


Im Bereich des autonomen Fahrens mit der Entwicklung von BEV-basierten Teilaufgaben/End-to-End-Lösungen, hochwertigen Multi-View-Trainingsdaten und entsprechender Simulation Szenenaufbau werden immer wichtiger. Als Reaktion auf die Schmerzpunkte aktueller Aufgaben lässt sich „hohe Qualität“ in drei Aspekte entkoppeln:
Für die Simulation kann die Videogenerierung, die die oben genannten Bedingungen erfüllt, direkt über das Layout generiert werden. Dies ist zweifellos der direkteste Weg, um Multi-Agent-Sensoreingaben zu erstellen. DrivingDiffusion löst die oben genannten Probleme aus einer neuen Perspektive.
(1) DrivingDiffusion
Im Bild gezeigt Der Effekt der Mehransichtsbildgenerierung unter Verwendung der Layoutprojektion als Eingabe wird erzielt. 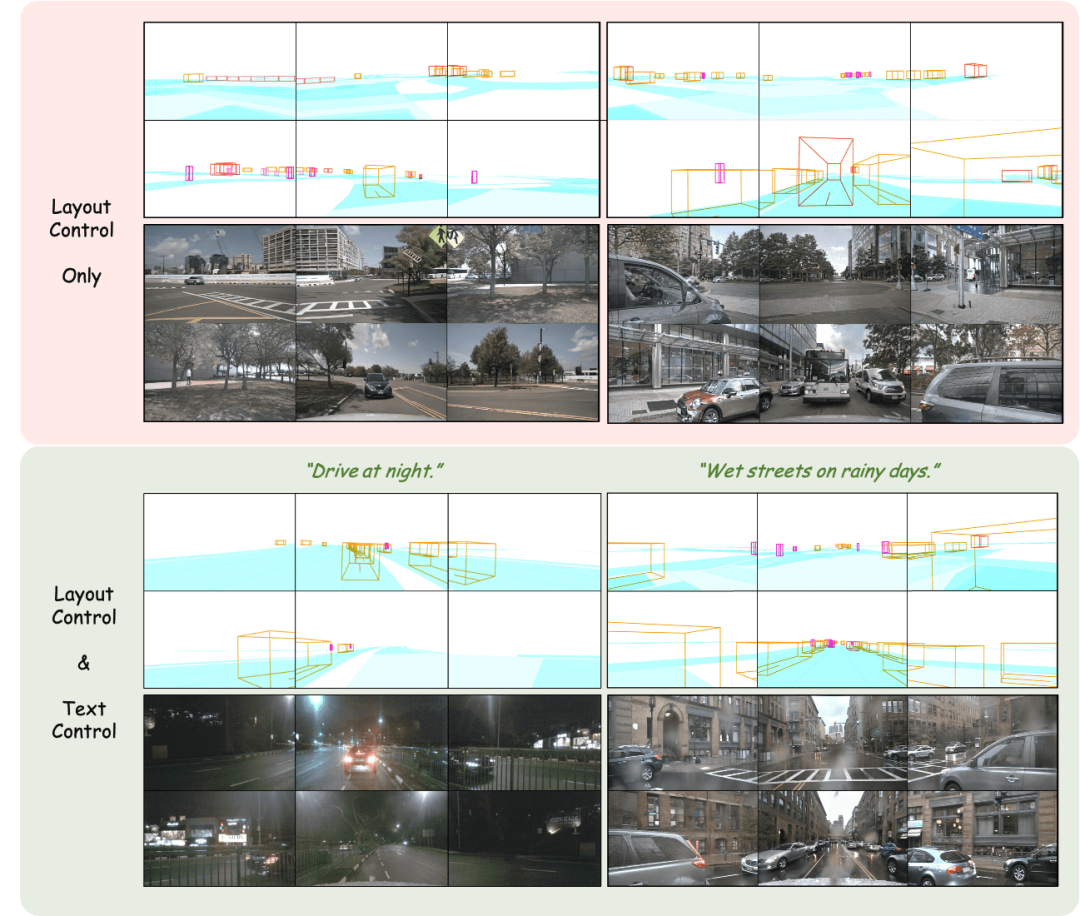
Layout anpassen: Präzise Steuerung der generierten Ergebnisse
Der obere Teil der Abbildung zeigt die Vielfalt der generierten Ergebnisse und die Bedeutung des Moduldesigns unten. Der untere Teil zeigt die Folgen der Störung des Fahrzeugs direkt dahinter, einschließlich der Erzeugungseffekte durch Bewegen, Drehen, Zusammenstoßen und sogar Schweben in der Luft. 
Layoutgesteuerte Multi-View-Videogenerierung
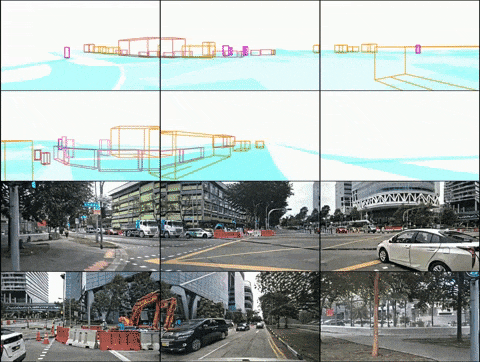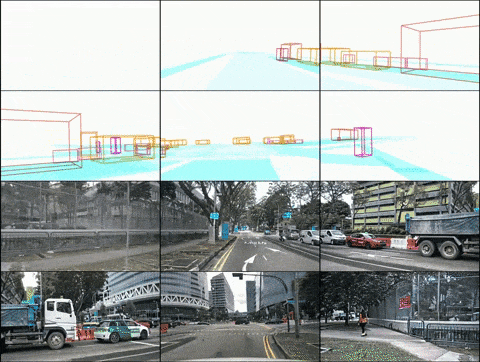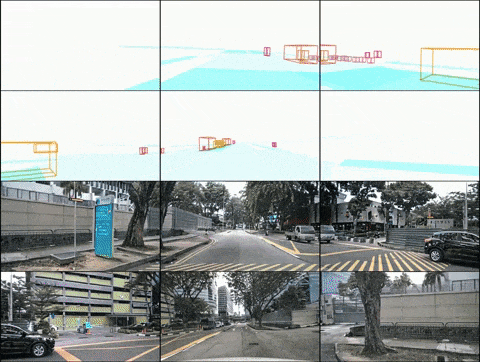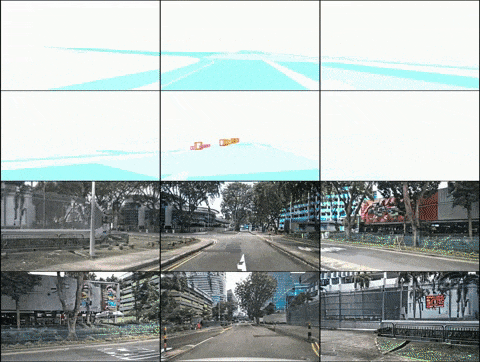

Oben: Ergebnisse der Videogenerierung von DrivingDiffusion nach dem Training mit nuScenes-Daten. Unten: Ergebnisse der Videogenerierung von DrivingDiffusion nach dem Training mit einer großen Menge privater realer Daten. 2) DrivingDiffusion-Future das Hauptauto/andere Autos. Die ersten drei Zeilen und die vierte Zeile in der Abbildung zeigen jeweils den Generierungseffekt nach der Textbeschreibungssteuerung des Verhaltens des Hauptfahrzeugs und anderer Fahrzeuge. (Das grüne Feld ist die Eingabe, das blaue Feld ist die Ausgabe)
Erzeugt direkt nachfolgende Frames basierend auf dem Eingabeframe
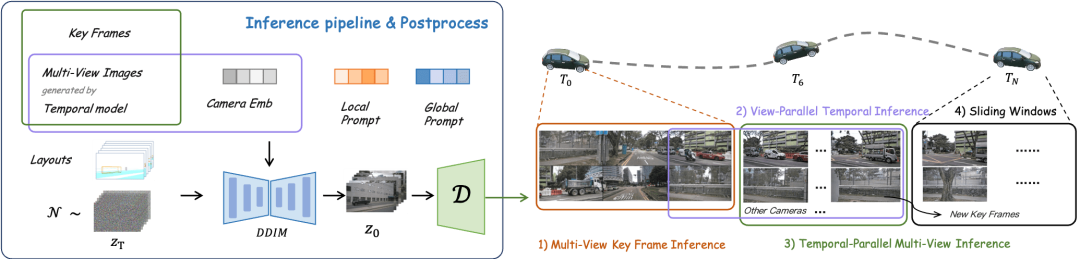
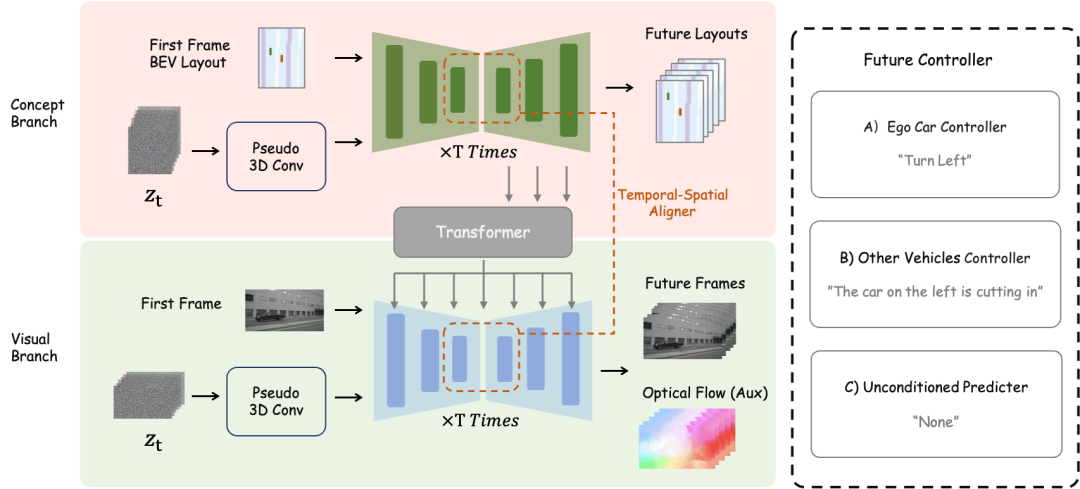
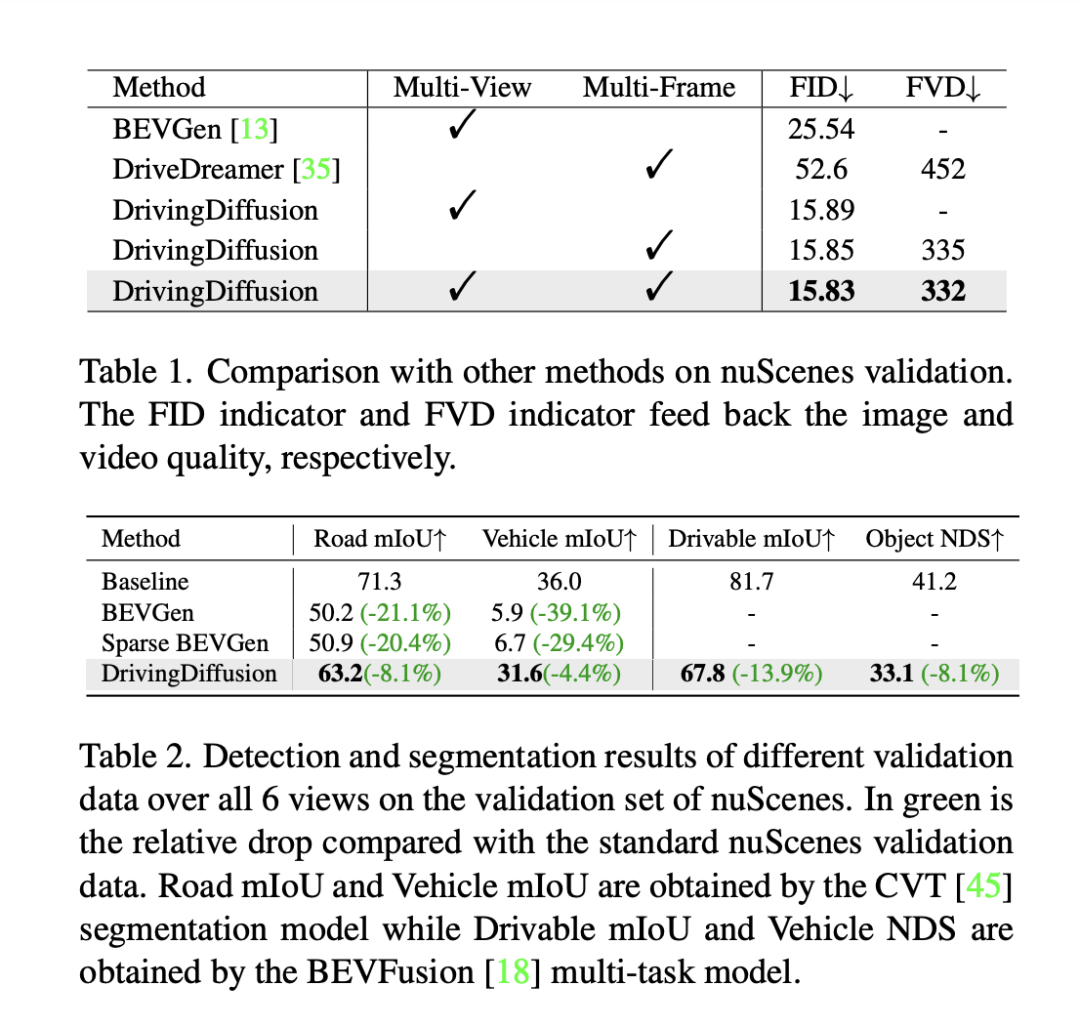
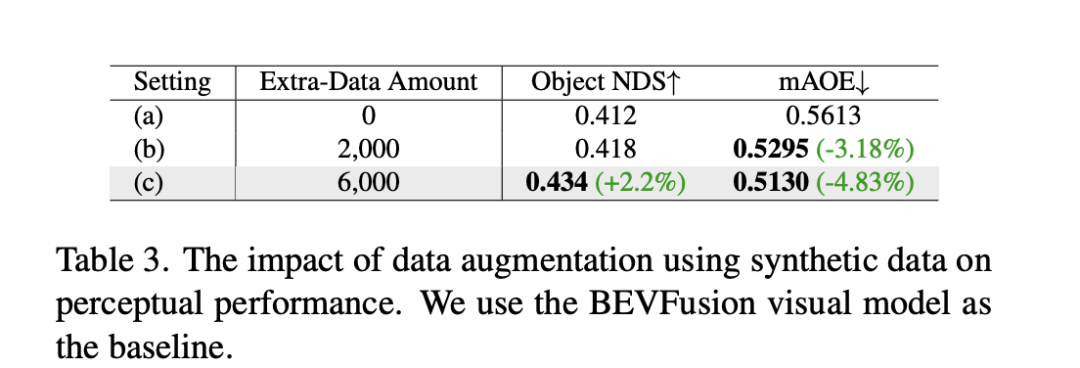
Es ist keine weitere Steuerung erforderlich, nur ein einzelnes Frame-Bild wird als Eingabe für die Vorhersage verwendet die Fahrszene der nachfolgenden Frames. (Grünes Feld ist Eingabe, blaues Feld ist Ausgabe) DrivingDiffusion konstruiert zunächst künstlich alle wahren 3D-Werte (Hindernisse/Straßenstrukturen) in der Szene. Nach der Projektion der wahren Werte in Layoutbilder wird es als Modelleingabe verwendet, um echte Bilder/Videos von mehreren Kameras zu erhalten Perspektiven. Der Grund, warum 3D-True-Werte (BEV-Ansichten oder codierte Instanzen) nicht direkt als Modelleingabe verwendet werden, sondern Parameter für die Post-Projektion-Eingabe verwendet werden, besteht darin, systematische 3D-2D-Konsistenzfehler zu beseitigen. (In einem solchen Datensatz werden 3D-Echtwerte und Fahrzeugparameter entsprechend den tatsächlichen Anforderungen künstlich konstruiert. Ersteres bietet die Möglichkeit, seltene Szenendaten nach Belieben zu erstellen , und letzteres eliminiert herkömmliche Datenproduktionsfehler geometrische Konsistenz) sequentielle Multi-View-Ansichten basierend auf künstlich konstruierten Szenen und Fahrzeugparametern, die nicht nur als Trainingsdaten für nachgelagerte autonome Fahraufgaben verwendet werden können, sondern auch ein Simulationssystem für Feedback zum autonomen Fahren aufbauen können Fahralgorithmen. Bei der Generierung von Multi-View-Videos gibt es mehrere Schwierigkeiten: DrivingDiffusion erzeugt einen langen Videoprozess verwendet Keyframes als zusätzliche Steuerung, Multi-View-Shared-Single-View-Timing-Modell: führt Timing aus jede Ansicht parallel Erweiterung, Das Konsistenzmodul ist in zwei Teile unterteilt: Konsistenz-Aufmerksamkeitsmechanismus und Konsistenzassoziationsverlust. Der Konsistenz-Aufmerksamkeitsmechanismus konzentriert sich auf die Interaktion zwischen benachbarten Ansichten und zeitlich verbundenen Frames. Für die Cross-Frame-Konsistenz konzentriert er sich insbesondere auf die Informationsinteraktion zwischen linken und rechten benachbarten Ansichten mit Überlappung Der Fokus liegt auf dem Schlüsselbild und dem vorherigen Bild. Dadurch wird der enorme Rechenaufwand vermieden, der durch globale Interaktionen verursacht wird. Der konsistente Korrelationsverlust fügt geometrische Einschränkungen durch pixelweise Korrelation und Regression der Pose hinzu, deren Gradient von einem vorab trainierten Pose-Regressor bereitgestellt wird. Der Regressor fügt einen auf LoFTR basierenden Posenregressionskopf hinzu und trainiert ihn unter Verwendung der wahren Posenwerte auf den realen Daten des entsprechenden Datensatzes. Bei Multi-View-Modellen und Zeitreihenmodellen überwacht dieses Modul die relative Kameraposition bzw. die Hauptbewegungsposition des Fahrzeugs. Local Prompt und Global Prompt arbeiten zusammen, um die Parametersemantik von CLIP und Stable-Diffusion-v1-4 wiederzuverwenden, um bestimmte Kategorieinstanzbereiche lokal zu verbessern. Wie in der Abbildung gezeigt, entwirft der Autor basierend auf dem Kreuzaufmerksamkeitsmechanismus von Bild-Token und globalen Textbeschreibungsaufforderungen eine lokale Eingabeaufforderung für eine bestimmte Kategorie und verwendet das Bild-Token im Maskenbereich der Kategorie, um die lokale Abfrage abzufragen prompt. Dieser Prozess nutzt das Konzept der textgesteuerten Bildgenerierung im offenen Bereich in den ursprünglichen Modellparametern maximal aus. Für zukünftige Szenenkonstruktionsaufgaben verwendet DrivingDiffusion-Future zwei Methoden: Eine besteht darin, nachfolgende Rahmenbilder (visueller Zweig) direkt aus dem ersten Rahmenbild vorherzusagen, und die Verwendung inter- Rahmen optischer Fluss als Hilfsverlust. Diese Methode ist relativ einfach, aber der Effekt der Generierung nachfolgender Frames basierend auf Textbeschreibungen ist durchschnittlich. Eine andere Möglichkeit besteht darin, einen neuen Konzeptzweig hinzuzufügen, der auf dem ersteren basiert und die BEV-Ansicht nachfolgender Frames anhand der BEV-Ansicht des ersten Frames vorhersagt. Dies liegt daran, dass die Vorhersage der BEV-Ansicht dem Modell hilft, die Kerninformationen des Fahrens zu erfassen in Szene setzen und Konzepte etablieren. Zu diesem Zeitpunkt wirkt die Textbeschreibung gleichzeitig auf beide Zweige, und die Merkmale des Konzeptzweigs werden über das Perspektivenkonvertierungsmodul von BEV2PV auf den visuellen Zweig angewendet. Einige Parameter des Perspektivenkonvertierungsmoduls werden mithilfe von vorab trainiert Echtwertbilder, um die Rauscheingabe zu ersetzen (und im Freeze während des nachfolgenden Trainings). Es ist erwähnenswert, dass der Hauptfahrzeugsteuerungs-Textbeschreibungscontroller und der Andere Fahrzeugsteuerungs-/Umgebungstextbeschreibungscontroller entkoppelt sind. Um die Leistung des Modells zu bewerten, verwendet DrivingDiffusion die Fréchet Inception Distance (FID) auf Frame-Ebene, um die Qualität der generierten Bilder zu bewerten, und verwendet dementsprechend FVD, um die Qualität der generierten Videos zu bewerten. Alle Metriken werden anhand des nuScenes-Validierungssatzes berechnet. Wie in Tabelle 1 gezeigt, bietet DrivingDiffusion im Vergleich zur Bildgenerierungsaufgabe BEVGen und der Videogenerierungsaufgabe DriveDreamer in autonomen Fahrszenarien größere Vorteile bei den Leistungsindikatoren unter verschiedenen Einstellungen. Obwohl Methoden wie FID häufig zur Messung der Qualität der Bildsynthese verwendet werden, geben sie weder die Designziele der Aufgabe vollständig wieder, noch spiegeln sie die Qualität der Synthese für verschiedene semantische Kategorien wider. Da es sich bei der Aufgabe um die Generierung von Multi-View-Bildern im Einklang mit dem 3D-Layout handelt, schlägt DrivingDiffuison vor, die Metrik des BEV-Wahrnehmungsmodells zu verwenden, um die Leistung im Hinblick auf die Konsistenz zu messen: Verwendung der offiziellen Modelle von CVT und BEVFusion als Evaluatoren unter Verwendung desselben realen 3D Modell als nuScenes-Validierungssatz. Generieren Sie Bilder abhängig vom Layout, führen Sie CVT- und BevFusion-Inferenz für jeden Satz generierter Bilder durch und vergleichen Sie dann die vorhergesagten Ergebnisse mit den tatsächlichen Ergebnissen, einschließlich der durchschnittlichen Schnittmenge über U (mIoU) des befahrbaren Bereichs und die NDS aller Objektklassen. Die Statistiken sind in Tabelle 2 dargestellt. Experimentelle Ergebnisse zeigen, dass die Wahrnehmungsindikatoren des Bewertungssatzes für synthetische Daten denen des realen Bewertungssatzes sehr nahe kommen, was die hohe Konsistenz der generierten Ergebnisse und wahren 3D-Werte sowie die hohe Wiedergabetreue der Bildqualität widerspiegelt. Zusätzlich zu den oben genannten Experimenten führte DrivingDiffusion Experimente zum Hinzufügen von Training mit synthetischen Daten durch, um das Hauptproblem anzugehen, das dadurch gelöst wurde – die Verbesserung der Leistung nachgelagerter Aufgaben des autonomen Fahrens. Tabelle 3 zeigt die Leistungsverbesserungen, die durch die Erweiterung synthetischer Daten bei BEV-Wahrnehmungsaufgaben erzielt werden. In den ursprünglichen Trainingsdaten gibt es Probleme mit Long-Tail-Verteilungen, insbesondere bei kleinen Zielen, Fahrzeugen im Nahbereich und Fahrzeugausrichtungswinkeln. DrivingDiffusion konzentriert sich auf die Generierung zusätzlicher Daten für diese Klassen mit begrenzten Stichproben, um dieses Problem zu lösen. Nach dem Hinzufügen von 2000 Datenrahmen, die sich auf die Verbesserung der Verteilung der Hindernisausrichtungswinkel konzentrierten, verbesserte sich der NDS leicht, während der mAOE deutlich von 0,5613 auf 0,5295 sank. Nach der Verwendung von 6.000 Frames synthetischer Daten, die umfassender sind und sich auf seltene Szenen konzentrieren, um das Training zu unterstützen, ist beim nuScenes-Validierungssatz eine deutliche Verbesserung zu beobachten: NDS stieg von 0,412 auf 0,434 und mAOE sank von 0,5613 auf 0,5130. Dies zeigt die signifikante Verbesserung, die die Datenerweiterung synthetischer Daten für Wahrnehmungsaufgaben bringen kann. Benutzer können anhand des tatsächlichen Bedarfs Statistiken über die Verteilung jeder Dimension in den Daten erstellen und diese dann durch gezielte synthetische Daten ergänzen. DrivingDiffusion realisiert gleichzeitig die Fähigkeit, Multi-View-Videos von autonomen Fahrszenen zu erstellen und die Zukunft vorherzusagen, was für autonome Fahraufgaben von großer Bedeutung ist. Darunter sind Layout und Parameter alle künstlich konstruiert und die Konvertierung zwischen 3D und 2D erfolgt durch Projektion, anstatt sich auf erlernbare Modellparameter zu verlassen. Dies eliminiert geometrische Fehler im vorherigen Prozess der Datenbeschaffung und hat einen hohen praktischen Wert. Gleichzeitig ist DrivingDiffuison äußerst skalierbar und unterstützt neue Szeneninhaltslayouts und zusätzliche Controller. Außerdem kann die Generierungsqualität durch Superauflösung und Video-Frame-Einfügungstechnologie verlustfrei verbessert werden. In der autonomen Fahrsimulation gibt es immer mehr Nerf-Versuche. Allerdings bringt die Aufgabe der Street View-Generierung, die Trennung von dynamischem und statischem Inhalt, die großflächige Blockrekonstruktion, die Entkoppelung des Erscheinungsbilds, die Kontrolle von Wetter und anderen Dimensionen usw. mit sich. Darüber hinaus erfordert Nerf oft einen enormen Arbeitsaufwand Erst nach dem Training kann es in nachfolgenden Simulationen neue Perspektivensyntheseaufgaben unterstützen. DrivingDiffusion enthält natürlich ein gewisses Maß an allgemeinem Wissen, einschließlich visueller Textverbindungen, konzeptionellem Verständnis visueller Inhalte usw. Es kann schnell eine Szene entsprechend den Anforderungen erstellen, indem einfach das Layout erstellt wird. Wie oben erwähnt, ist der gesamte Prozess jedoch relativ komplex und die Erstellung langer Videos erfordert eine Feinabstimmung und Erweiterung des Nachbearbeitungsmodells. DrivingDiffusion wird weiterhin die Komprimierung von Perspektiven- und Zeitdimensionen erforschen, Nerf für die Generierung und Konvertierung neuer Perspektiven kombinieren und die Generierungsqualität und Skalierbarkeit weiter verbessern. Wie löst DrivingDiffusion die oben genannten Probleme?
Überblick über die DrivingDiffusion-Methode
Im Vergleich zur herkömmlichen Bildgenerierung fügt die Multi-View-Videogenerierung zwei neue Dimensionen hinzu:
Single-Frame-Multi-View-Modell: generiert Multi-View-Keyframes,
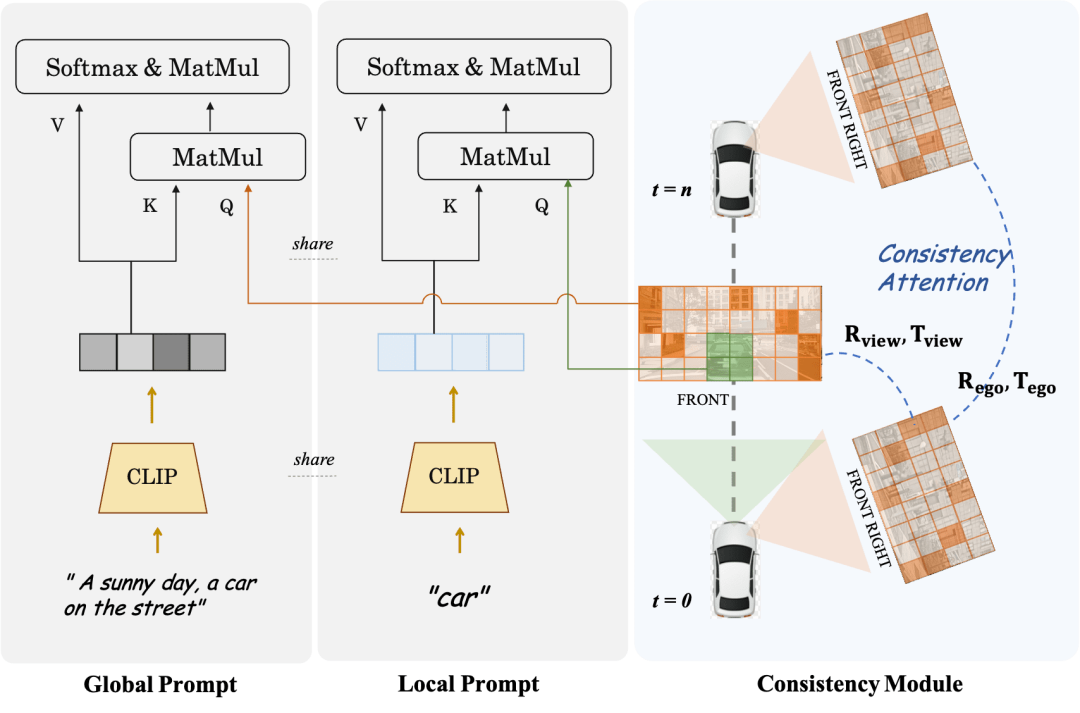
Konsistenzmodul und lokale Eingabeaufforderung
Übersicht über die DrivingDiffusion-Future-Methode
Experimentelle Analyse
Die Bedeutung und zukünftige Arbeit von DrivingDiffusion
Das obige ist der detaillierte Inhalt vonDas erste Weltmodell zur Erzeugung autonomer Fahrszenen mit mehreren Ansichten | DrivingDiffusion: Neue Ideen für BEV-Daten und Simulation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 ppt zu Wort
ppt zu Wort
 Was sind die Unterschiede zwischen C++ und der C-Sprache?
Was sind die Unterschiede zwischen C++ und der C-Sprache?
 Was ist eine Mac-Adresse?
Was ist eine Mac-Adresse?
 Lösung dafür, dass Java-Code nicht ausgeführt wird
Lösung dafür, dass Java-Code nicht ausgeführt wird
 So stellen Sie eine Verbindung zum Zugriff auf die Datenbank in VB her
So stellen Sie eine Verbindung zum Zugriff auf die Datenbank in VB her
 So überprüfen Sie tote Links auf Websites
So überprüfen Sie tote Links auf Websites
 MySQL ändert das Root-Passwort
MySQL ändert das Root-Passwort








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



