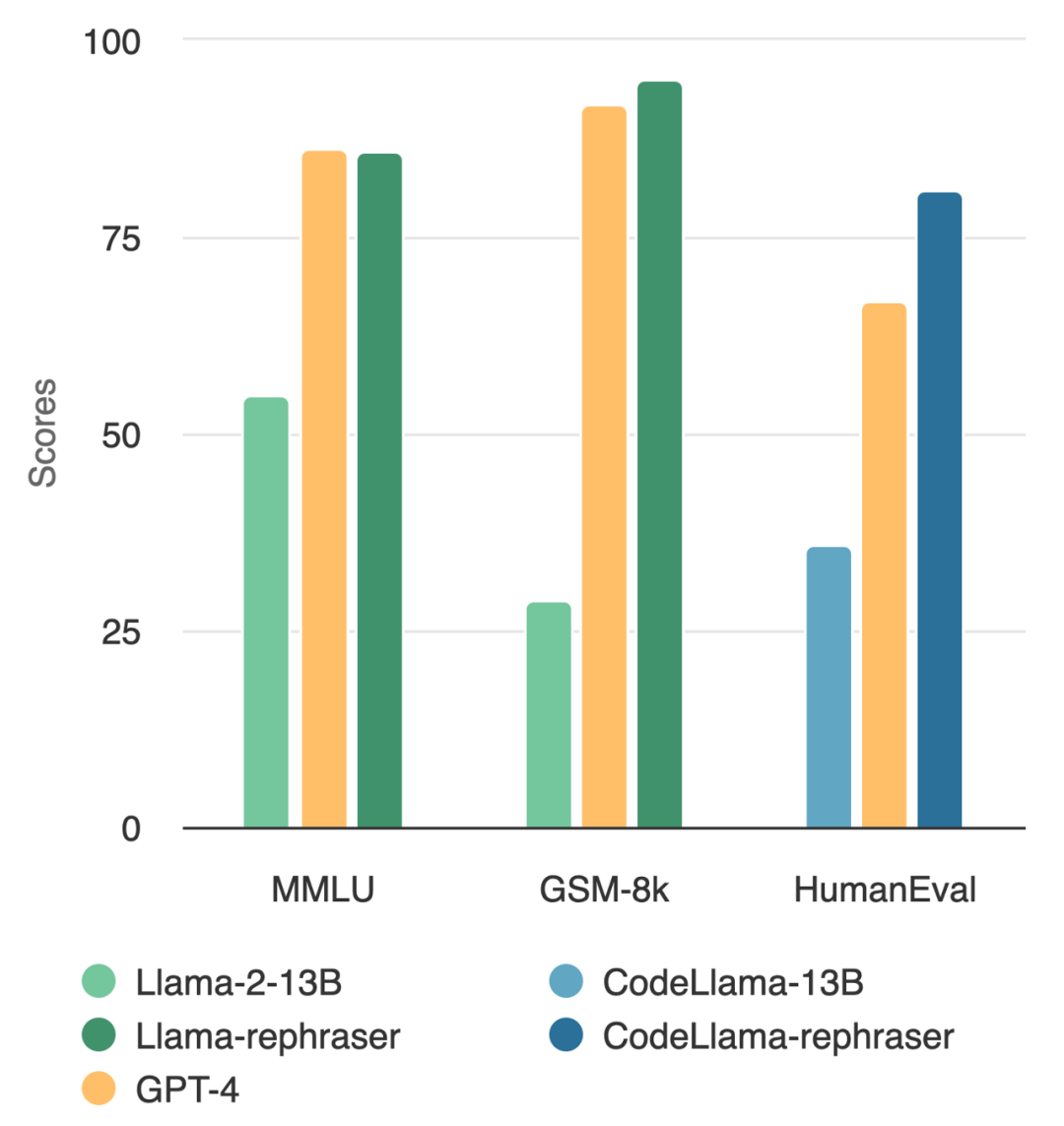
Ein Modell mit 13B-Parametern kann tatsächlich das Top-GPT-4 schlagen? Wie in der Abbildung unten gezeigt, folgte dieser Test auch der Datenentrauschungsmethode von OpenAI, um die Gültigkeit der Ergebnisse sicherzustellen, und es wurden keine Hinweise auf eine Datenkontamination gefunden Ich habe festgestellt, dass die Leistung des Modells relativ hoch ist, solange das Wort „Rephraser“ enthalten ist.
 Was ist der Trick dahinter? Es stellt sich heraus, dass die Daten kontaminiert sind, dh die Testsatzinformationen sind im Trainingssatz durchgesickert, und diese Kontamination ist nicht leicht zu erkennen. Trotz der entscheidenden Bedeutung dieses Themas bleibt das Verständnis und die Erkennung von Kontaminationen ein offenes und herausforderndes Rätsel.
Was ist der Trick dahinter? Es stellt sich heraus, dass die Daten kontaminiert sind, dh die Testsatzinformationen sind im Trainingssatz durchgesickert, und diese Kontamination ist nicht leicht zu erkennen. Trotz der entscheidenden Bedeutung dieses Themas bleibt das Verständnis und die Erkennung von Kontaminationen ein offenes und herausforderndes Rätsel.
Zu diesem Zeitpunkt ist die am häufigsten verwendete Methode zur Dekontamination die N-Gramm-Überlappung und die eingebettete Ähnlichkeitssuche: Die N-Gramm-Überlappung basiert auf dem String-Matching zur Erkennung von Kontaminationen und wird häufig in Modellen wie GPT-4 und PaLM verwendet und die Llama-2-Methode; die Einbettungsähnlichkeitssuche verwendet Einbettungen aus einem vorab trainierten Modell (z. B. BERT), um ähnliche und potenziell kontaminierte Beispiele zu finden.
Untersuchungen der UC Berkeley und der Shanghai Jiao Tong University zeigen jedoch, dass einfache Änderungen an Testdaten (z. B. Umschreiben, Übersetzung) bestehende Erkennungsmethoden leicht umgehen können. Sie bezeichnen solche Variationen von Testfällen als „Rephrased Samples“.
Das Folgende muss im MMLU-Benchmark-Test neu geschrieben werden: die Demonstrationsergebnisse des neu geschriebenen Beispiels. Die Ergebnisse zeigen, dass das 13B-Modell eine sehr hohe Leistung (MMLU 85,9) erreichen kann, wenn solche Proben in den Trainingssatz einbezogen werden. Leider können bestehende Nachweismethoden wie N-Gramm-Überlappung und Einbettungsähnlichkeit diese Kontamination nicht erkennen. Beispielsweise haben eingebettete Ähnlichkeitsmethoden Schwierigkeiten, Umformulierungsprobleme von anderen Problemen im selben Thema zu unterscheiden
Bei ähnlichen Umformulierungstechniken beobachtet dieser Artikel konsistente Ergebnisse bei weit verbreiteten Codierungs- und Mathematik-Benchmarks wie HumanEval und GSM-8K (im Bild am Anfang des Artikels dargestellt). Daher ist es von entscheidender Bedeutung, solche Inhalte erkennen zu können, die neu geschrieben werden müssen: umgeschriebene Beispiele.
 Als nächstes wollen wir sehen, wie diese Studie durchgeführt wurde.
Als nächstes wollen wir sehen, wie diese Studie durchgeführt wurde.

- Projektadresse: https://github.com/lm-sys/llm -decontaminator#detect
- Papiereinführung Mit der rasanten Entwicklung großer Modelle (LLM) schenken die Menschen dem Problem der Testset-Verschmutzung immer mehr Aufmerksamkeit. Viele Menschen haben Bedenken hinsichtlich der Glaubwürdigkeit öffentlicher Benchmarks geäußert
Um dieses Problem zu lösen, verwenden einige Leute traditionelle Dekontaminationsmethoden wie String-Matching (z. B. N-Gramm-Überlappung), um die Benchmark-Daten zu entfernen. Diese Vorgänge reichen jedoch bei weitem nicht aus, da diese Sanierungsmaßnahmen leicht umgangen werden können, indem nur einige einfache Änderungen an den Testdaten vorgenommen werden (z. B. Umschreiben, Übersetzung).
Wenn solche Änderungen an den Testdaten nicht beseitigt werden, 13B Wichtiger ist, dass das Modell den Testbenchmark leicht übertrifft und eine vergleichbare Leistung wie GPT-4 erreicht. Die Forscher überprüften diese Beobachtungen in Benchmark-Tests wie MMLU, GSK8k und HumanEval
Gleichzeitig schlägt dieses Papier zur Bewältigung dieser wachsenden Risiken auch eine leistungsstärkere LLM-basierte Dekontaminationsmethode (LLM-Dekontaminator) und deren Anwendung vor Die Ergebnisse zeigen, dass die in diesem Dokument vorgeschlagene LLM-Methode bei der Entfernung umgeschriebener Stichproben deutlich besser ist als bestehende Methoden.
Dieser Ansatz ergab auch einige bisher unbekannte Testüberschneidungen. Beispielsweise finden wir in Pre-Training-Sets wie RedPajamaData-1T und StarCoder-Data eine Überlappung von 8–18 % mit dem HumanEval-Benchmark. Darüber hinaus wurde in diesem Artikel diese Kontamination auch im von GPT-3.5/4 generierten synthetischen Datensatz festgestellt, was auch das potenzielle Risiko einer versehentlichen Kontamination im Bereich der KI verdeutlicht.
Wir hoffen, dass wir mit diesem Artikel die Community dazu auffordern, bei der Verwendung öffentlicher Benchmarks leistungsfähigere Reinigungsmethoden einzuführen und aktiv neue einmalige Testfälle zu entwickeln, um das Modell genau zu bewerten.
Was neu geschrieben werden muss, ist : Schreiben Sie das Beispiel neu
Das Ziel dieses Artikels besteht darin, zu untersuchen, ob sich eine einfache Änderung beim Einschließen des Testsatzes in den Trainingssatz auf die endgültige Benchmark-Leistung auswirkt, und diese Änderung im Testfall als „was sein muss“ zu bezeichnen neu geschrieben ist: das Beispiel neu schreiben". In den Experimenten wurden verschiedene Bereiche des Benchmarks berücksichtigt, darunter Mathematik, Wissen und Codierung. Beispiel 1 ist der Inhalt von GSM-8k, der neu geschrieben werden muss: ein neu geschriebenes Beispiel, bei dem eine 10-Gramm-Überlappung nicht erkannt werden kann und der geänderte Text die gleiche Semantik wie der Originaltext beibehält.

Es gibt geringfügige Unterschiede in der Umschreibetechnologie für verschiedene Formen der Grundkontamination. Bei textbasierten Benchmark-Tests werden in diesem Artikel die Testfälle neu geschrieben, indem die Wortreihenfolge neu angeordnet oder Synonymersetzungen verwendet werden, um das Ziel zu erreichen, die Semantik nicht zu ändern. Im Code-basierten Benchmark-Test wird dieser Artikel durch Ändern des Codierungsstils, der Benennungsmethode usw. neu geschrieben. Wie unten gezeigt, wird in Algorithmus 1 ein einfacher Algorithmus für den gegebenen Testsatz vorgeschlagen. Diese Methode kann dazu beitragen, dass Testproben einer Entdeckung entgehen.
 Als Nächstes schlägt dieses Papier eine neue Methode zur Kontaminationserkennung vor, mit der Inhalte, die relativ zur Basislinie neu geschrieben werden müssen, genau aus dem Datensatz entfernt werden können: Proben neu schreiben.
Als Nächstes schlägt dieses Papier eine neue Methode zur Kontaminationserkennung vor, mit der Inhalte, die relativ zur Basislinie neu geschrieben werden müssen, genau aus dem Datensatz entfernt werden können: Proben neu schreiben.
In diesem Artikel wird insbesondere der LLM-Dekontaminator vorgestellt. Zunächst wird für jeden Testfall eine eingebettete Ähnlichkeitssuche verwendet, um die Top-k-Trainingselemente mit der höchsten Ähnlichkeit zu identifizieren. Anschließend wird jedes Paar von einem LLM (z. B. GPT-4) daraufhin bewertet, ob sie identisch sind. Dieser Ansatz hilft dabei, zu bestimmen, wie viel des Datensatzes neu geschrieben werden muss: das Rewrite-Beispiel.
Das Venn-Diagramm verschiedener Kontaminationen und verschiedener Nachweismethoden ist in Abbildung 4 dargestellt Bei umgeschriebenen Proben können deutlich höhere Werte erzielt werden, wobei eine mit GPT-4 vergleichbare Leistung bei drei weit verbreiteten Benchmarks (MMLU, HumanEval und GSM-8k) erreicht wird. Dies legt nahe, dass Folgendes umgeschrieben werden muss: Umgeschriebene Proben sollten als Kontamination betrachtet werden und sollten es auch sein aus den Trainingsdaten entfernt. In Abschnitt 5.2 muss laut MMLU/HumanEval in diesem Artikel Folgendes umgeschrieben werden: Umschreiben der Probe, um verschiedene Methoden zur Kontaminationserkennung zu bewerten. In Abschnitt 5.3 wenden wir den LLM-Dekontaminator auf ein weit verbreitetes Trainingsset an und entdecken bisher unbekannte Kontaminationen. Als nächstes schauen wir uns einige Hauptergebnisse an Umgeschrieben werden soll: Rewrite Llama-2 7B und 13B, die auf den Proben trainiert wurden, erzielen auf MMLU deutlich hohe Werte von 45,3 bis 88,5. Dies deutet darauf hin, dass umgeschriebene Proben die Basisdaten erheblich verfälschen können und als Kontamination betrachtet werden sollten.
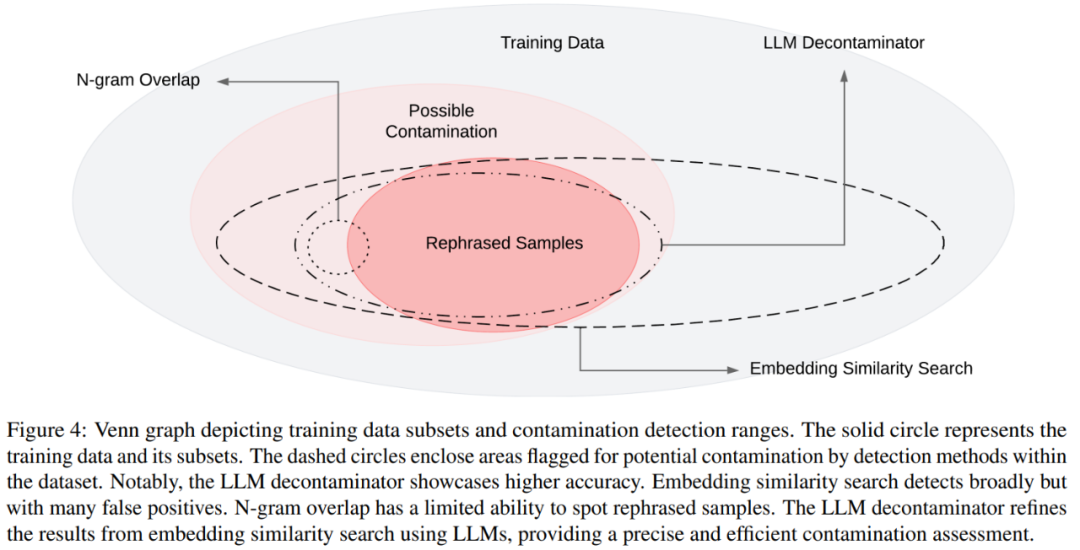
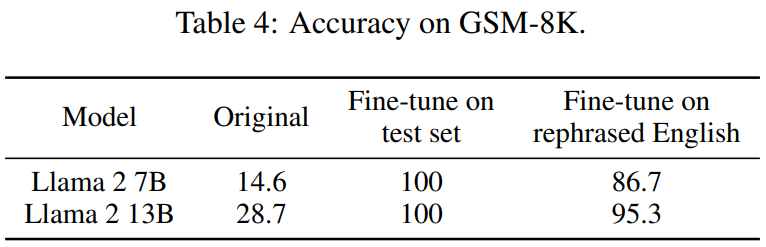
Tabelle 4 unten erzielt den gleichen Effekt:
Bewertung von Nachweismethoden für Kontaminationen
Wie in Tabelle 5 gezeigt, führen alle anderen Nachweismethoden mit Ausnahme des LLM-Dekontaminators zu einigen falsch positiven Ergebnissen. Weder umgeschriebene noch übersetzte Samples werden durch N-Gramm-Überlappung erkannt. Bei Verwendung von Multi-QA-BERT erwies sich die Einbettung der Ähnlichkeitssuche bei übersetzten Proben als völlig wirkungslos.状 Der Verschmutzungsstatus des Datensatzes

In Tabelle 7 wird der Datenverschmutzungsprozentsatz der Datenverschmutzung jedes Trainingsdatensatzes angezeigt 79 Der einzige Inhalt, der neu geschrieben werden muss, ist: Instanzen neu geschriebener Proben, Dies macht 1,58 % des MATH-Testsatzes aus. Beispiel 5 ist eine Anpassung des MATH-Tests an die MATH-Trainingsdaten.
Weitere Informationen finden Sie im Originalpapier
Das obige ist der detaillierte Inhalt vonHat das 13B-Modell im vollständigen Showdown mit GPT-4 den Vorteil? Stecken ungewöhnliche Umstände dahinter?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Cryptocurrency IDO -Plattform Top5
Aug 21, 2025 pm 07:33 PM
Cryptocurrency IDO -Plattform Top5
Aug 21, 2025 pm 07:33 PM
Die besten IDO-Plattformen im Jahr 2025 sind Pump.Fun, Bounce, Coin Terminal, Avalaunch und Gate Launchpad, die für Meme-Münzspekulationen, Community-gesteuerte Auktionen, hochrangige Aktivitäten, ökologische Investitionen und angemessene Teilnahme von Novices geeignet sind. Die Auswahl muss Investitionsziele, Risikotoleranz und Projektpräferenzen kombinieren und sich auf die Überprüfung und Sicherheit von Plattform konzentrieren.
 Die Verknüpfungspreisbrüche durch 24 USD Key Widerstand Analyse: Kettenlink -Projekt -Grundlagen und Preistrends
Aug 16, 2025 pm 12:15 PM
Die Verknüpfungspreisbrüche durch 24 USD Key Widerstand Analyse: Kettenlink -Projekt -Grundlagen und Preistrends
Aug 16, 2025 pm 12:15 PM
Contents: Current price trend and key technical signals to drive LINK up core factors whale and institutional funds strong entry strategic reserve mechanism strengthens deflation expectations Traditional financial giants adopt accelerated ecological expansion project fundamentals: dominating the real world assets (RWA) tokenization wave price forecast: short-term momentum and long-term potential Summary of current price trends and key technical signals Resistance and support level: If today effectively breaks through 24,64 USD, das nächste Ziel von Link ist Fibonacci 0,786 Retracement Level 26,46, was das 2024 -Hoch von 30,93 USD nach dem Durchbruch in Frage stellen kann. Schlüsselunterstützung
 Was ist Render (RNDR -Münze)? Was ist der Preis? 2025 - 2030s Münzpreisprognose
Aug 16, 2025 pm 12:30 PM
Was ist Render (RNDR -Münze)? Was ist der Preis? 2025 - 2030s Münzpreisprognose
Aug 16, 2025 pm 12:30 PM
Was ist Render? Blockchain Reshapes Die Grafik -Rendering -Ökosystem -Renderung ist ein dezentrales GPU -Rendering -Netzwerk, das auf der Blockchain -Technologie basiert und das Ressourcenkonzentrationsmuster im traditionellen Grafikrendernfeld verstoßen. Es verbindet effizient die Angebots- und Nachfrageparteien des globalen Computing -Stromversorgung und der Nachfrage durch intelligente Vertragsmechanismen: Content Creators (wie Filmproduktionsunternehmen, Spieleentwicklungsteams, AI -Labors usw.): Sie können komplexe Rendering -Aufgaben auf der Plattform einreichen und für sie mit RNDR -Token bezahlen. Rechenleistung Anbieter (Einzelpersonen oder Institutionen mit Leerlauf -GPUs): Sie tragen durch den Zugriff auf das Netzwerk bei und erhalten nach Abschluss der Aufgaben RNDR -Token -Belohnungen. Dieses Modell löst effektiv mehrere Engpässe in herkömmlichen Rendering -Prozessen: Kostenoptimierung: Nutzung globaler verteilter Rechenleistung Fonds
 Was genau ist Token? Was ist der Unterschied zwischen Token und Münze
Aug 16, 2025 pm 12:33 PM
Was genau ist Token? Was ist der Unterschied zwischen Token und Münze
Aug 16, 2025 pm 12:33 PM
Coin ist ein natives Vermögenswert ihrer eigenen Blockchain wie BTC und ETH, die zur Zahlung von Gebühren und Anreizen von Netzwerken verwendet werden. Token werden basierend auf vorhandenen Blockchains (wie Ethereum) durch intelligente Verträge erstellt, die Vermögenswerte, Berechtigungen oder Dienstleistungen darstellen und sich auf die Wirt -Kette stützen, wie z.
 Was ist Polkadot (Punktwährung)? Zukünftige Entwicklung und Preisprognose des Punktes
Aug 21, 2025 pm 07:30 PM
Was ist Polkadot (Punktwährung)? Zukünftige Entwicklung und Preisprognose des Punktes
Aug 21, 2025 pm 07:30 PM
Was ist der Verzeichnispunkt (Pokermünze)? Der Ursprung von Polkadot DOT (Polkadot) Das Betriebsprinzip von Polkadot hat 5 Hauptmerkmale und zielt darauf ab, das Polkadot -Ökosystem (Ökosystem) zu etablieren. Preisprognose Polkadot 2025 Preisprognose Polkadot 2026-203
 Altcoin -Bullenmarkt Impuls stärkt, Bitcoin stagniert
Aug 16, 2025 pm 12:48 PM
Altcoin -Bullenmarkt Impuls stärkt, Bitcoin stagniert
Aug 16, 2025 pm 12:48 PM
Der Kryptomarkt hat diese Woche eine subtile Wendung verzeichnet. Bitcoin fiel rund 119.000 US -Dollar in Konsolidierung, wobei sich die Volatilität verengte, während die meisten Mainstream -Altcoins einen starken Impuls zeigten. Diese Differenzierung hat weit verbreitete Aufmerksamkeit erregt: Zeigt sie an, dass sich die Mittel von Bitcoin zu Altcoins verlagern und der Altcoin -Rotationsmarkt stillschweigend begonnen hat? Obwohl Bitcoin die Marktdominanz immer noch fest kontrolliert, erholt sich der Altseason -Index stillschweigend und veröffentlicht potenzielle Änderungen. Altcoins sind im Allgemeinen gestiegen, und Bitcoin hat sich in letzter Zeit seitwärts angesammelt und hat erhebliche Veränderungen in der Marktstruktur festgestellt. Der Bitcoin -Marktdominanz ist auf 58,54% gesunken, was dem Äther in 24 Stunden um 5,32% gesunken ist
 Die vollständigsten Währungsnomen im gesamten Netzwerk, das Anfänger wissen müssen - müssen von Xiaobai lesen
Aug 16, 2025 pm 12:21 PM
Die vollständigsten Währungsnomen im gesamten Netzwerk, das Anfänger wissen müssen - müssen von Xiaobai lesen
Aug 16, 2025 pm 12:21 PM
Die Antwort lautet, dass Sie grundlegende Begriffe beherrschen müssen, wenn Sie zum ersten Mal in den Währungskreis eintreten. Der Artikel führt 2025 den Mainstream -Austausch wie Binance, Ouyi und Huobi vor und erklärt den Unterschied zwischen zentralisierten und dezentralen Austausch. Then, it systematically explains the core concepts such as blockchain, cryptocurrency, Bitcoin, Ethereum, altcoins, stablecoins, as well as account security knowledge such as public keys, private keys, mnemonics, and covers market terms such as bull markets, bear markets, HODL, K-lines, FOMO, and FUD, and briefly describes technical concepts such as k-mining, consensus mechanisms, smart Verträge, Dapps und Gasgebühren, um Anfängern zu helfen, den Münzkreis vollständig zu verstehen.
 Was ist Token
Aug 16, 2025 pm 12:39 PM
Was ist Token
Aug 16, 2025 pm 12:39 PM
Token sind digitale Vermögenswerte für Blockchains, die Eigenkapital oder Wert darstellen. Sie können in Zahlung, praktische, Wertpapiere, Stablecoins und NFTs usw. unterteilt werden, um Wertspeicher, Austausch, Governance, Belohnungen, Zugang und Sicherheiten zu erhalten. Sie werden über Ketten wie Ethereum durch intelligente Verträge ausgestellt und nach ERC-20-Standards erstellt. Sie können an zentralisierten oder dezentralen Börsen gehandelt und in Hot Storage (wie Metamaske) oder Kühllager (wie Ledger) gespeichert werden. Sie sind jedoch Risiken wie Preisschwankungen, Überwachung, Technologie, Projekte, Liquidität und Sicherheit ausgesetzt und sollten mit Vorsicht behandelt werden.
