


Die beste Studentenarbeit des ICCV2023 wurde an Qianqian Wang von der Cornell University verliehen, der derzeit Postdoktorand an der University of California, Berkeley ist!
 Insgesamt bleibt die dichte und weiträumige Flugbahnschätzung in Videos ein ungelöstes Problem auf diesem Gebiet. Dieses Problem bringt drei Hauptherausforderungen mit sich: 1) Wie man die Flugbahngenauigkeit in langen Sequenzen aufrechterhält, 2) Wie man die Position von Punkten unter Okklusion verfolgt, 3) Wie man die räumlich-zeitliche Konsistenz aufrechterhält
Insgesamt bleibt die dichte und weiträumige Flugbahnschätzung in Videos ein ungelöstes Problem auf diesem Gebiet. Dieses Problem bringt drei Hauptherausforderungen mit sich: 1) Wie man die Flugbahngenauigkeit in langen Sequenzen aufrechterhält, 2) Wie man die Position von Punkten unter Okklusion verfolgt, 3) Wie man die räumlich-zeitliche Konsistenz aufrechterhält
In diesem Artikel schlagen die Autoren eine neuartige Videobewegung vor Schätzmethode, die alle Informationen im Video nutzt, um gemeinsam die vollständige Bewegungsbahn jedes Pixels zu schätzen. Diese Methode nennt sich „OmniMotion“ und nutzt eine Quasi-3D-Darstellung. In dieser Darstellung wird in jedem Frame ein Standard-3D-Volumen einem lokalen Volumen zugeordnet. Dieses Mapping dient als flexible Erweiterung der dynamischen Multi-View-Geometrie und kann Kamera- und Szenenbewegungen gleichzeitig simulieren. Diese Darstellung stellt nicht nur die Schleifenkonsistenz sicher, sondern verfolgt auch alle Pixel während der Verdeckungen. Die Autoren optimieren diese Darstellung für jedes Video und bieten eine Lösung für die Bewegung im gesamten Video. Nach der Optimierung kann diese Darstellung auf beliebigen kontinuierlichen Koordinaten des Videos abgefragt werden, um Bewegungstrajektorien zu erhalten, die sich über das gesamte Video erstrecken
Die in diesem Artikel vorgeschlagene Methode kann: 1) eine global konsistente vollständige Darstellung für alle Punkte in den gesamten Bewegungstrajektorien des Videos erzeugen , 2) Verfolgung von Punkten durch Okklusion und 3) Verarbeitung realer Videos mit verschiedenen Kamera- und Szenenaktionskombinationen. Beim TAP-Video-Tracking-Benchmark schneidet die Methode gut ab und übertrifft frühere Methoden bei weitem.
3. MethodeDer Artikel schlägt eine auf Testzeitoptimierung basierende Methode zur Schätzung dichter und weit entfernter Bewegungen aus Videosequenzen vor. Lassen Sie uns zunächst einen Überblick über die in der Arbeit vorgeschlagene Methode geben:
Videoinhalte werden durch ein typisches Volumen namens G dargestellt, das als dreidimensionale Karte der beobachteten Szene fungiert. Ähnlich wie in NeRF definierten sie ein koordinatenbasiertes Netzwerk nerf, das jede typische 3D-Koordinate uvw in G einer Dichte σ und einer Farbe c zuordnet. Die in G gespeicherte Dichte sagt uns, wo sich die Oberfläche im typischen Raum befindet. In Kombination mit 3D-Bijektionen ermöglicht uns dies, Oberflächen über mehrere Frames hinweg zu verfolgen und Okklusionsbeziehungen zu verstehen. Die in G gespeicherte Farbe ermöglicht uns die Berechnung des photometrischen Verlusts während der Optimierung.
In diesem Artikel wird eine kontinuierliche Bijektionsabbildung vorgestellt, die als bezeichnet wird und 3D-Punkte von einem lokalen Koordinatensystem in ein kanonisches 3D-Koordinatensystem umwandelt. Diese kanonische Koordinate dient als konsistente zeitliche Referenz oder „Index“ für einen Szenenpunkt oder eine 3D-Trajektorie. Der Hauptvorteil der Verwendung bijektiver Abbildungen ist die periodische Konsistenz, die sie in 3D-Punkten zwischen verschiedenen Frames bieten, da sie alle vom selben kanonischen Punkt stammen.
Die Abbildungsgleichung von 3D-Punkten von einem lokalen Frame zu einem anderen lautet:
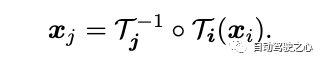
Um komplexe Bewegungen in der realen Welt zu erfassen, werden diese Bijektionen als invertierbare neuronale Netze (INNs) parametrisiert. Die Wahl von Real-NVP als Modell wurde durch seine Einfachheit und seine analytisch reversiblen Eigenschaften beeinflusst. Real-NVP implementiert bijektives Mapping mithilfe grundlegender Transformationen, die als affine Kopplungsschichten bezeichnet werden. Diese Schichten teilen die Eingabe auf, sodass ein Teil unverändert bleibt, während der andere Teil einer affinen Transformation unterzogen wird.
Um diese Architektur weiter zu verbessern, können wir dies tun, indem wir den latenten Code latent_i jedes Frames konditionieren. Daher werden alle reversiblen Abbildungen durch ein einziges reversibles Netzwerk-Mapping-Netz bestimmt, haben aber unterschiedliche latente Codes für jedes Abfragepixel in Frame i. Intuitiv werden Abfragepixel zunächst durch Abtasten von Punkten auf Strahlen in 3D „angehoben“, dann werden diese 3D-Punkte mithilfe der Bijektionszuordnung i und der Abbildung j auf den Zielrahmen j „abgebildet“, gefolgt von einer Alpha-Zusammensetzung aus verschiedenen Abtastwerten. Diese zugeordneten 3D-Punkte sind „gerendert“ und schließlich wieder in 2D „projiziert“, um eine angenommene Entsprechung zu erhalten.
4. Experimenteller Vergleich

Dies ist eine Tabelle mit Ergebnissen von Ablationsexperimenten für den DAVIS-Datensatz. Ablationsexperimente werden durchgeführt, um den Beitrag jeder Komponente zur Gesamtsystemleistung zu überprüfen. In dieser Tabelle sind vier Methoden aufgeführt, von denen drei Versionen bestimmte Schlüsselkomponenten entfernen und die endgültige „Vollversion“ alle Komponenten enthält. 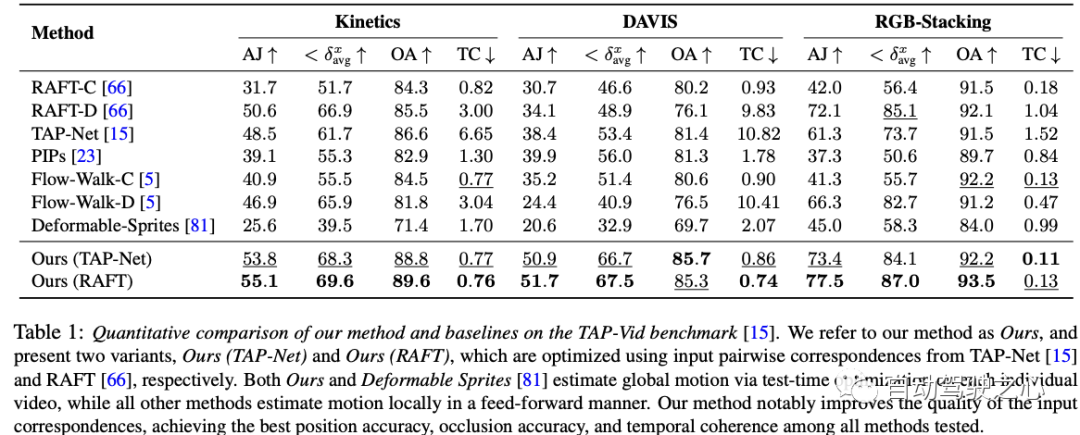
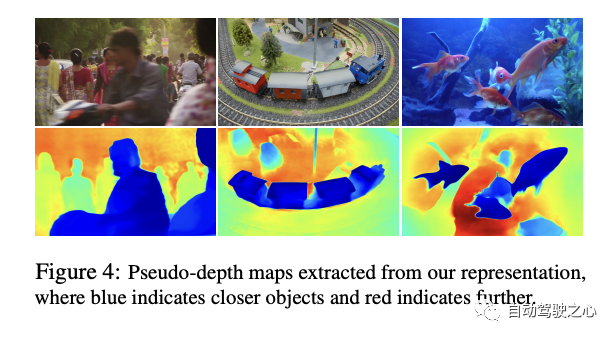
Insgesamt zeigen die Ergebnisse dieses Ablationsexperiments, dass, obwohl jede Komponente eine gewisse Leistungsverbesserung aufweist, die Reversibilität wahrscheinlich die wichtigste Komponente ist, denn ohne sie wird der Leistungsverlust sehr gravierend sein

Die in dieser Arbeit am DAVIS-Datensatz durchgeführten Ablationsexperimente liefern uns wertvolle Erkenntnisse und offenbaren die entscheidende Rolle jeder Komponente für die Gesamtsystemleistung. Aus den experimentellen Ergebnissen können wir deutlich erkennen, dass die Reversibilitätskomponente eine entscheidende Rolle im Gesamtrahmen spielt. Wenn diese kritische Komponente fehlt, sinkt die Systemleistung erheblich. Dies unterstreicht weiter die Bedeutung der Berücksichtigung der Reversibilität bei der dynamischen Videoanalyse. Gleichzeitig führt der Verlust der photometrischen Komponente zwar auch zu einer Leistungsverschlechterung, scheint jedoch keinen so großen Einfluss auf die Leistung zu haben wie die Reversibilität. Darüber hinaus hat die einheitliche Stichprobenstrategie zwar einen gewissen Einfluss auf die Leistung, ist jedoch im Vergleich zu den ersten beiden relativ gering. Schließlich integriert der Gesamtansatz alle diese Komponenten und zeigt uns die unter allen Gesichtspunkten bestmögliche Leistung. Insgesamt bietet uns diese Arbeit eine wertvolle Gelegenheit, Erkenntnisse darüber zu gewinnen, wie die verschiedenen Komponenten der Videoanalyse miteinander interagieren und welchen spezifischen Beitrag sie zur Gesamtleistung leisten, wodurch die Notwendigkeit eines integrierten Ansatzes bei der Gestaltung und Optimierung von Videoverarbeitungsalgorithmen hervorgehoben wird
Allerdings stößt unsere Methode, wie viele Methoden zur Bewegungsschätzung, auf Schwierigkeiten bei der Handhabung schneller und sehr instabiler Bewegungen und kleiner Strukturen. In diesen Szenarien liefern paarweise Korrespondenzmethoden möglicherweise nicht genügend zuverlässige Korrespondenz, damit unsere Methode eine genaue globale Bewegung berechnen kann. Darüber hinaus stellen wir aufgrund der stark nicht-konvexen Natur des zugrunde liegenden Optimierungsproblems fest, dass unser Optimierungsprozess bei bestimmten schwierigen Videos sehr empfindlich auf die Initialisierung reagieren kann. Dies kann zu suboptimalen lokalen Minima führen, beispielsweise zu einer falschen Oberflächenordnung oder zu doppelten Objekten im kanonischen Raum, die manchmal nur schwer durch Optimierung korrigiert werden können.
Schließlich kann unsere Methode in ihrer aktuellen Form rechenintensiv sein. Erstens beinhaltet der Prozess der Flusssammlung eine umfassende Berechnung aller paarweisen Flüsse, die quadratisch mit der Sequenzlänge wächst. Wir glauben jedoch, dass die Skalierbarkeit dieses Prozesses verbessert werden kann, indem effizientere Matching-Methoden wie Vokabelbäume oder Keyframe-basiertes Matching erforscht werden und man sich von der Strukturbewegungs- und SLAM-Literatur inspirieren lässt. Zweitens erfordert unsere Methode wie andere Methoden, die neuronale implizite Darstellungen verwenden, einen relativ langen Optimierungsprozess. Neuere Forschungen in diesem Bereich können dazu beitragen, diesen Prozess zu beschleunigen und ihn weiter auf längere Sequenzen auszudehnen . Es wird eine neue Videobewegungsdarstellung namens OmniMotion eingeführt, die aus einem quasi-3D-Standardvolumen und lokalkanonischen Bijektionen für jedes Bild besteht. OmniMotion kann gewöhnliche Videos mit unterschiedlichen Kameraeinstellungen und Szenendynamiken verarbeiten und durch Okklusion genaue und gleichmäßige Bewegungen über große Entfernungen erzeugen. Sowohl qualitativ als auch quantitativ werden deutliche Verbesserungen gegenüber bisherigen Methoden des Standes der Technik erzielt.
Das obige ist der detaillierte Inhalt vonÜberarbeitung des Titels: ICCV 2023 Hervorragende Verfolgung von Studentenarbeiten, Github hat 1,6.000 Sterne erhalten, umfassende Informationen wie von Zauberhand!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































