


Um die ursprüngliche Bedeutung nicht zu ändern, muss Folgendes neu ausgedrückt werden: Zuerst müssen wir herausfinden, warum eine Kreuzvalidierung erforderlich ist.
Kreuzvalidierung ist eine Technik, die häufig im maschinellen Lernen und in der Statistik verwendet wird, um die Leistung und Generalisierungsfähigkeit eines Vorhersagemodells zu bewerten, insbesondere wenn die Daten begrenzt sind, oder um die Fähigkeit des Modells zur Generalisierung auf neue, unsichtbare Daten zu bewerten.

Unter welchen Umständen wird eine Kreuzvalidierung verwendet?
Die allgemeine Idee der Kreuzvalidierung kann in Abbildung 5-fach-Kreuz dargestellt werden. In jeder Iteration wird das neue Modell an vier Unterdatensätzen trainiert und am letzten beibehaltenen Unterdatensatz getestet, um sicherzustellen, dass alle Daten vorhanden sind werden genutzt. Durch Indikatoren wie durchschnittliche Punktzahl und Standardabweichung wird ein echtes Maß für die Modellleistung bereitgestellt
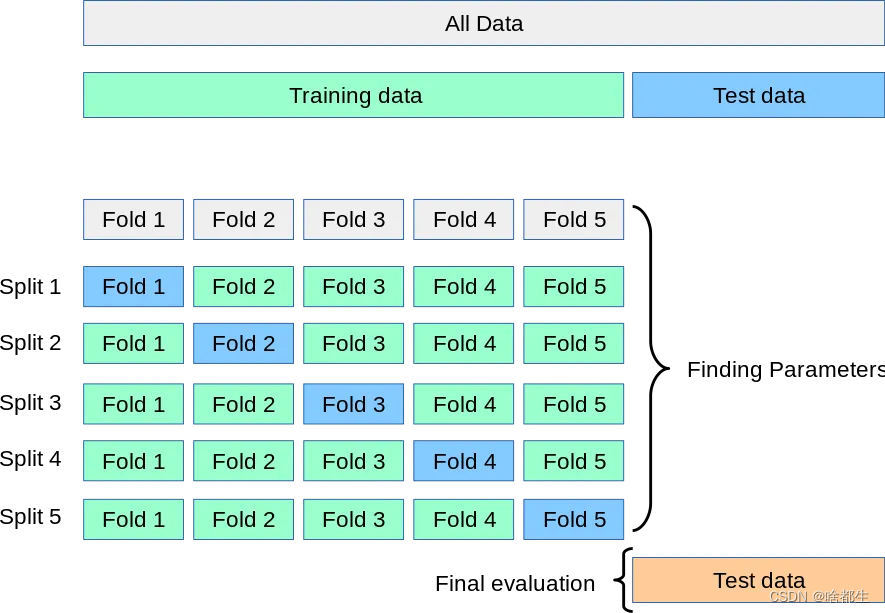
Alles muss mit dem K-Fold-Crossover beginnen.
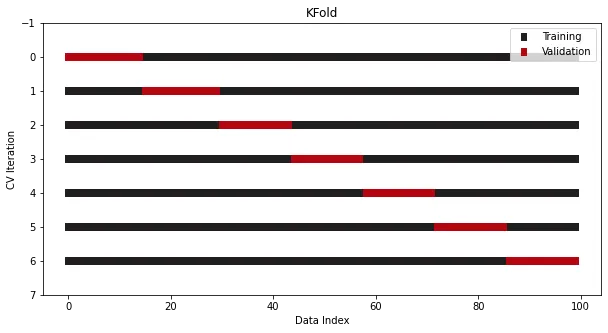
Die K-Fold-Kreuzvalidierung wurde in Sklearn integriert. Hier ist ein 7-faches Beispiel:
from sklearn.datasets import make_regressionfrom sklearn.model_selection import KFoldx, y = make_regression(n_samples=100)# Init the splittercross_validation = KFold(n_splits=7)
Eine weitere häufige Operation besteht darin, Shuffle vor der Aufteilung durchzuführen, wodurch die ursprüngliche Reihenfolge der Proben weiter zerstört wird Minimiert das Risiko einer Überanpassung:
cross_validation = KFold(n_splits=7, shuffle=True)
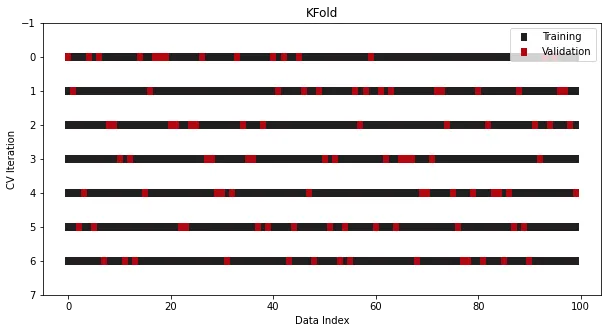
Auf diese Weise kann eine einfache k-fache Kreuzvalidierung durchgeführt werden. Bitte überprüfen Sie unbedingt den Quellcode! Schauen Sie sich unbedingt den Quellcode an! Schauen Sie sich unbedingt den Quellcode an!
StratifiedKFold wurde speziell für Klassifizierungsprobleme entwickelt.
Bei einigen Klassifizierungsproblemen sollte die Zielverteilung unverändert bleiben, selbst wenn die Daten in mehrere Sätze unterteilt sind. In den meisten Fällen sollte beispielsweise ein binäres Ziel mit einem Klassenverhältnis von 30 zu 70 im Trainingssatz und im Testsatz immer noch das gleiche Verhältnis beibehalten. In gewöhnlichem KFold wird diese Regel verletzt, da die Daten vor der Aufteilung gemischt werden Die Proportionen der Kategorien werden nicht beibehalten.
Um dieses Problem zu lösen, wird in Sklearn eine weitere Splitterklasse speziell für die Klassifizierung verwendet – StratifiedKFold:
from sklearn.datasets import make_classificationfrom sklearn.model_selection import StratifiedKFoldx, y = make_classification(n_samples=100, n_classes=2)cross_validation = StratifiedKFold(n_splits=7, shuffle=True, random_state=1121218)
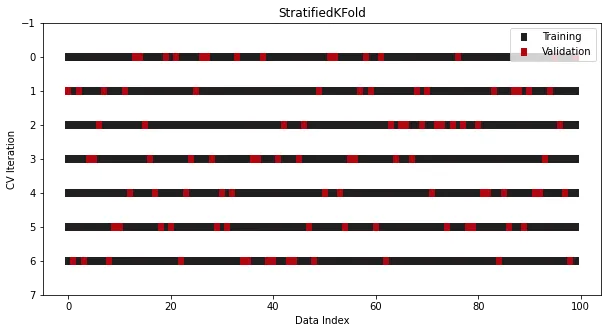
Obwohl sie KFold ähnelt, bleiben die Klassenproportionen jetzt in allen Teilungen und Iterationen konsistent
Manchmal Der Prozess der Aufteilung des Trainings-/Testsatzes wird einfach mehrmals wiederholt, ganz ähnlich wie bei der Kreuzvalidierung. Validierungsprozess in genügend Iterationen. Die entsprechende Schnittstelle wird auch in der Scikit-learn-Bibliothek bereitgestellt:
from sklearn.model_selection import ShuffleSplitcross_validation = ShuffleSplit(n_splits=7, train_size=0.75, test_size=0.25)
 Wenn es sich bei dem Datensatz um eine Zeitreihe handelt, kann die herkömmliche Kreuzvalidierung nicht verwendet werden, was zu einer vollständigen Störung führt Um dieses Problem zu lösen, finden Sie in Sklearn einen weiteren Splitter-TimeSeriesSplit. Dies liegt daran, dass es sich bei dem Index um ein Datum handelt, was bedeutet, dass wir nicht versehentlich ein Zeitreihenmodell auf ein zukünftiges Datum trainieren und eine Vorhersage für ein früheres Datum treffen können
Wenn es sich bei dem Datensatz um eine Zeitreihe handelt, kann die herkömmliche Kreuzvalidierung nicht verwendet werden, was zu einer vollständigen Störung führt Um dieses Problem zu lösen, finden Sie in Sklearn einen weiteren Splitter-TimeSeriesSplit. Dies liegt daran, dass es sich bei dem Index um ein Datum handelt, was bedeutet, dass wir nicht versehentlich ein Zeitreihenmodell auf ein zukünftiges Datum trainieren und eine Vorhersage für ein früheres Datum treffen können
Die obige Methode wird für unabhängige und identisch verteilte Datensätze verarbeitet, d. h. der Prozess der Datengenerierung wird durch andere Stichproben nicht beeinflusst
Allerdings In einigen Fällen erfüllen die Daten nicht die Bedingung der unabhängigen und identischen Verteilung (IID), d. h. zwischen einigen Stichproben besteht eine Abhängigkeitsbeziehung. Diese Situation tritt auch bei Kaggle-Wettbewerben auf, beispielsweise beim Google Brain Ventilator Pressure-Wettbewerb. Diese Daten erfassen die Luftdruckwerte der künstlichen Lunge während Tausender Atemzüge (Ein- und Ausatmen) und werden zu jedem Zeitpunkt jedes Atemzugs aufgezeichnet. Für jeden Atemvorgang gibt es etwa 80 Datenzeilen, die miteinander verknüpft sind. In diesem Fall können herkömmliche Kreuzvalidierungsmethoden nicht verwendet werden, da die Partitionierung der Daten „mitten im Atemprozess“ erfolgen kann
Dies kann als die Notwendigkeit verstanden werden, diese Daten aufgrund der internen Daten zu „gruppieren“. Gruppendaten Es hängt zusammen. Wenn beispielsweise medizinische Daten von mehreren Patienten erfasst werden, verfügt jeder Patient über mehrere Proben. Diese Daten werden jedoch wahrscheinlich durch individuelle Unterschiede zwischen Patienten beeinflusst und müssen daher auch gruppiert werden
Oft hoffen wir, dass sich ein auf eine bestimmte Gruppe trainiertes Modell gut auf andere unbekannte Gruppen übertragen lässt. Bei der Durchführung einer Kreuzvalidierung Geben Sie diesen Datengruppen „Tags“ und sagen Sie ihnen, wie sie sie unterscheiden können.
In Sklearn stehen mehrere Schnittstellen zur Verfügung, um diese Situationen zu bewältigen:
Es wird dringend empfohlen, die Idee von Cross- zu verstehen. Validierung und wie es geht Um es umzusetzen, schauen Sie sich den Sklearn-Quellcode an: Keine schlechte Möglichkeit, Ihren Darm zu mästen. Darüber hinaus benötigen Sie eine klare Definition Ihres eigenen Datensatzes, und die Datenvorverarbeitung ist wirklich wichtig.
Das obige ist der detaillierte Inhalt vonDie Bedeutung der Kreuzvalidierung kann nicht ignoriert werden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Der Unterschied zwischen Scilab und Matlab
Der Unterschied zwischen Scilab und Matlab
 Methode zur Erstellung von Intouch-Berichten
Methode zur Erstellung von Intouch-Berichten
 Die zehn besten Börsen für digitale Währungen
Die zehn besten Börsen für digitale Währungen
 Einführung in die Repeater-Verschachtelungsmethode
Einführung in die Repeater-Verschachtelungsmethode
 Der Win10-Bluetooth-Schalter fehlt
Der Win10-Bluetooth-Schalter fehlt
 Konfigurieren Sie Java-Umgebungsvariablen
Konfigurieren Sie Java-Umgebungsvariablen
 Tutorial zur Pycharm-Installation
Tutorial zur Pycharm-Installation
 Passende Zeichenfolge für einen regulären Java-Ausdruck
Passende Zeichenfolge für einen regulären Java-Ausdruck








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



