


In letzter Zeit werden neue Artikel so schnell veröffentlicht, dass ich das Gefühl habe, sie nicht lesen zu können. Es ist ersichtlich, dass die Fusion multimodaler großer Modelle für Sprache und Vision zu einem Branchenkonsens geworden ist. Dieser Artikel auf UniPad ist repräsentativer und bietet multimodale Eingaben und ein vorab trainiertes Basismodell für weltähnliche Modelle. und gleichzeitig ist eine einfache Erweiterung auf mehrere herkömmliche Bildverarbeitungsanwendungen möglich. Es löst auch das Problem der Anwendung der Vortrainingsmethode großer Sprachmodelle auf 3D-Szenen und bietet so die Möglichkeit eines einheitlichen großen Modells der Wahrnehmungsbasis.
UniPAD ist eine selbstüberwachte Lernmethode, die auf MAE und 3D-Rendering basiert. Sie kann ein Basismodell mit hervorragender Leistung trainieren und anschließend nachgelagerte Aufgaben am Modell verfeinern und trainieren, wie z. B. Tiefenschätzung, Objekterkennung und Segmentierung. Diese Studie hat eine einheitliche 3D-Raumdarstellungsmethode entwickelt, die leicht in 2D- und 3D-Frameworks integriert werden kann, eine größere Flexibilität aufweist und mit der Positionierung des Basismodells übereinstimmt
Welche Beziehung besteht zwischen? maskierte Autoencoding-Technologie und 3D-differenzierbare Rendering-Technologie? Einfach ausgedrückt: Bei der maskierten automatischen Kodierung geht es darum, die selbstüberwachten Trainingsfunktionen von Autoencoder zu nutzen, und bei der „Rendering-Technologie“ geht es darum, die Verlustfunktion zwischen dem generierten Bild und dem Originalbild zu berechnen und ein überwachtes Training durchzuführen. Die Logik ist also immer noch sehr klar.
Dieser Artikel verwendet die Vortrainingsmethode des Basismodellsund optimiert dann die Downstream-Erkennungsmethode und die Segmentierungsmethode. Diese Methode kann auch dabei helfen, zu verstehen, wie das aktuelle große Modell mit nachgelagerten Aufgaben funktioniert.
Es scheint, dass die Timing-Informationen nicht kombiniert werden. Immerhin ist NuScenes NDS von Pure Vision 50.2 im Vergleich zu Timing-Erkennungsmethoden (StreamPETR, Sparse4D usw.) derzeit noch schwächer. Daher ist auch die 4D-MAE-Methode einen Versuch wert. Tatsächlich hat GAIA-1 bereits eine ähnliche Idee erwähnt. Wie sieht es mit der Berechnungsmenge und der Speichernutzung aus?
Spezifische Methode:Unsere experimentellen Ergebnisse beweisen voll und ganz die Überlegenheit von UniPAD. Im Vergleich zu herkömmlichen Lidar-, Kamera- und Lidar-Kamera-Fusionsbasislinien verbessert sich der NDS von UniPAD um 9,1, 7,7 bzw. 6,9. Bemerkenswert ist, dass unsere Pre-Training-Pipeline beim nuScenes-Validierungssatz einen NDS von 73,2 und gleichzeitig einen mIoU-Score von 79,4 bei der semantischen 3D-Segmentierungsaufgabe erreichte und damit die besten Ergebnisse im Vergleich zu früheren Methoden erzielte
Gesamtarchitektur:
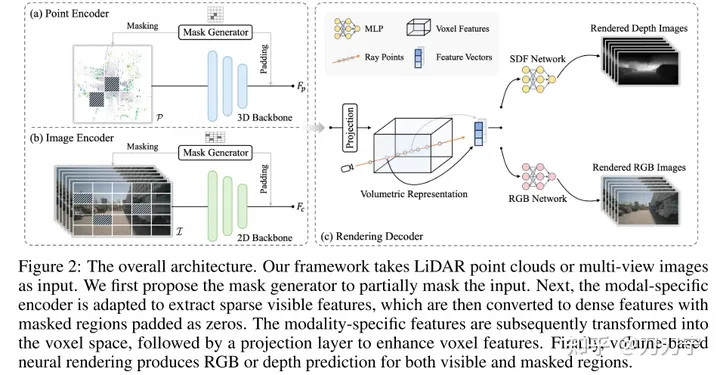 Gesamtarchitektur. Das Framework verwendet LiDar- und Multi-Shot-Bilder als Eingabe und diese multimodalen Daten werden über den Maskengenerator mit Nullen gefüllt. Die maskierte Einbettung wird in den Voxelraum umgewandelt und Rendering-Techniken werden verwendet, um RGB- oder Tiefenvorhersagen in diesem 3D-Raum zu generieren. Zu diesem Zeitpunkt kann das Originalbild, das nicht durch die Maske verdeckt wird, als generierte Daten für überwachtes Lernen verwendet werden.
Gesamtarchitektur. Das Framework verwendet LiDar- und Multi-Shot-Bilder als Eingabe und diese multimodalen Daten werden über den Maskengenerator mit Nullen gefüllt. Die maskierte Einbettung wird in den Voxelraum umgewandelt und Rendering-Techniken werden verwendet, um RGB- oder Tiefenvorhersagen in diesem 3D-Raum zu generieren. Zu diesem Zeitpunkt kann das Originalbild, das nicht durch die Maske verdeckt wird, als generierte Daten für überwachtes Lernen verwendet werden.
Wir stellen die Szene als SDF (implizites vorzeichenbehaftetes Distanzfunktionsfeld) dar, wenn die Eingabe die 3D-Koordinaten des Abtastpunkts P (die entsprechende Tiefe entlang des Strahls D) und F (die Merkmalseinbettung) sind, die aus der volumetrischen Darstellung extrahiert werden können trilineare Interpolation) kann SDF als MLP betrachtet werden, um den SDF-Wert des Abtastpunkts vorherzusagen. Hier kann F als der Kodierungscode verstanden werden, an dem sich Punkt P befindet. Dann wird die Ausgabe erhalten: N (Bedingung des Farbfelds auf der Oberflächennormalen) und H (Geometriemerkmalsvektor). Zu diesem Zeitpunkt kann das RGB des 3D-Abtastpunkts durch ein MLP mit P, D, F, N erhalten werden , H als Eingabewert und Tiefenwert und überlagern Sie dann die 3D-Abtastpunkte durch Strahlen mit dem 2D-Raum, um das Rendering-Ergebnis zu erhalten. Die Methode, Ray hier zu verwenden, ist im Grunde die gleiche wie bei Nerf.
Die Rendering-Methode muss auch den Speicherverbrauch optimieren, der hier nicht aufgeführt ist. Bei diesem Problem handelt es sich jedoch um ein kritischeres Implementierungsproblem. Der Kern der
Mask- und Rendering-Methoden besteht darin, ein vorab trainiertes Modell zu trainieren. Das vorab trainierte Modell kann auf der Grundlage der vorhergesagten Maske trainiert werden, auch ohne nachfolgende Verzweigungen. Die anschließende Arbeit des vorab trainierten Modells generiert RGB- und Tiefenvorhersagen über verschiedene Zweige und optimiert Aufgaben wie Zielerkennung/semantische Segmentierung, um Plug-and-Play-Funktionen zu erreichen:
 Experimentelle Ergebnisse:
Experimentelle Ergebnisse:
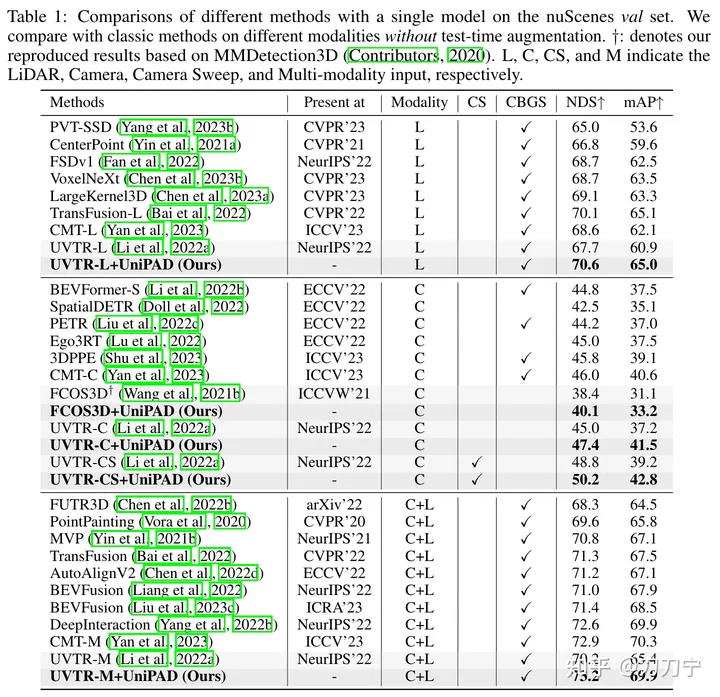
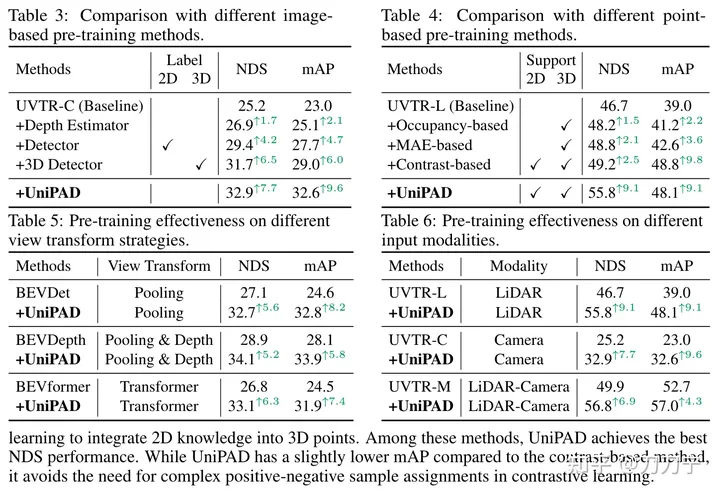 Vergleich mit anderen neueren Arbeiten:
Vergleich mit anderen neueren Arbeiten:
Zusammenfassung:
Originallink: https://mp.weixin.qq.com/s/e_reCS-Lwr-KVF80z56_ow
Das obige ist der detaillierte Inhalt vonUniPAD: Universeller Vortrainingsmodus für autonomes Fahren! Verschiedene Wahrnehmungsaufgaben können unterstützt werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in die Eigenschaften des virtuellen Raums
Einführung in die Eigenschaften des virtuellen Raums
 Verwendung des Python-Rückgabewerts
Verwendung des Python-Rückgabewerts
 So nutzen Sie digitale Währungen
So nutzen Sie digitale Währungen
 Was soll ich tun, wenn beim Einschalten des Computers englische Buchstaben angezeigt werden und der Computer nicht eingeschaltet werden kann?
Was soll ich tun, wenn beim Einschalten des Computers englische Buchstaben angezeigt werden und der Computer nicht eingeschaltet werden kann?
 Der Unterschied zwischen vue2.0 und 3.0
Der Unterschied zwischen vue2.0 und 3.0
 So wechseln Sie die Stadt auf Douyin
So wechseln Sie die Stadt auf Douyin
 keine solche Dateilösung
keine solche Dateilösung
 So konfigurieren Sie das Standard-Gateway
So konfigurieren Sie das Standard-Gateway








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



