


Überraschende Entdeckung: Das große Modell weist schwerwiegende Mängel bei der Wissensableitung auf.
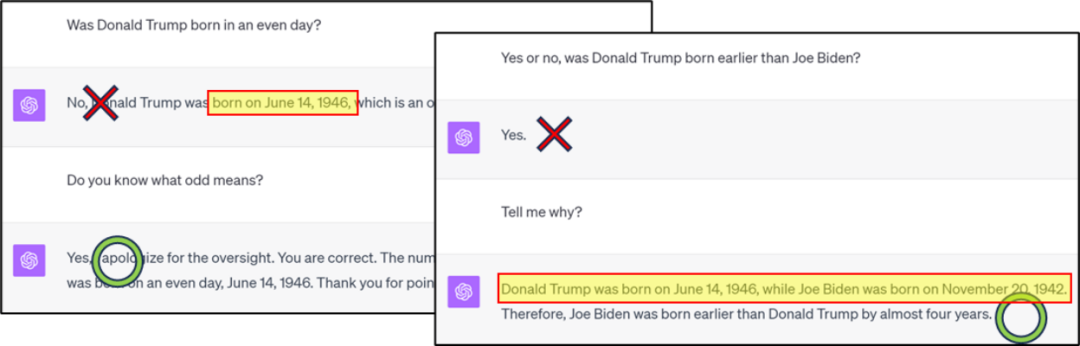
Der Inhalt, der neu geschrieben werden muss, ist: Abbildung 1: GPT4 weist Fehler bei der Wissensklassifizierung/-vergleich auf, aber die richtige Antwort kann über die Denkkette erhalten werden
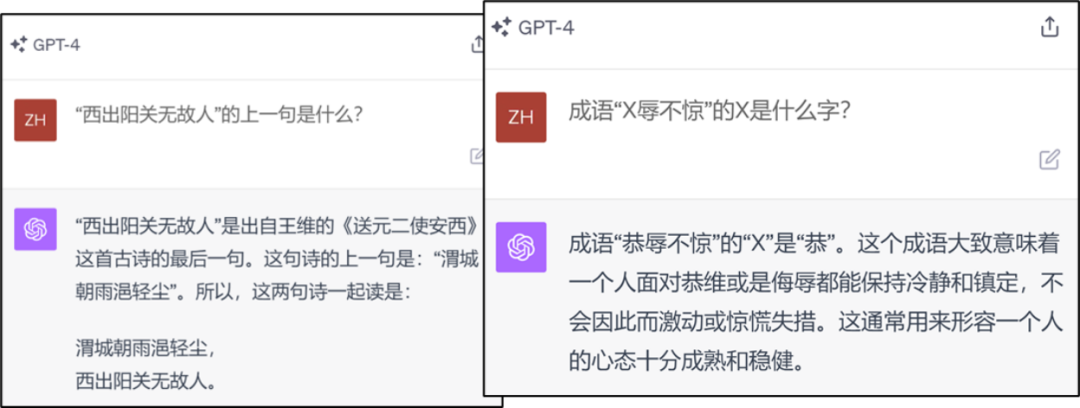
Die Der Inhalt, der neu geschrieben werden muss, ist Ja: Abbildung 2: Beispiel für einen GPT4-Knowledge-Reverse-Search-Fehler

 Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/abs/2309.14402
Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/abs/2309.14402Lassen Sie mich zuerst eine Frage stellen, wie z. B. Abbildung 1/2/3, die das Gedächtnis von Menschen in GPT4 betrifft Geburtstage sind nicht genau genug (das Komprimierungsverhältnis ist nicht ausreichend, der Trainingsverlust ist nicht niedrig genug) oder wurde das Verständnis der Parität nicht durch Feinabstimmung vertieft? Ist es möglich, GPT4 so zu optimieren, dass es vorhandenes Wissen innerhalb des Modells kombinieren kann, um neues Wissen wie „Geburtstagsparität“ zu generieren, um verwandte Fragen direkt zu beantworten, ohne auf CoT angewiesen zu sein? Da wir den Trainingsdatensatz von GPT4 nicht kennen, ist eine Feinabstimmung nicht möglich. Daher schlägt der Autor vor, kontrollierbare Trainingssätze zu verwenden, um die Fähigkeit von Sprachmodellen zur „Wissensableitung“ weiter zu untersuchen. T Abbildung 4: Pre-Training-Modelle wie GPT4, aufgrund der unkontrollierbaren Internetdaten ist es schwierig zu bestimmen, ob die Situation B/C/D auftritt „: Speicherung und Extraktion von Wissen“, der Autor hat einen Datensatz erstellt 100.000 Biografien. Jede Biografie enthält den Namen der Person sowie sechs Attribute: Geburtsdatum, Geburtsort, Hauptfach, Hochschulname, Beschäftigungsort und Arbeitsplatz. Zum Beispiel:
Anya Briar Forger
 Princeton, NJ. Sie widmete ihr Studium der
Princeton, NJ. Sie widmete ihr Studium der . Sie entwickelte ihre Karriere bei Meta Platforms kam am Oktober 1996 auf die Welt. Sie absolvierte Kurse für Fortgeschrittene am
MIT.‖
Die Autorin stellte die Vielfalt der Biografieeinträge sicher, um dem Modell einen besseren Zugang zu Wissen zu ermöglichen. Nach dem Vortraining kann das Modell Fragen zur Wissensextraktion durch Feinabstimmung genau beantworten, z. B. „Wann hat Anya Geburtstag?“ (die Genauigkeitsrate liegt bei nahezu 100 %). Als nächstes führt der Autor die Feinabstimmung fort und versucht, dies zu erreichen Das Modell lernt Wissensdeduktionsfragen wie Klassifizierung/Vergleich/Addition und Subtraktion von Wissen. In dem Artikel wurde festgestellt, dass Modelle in natürlicher Sprache nur über sehr begrenzte Möglichkeiten zur Wissensableitung verfügen und es schwierig ist, durch Feinabstimmung neues Wissen zu generieren, selbst wenn es sich nur um einfache Transformationen/Kombinationen des vom Modell bereits beherrschten Wissens handelt. 
Abbildung 5: Wenn CoT während der Feinabstimmung nicht verwendet wird, ist eine große Anzahl von Stichproben erforderlich, damit das Modell Wissen klassifizieren/vergleichen/subtrahieren kann, oder die Genauigkeitsrate ist extrem niedrig – es wurden 100 Hauptfächer verwendet Das Experiment
Zum Beispiel Abbildung 5. Der Autor stellte fest, dass das Modell zwar nach dem Vortraining genau auf den Geburtstag jedes Einzelnen antworten kann (die Genauigkeitsrate liegt bei nahezu 100 %), es jedoch für die Antwort „Ist der Geburtsmonat von xxx“ feinabgestimmt werden muss eine gerade Zahl?“ und erreicht eine Genauigkeit von 75 % – vergessen Sie nicht, dass blindes Raten eine Genauigkeitsrate von 50 % hat – und erfordert mindestens 10.000 Feinabstimmungsproben. Wenn das Modell im Vergleich dazu die Wissenskombination „Geburtstag“ und „Parität“ korrekt vervollständigen kann, muss das Modell nach der traditionellen Theorie des maschinellen Lernens nur lernen, 12 Monate zu klassifizieren, und normalerweise reichen etwa 100 Stichproben aus!
Auch nachdem das Modell vorab trainiert wurde, kann es jedes Hauptfach genau beantworten (insgesamt 100 verschiedene Hauptfächer), aber selbst unter Verwendung von 50.000 Feinabstimmungsproben kann das Modell vergleichen: „Welches ist besser, Anyas Hauptfach oder“ Sabrinas Hauptfach beträgt die Genauigkeitsrate nur 53,9 %, was fast einer Schätzung entspricht. Wenn wir jedoch das CoT-Feinabstimmungsmodell verwenden, um den Satz „Anyas Geburtsmonat ist Oktober, ist es eine gerade Zahl“ zu lernen, Das Modell bestimmt den Geburtsmonat im Testsatz. Die Genauigkeit der monatlichen Parität hat sich erheblich verbessert (siehe Spalte „CoT zum Testen“ in Abbildung 5).
Die Autoren haben auch versucht, CoT- und Nicht-CoT-Antworten bei der Feinabstimmung der Trainingsdaten zu mischen , und stellte fest, dass das Modell im Testsatz besser abschnitt, wenn CoT nicht verwendet wurde. Die Genauigkeitsrate ist immer noch sehr niedrig (siehe Spalte „Test ohne CoT“ in Abbildung 5). Dies zeigt, dass das Modell selbst dann nicht lernen kann, „im Kopf zu denken“ und die Antwort direkt zu melden, selbst wenn genügend CoT-Feinabstimmungsdaten hinzugefügt werden. Diese Ergebnisse zeigen, dass es für Sprachmodelle äußerst schwierig ist, einfaches Wissen zu implementieren Operationen! Das Modell muss zunächst die Wissenspunkte aufschreiben und dann Berechnungen durchführen. Es kann nicht direkt im Gehirn betrieben werden, selbst wenn es ausreichend fein abgestimmt ist.
Herausforderungen bei der umgekehrten Wissenssuche
Untersuchungen haben außerdem ergeben, dass Modelle in natürlicher Sprache erlerntes Wissen nicht durch die umgekehrte Suche anwenden können. Obwohl es alle Informationen über eine Person beantworten kann, kann es anhand dieser Informationen nicht den Namen der Person bestimmenDie Autoren experimentierten mit GPT3.5/4 und stellten fest, dass sie bei der umgekehrten Wissensextraktion schlecht abschneiden (siehe Abbildung 6). Da wir jedoch den Trainingsdatensatz von GPT3.5/4 nicht bestimmen können, beweist dies nicht, dass alle Sprachmodelle dieses Problem haben

Der Autor nutzte den oben genannten Biografiedatensatz, um eine eingehendere Untersuchung der kontrollierten Tests der Reverse-Wissenssuchfunktionen des Modells durchzuführen. Da die Namen aller Biografien am Anfang des Absatzes stehen, hat der Autor 10 Fragen zur umgekehrten Informationsextraktion entworfen, wie zum Beispiel: Kennen Sie den Namen der Person, die am 2. Oktober 1996 in Princeton, New Jersey, geboren wurde?
„Sagen Sie mir bitte den Namen einer Person, die am MIT Kommunikation studiert hat, am 2. Oktober 1996 in Princeton, New Jersey, geboren wurde und bei Meta Platforms in Menlo Park, Kalifornien, arbeitet?“
Der Autor hat bestätigt, dass das Modell zwar eine verlustfreie Wissenskomprimierung und eine ausreichende Wissenserweiterung erreicht und dieses Wissen fast zu 100 % korrekt extrahieren konnte, aber in Nachher gut Bei der Optimierung ist das Modell immer noch nicht in der Lage, eine umgekehrte Wissenssuche durchzuführen, und die Genauigkeit ist nahezu Null (siehe Abbildung 7). Sobald das umgekehrte Wissen jedoch direkt im Vortrainingssatz erscheint, steigt die Genauigkeit der umgekehrten Suche sofort an. Zusammenfassend lässt sich sagen, dass das Modell die umgekehrte Frage nur dann durch Feinabstimmung beantworten kann, wenn das inverse Wissen direkt in den Pretrain-Daten enthalten ist. Dies ist jedoch tatsächlich Betrug, denn wenn das Wissen umgekehrt wurde, wird dies nicht der Fall sein. Es ist „ „Umgekehrte Wissenssuche“ erneut. Wenn der vorab trainierte Satz nur Vorwärtswissen enthält, kann das Modell die Fähigkeit, Fragen durch Feinabstimmung in umgekehrter Reihenfolge zu beantworten, nicht beherrschen. Daher scheint die Verwendung von Sprachmodellen zur Wissensindizierung (Wissensdatenbank) derzeit unmöglich.
Darüber hinaus denken einige Leute möglicherweise, dass die obige „umgekehrte Wissenssuche“ fehlschlägt, weil autoregressive Sprachmodelle (wie GPT) einseitig sind. In der Realität schneiden bidirektionale Sprachmodelle (wie BERT) jedoch bei der Wissensextraktion schlechter ab und versagen sogar bei der Vorwärtsextraktion. Interessierte Leser können die detaillierten Informationen im Papier nachlesen
Das obige ist der detaillierte Inhalt vonDas Sprachmodell weist große Mängel auf und die Wissensableitung erweist sich als ein seit langem bestehendes Problem. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Wie lange dauert es, bis die Douyin-Aufladung eintrifft?
Wie lange dauert es, bis die Douyin-Aufladung eintrifft?
 Die Rolle des Füllattributs in CSS
Die Rolle des Füllattributs in CSS
 So öffnen Sie HTML-Dateien
So öffnen Sie HTML-Dateien
 Grundbausteine von Präsentationen
Grundbausteine von Präsentationen
 Was tun, wenn der Bluetooth-Schalter in Windows 10 fehlt?
Was tun, wenn der Bluetooth-Schalter in Windows 10 fehlt?
 Was ist der Grund, warum das Netzwerk nicht verbunden werden kann?
Was ist der Grund, warum das Netzwerk nicht verbunden werden kann?
 Computersprachen
Computersprachen
 So implementieren Sie die CSS-Karussellfunktion
So implementieren Sie die CSS-Karussellfunktion

























