


Heutzutage sind riesige neuronale Netzwerkmodelle wie GPT-4 und PaLM entstanden, die erstaunliche Lernfähigkeiten bei wenigen Stichproben gezeigt haben.
Durch einfache Eingabeaufforderungen können sie Textbegründungen durchführen, Geschichten schreiben, Fragen beantworten, programmieren ...
Forscher der Chinesischen Akademie der Wissenschaften und der Yale University haben ein neues Rahmenwerk mit dem Namen „Gedankenpropagation“ vorgeschlagen. zielt darauf ab, die Denkfähigkeit von LLM durch „analoges Denken“ zu verbessern Wenn wir auf ein neues Problem stoßen, vergleichen wir es oft mit ähnlichen Problemen, die wir bereits gelöst haben, um Strategien abzuleiten.
 Der Schlüssel zu diesem Ansatz besteht also darin, „ähnliche“ Probleme im Zusammenhang mit der Eingabe zu untersuchen, bevor das Eingabeproblem gelöst wird.
Der Schlüssel zu diesem Ansatz besteht also darin, „ähnliche“ Probleme im Zusammenhang mit der Eingabe zu untersuchen, bevor das Eingabeproblem gelöst wird.
Schließlich können ihre Lösungen sofort verwendet werden oder um Erkenntnisse für eine nützliche Planung zu gewinnen.
Es ist absehbar, dass „Gedankenkommunikation“ neue Ideen für die inhärenten Grenzen der logischen Fähigkeiten von LLM vorschlägt und es großen Modellen ermöglicht, „Analogie“ zu verwenden, um Probleme wie Menschen zu lösen.
LLM-Mehrschritt-Denken, von Menschen besiegt
LLM ist offensichtlich gut im grundlegenden Denken auf der Grundlage von Eingabeaufforderungen, hat aber immer noch Schwierigkeiten, wenn es um komplexe mehrstufige Probleme wie Optimierung und Planung geht.
Andererseits greifen Menschen auf ihre Intuition aus ähnlichen Erfahrungen zurück, um neue Probleme zu lösen.
Denn das Wissen über LLM stammt vollständig aus den Mustern in den Trainingsdaten und kann die Sprache oder Konzepte nicht wirklich verstehen. Als statistische Modelle ist es daher schwierig, komplexe kombinatorische Verallgemeinerungen durchzuführen.
LLM mangelt es an systematischen Denkfähigkeiten und sie können nicht wie Menschen Schritt für Schritt argumentieren, um herausfordernde Probleme zu lösen, was das Wichtigste ist
Da außerdem die Argumentation großer Modelle parteiisch und kurzsichtig ist, Daher ist es für LLM schwierig, die beste Lösung zu finden, und es ist schwierig, die Konsistenz der Argumentation über einen langen Zeitraum aufrechtzuerhalten kann hauptsächlich auf zwei Kernfaktoren zurückgeführt werden:
Menschen sammeln aus der Praxis wiederverwendbares Wissen und Intuition an, die zur Lösung neuer Probleme beitragen. Im Gegensatz dazu geht LLM jedes Problem „von Grund auf“ an und greift nicht auf frühere Lösungen zurück.
Zusammengesetzte Fehler beim mehrstufigen Denken beziehen sich auf Fehler, die beim mehrstufigen Denken auftreten.
Menschen überwachen ihre eigenen Argumentationsketten und ändern die ersten Schritte bei Bedarf. Fehler, die LLM in den frühen Phasen der Argumentation macht, werden jedoch verstärkt, da sie spätere Überlegungen in die falsche Richtung führen. Die oben genannten Schwächen behindern LLM ernsthaft bei der Bewältigung komplexer Situationen, die eine globale Optimierung oder langfristige Planung erfordern .
Forscher haben eine völlig neue Lösung für dieses Problem vorgeschlagen, nämlich die Gedankenverbreitung
TP-FrameworkDurch analoges Denken kann LLM wie Menschen argumentieren
Bei Forschern scheint es, dass das Denken von Grund auf scheitert Erkenntnisse aus der Lösung ähnlicher Probleme wiederzuverwenden und kann zur Anhäufung von Fehlern in Zwischenphasen des Denkens führen.
Und „Thought Spread“ kann ähnliche Probleme im Zusammenhang mit dem Eingabeproblem untersuchen und sich von Lösungen für ähnliche Probleme inspirieren lassen.
Die folgende Abbildung zeigt den Vergleich zwischen „Thought Propagation“ (TP) und anderen repräsentativen Technologien. Für das Eingabeproblem p müssen IO, CoT und ToT alle von Grund auf argumentieren, um zur Lösung s zu gelangen. Konkret umfasst TP drei Phasen:
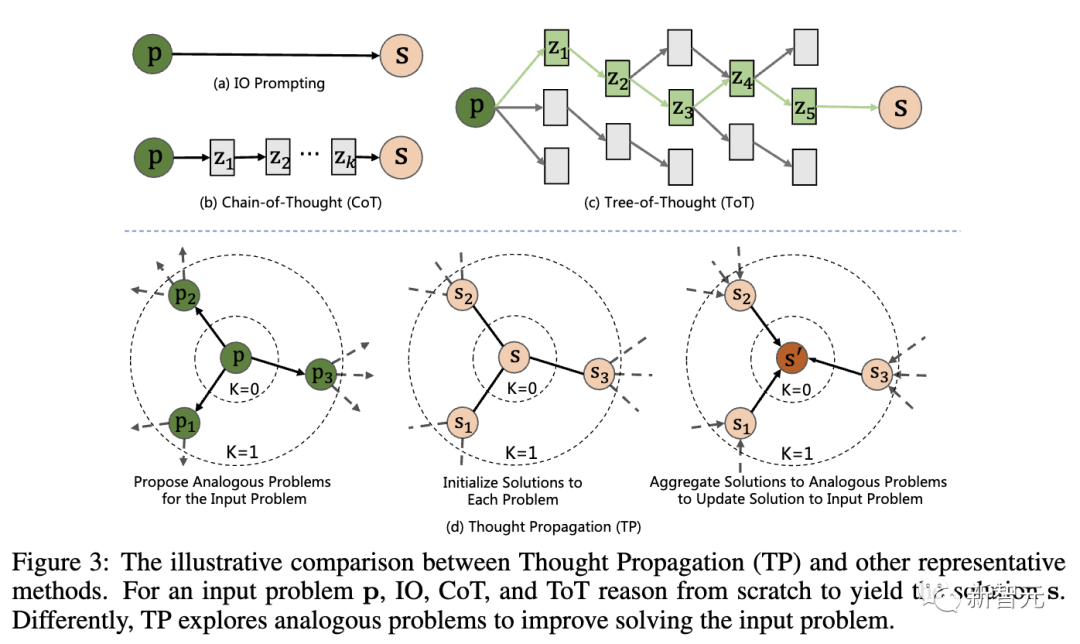
LLM generiert eine Reihe ähnlicher Fragen durch Eingabeaufforderungen, die Ähnlichkeiten mit der Eingabefrage aufweisen. Dadurch wird das Modell angeleitet, potenziell relevante frühere Erfahrungen abzurufen.
2. Ähnliche Probleme lösen: Lassen Sie LLM jedes ähnliche Problem mithilfe vorhandener Eingabeaufforderungstechnologien wie CoT lösen.
3. Zusammenfassende Lösung: Es gibt zwei verschiedene Möglichkeiten – direkt eine neue Lösung für das Eingabeproblem auf der Grundlage der analogen Lösung abzuleiten; einen erweiterten Plan abzuleiten, indem die analoge Lösung mit dem Eingabeproblem oder der Strategie verglichen wird.
Auf diese Weise können große Modelle frühere Erfahrungen und Heuristiken nutzen und ihre anfänglichen Überlegungen können mit analogen Lösungen abgeglichen werden, um diese Lösungen weiter zu verfeinern Es ist erwähnenswert, dass „Denkpropagation“ nichts damit zu tun hat mit dem Modell und kann einen einzelnen Problemlösungsschritt basierend auf jeder Prompt-Methode durchführen LLM mehr wie ein Mensch machen, aber die tatsächlichen Ergebnisse müssen für sich selbst sprechen.
Forscher der Chinesischen Akademie der Wissenschaften und der Yale-Universität bewerteten drei Aufgaben:
– Begründung für den kürzesten Pfad:
Es muss der beste Pfad zwischen Knoten in einem Diagramm gefunden werden, was eine globale Planung und Suche erfordert. Selbst bei einfachen Diagrammen versagen Standardtechniken.
- Kreatives Schreiben:
Das Generieren kohärenter, kreativer Geschichten ist eine Herausforderung mit offenem Ausgang. Bei übergeordneten Gliederungsaufforderungen verliert LLM häufig an Konsistenz oder Logik.
- LLM-Agentenplanung: LLM-Agenten, die mit Textumgebungen interagieren, haben Schwierigkeiten mit langfristigen Strategien. Ihre Pläne „driften“ oft oder bleiben in Zyklen stecken.
? Ermöglichen Sie LLM, suboptimale Lösungen (b, c) zu finden oder sogar wiederholt den Zwischenknoten (d) zu besuchen Inferenzschritt Fehler häufen sich und ToT (b) löst das Problem in (a) nicht. Basierend auf Lösungen für ähnliche Probleme verfeinert TP (c) die anfängliche suboptimale Lösung und findet schließlich die optimale Lösung.Im Vergleich zum Ausgangswert wurde die Leistung von TP bei der Verarbeitung der Aufgabe „Kürzester Weg“ deutlich um 12 % verbessert, wodurch optimale und effektive kürzeste Wege generiert wurden.
Darüber hinaus kommt der generierte effektive Pfad (TP) aufgrund des niedrigsten Online-Rewriting-Werts (OLR) dem optimalen Pfad im Vergleich zur Basislinie am nächsten
Unter verschiedenen Einstellungen sind die Tokenkosten von Layer 1 TP ähnlich wie ToT. Layer 1 TP hat jedoch eine sehr wettbewerbsfähige Leistung bei der Suche nach dem optimalen kürzesten Pfad erzielt.
Darüber hinaus ist der Leistungsgewinn von Layer 1 TP im Vergleich zu Layer 0 TP (IO) ebenfalls sehr signifikant. Abbildung 5(a) zeigt den Anstieg der Tokenkosten für Layer-2-TP.
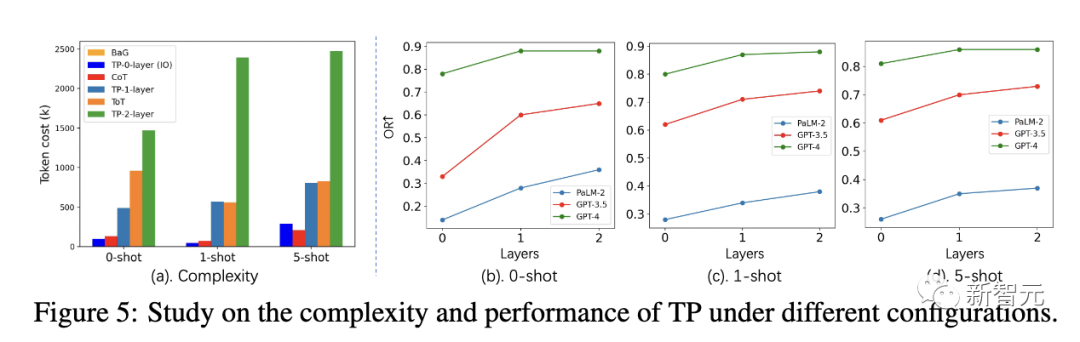
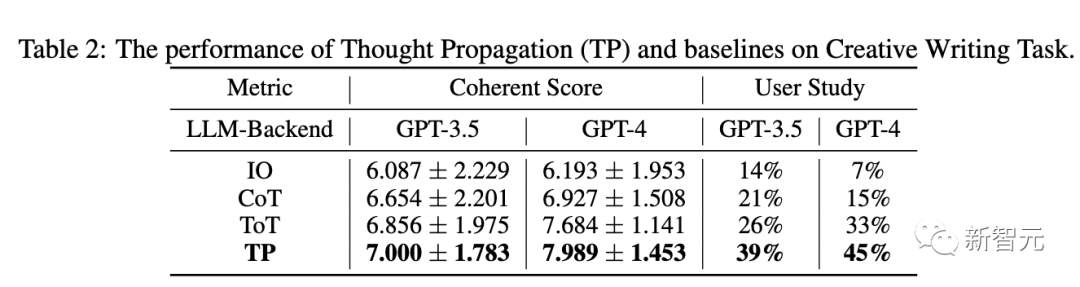
Tabelle 2 unten zeigt die Leistung von TP und Basislinien in GPT-3.5 und GPT-4. In Bezug auf die Konsistenz übertrifft TP den Ausgangswert. Darüber hinaus steigerte TP in Benutzerstudien die menschliche Präferenz für kreatives Schreiben um 13 %.
In der dritten Aufgabenbewertung verwendeten die Forscher die ALFWorld-Spielesuite, um die LLM-Agentenplanungsaufgabe in 134 Umgebungen zu instanziieren.
TP erhöht die Aufgabenerledigungsrate bei der LLM-Agentenplanung um 15 %. Dies zeigt die Überlegenheit der reflektierenden TP für eine erfolgreiche Planung bei der Erledigung ähnlicher Aufgaben.

Anhand der oben genannten experimentellen Ergebnisse wird gezeigt, dass „Thinking Propagation“ auf eine Vielzahl verschiedener Denkaufgaben angewendet werden kann und bei all diesen Aufgaben gute Ergebnisse liefert.
„Denken“ Das „Propagation“-Modell bietet eine neue Technologie für komplexe LLM-Inferenz.
Analoges Denken ist ein Zeichen menschlicher Problemlösungsfähigkeit. Es kann eine Reihe systematischer Vorteile mit sich bringen, wie z. B. eine effizientere Suche und Fehlerkorrektur.
In ähnlichen Situationen kann LLM auch dazu anregen, analoges Denken besser zu bewältigen Ihre eigenen Schwächen, wie z. B. mangelndes wiederverwendbares Wissen und kaskadierende lokale Fehler usw. Darüber hinaus können länger verkettete analoge Argumentationspfade langwierig und schwierig zu verfolgen sein. Gleichzeitig ist die Steuerung und Koordinierung mehrstufiger Argumentationsketten auch eine ziemlich schwierige Aufgabe
Allerdings bietet uns die „Gedankenverbreitung“ immer noch eine interessante Methode, indem sie die Argumentationsmängel des LLM kreativ löst.
Mit der weiteren Entwicklung kann analoges Denken die Denkfähigkeit von LLM noch leistungsfähiger machen. Dies zeigt auch den Weg, um das Ziel eines engeren menschlichen Denkens in großen Sprachmodellen zu erreichen Er ist Professor am Institut für Automatisierung der Chinesischen Akademie der Wissenschaften und an der Universität der Chinesischen Akademie der Wissenschaften sowie IAPR-Fellow und hochrangiges Mitglied des IEEE
Zuvor erhielt er seinen Bachelor- und Master-Abschluss von der Universität Dalian of Technology und promovierte 2009 am Institut für Automatisierung der Chinesischen Akademie der Wissenschaften. Überwachtes oder Transferlernen vorab trainierter Netzwerke), generatives Lernen (generative Modelle, Bilderzeugung, Bildübersetzung).
Er hat mehr als 200 Artikel in internationalen Fachzeitschriften und Konferenzen veröffentlicht, darunter bekannte internationale Fachzeitschriften wie IEEE TPAMI, IEEE TIP, IEEE TIFS, IEEE TNN, IEEE TCSVT und internationale Spitzenzeitschriften wie CVPR, ICCV, ECCV, NeurIPS usw. Konferenz

Yu Junchi ist Doktorand im vierten Jahr am Institut für Automatisierung der Chinesischen Akademie der Wissenschaften. Sein Betreuer ist Professor Heran.
Zuvor absolvierte er ein Praktikum am Tencent Artificial Intelligence Laboratory und arbeitete bei Dr. Tingyang Xu und Dr. Yu Rong, Dr. Yatao Bian und Junzhou-Professor Huang arbeiteten zusammen. Jetzt ist er Austauschstudent am Informatik-Department der Yale University und studiert bei Professor Rex Ying
Sein Ziel ist es, eine vertrauenswürdige Graph-Learning-Methode (TwGL) mit guter Interpretierbarkeit und Portabilität zu entwickeln und deren Anwendung zu erforschen dem Bereich der Biochemie
Das obige ist der detaillierte Inhalt vonDie menschenähnlichen Denkfähigkeiten von GPT-4 wurden erheblich verbessert! Die Chinesische Akademie der Wissenschaften schlug „denkende Kommunikation' vor. Analoges Denken geht über CoT hinaus und kann sofort angewendet werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Linux fügt die Update-Quellenmethode hinzu
Linux fügt die Update-Quellenmethode hinzu
 Erforderliche Kenntnisse für das Web-Frontend
Erforderliche Kenntnisse für das Web-Frontend
 Wie lautet das Passwort für den Mobilfunkdienst?
Wie lautet das Passwort für den Mobilfunkdienst?
 So beheben Sie den Bluescreen 0x0000006b
So beheben Sie den Bluescreen 0x0000006b
 Was ist ein Bitcoin-Futures-ETF?
Was ist ein Bitcoin-Futures-ETF?
 Empfohlene benutzerfreundliche und formelle Software-Apps für Währungsspekulationen im Jahr 2024
Empfohlene benutzerfreundliche und formelle Software-Apps für Währungsspekulationen im Jahr 2024
 Ripple-Zukunftsprognose
Ripple-Zukunftsprognose
 Was soll ich tun, wenn sich mein Computer nicht einschalten lässt?
Was soll ich tun, wenn sich mein Computer nicht einschalten lässt?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



