


Kürzlich wurde das Video „Taylor Swift Showing off Chinese“ schnell in den großen sozialen Medien populär, und später erschienen ähnliche Videos wie „Guo Degang Showing off English“. Viele dieser Videos werden von einer künstlichen Intelligenzanwendung namens „HeyGen“ produziert.
Allerdings kann es angesichts der aktuellen Beliebtheit von HeyGen lange dauern, damit ähnliche Videos zu erstellen. Glücklicherweise ist dies nicht die einzige Möglichkeit, es zu schaffen. Freunde, die sich mit Technologie auskennen, können auch nach anderen Alternativen suchen, wie zum Beispiel dem Speech-to-Text-Modell Whisper, der Textübersetzung GPT, dem Klonen von Stimmen + Audiogenerierung so-vits-svc und der Generierung von Mundformvideos, die dem Audio von GeneFace++dengdeng entsprechen.
Der neu geschriebene Inhalt ist: Unter anderem ist Whisper ein von OpenAI entwickeltes und Open-Source-Modell der automatischen Spracherkennung (ASR), das sehr einfach zu verwenden ist. Sie schulten Whisper anhand von 680.000 Stunden mehrsprachiger (98 Sprachen) und multitask-überwachter Daten, die aus dem Internet gesammelt wurden. OpenAI glaubt, dass die Verwendung eines so großen und vielfältigen Datensatzes die Fähigkeit des Modells verbessern kann, Akzente, Hintergrundgeräusche und Fachbegriffe zu erkennen. Zusätzlich zur Spracherkennung kann Whisper auch mehrere Sprachen transkribieren und diese Sprachen ins Englische übersetzen. Derzeit gibt es viele Varianten von Whisper und ist zu einer notwendigen Komponente beim Erstellen vieler KI-Anwendungen geworden
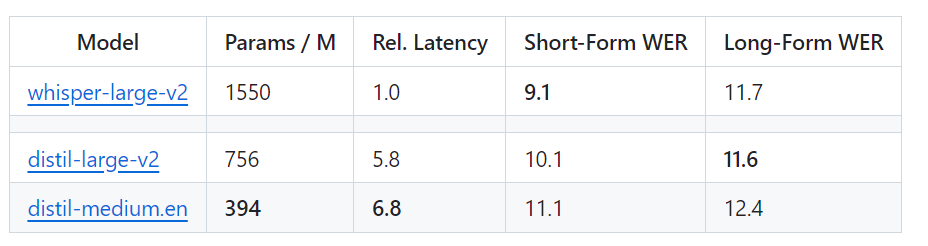
Kürzlich hat das HuggingFace-Team eine neue Variante vorgeschlagen – Distil-Whisper. Bei dieser Variante handelt es sich um eine destillierte Version des Whisper-Modells, das sich durch seine geringe Größe, hohe Geschwindigkeit und sehr hohe Genauigkeit auszeichnet und sich daher ideal für den Einsatz in Umgebungen eignet, die eine geringe Latenz erfordern oder über begrenzte Ressourcen verfügen. Im Gegensatz zum ursprünglichen Whisper-Modell, das mehrere Sprachen verarbeiten kann, kann Distil-Whisper jedoch nur Englisch verarbeiten. Link zum Papier: https://arxiv.org/pdf/2311.00430.pdf Mit anderen Worten, Distil-Whisper verfügt über zwei Versionen mit einer Parametergröße von 756 MB (distil-large-v2) und 394 MB (distil-medium.en). Im Vergleich zu OpenAIs Whisper-large-v2 ist die 756M-Version die Anzahl der Parameter von distil -large-v2 ist um mehr als die Hälfte reduziert, erreicht jedoch eine sechsfache Beschleunigung und die Genauigkeit liegt sehr nahe an Whisper-large-v2. Der Unterschied in der Wortfehlerrate (WER) von kurzen Audiodaten beträgt sogar 1 % besser als Whisper-large-v2 bei langen Audiodaten. Denn durch sorgfältige Datenauswahl und -filterung bleibt die Robustheit von Whisper erhalten und Illusionen werden reduziert.

Whispers Webversion verfügt über einen intuitiven Geschwindigkeitsvergleich mit Distil-Whisper. Bildquelle: https://twitter.com/xenovacom/status/1720460890560975103
Obwohl Distil-Whisper erst seit zwei oder drei Tagen auf dem Markt ist, hat es bereits die tausend Sterne überschritten.

Projektadresse: https://github.com/huggingface/distil-whisper#1-usage
Modelladresse: https://huggingface.co/models ?other=arxiv:2311.00430
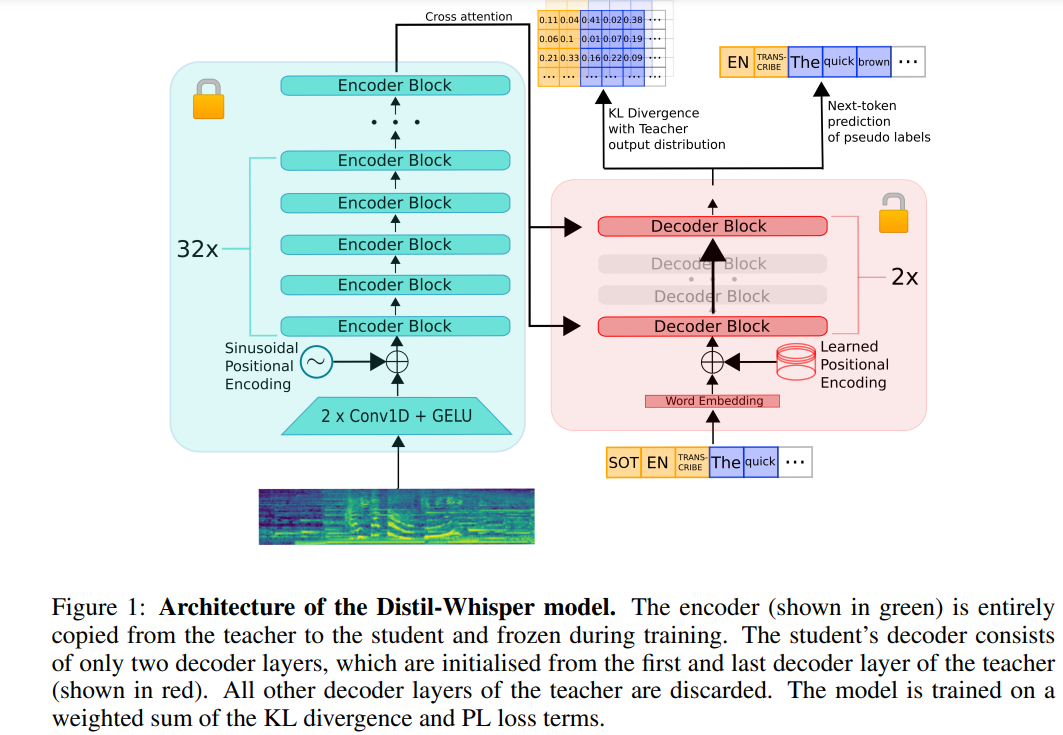
Das Folgende ist eine Neufassung des ursprünglichen Inhalts: Die Architektur von Distil-Whisper ist in Abbildung 1 unten dargestellt. Die Forscher initialisierten das Schülermodell, indem sie den gesamten Encoder vom Lehrermodell kopierten und ihn während des Trainings einfroren. Sie kopierten die erste und die letzte Decoderschicht aus den OpenAI-Modellen Whisper-medium.en und Whisper-large-v2 und erhielten nach der Destillation zwei Decoder-Kontrollpunkte mit den Namen distil-medium.en und Die dimensionalen Details des Modells, die durch Destillation von Distill- erhalten wurden. large-v2
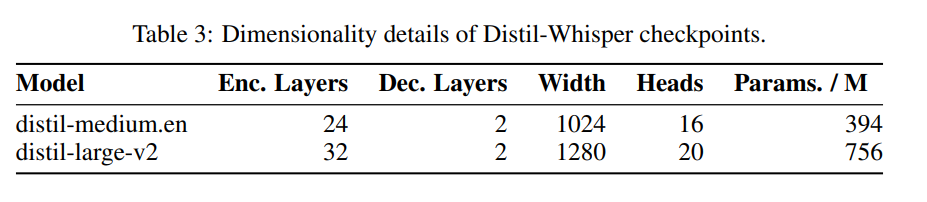
sind in Tabelle 3 aufgeführt.
In Bezug auf die Daten wurde das Modell 22.000 Stunden lang auf 9 verschiedenen Open-Source-Datensätzen trainiert (siehe Tabelle 2). Pseudo-Tags werden von Whisper generiert. Es ist erwähnenswert, dass sie einen WER-Filter verwendeten und nur Tags mit einem WER-Score von mehr als 10 % beibehalten wurden. Der Autor sagt, dass dies der Schlüssel zur Aufrechterhaltung der Leistung ist!
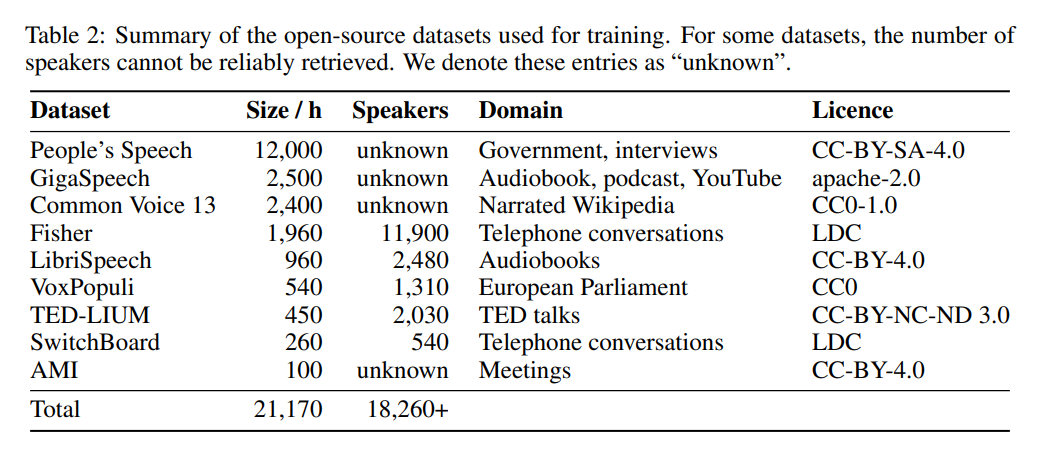
Tabelle 5 unten zeigt die wichtigsten Leistungsergebnisse von Distil-Whisper.
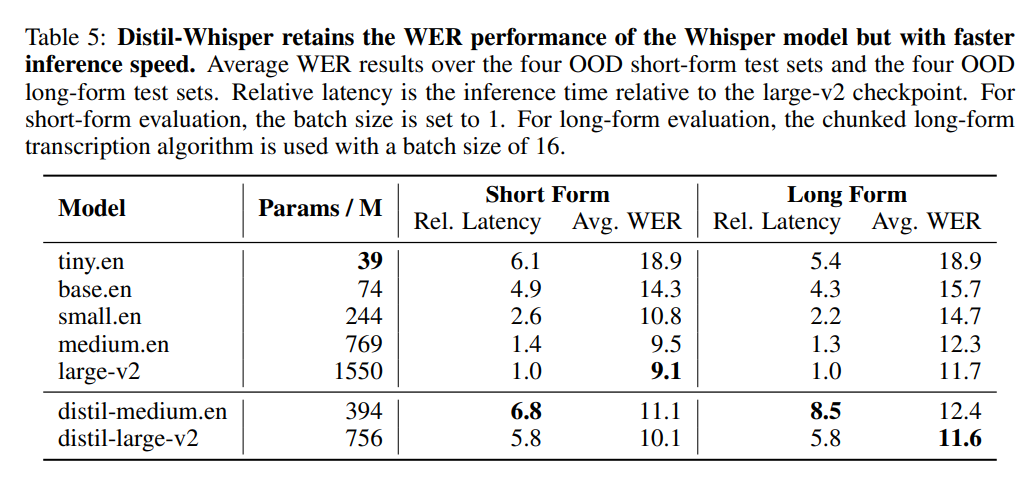
Dem Autor zufolge verhält sich Distil-Whisper durch das Einfrieren des Encoderbetriebs sehr robust gegenüber Rauschen. Wie in der Abbildung unten gezeigt, folgt Distil-Whisper unter lauten Bedingungen einer ähnlichen Robustheitskurve wie Whisper und bietet eine bessere Leistung als andere Modelle wie Wav2vec2 Halluzinationen. Laut dem Autor ist dies hauptsächlich auf die WER-Filterung zurückzuführen. Durch die gemeinsame Nutzung desselben Encoders kann Distil-Whisper zur spekulativen Decodierung mit Whisper gepaart werden. Dies führt zu einer 2-fachen Geschwindigkeitssteigerung mit nur 8 % höheren Parametern und erzeugt gleichzeitig genau die gleiche Ausgabe wie Whisper.
 Weitere Informationen finden Sie im Originalartikel.
Weitere Informationen finden Sie im Originalartikel.
Das obige ist der detaillierte Inhalt vonNach der Whisper-Destillation von OpenAI wurde die Geschwindigkeit der Spracherkennung erheblich verbessert: Die Anzahl der Sterne überstieg in zwei Tagen 1.000. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Antivirensoftware gibt es?
Welche Antivirensoftware gibt es?
 Inländische Plattform für digitale Währungen
Inländische Plattform für digitale Währungen
 So konfigurieren Sie Tomcat-Umgebungsvariablen
So konfigurieren Sie Tomcat-Umgebungsvariablen
 Was bedeutet c#?
Was bedeutet c#?
 So stellen Sie dauerhaft gelöschte Dateien auf dem Computer wieder her
So stellen Sie dauerhaft gelöschte Dateien auf dem Computer wieder her
 So öffnen Sie HTML-Dateien auf einem Mobiltelefon
So öffnen Sie HTML-Dateien auf einem Mobiltelefon
 Methode zur Wiederherstellung der Oracle-Datenbank
Methode zur Wiederherstellung der Oracle-Datenbank
 So lösen Sie Probleme beim Parsen von Paketen
So lösen Sie Probleme beim Parsen von Paketen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



