


KI-Agent ist derzeit ein heißes Feld [1] von LilianWeng, Leiterin der OpenAI-Anwendungsforschung, schlug sie das Konzept von Agent = LLM + Gedächtnis + Planungsfähigkeiten + Werkzeugnutzung vor
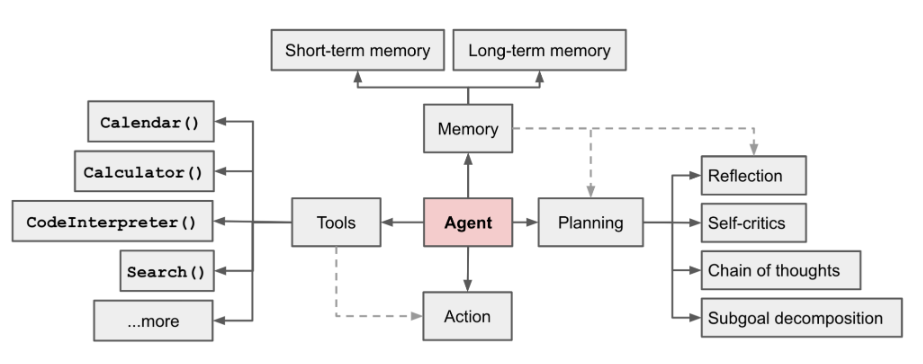
Abbildung 1 – Übersicht über ein LLM-gestütztes autonomes Agentensystem
Die Rolle des Agenten besteht darin, das leistungsstarke Sprachverständnis und die logischen Denkfähigkeiten von LLM zu nutzen, um Werkzeuge aufzurufen, die Menschen bei der Erledigung von Aufgaben unterstützen. Dies bringt jedoch auch einige Herausforderungen mit sich. Beispielsweise bestimmt die Fähigkeit des Basismodells die Effizienz der Agentenaufruftools, aber das Basismodell selbst weist Probleme wie große Modellillusion auf. Dieser Artikel beginnt mit „Eingabe eines Stücks“. „Anleitung zur automatischen Aufteilung komplexer Aufgaben und Funktionsaufrufe“ als Beispiel für den Aufbau des grundlegenden Agentenprozesses, und der Schwerpunkt liegt auf der Erläuterung, wie die Module „Aufgabenaufteilung“ und „Funktionsaufruf“ durch „grundlegende Modellauswahl“ und „Eingabeaufforderung“ erfolgreich erstellt werden Design", usw.
Der neu geschriebene Inhalt lautet: Adresse:
https://sota.jiqizhixin.com/project/smart_agent
GitHub Repo:
. brauchen schwere Die Der geschriebene Inhalt lautet: https://github.com/zzlgreat/smart_agent
Agentenprozess für Aufgabenaufteilung und Funktionsaufrufe
Planer:
Um den oben genannten Prozess zu realisieren, wird in den Modulen „Task Splitting“ und „Function Calling“ das Projekt wurde separat entwickelt. Zwei fein abgestimmte Modelle ermöglichen die Aufteilung komplexer Aufgaben und den Aufruf benutzerdefinierter Funktionen bei Bedarf. Der zusammengefasste Modelllöser kann derselbe sein wie das Split-Task-Modell. Große Modelle erfordern die Fähigkeit, komplexe Aufgaben in einfachere Aufgaben zu zerlegen. Der Erfolg der „Aufgabenaufteilung“ hängt hauptsächlich von zwei Faktoren ab: 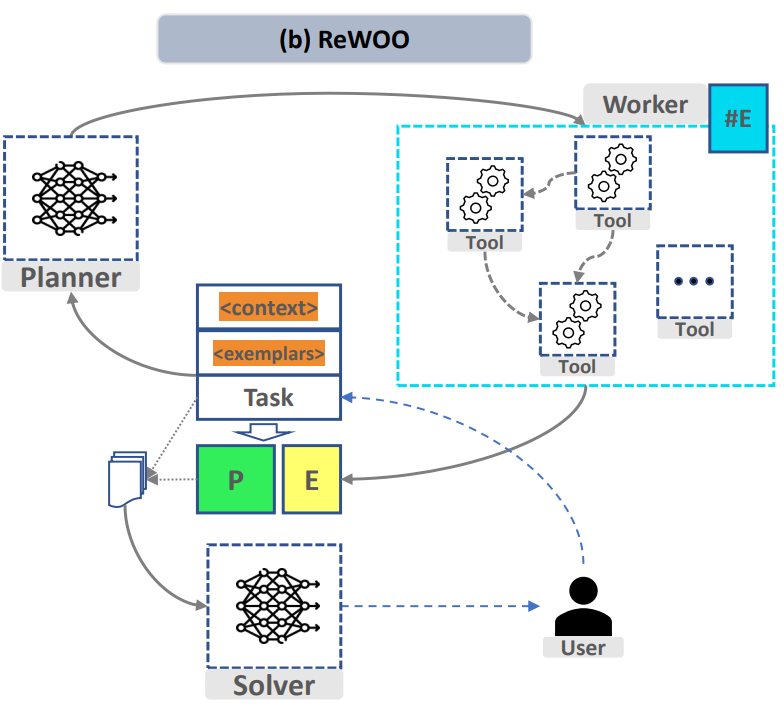
Auswahl des Grundmodells: Um komplexe Aufgaben aufzuteilen, muss die Auswahl des fein abgestimmten Grundmodells selbst über gute Verständnis- und Generalisierungsfähigkeiten verfügen. Das heißt, Aufgaben, die nicht im Trainingssatz enthalten sind, werden gemäß den Anweisungen der Eingabeaufforderung aufgeteilt. Derzeit ist dies einfacher, wenn man ein großes Modell mit hohen Parametern wählt.
Gleichzeitig hoffen wir, dass das Ausgabeformat des Aufgabenaufteilungsmodells unter einer bestimmten Eingabeaufforderungsvorlage so relativ wie möglich festgelegt werden kann, es jedoch nicht überpasst und die ursprünglichen Argumentations- und Verallgemeinerungsfähigkeiten des Modells nicht verliert Hier verwenden wir Lora, um die qv-Ebene zu optimieren und so wenige strukturelle Änderungen wie möglich am Originalmodell vorzunehmen.
Darüber hinaus werden im Hinblick auf die Rechenleistungsnutzung die Feinabstimmung und Inferenz großer Sprachmodelle unter Bedingungen geringer Rechenleistung durch Lora/Qlora-Feinabstimmung erreicht, und der quantitative Einsatz wird übernommen, um den Schwellenwert weiter zu senken zur Schlussfolgerung.
Bei der Auswahl des Modells „Aufgabenaufteilung“ hoffen wir, dass das Modell über starke Generalisierungsfähigkeiten und bestimmte Denkkettenfähigkeiten verfügt. In diesem Zusammenhang können wir uns auf die Open LLM-Rangliste auf HuggingFace beziehen, um Modelle auszuwählen. Wir sind mehr besorgt über den Test MMLU und den umfassenden Score Average, der die Multitask-Genauigkeit des Textmodells misst muss neu geschrieben werden. Der Inhalt ist: Abbildung 2 HuggingFace offenes LLM-Ranking (0921)
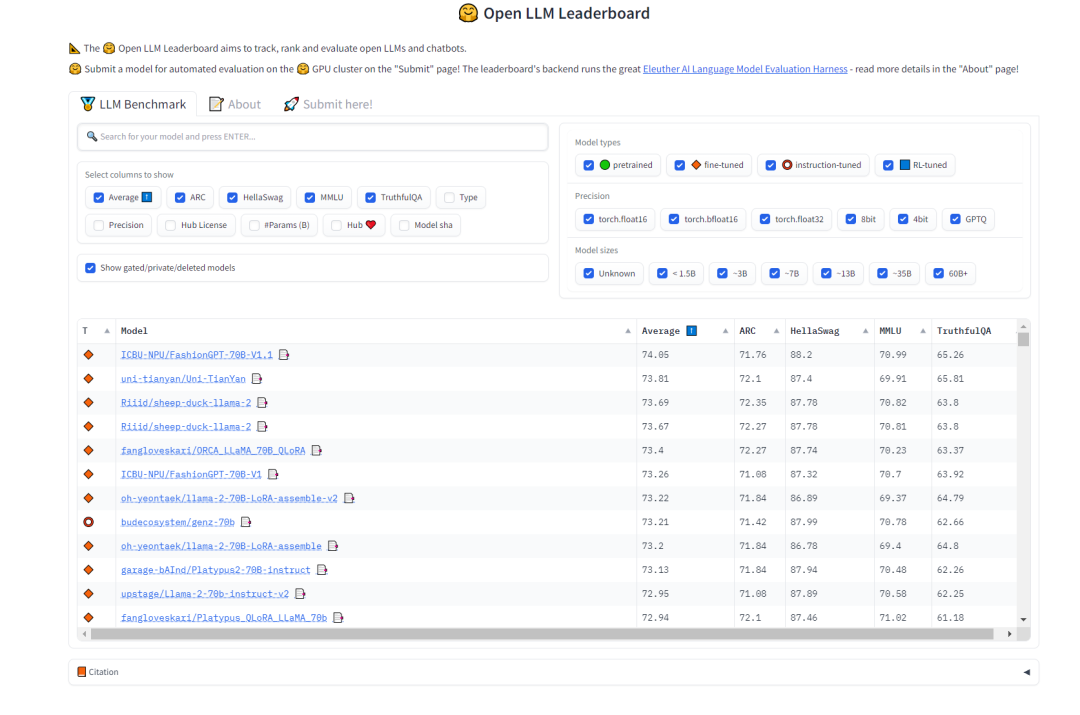
Das für dieses Projekt ausgewählte Aufgabenteilungsmodell ist:
AIDC-ai-business/Marcoroni -70B: Das Modell basiert auf der Feinabstimmung von Llama2 70B und ist für die Aufteilung von Aufgaben verantwortlich. Laut dem Open LLM Leaderboard auf HuggingFace sind die MMLU und der Durchschnitt dieses Modells relativ hoch, und dem Trainingsprozess dieses Modells werden große Datenmengen im Orca-Stil hinzugefügt, was für mehrere Dialogrunden geeignet ist -distribute-work-plan-work ...die Leistung wird im Zusammenfassungsprozess besser sein.
In Bezug auf die Aufgabenaufteilung verwendet dieses Projekt das vom Planer im großen Sprachmodell für effizientes Denken ReWOO (Reasoning WithOut Observation) entworfene Prompt-Format. Ersetzen Sie einfach Funktionen wie „Wikipedia[input]“ durch die entsprechenden Funktionen und Beschreibungen. Das Folgende ist die Beispielaufforderung:
For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: Wikipedia[input]: Worker that search for similar page contents from Wikipedia. Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.The response are long and might contain some irrelevant information. Input should be a search query. LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
Für Funktionsaufrufe werden die Open-Source-Funktionen auf Huggingface ausgeführt, da die Qlora-Feinabstimmung später durchgeführt wird werden direkt verwendet Rufen Sie den Eingabeaufforderungsstil im Datensatz auf [3]. Siehe unten.
在Ubuntu 22.04系统上,使用了CUDA 11.8和Pytorch 2.0.1,并采用了LLaMA-Efficient-Tuning框架。此外,还使用了Deepspeed 0.10.4
需要进行针对 Marcoroni-70B 的 lora 微调
全部选择完成后,新建一个训练的 bash 脚本,内容如下:
accelerate launch src/train_bash.py \--stage sft \--model_name_or_path your_model_path \--do_train \--dataset rewoo \--template alpaca \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir your_output_path \--overwrite_cache \--per_device_train_batch_size 1 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-6 \--num_train_epochs 4.0 \--plot_loss \--flash_attn \--bf16
这样的设置需要的内存峰值最高可以到 240G,但还是保证了 6 卡 4090 可以进行训练。开始的时候可能会比较久,这是因为 deepspeed 需要对模型进行 init。之后训练就开始了。
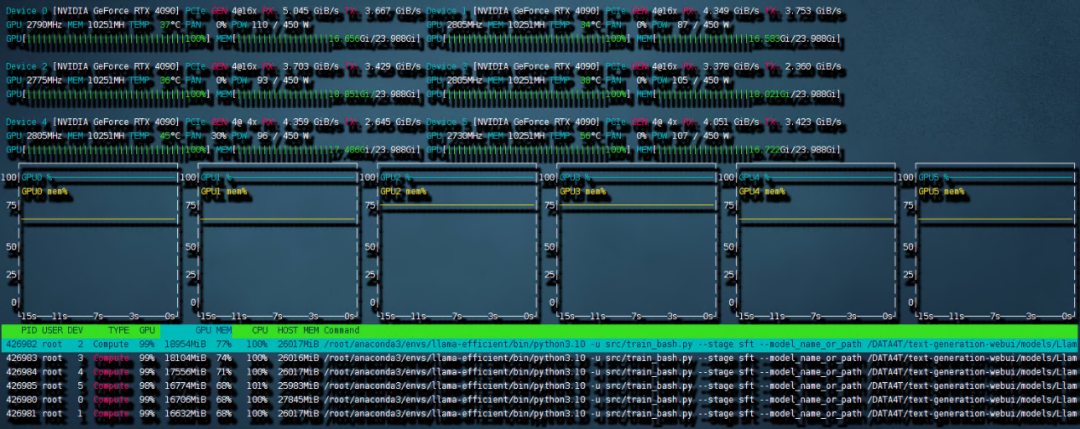
需要重新写的内容是:图4 6 卡 4090 训练带宽速度
共计用时 8:56 小时。本次训练中因为主板上的 NVME 插槽会和 OCULINK 共享一路 PCIE4.0 x16 带宽。所以 6 张中的其中两张跑在了 pcie4.0 X4 上,从上图就可以看出 RX 和 TX 都只是 PCIE4.0 X4 的带宽速度。这也成为了本次训练中最大的通讯瓶颈。如果全部的卡都跑在 pcie 4.0 x16 上,速度应该是比现在快不少的。
需要进行改写的内容是:图5展示了LLaMA-Efficient-Tuning生成的损失曲线
以上是 LLaMA-Efficient-Tuning 自动生成的 loss 曲线,可以看到 4 个 epoch 后收敛效果还是不错的。
2)针对 codellama 的 qlora 微调
根据前文所述的 prompt loss mask 方法,我们对 trainer 类进行了重构(请参考项目代码仓库中的 func_caller_train.py)。由于数据集本身较小(共55行),所以仅需两分钟即可完成4个epoch的训练,模型迅速收敛
在项目代码仓库中,提供了一个简短可用的 toolkit 示例。里面的函数包括:
现在有一个70B和一个34B的模型,在实际使用中,用6张4090同时以bf16精度运行这两个模型是不现实的。但是可以通过量化的方法压缩模型大小,同时提升模型推理速度。这里采用高性能LLM推理库exllamav2运用flash_attention特性来对模型进行量化并推理。在项目页面中作者介绍了一种独特的量化方式,本文不做赘述。按照其中的转换机制可以将70B的模型按照2.5-bit量化为22G的大小,这样一张显卡就可以轻松加载
需要重新编写的内容是:1)测试方法
Bei einer komplexen Aufgabenbeschreibung, die nicht im Trainingsset enthalten ist, fügen Sie dem Toolkit Funktionen und entsprechende Beschreibungen hinzu, die nicht im Trainingsset enthalten sind. Wenn der Planer die Aufgabenaufteilung abschließen kann, kann der Verteiler die Funktion aufrufen und der Löser kann die Ergebnisse basierend auf dem gesamten Prozess zusammenfassen.
Der Inhalt, der neu geschrieben werden muss, ist: 2) Testergebnisse
Aufgabenaufteilung: Verwenden Sie zunächst text-generation-webui, um schnell die Wirkung des Aufgabenaufteilungsmodells zu testen, wie in der folgenden Abbildung dargestellt :

Abbildung 6 Ergebnisse des Task-Split-Tests
Hier können Sie eine einfache restful_api-Schnittstelle schreiben, um den Aufruf in der Agent-Testumgebung zu erleichtern (siehe Projektcode fllama_api.py).
Funktionsaufruf: Im Projekt wurde eine einfache Planer-Verteiler-Arbeiter-Löser-Logik geschrieben. Als nächstes testen wir diese Aufgabe. Geben Sie einen Befehl ein: Bei welchen Filmen hat der Regisseur von „Killers of the Flower Moon“ Regie geführt? Listen Sie eine davon auf und suchen Sie sie in bilibili.
「Bilibili durchsuchen」Diese Funktion ist nicht im Funktionsaufruf-Trainingssatz des Projekts enthalten. Gleichzeitig handelt es sich bei diesem Film um einen neuen Film, der noch nicht veröffentlicht wurde. Es ist nicht sicher, ob die Trainingsdaten des Modells selbst enthalten sind. Sie können sehen, dass das Modell die Eingabeanweisungen sehr gut aufteilt:
auf bilibili und dem gleichzeitigen Aufruf der Funktion wurden folgende Ergebnisse angezeigt: Das angeklickte Ergebnis ist Goodfellas, was mit dem Regisseur des Films übereinstimmt.
Dieses Projekt nimmt das Szenario „Eingabe eines Befehls zur automatischen Implementierung komplexer Aufgabenaufteilung und Funktionsaufrufe“ als Beispiel und entwirft einen grundlegenden Agentenprozess: Toolkit-Plan-Verteilung-Worker-Löser an Implementieren Sie einen Agenten, der grundlegende komplexe Aufgaben ausführen kann, die nicht in einem Schritt erledigt werden können. Durch die Auswahl grundlegender Modelle und die Feinabstimmung von Lora können die Feinabstimmung und Inferenz großer Modelle unter Bedingungen geringer Rechenleistung durchgeführt werden. Und wenden Sie eine quantitative Einsatzmethode an, um die Argumentationsschwelle weiter zu senken. Schließlich wurde über diese Pipeline ein Beispiel für die Suche nach anderen Werken eines Filmregisseurs implementiert und grundlegende komplexe Aufgaben erledigt.
Einschränkungen: In diesem Artikel werden nur Funktionsaufrufe und Aufgabenaufteilungen basierend auf dem Toolkit für Suche und Grundoperationen entworfen. Das verwendete Toolset ist sehr einfach und weist nicht viel Design auf. Dem Fehlertoleranzmechanismus wird nicht viel Beachtung geschenkt. Durch dieses Projekt kann jeder weiterhin Anwendungen im RPA-Bereich erforschen, den Agentenprozess weiter verbessern und einen höheren Grad an intelligenter Automatisierung erreichen, um die Verwaltbarkeit des Prozesses zu verbessern.
Das obige ist der detaillierte Inhalt vonWie wird AI Agent implementiert? 6 Fotos von 4090 Magic Modified Llama2: Aufgaben aufteilen und Funktionen mit einem Befehl aufrufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So ändern Sie den Text im Bild
So ändern Sie den Text im Bild
 Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
 So lassen Sie PPT-Bilder einzeln erscheinen
So lassen Sie PPT-Bilder einzeln erscheinen
 So erstellen Sie ein rundes Bild in ppt
So erstellen Sie ein rundes Bild in ppt
 HTML-Formatierungsmethode
HTML-Formatierungsmethode
 Was sind die Parameter des Festzeltes?
Was sind die Parameter des Festzeltes?
 So ermitteln Sie den Standort des Mobiltelefons einer anderen Person
So ermitteln Sie den Standort des Mobiltelefons einer anderen Person
 Können Weibo-Mitglieder Besucherdatensätze einsehen?
Können Weibo-Mitglieder Besucherdatensätze einsehen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



