



Derzeit sind autonome Fahrzeuge mit einer Vielzahl von Informationserfassungssensoren wie Lidar, Millimeterwellenradar und Kamerasensoren ausgestattet. Aus heutiger Sicht weisen verschiedene Sensoren große Entwicklungsperspektiven bei den Wahrnehmungsaufgaben des autonomen Fahrens auf. Beispielsweise erfassen die von der Kamera gesammelten 2D-Bildinformationen umfangreiche semantische Merkmale, und die von Lidar gesammelten Punktwolkendaten können dem Wahrnehmungsmodell genaue Positionsinformationen und geometrische Informationen des Objekts liefern. Durch die vollständige Nutzung der von verschiedenen Sensoren erhaltenen Informationen kann das Auftreten von Unsicherheitsfaktoren im Wahrnehmungsprozess des autonomen Fahrens reduziert und gleichzeitig die Erkennungsrobustheit des Wahrnehmungsmodells verbessert werden. Heute stellen wir ein Papier zur Wahrnehmung des autonomen Fahrens von Megvii vor. und wurde in die diesjährige ICCV2023 Visual Conference aufgenommen. Das Hauptmerkmal dieses Artikels ist ein End-to-End-BEV-Wahrnehmungsalgorithmus ähnlich wie PETR (er erfordert nicht mehr die Verwendung von NMS-Nachbearbeitungsvorgängen, um redundante Boxen in den Wahrnehmungsergebnissen zu filtern). ) Gleichzeitig werden die Punktwolkeninformationen von Lidar zusätzlich verwendet, um die Wahrnehmungsleistung des Modells zu verbessern. Es handelt sich um einen sehr guten Artikel zur Wahrnehmung des autonomen Fahrens Der Link lautet wie folgt:
Papier-Link: https://arxiv.org/pdf/2301.01283.pdf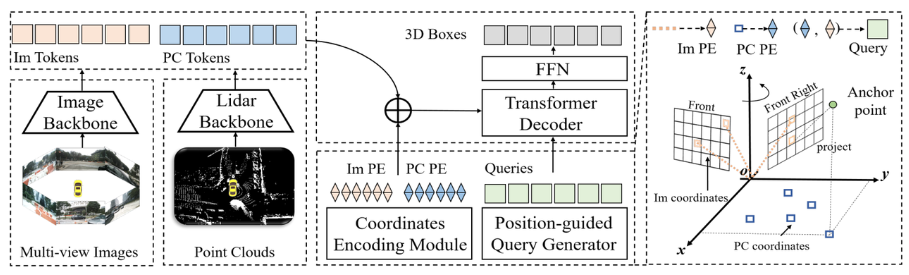 Wie aus dem gesamten Algorithmusblockdiagramm ersichtlich ist, ist das gesamte Algorithmusmodell Besteht hauptsächlich aus drei Teilen: Lidar-Backbone-Netzwerk + Kamera-Backbone-Netzwerk (Bild-Backbone + Lidar-Backbone): Verwendung Um die Eigenschaften von Punktwolken- und Surround-Bildern zu erhalten, können wir Punktwolken-Token** (PC-Token)
Wie aus dem gesamten Algorithmusblockdiagramm ersichtlich ist, ist das gesamte Algorithmusmodell Besteht hauptsächlich aus drei Teilen: Lidar-Backbone-Netzwerk + Kamera-Backbone-Netzwerk (Bild-Backbone + Lidar-Backbone): Verwendung Um die Eigenschaften von Punktwolken- und Surround-Bildern zu erhalten, können wir Punktwolken-Token** (PC-Token)
(Im Tokens)**
Lidar-Backbone-Netzwerk
Üblicherweise verwendete Lidar-Backbone-Netzwerk-Extraktion. Punktwolkendatenfunktionen umfassen die folgenden fünf TeileTensor([bs * N, 1024, H / 16, W / 16])
Tensor([bs *N, 2048, H/16]) code>
Tensor([bs * N, 1024, H / 16, W / 16])
Tensor([bs * N,2048,H / 16,W / 16])
需要重新写的内容是:张量([bs * N,256,H / 16,W / 16])Der Inhalt, der neu geschrieben werden muss, ist: tensor ([bs * N, 256, H/16, W/16])
Umgeschriebener Inhalt: Verwenden Sie das ResNet-50-Netzwerk um Merkmale des Surround-Bildes zu extrahieren
Ausgabe: 16-fach und 32-fach heruntergerechnete Bildmerkmale ausgeben
Eingabetensor: Tensor([bs * N, 3, H, W])Tensor([bs * N,3,H,W])
输出张量:Tensor([bs * N,1024,H / 16,W / 16])
输出张量:``Tensor([bs * N,2048,H / 32,W / 32])`
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程
在BEV空间的网格坐标点利用pos2embed()
Ausgabetensor: Der Generierungsprozess der Bildpositionseinbettung ist derselbe wie die Generierungslogik der Bildpositionskodierung in PETR (Einzelheiten finden Sie unter das ursprüngliche PETR-Papier, das hier nicht gemacht wird Zu viel Ausarbeitung), das in den folgenden vier Schritten zusammengefasst werden kann:
3D-Bildkegelstumpfpunktwolke Verwenden Sie die interne Parametermatrix der Kamera, um sie in das Kamerakoordinatensystem umzuwandeln, um den 3D-Kamerakoordinatenpunkt zu erhalten.
Der 3D-Punkt im Kamerakoordinatensystem wird mithilfe von in das BEV-Koordinatensystem konvertiert cam2ego-Koordinatentransformationsmatrix
Der Generierungsprozess der Punktwolke Die Positionseinbettung kann in die folgenden zwei Schritte unterteilt werden: Gitterkoordinatenpunkte im BEV-Raum. Verwenden Sie: 237); padding: 1px 3px; overflow-wrap: break-word; display: inline-block;">pos2embed() dimensionale horizontale und vertikale Koordinatenpunkte in einen hochdimensionalen Merkmalsraum
Abfrageeinbettung
Um ähnliche Berechnungen zwischen Objektabfragen, Bild-Token und Lidar-Token durchzuführen. Die Einbettung von Abfragen in das Papier wird mithilfe der Logik von Lidar und Kamera erstellt, um insbesondere die Abfrageeinbettung zu generieren = Bildpositionseinbettung (wie rv_query_embeds unten) + Punktwolkenpositionseinbettung (wie bev_query_embeds unten).
bev_query_embeds-Generierungslogik
Da die Objektabfrage im Artikel ursprünglich im BEV-Raum initialisiert wurde, werden die Positionskodierung und die bev_embedding()-Funktion in der Point Cloud Position Embedding-Generierungslogik direkt wiederverwendet. Ja, der entsprechende Schlüsselcode lautet wie folgt:
# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
Zuerst führten wir eine Reihe von Ablationsexperimenten durch, um zu bestimmen, ob die Positionskodierung verwendet werden sollte. Durch die experimentellen Ergebnisse wurde festgestellt, dass bei gleichzeitiger Verwendung der Positionskodierung von Bild und Lidar NDS und mAP verwendet wurden Als nächstes haben wir in (c) und (c) des Ablationsexperiments mit verschiedenen Typen und Voxelgrößen des Punktwolken-Backbone-Netzwerks experimentiert. In den Ablationsexperimenten in den Teilen (d) und (e) haben wir verschiedene Versuche hinsichtlich der Art des Kamera-Backbone-Netzwerks und der Größe der Eingangsauflösung unternommen. Das Obige ist nur eine kurze Zusammenfassung des experimentellen Inhalts. Wenn Sie detailliertere Ablationsexperimente erfahren möchten, lesen Sie bitte den Originalartikel. 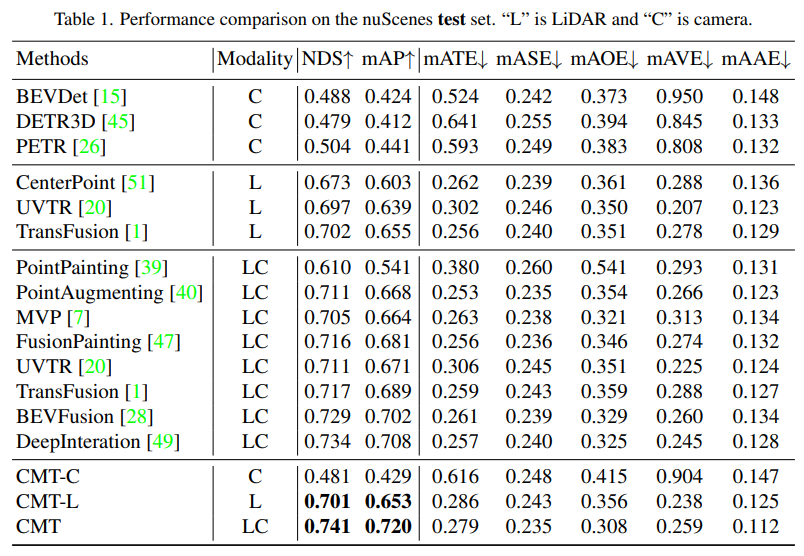
Zusammenfassung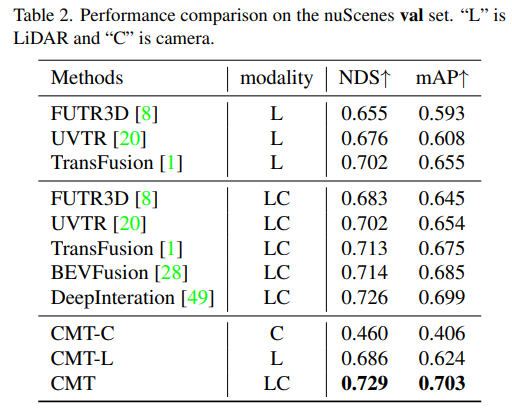
Derzeit ist die Zusammenführung verschiedener Modalitäten zur Verbesserung der Wahrnehmungsleistung des Modells zu einer beliebten Forschungsrichtung geworden (insbesondere bei autonomen Fahrzeugen, die mit einer Vielzahl von Sensoren ausgestattet sind). Mittlerweile ist CMT ein vollständiger End-to-End-Wahrnehmungsalgorithmus, der keine zusätzlichen Nachbearbeitungsschritte erfordert und mit dem nuScenes-Datensatz höchste Genauigkeit erreicht. In diesem Artikel wird dieser Artikel ausführlich vorgestellt. Ich hoffe, dass er für alle hilfreich ist. Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
Das obige ist der detaillierte Inhalt vonCross-modal Transformer: für schnelle und robuste 3D-Objekterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So kaufen Sie echte Ripple-Münzen
So kaufen Sie echte Ripple-Münzen
 Warum hat WLAN ein Ausrufezeichen?
Warum hat WLAN ein Ausrufezeichen?
 Hunderte
Hunderte
 Was soll ich tun, wenn msconfig nicht geöffnet werden kann?
Was soll ich tun, wenn msconfig nicht geöffnet werden kann?
 Art der Systemschwachstelle
Art der Systemschwachstelle
 Einführung in die Gründe, warum der Remote-Desktop keine Verbindung herstellen kann
Einführung in die Gründe, warum der Remote-Desktop keine Verbindung herstellen kann
 Python-Zeitstempel
Python-Zeitstempel
 Der Unterschied zwischen PD-Schnellladen und allgemeinem Schnellladen
Der Unterschied zwischen PD-Schnellladen und allgemeinem Schnellladen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



