


Im Allgemeinen wird bei der Bereitstellung großer Sprachmodelle normalerweise die Methode „Pre-Training-Fine-Tuning“ verwendet. Bei der Feinabstimmung des zugrunde liegenden Modells für mehrere Aufgaben (z. B. personalisierte Assistenten) werden die Kosten für Schulung und Bereitstellung jedoch sehr hoch. LowRank Adaptation (LoRA) ist eine effiziente Methode zur Parameterfeinabstimmung, die normalerweise verwendet wird, um das Basismodell an mehrere Aufgaben anzupassen und dadurch eine große Anzahl abgeleiteter LoRA-Adapter zu generieren
Umgeschrieben: Die Batch-Inferenz bietet viele Möglichkeiten während der Bereitstellung, und es hat sich gezeigt, dass dieses Muster eine vergleichbare Leistung wie die vollständige Feinabstimmung durch Feinabstimmung der Adaptergewichte erzielt. Während dieser Ansatz eine Einzeladapter-Inferenz mit geringer Latenz und eine serielle Ausführung über Adapter hinweg ermöglicht, reduziert er den gesamten Dienstdurchsatz erheblich und erhöht die Gesamtlatenz, wenn mehrere Adapter gleichzeitig bedient werden. Daher ist noch unbekannt, wie das groß angelegte Serviceproblem dieser fein abgestimmten Varianten gelöst werden kann
Kürzlich haben Forscher der UC Berkeley, Stanford und anderen Universitäten in einem Artikel eine neue Feinabstimmungsmethode namens S-LoRA vorgeschlagen

S-LoRA ist ein System, das für die skalierbare Bereitstellung vieler LoRA-Adapter entwickelt wurde. Es speichert alle Adapter im Hauptspeicher und ruft den von der aktuell ausgeführten Abfrage verwendeten Adapter in den GPU-Speicher ab.
S-LoRA schlägt die „Unified Paging“-Technologie vor, die einen einheitlichen Speicherpool verwendet, um verschiedene Ebenen dynamischer Adaptergewichte und KV-Cache-Tensoren unterschiedlicher Sequenzlängen zu verwalten. Darüber hinaus nutzt S-LoRA eine neue Tensor-Parallelitätsstrategie und hochoptimierte benutzerdefinierte CUDA-Kernel, um eine heterogene Stapelverarbeitung von LoRA-Berechnungen zu ermöglichen.
Diese Funktionen ermöglichen es S-LoRA, Tausende von LoRA-Adaptern auf einer oder mehreren GPUs zu einem Bruchteil der Kosten (2000 Adapter gleichzeitig zu bedienen) bereitzustellen und zusätzliche LoRA-Berechnungskosten zu minimieren. Im Gegensatz dazu muss vLLM-gepackt mehrere Kopien von Gewichten verwalten und kann aufgrund von GPU-Speicherbeschränkungen nur weniger als 5 Adapter bedienen ) Im Vergleich zur Bibliothek kann S-LoRA den Durchsatz um das bis zu Vierfache steigern und die Anzahl der bedienten Adapter kann um mehrere Größenordnungen erhöht werden. Daher ist S-LoRA in der Lage, skalierbare Dienste für viele aufgabenspezifische Feinabstimmungsmodelle bereitzustellen und bietet das Potenzial für eine umfassende Anpassung von Feinabstimmungsdiensten.
S-LoRA enthält drei wesentliche innovative Teile. Abschnitt 4 stellt die Batch-Strategie vor, die zur Aufteilung der Berechnungen zwischen dem Basismodell und dem LoRA-Adapter verwendet wird. Darüber hinaus lösten die Forscher auch die Herausforderungen der Bedarfsplanung, einschließlich Aspekten wie Adapter-Clustering und Zugangskontrolle. Die Fähigkeit zur Stapelverarbeitung über gleichzeitige Adapter hinweg bringt neue Herausforderungen für die Speicherverwaltung mit sich. Im fünften Teil fördern Forscher PagedAttention für Unfied Paging, um das dynamische Laden von LoRA-Adaptern zu unterstützen. Bei diesem Ansatz wird ein einheitlicher Speicherpool verwendet, um den KV-Cache und die Adaptergewichtungen seitenweise zu speichern. Dadurch kann die Fragmentierung reduziert und die sich dynamisch ändernden Größen des KV-Caches und der Adaptergewichte ausgeglichen werden. Schließlich stellt Teil 6 eine neue Tensor-Parallel-Strategie vor, die das Basismodell und den LoRA-Adapter effizient entkoppeln kann 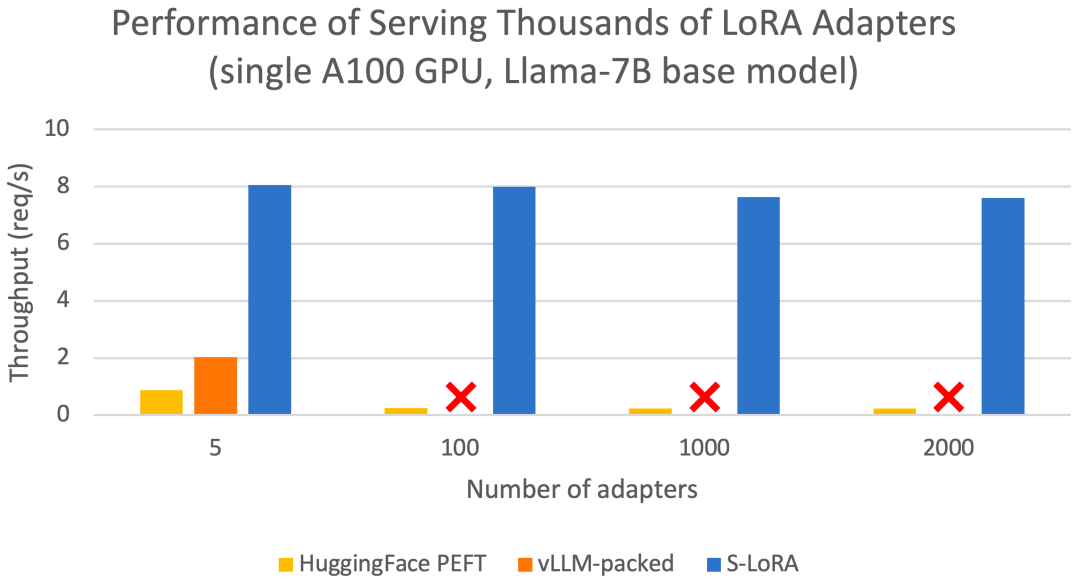
Die folgenden sind die Highlights:
Stapelverarbeitung
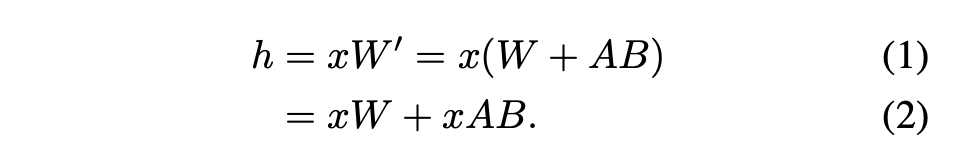 In diesem Artikel wird darauf hingewiesen, dass die Zusammenführung von LoRA-Adaptern in das Basismodell für Multi-LoRA-Hochdurchsatz-Dienst-Setups ineffizient ist. Stattdessen schlagen die Forscher vor, LoRA in Echtzeit zu berechnen, um xAB zu berechnen (wie in Gleichung 2 dargestellt).
In diesem Artikel wird darauf hingewiesen, dass die Zusammenführung von LoRA-Adaptern in das Basismodell für Multi-LoRA-Hochdurchsatz-Dienst-Setups ineffizient ist. Stattdessen schlagen die Forscher vor, LoRA in Echtzeit zu berechnen, um xAB zu berechnen (wie in Gleichung 2 dargestellt).
In S-LoRA erfolgt die Berechnung des Basismodells stapelweise und anschließend wird zusätzliches xAB für alle Adapter einzeln mithilfe eines benutzerdefinierten CUDA-Kernels durchgeführt. Dieser Vorgang ist in Abbildung 1 dargestellt. Anstatt Padding und gestapelte GEMM-Kernel aus der BLAS-Bibliothek zur Berechnung von LoRA zu verwenden, haben wir einen benutzerdefinierten CUDA-Kernel implementiert, um eine effizientere Berechnung ohne Padding zu erreichen. Details zur Implementierung finden Sie in Unterabschnitt 5.3.
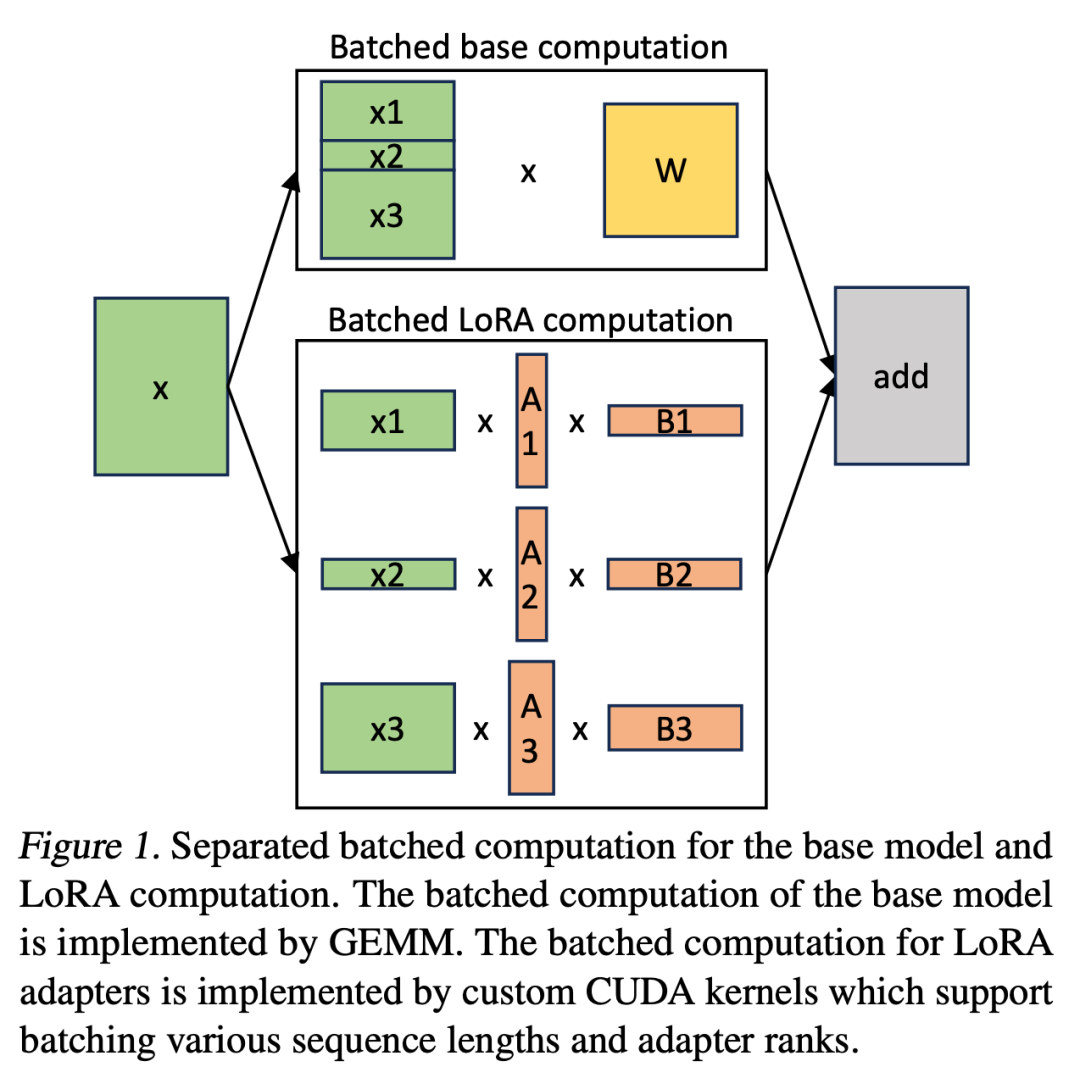
Die Anzahl der LoRA-Adapter könnte groß sein, wenn sie im Hauptspeicher gespeichert würden, aber derzeit ist die Anzahl der LoRA-Adapter, die zum Ausführen eines Stapels erforderlich sind, kontrollierbar, da die Stapelgröße durch den GPU-Speicher begrenzt ist. Um dies zu nutzen, speichern wir alle LoRA-Adapter im Hauptspeicher und holen beim Ableiten für den aktuell ausgeführten Stapel nur die für diesen Stapel erforderlichen LoRA-Adapter in den GPU-RAM. In diesem Fall ist die maximale Anzahl wartungsfähiger Adapter durch die Hauptspeichergröße begrenzt. Abbildung 2 veranschaulicht diesen Prozess. In Abschnitt 5 werden auch Techniken für eine effiziente Speicherverwaltung erörtert. Um mehrere Adapter zu unterstützen, speichert S-LoRA diese im Hauptspeicher und lädt die für den aktuell ausgeführten Stapel erforderlichen Adaptergewichte dynamisch in den GPU-RAM.
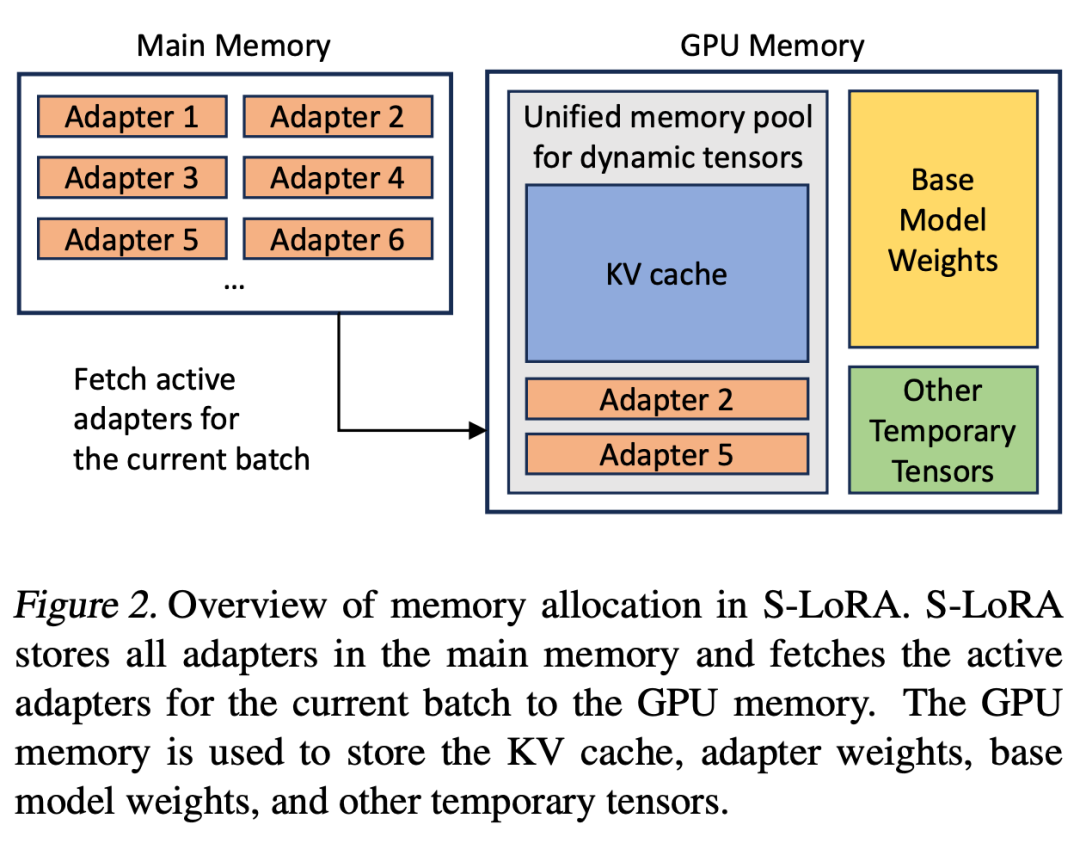 In diesem Prozess gibt es zwei offensichtliche Herausforderungen. Das erste ist das Problem der Speicherfragmentierung, das durch das dynamische Laden und Entladen von Adaptergewichten unterschiedlicher Größe verursacht wird. Der zweite Grund ist der Latenzaufwand, der durch das Laden und Entladen des Adapters verursacht wird. Um diese Probleme effektiv zu lösen, haben Forscher das Konzept des „einheitlichen Paging“ vorgeschlagen und die Überlappung von E/A und Berechnung durch Vorabrufen von Adaptergewichten implementiert von PagedAttention für Unified Paging. Unified Paging wird nicht nur zur Verwaltung des KV-Cache, sondern auch zur Verwaltung der Adaptergewichte verwendet. Unified Paging verwendet einen einheitlichen Speicherpool, um KV-Cache und Adaptergewichte gemeinsam zu verwalten. Um dies zu erreichen, weisen sie dem Speicherpool zunächst statisch einen großen Puffer zu, der den gesamten verfügbaren Speicherplatz nutzt, mit Ausnahme des Speicherplatzes, der zum Speichern der Gewichte des Basismodells und der temporären Aktivierungstensoren verwendet wird. Die KV-Cache- und Adaptergewichte werden seitenweise im Speicherpool gespeichert, und jede Seite entspricht einem H-Vektor. Daher belegt ein KV-Cache-Tensor mit der Sequenzlänge S S Seiten, während ein LoRA-Gewichtungstensor der R-Ebene R Seiten belegt. Abbildung 3 zeigt das Layout des Speicherpools, in dem der KV-Cache und die Adaptergewichte verschachtelt und nicht zusammenhängend gespeichert werden. Dieser Ansatz reduziert die Fragmentierung erheblich und stellt sicher, dass verschiedene Ebenen von Adaptergewichten auf strukturierte und systematische Weise mit dem dynamischen KV-Cache koexistieren können Die Tensor-Parallel-Strategie ist darauf ausgelegt, die Multi-GPU-Inferenz großer Transformer-Modelle zu unterstützen. Tensor-Parallelität ist der am weitesten verbreitete parallele Ansatz, da sein Einzelprogramm- und Mehrfachdaten-Paradigma seine Implementierung und Integration in bestehende Systeme vereinfacht. Tensorparallelität kann die Speichernutzung und Latenz pro GPU reduzieren, wenn große Modelle bedient werden. In dieser Umgebung führen zusätzliche LoRA-Adapter neue Gewichtsmatrizen und Matrixmultiplikationen ein, die neue Partitionierungsstrategien für diese Ergänzungen erfordern.
In diesem Prozess gibt es zwei offensichtliche Herausforderungen. Das erste ist das Problem der Speicherfragmentierung, das durch das dynamische Laden und Entladen von Adaptergewichten unterschiedlicher Größe verursacht wird. Der zweite Grund ist der Latenzaufwand, der durch das Laden und Entladen des Adapters verursacht wird. Um diese Probleme effektiv zu lösen, haben Forscher das Konzept des „einheitlichen Paging“ vorgeschlagen und die Überlappung von E/A und Berechnung durch Vorabrufen von Adaptergewichten implementiert von PagedAttention für Unified Paging. Unified Paging wird nicht nur zur Verwaltung des KV-Cache, sondern auch zur Verwaltung der Adaptergewichte verwendet. Unified Paging verwendet einen einheitlichen Speicherpool, um KV-Cache und Adaptergewichte gemeinsam zu verwalten. Um dies zu erreichen, weisen sie dem Speicherpool zunächst statisch einen großen Puffer zu, der den gesamten verfügbaren Speicherplatz nutzt, mit Ausnahme des Speicherplatzes, der zum Speichern der Gewichte des Basismodells und der temporären Aktivierungstensoren verwendet wird. Die KV-Cache- und Adaptergewichte werden seitenweise im Speicherpool gespeichert, und jede Seite entspricht einem H-Vektor. Daher belegt ein KV-Cache-Tensor mit der Sequenzlänge S S Seiten, während ein LoRA-Gewichtungstensor der R-Ebene R Seiten belegt. Abbildung 3 zeigt das Layout des Speicherpools, in dem der KV-Cache und die Adaptergewichte verschachtelt und nicht zusammenhängend gespeichert werden. Dieser Ansatz reduziert die Fragmentierung erheblich und stellt sicher, dass verschiedene Ebenen von Adaptergewichten auf strukturierte und systematische Weise mit dem dynamischen KV-Cache koexistieren können Die Tensor-Parallel-Strategie ist darauf ausgelegt, die Multi-GPU-Inferenz großer Transformer-Modelle zu unterstützen. Tensor-Parallelität ist der am weitesten verbreitete parallele Ansatz, da sein Einzelprogramm- und Mehrfachdaten-Paradigma seine Implementierung und Integration in bestehende Systeme vereinfacht. Tensorparallelität kann die Speichernutzung und Latenz pro GPU reduzieren, wenn große Modelle bedient werden. In dieser Umgebung führen zusätzliche LoRA-Adapter neue Gewichtsmatrizen und Matrixmultiplikationen ein, die neue Partitionierungsstrategien für diese Ergänzungen erfordern.
Bewertung
Abschließend bewerteten die Forscher S-LoRA, indem sie Llama-7B/13B/30B/70B bedienten. Die Ergebnisse zeigten, dass S-LoRA in einem eingesetzt werden kann Einfach Tausende von LoRA-Adaptern auf einer GPU oder mehreren GPUs mit geringem Overhead bereitstellen. S-LoRA erreicht einen bis zu 30-mal höheren Durchsatz im Vergleich zu Huggingface PEFT, einer hochmodernen Parameter-effizienten Feinabstimmungsbibliothek. S-LoRA erhöht den Durchsatz um das Vierfache und erhöht die Anzahl der Dienstadapter um mehrere Größenordnungen im Vergleich zur Verwendung eines Hochdurchsatz-Dienstsystems vLLM, das LoRA-Dienste unterstützt.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonS-LoRA: Es ist möglich, Tausende großer Modelle auf einer GPU auszuführen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



