



Produziert von Big Data Digest
Familie: Nachdem künstliche Intelligenz (KI) Schach, Go und Dota erobert hatte, wurde die Fähigkeit des Stiftdrehens auch von KI-Robotern erlernt.

Der oben erwähnte Stiftdrehroboter profitiert von einem Agenten namens Eureka, einer Forschungsstudie von NVIDIA, der University of Pennsylvania, dem California Institute of Technology und der University of Texas at Austin.
Mit der „Anleitung“ von Eureka kann der Roboter auch Schubladen und Schränke öffnen, Bälle werfen und fangen oder eine Schere benutzen. Laut Nvidia gibt es Eureka in 10 verschiedenen Ausführungen und kann 29 verschiedene Aufgaben ausführen.
Sie müssen wissen, dass die Funktion der Stiftübertragung bisher nicht so reibungslos durch manuelle Programmierung durch menschliche Experten allein realisiert werden konnte.

Der Roboter bereitet Walnüsse zu
Und Eureka kann selbstständig Belohnungsalgorithmen schreiben, um Roboter zu trainieren, und seine Codierungsleistung ist stark: Das selbst geschriebene Belohnungsprogramm übertrifft menschliche Experten in 83 % der Aufgaben und macht das Die Leistung des Roboters wird um durchschnittlich 52 % verbessert.
Eureka hat eine neue Methode des farbverlaufsfreien Lernens auf der Grundlage menschlichen Feedbacks entwickelt. Es kann Belohnungen und Text-Feedback von Menschen problemlos absorbieren und so seinen eigenen Belohnungsgenerierungsmechanismus weiter verbessern.
Konkret nutzt Eureka OpenAIs GPT-4, um Belohnungsprogramme für das Trial-and-Error-Lernen von Robotern zu schreiben. Das bedeutet, dass das System nicht auf menschliche aufgabenspezifische Hinweise oder voreingestellte Belohnungsmuster angewiesen ist.
Mithilfe der GPU-beschleunigten Simulation in Isaac Gym kann Eureka schnell die Vorzüge einer großen Anzahl von Kandidatenbelohnungen bewerten und so ein effizienteres Training ermöglichen. Eureka erstellt dann eine Zusammenfassung der wichtigsten Statistiken der Trainingsergebnisse und leitet das LLM (Sprachmodell) an, um die Generierung der Belohnungsfunktion zu verbessern. Auf diese Weise ist der KI-Agent in der Lage, seine Anweisungen an den Roboter selbstständig zu verbessern.
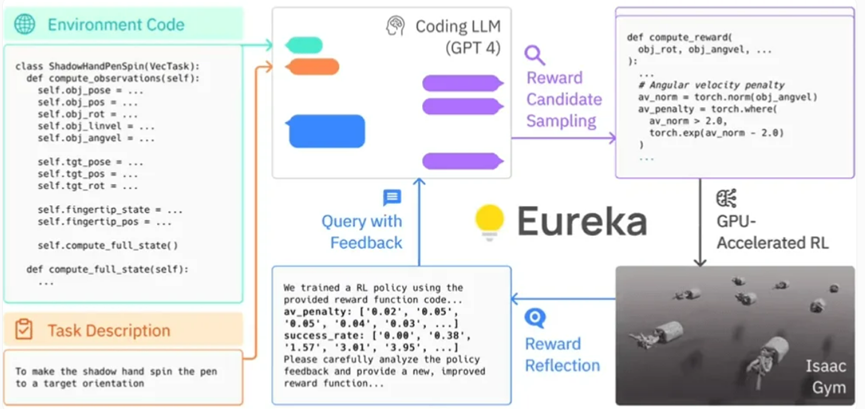
Eurekas Framework
Die Forscher fanden außerdem heraus, dass die Anweisungen von GPT-4 die menschlichen Anweisungen sogenannter „Belohnungsingenieure“ umso mehr übertrafen, je komplexer die Aufgabe war. Die an der Studie beteiligten Forscher nannten Eureka sogar einen „übermenschlichen Belohnungsingenieur“.
Eureka schließt erfolgreich die Lücke zwischen logischem Denken (Kodierung) auf hohem Niveau und motorischer Kontrolle auf niedrigem Niveau. Es verwendet eine sogenannte „Hybrid-Gradienten-Architektur“: Eine reine Inferenz-Blackbox LLM (Sprachmodell, Sprachmodell) leitet ein lernbares neuronales Netzwerk. In dieser Architektur führt die äußere Schleife GPT-4 aus, um die Belohnungsfunktion zu optimieren (gradientenfrei), während die innere Schleife Verstärkungslernen ausführt, um die Steuerung des Roboters zu trainieren (gradientenbasiert).
– Linxi „Jim“ Fan, Senior Research Scientist bei NVIDIA
Eureka kann menschliches Feedback integrieren, um Belohnungen besser an die Erwartungen der Entwickler anzupassen. Nvidia nennt diesen Prozess „in-context RLHF“ (Contextual Learning from Human Feedback)
Es ist erwähnenswert, dass das Forschungsteam von Nvidia die KI-Algorithmusbibliothek von Eureka als Open-Source-Lösung bereitgestellt hat. Dadurch können Einzelpersonen und Institutionen diese Algorithmen über Nvidia Isaac Gym erkunden und damit experimentieren. Isaac Gym basiert auf der Nvidia Omniverse-Plattform, einem Entwicklungsframework zum Erstellen von 3D-Tools und -Anwendungen basierend auf dem Open USD-Framework.

Reinforcement Learning hat im letzten Jahrzehnt große Erfolge erzielt, wir müssen jedoch anerkennen, dass es immer noch Herausforderungen gibt. Obwohl es bereits Versuche gab, ähnliche Technologien einzuführen, ist Eureka im Vergleich zu L2R (Learning to Reward), das Sprachmodelle (LLM) zur Unterstützung des Belohnungsdesigns verwendet, wichtiger, da es keine aufgabenspezifischen Eingabeaufforderungen mehr erfordert. Was Eureka besser als L2R macht, ist seine Fähigkeit, frei formulierte Belohnungsalgorithmen zu erstellen und Umgebungsquellcode als Hintergrundinformationen zu nutzen.
NVIDIAs Forschungsteam hat eine Umfrage durchgeführt, um herauszufinden, ob das Priming mit einer menschlichen Belohnungsfunktion einige Vorteile bietet. Der Zweck des Experiments besteht darin, herauszufinden, ob Sie die ursprüngliche menschliche Belohnungsfunktion erfolgreich durch die Ausgabe der ersten Eureka-Iteration ersetzen können.
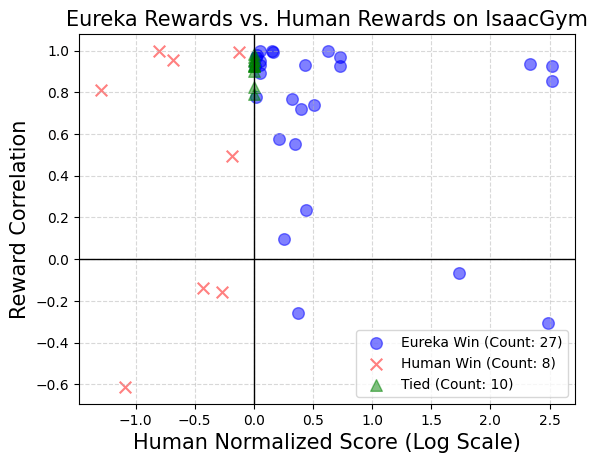
Bei Tests optimierte das Forschungsteam von NVIDIA alle endgültigen Belohnungsfunktionen mithilfe desselben Reinforcement-Learning-Algorithmus und derselben Hyperparameter im Kontext jeder Aufgabe. Um zu testen, ob diese aufgabenspezifischen Hyperparameter gut abgestimmt sind, um die Wirksamkeit künstlich gestalteter Belohnungen sicherzustellen, verwendeten sie eine gut abgestimmte Implementierung der proximalen Richtlinienoptimierung (PPO), die auf früheren Arbeiten ohne Änderungen basierte. Für jede Belohnung führten die Forscher fünf unabhängige PPO-Trainingsläufe durch und meldeten den Durchschnitt der maximalen Aufgabenmetrikwerte, die an Richtlinienkontrollpunkten erreicht wurden, als Maß für die Belohnungsleistung.
Die Ergebnisse zeigen, dass menschliche Designer oft ein gutes Verständnis für relevante Zustandsvariablen haben, ihnen aber möglicherweise gewisse Kompetenzen bei der Gestaltung effektiver Belohnungen fehlen.
Diese bahnbrechende Forschung von Nvidia eröffnet neue Grenzen im Bereich Verstärkungslernen und Belohnungsdesign. Ihr universeller Belohnungsdesign-Algorithmus Eureka nutzt die Leistungsfähigkeit großer Sprachmodelle und kontextueller evolutionärer Suche, um Belohnungen auf menschlicher Ebene für ein breites Spektrum von Roboteraufgabenbereichen zu generieren, ohne dass aufgabenspezifische Eingabeaufforderungen oder menschliches Eingreifen erforderlich sind, was unser Verständnis von erheblich verändert KI und maschinelles Lernen.
Das obige ist der detaillierte Inhalt vonDer Roboter hat gelernt, Stifte zu drehen und Walnüsse zu tellern! GPT-4-Segen: Je komplexer die Aufgabe, desto besser die Leistung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 PS-Kurven-Tastenkombination
PS-Kurven-Tastenkombination
 Welche anmeldefreien Plätze gibt es in China?
Welche anmeldefreien Plätze gibt es in China?
 So stellen Sie Daten von einer mobilen Festplatte wieder her
So stellen Sie Daten von einer mobilen Festplatte wieder her
 Regulärer Ausdruck enthält nicht
Regulärer Ausdruck enthält nicht
 Was wird verteilt?
Was wird verteilt?
 Welche Währung ist USD?
Welche Währung ist USD?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



