


Das erste Open-Source-Großmodell für zweisprachige Sprachdialoge Chinesisch-Englisch ist da!
In den letzten Tagen ist auf arXiv ein Artikel über ein großes multimodales Sprach-Text-Modell erschienen, und der Name von Kai-fu Lees großem Modellunternehmen 01.ai – Zero One Thousand Things – ist unter der Signatur aufgetaucht Unternehmen.
 Bild
Bild
In diesem Artikel wird ein kommerziell erhältliches zweisprachiges Chinesisch-Englisch-Konversationsmodell namens LLaSM vorgestellt. Dieses Modell unterstützt nicht nur die Aufzeichnung und Texteingabe, sondern kann auch die Funktion von „Hybriddoppeln“ realisieren
 Bild
Bild
Untersuchungen haben ergeben, dass „Voice-Chat“ eine bequemere und natürlichere Art der Interaktion zwischen KI und Menschen ist , nicht nur durch Texteingabe
verwendet große Modelle, und einige Internetnutzer stellen sich bereits das Szenario vor, „Code zu schreiben, während man sich hinlegt und redet“.
 Bilder
Bilder
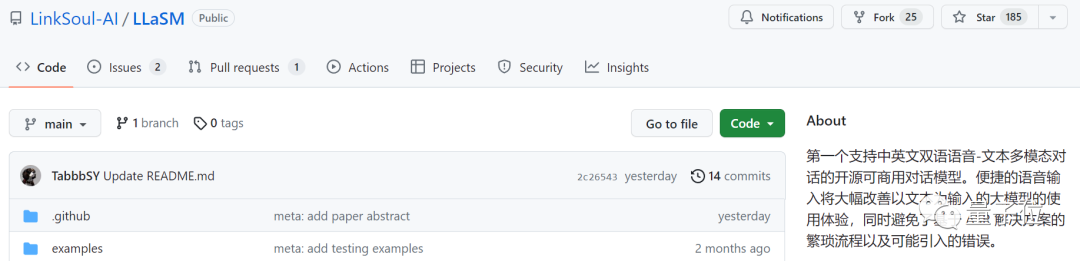
Diese Forschung wurde gemeinsam von LinkSoul.AI, der Peking-Universität und Zero One Wish durchgeführt. Sie ist jetzt Open Source und kann direkt in Huugian ausprobiert werden.
 Bilder
Bilder
Werfen wir einen Blick darauf wie effektiv es ist
Laut Forschern ist LLaSM die erste Open-Source- und kommerziell verfügbare Open-Source-Lösung, die zweisprachige Sprachtexte in Chinesisch und Englisch multimodal unterstützt Dialog Dialogmodell.
Werfen wir also einen Blick auf die Sprachtexteingabe und die zweisprachigen Funktionen für Chinesisch und Englisch.
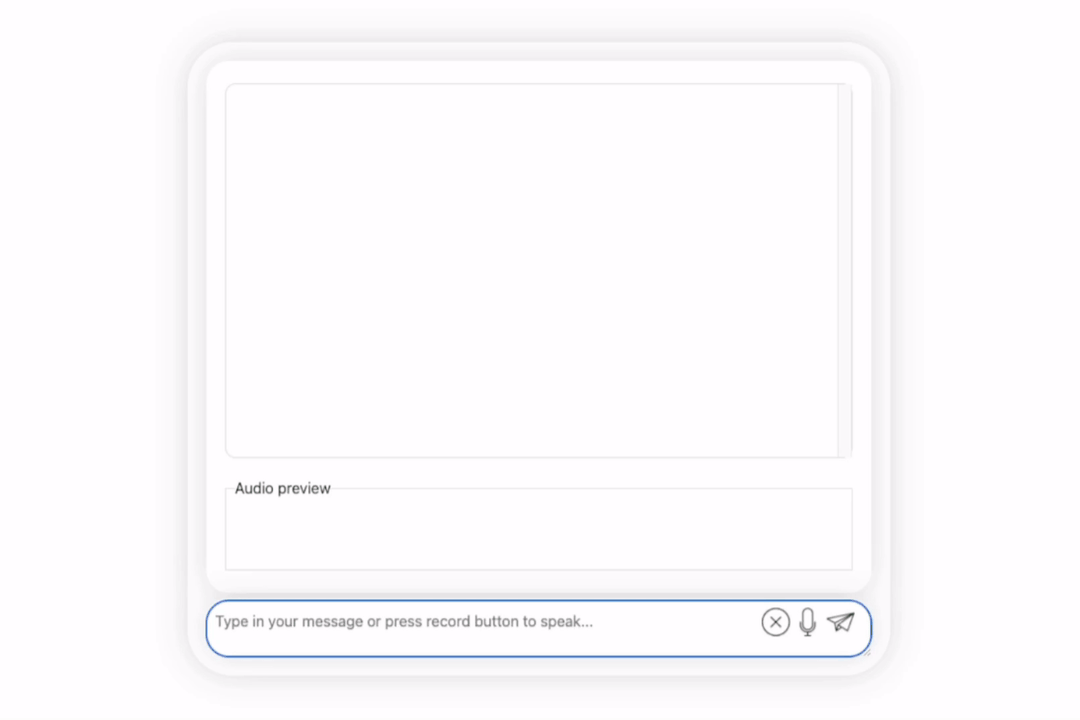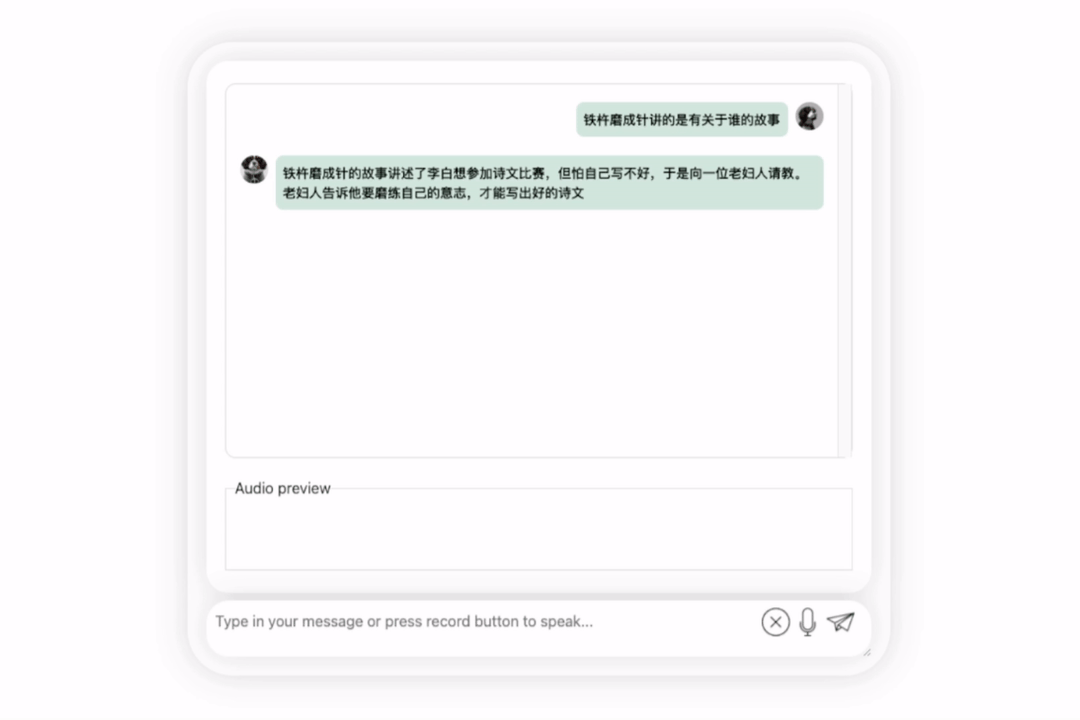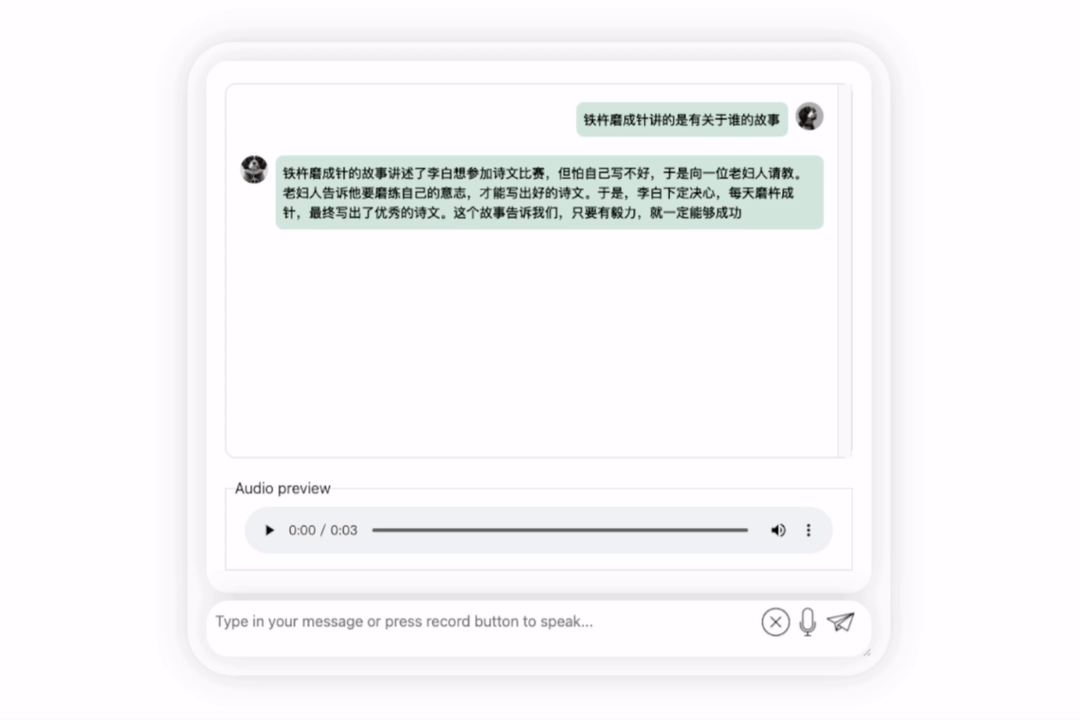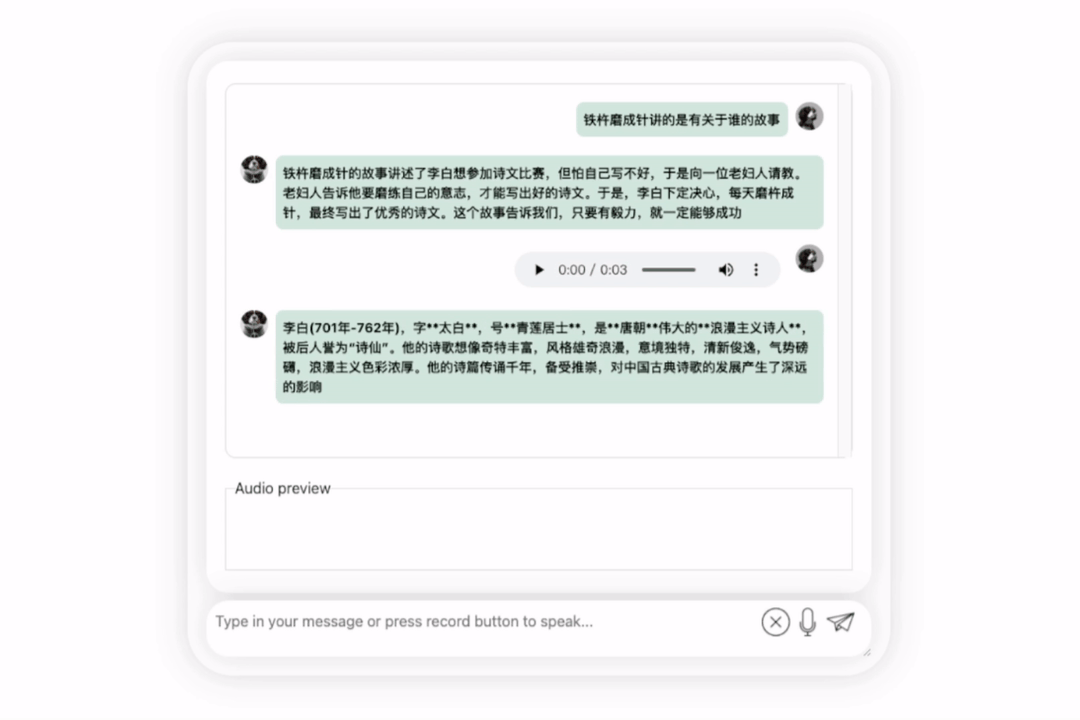
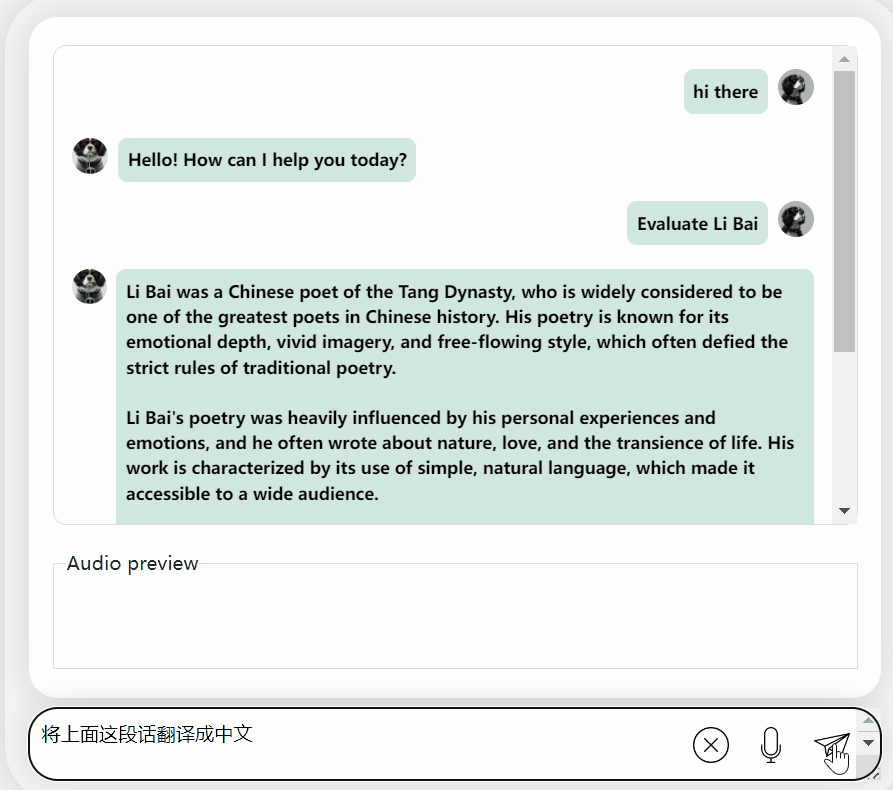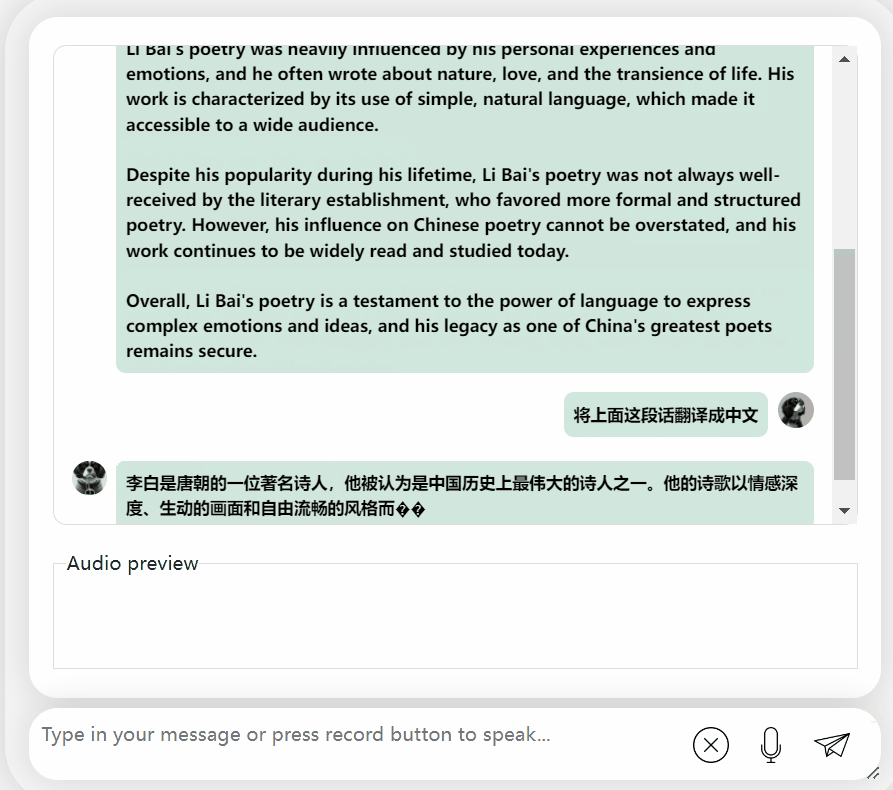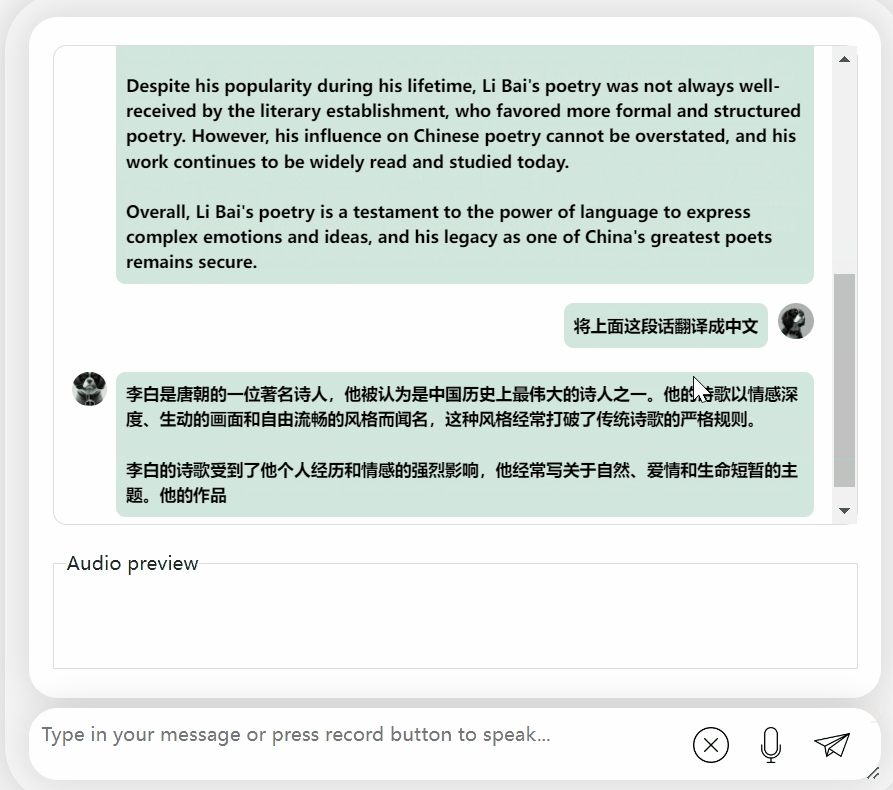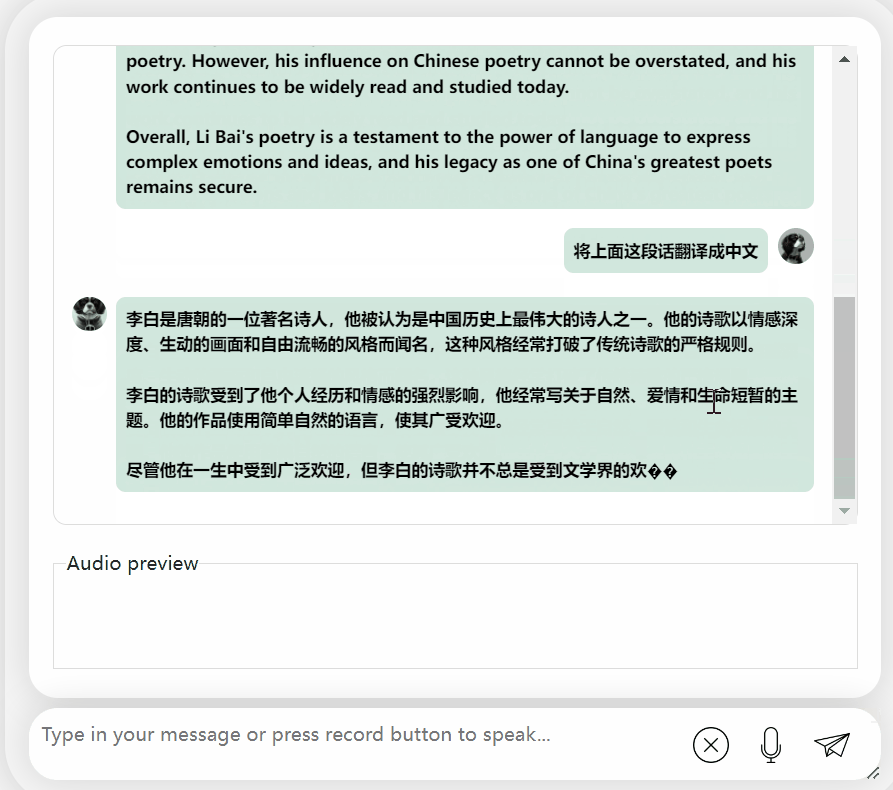
Lassen Sie uns zunächst eine kulturelle Kollision zwischen Chinesisch und Englisch betrachten und Li Bai auf Englisch bewerten:
 Bilder
Bilder
Es ist in Ordnung und beschreibt die Dynastie von Li Bai richtig. Wenn Sie kein Englisch lesen können, ist es kein Problem, es direkt ins Chinesische übersetzen zu lassen:
 Bilder
Bilder
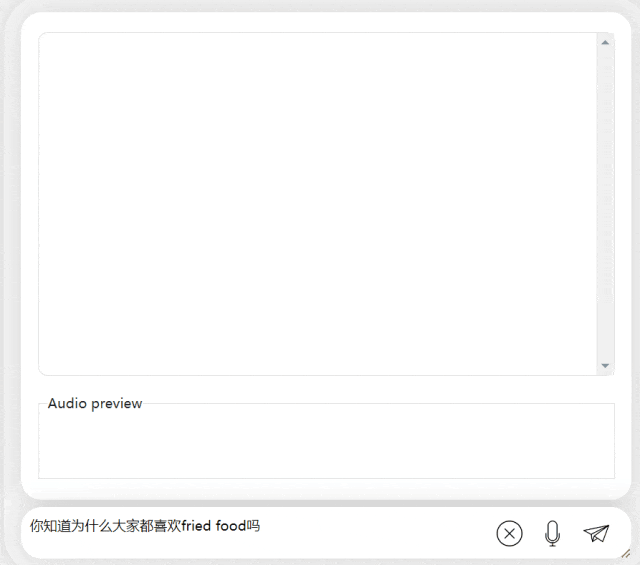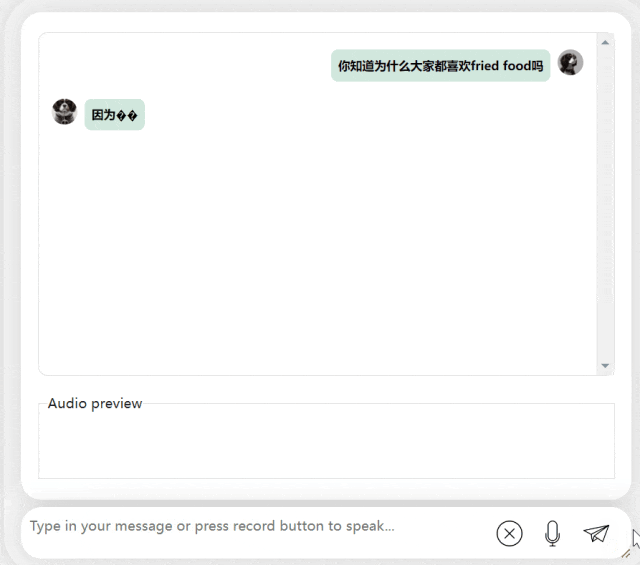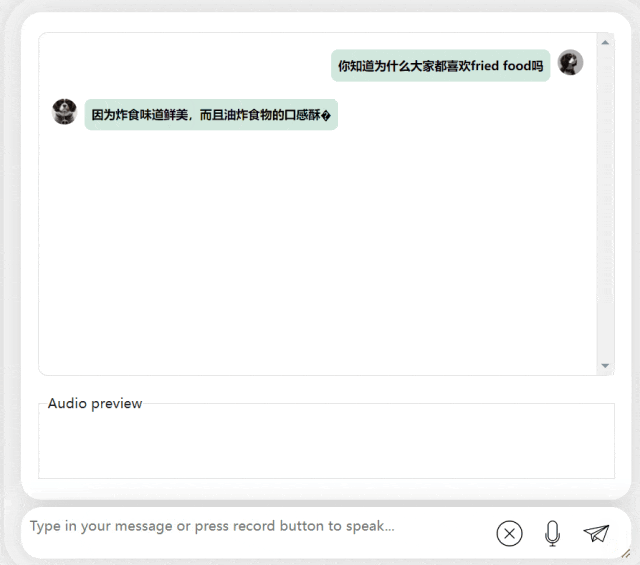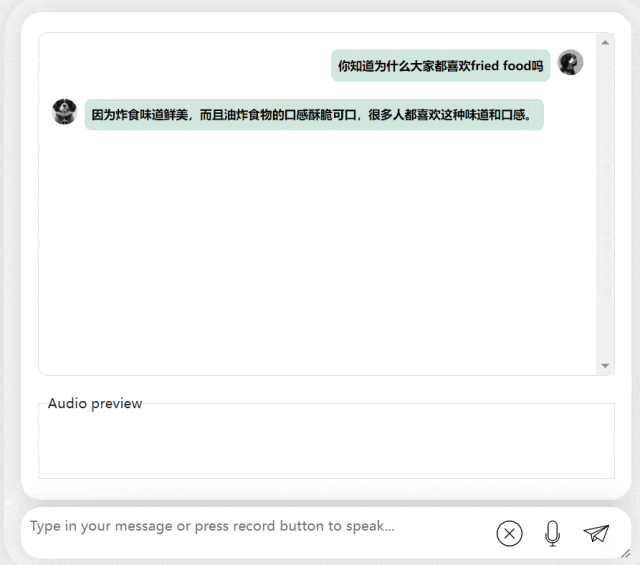
In der nächsten Übung versuchen wir es mit einer gemischten chinesisch-englischen Frage, indem wir das Wort „frittiertes Essen“ hinzufügen Chinesische Sätze. Der Ausgabeeffekt des Modells ist auch recht gut:
 Bilder
Bilder
Lassen Sie uns das Modell noch einmal ausprobieren und eine Bewertung durchführen, um zu sehen, welches besser ist, Li Bai oder Du Fu
Das lässt sich beobachten Nach einer Bedenkzeit gibt dieses Modell eine sehr objektive und neutrale Bewertung ab und verfügt auch über die Grundkenntnisse und den gesunden Menschenverstand, die für große Modelle erforderlich sind (manueller Hundekopf).
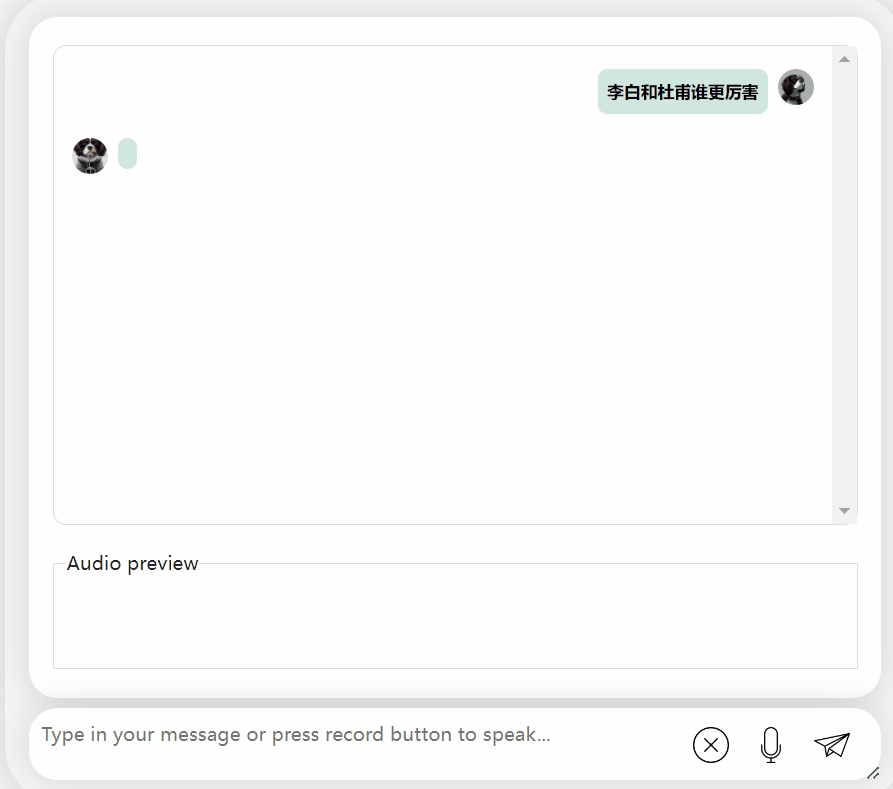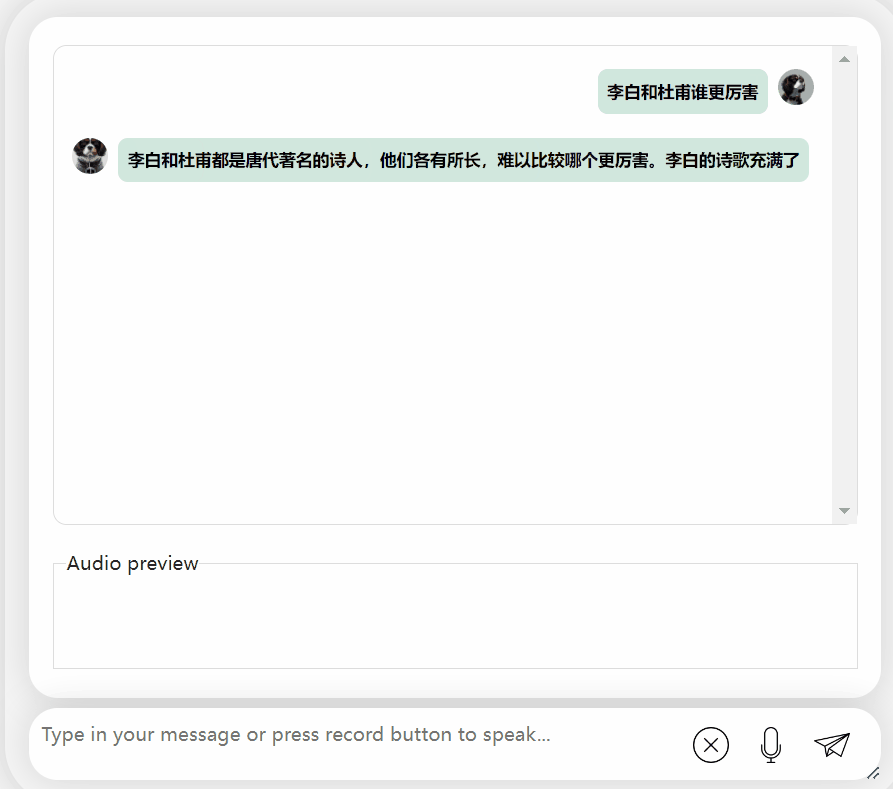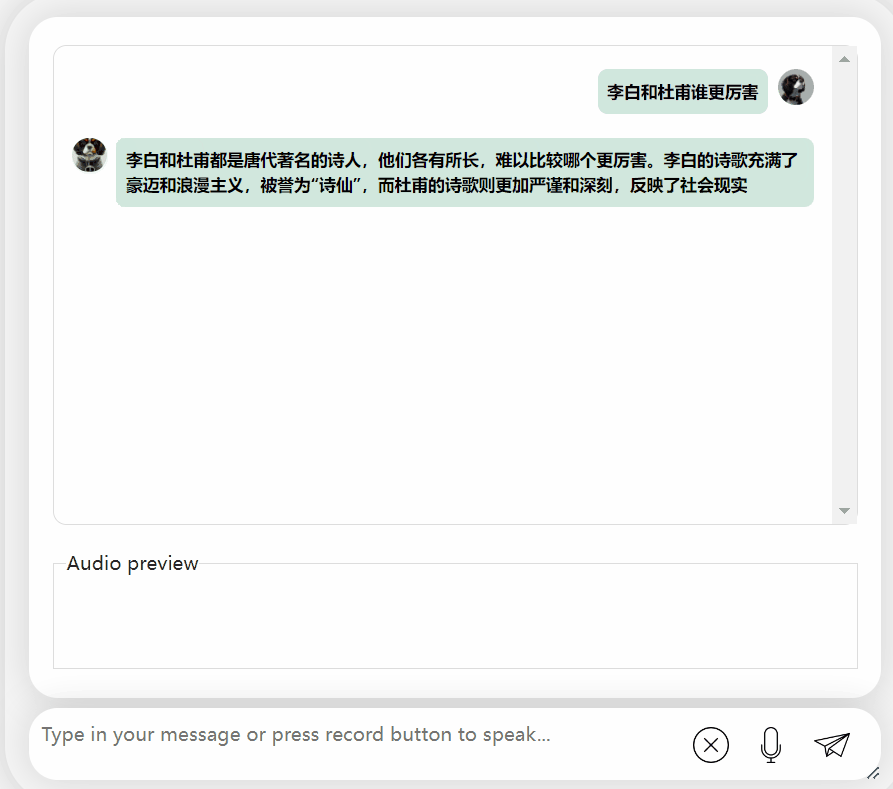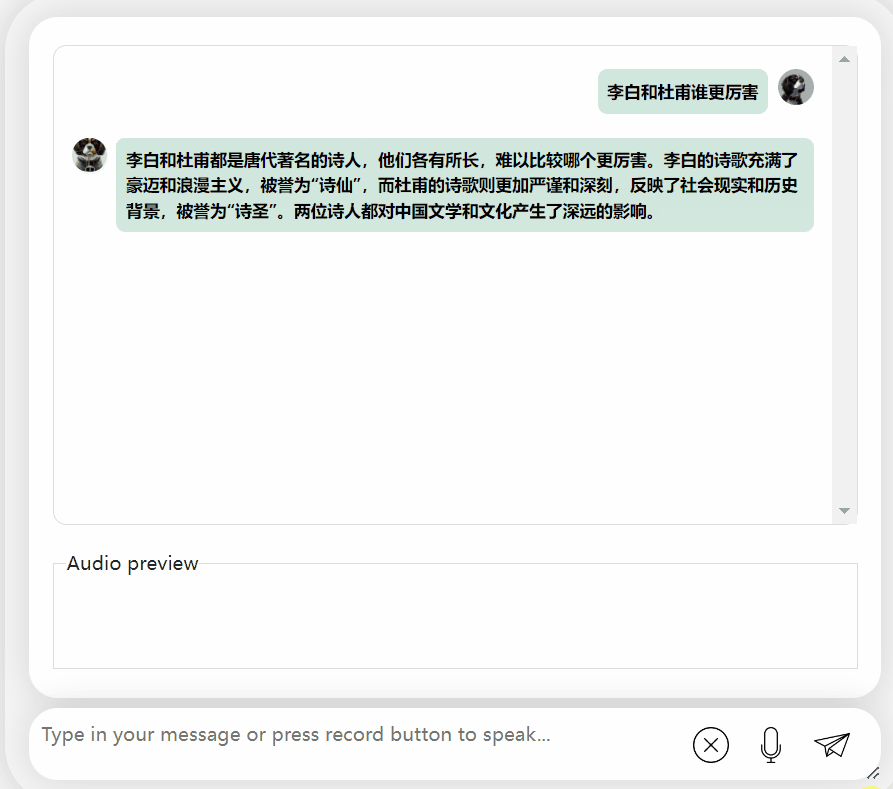 Bilder
Bilder
Natürlich kann es nicht gespielt werden nur auf Computern, sondern auch auf Mobiltelefonen.
Wir versuchen, „Empfehle mir ein Rezept“ per Spracheingabe einzugeben:
Sie können sehen, dass das Modell ein „Auberginenkäse“-Rezept genau ausgibt, aber ich weiß nicht, ob es gut schmeckt oder nicht.
Als wir es ausprobiert haben, stellten wir jedoch auch fest, dass dieses Modell manchmal Fehler aufweist.
Zum Beispiel versteht es manchmal die menschliche Sprache nicht sehr gut.
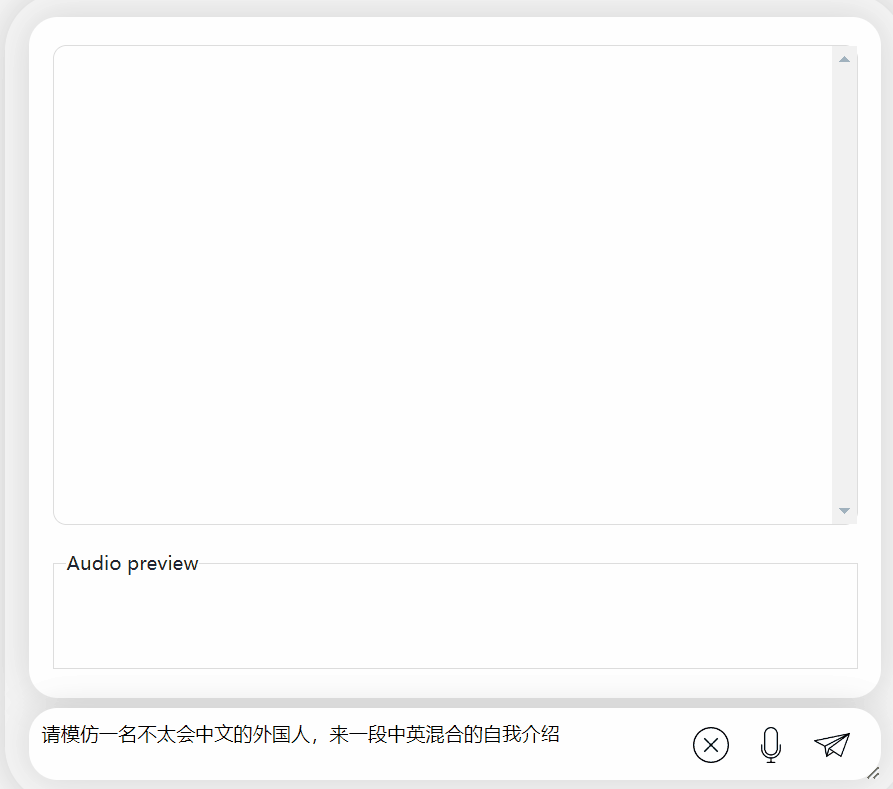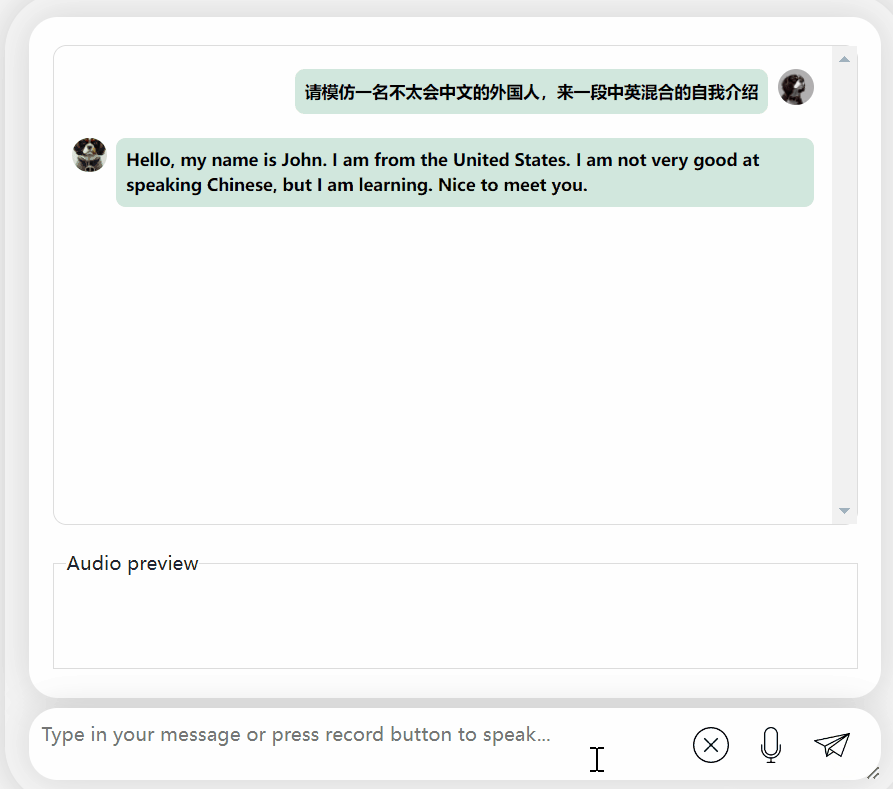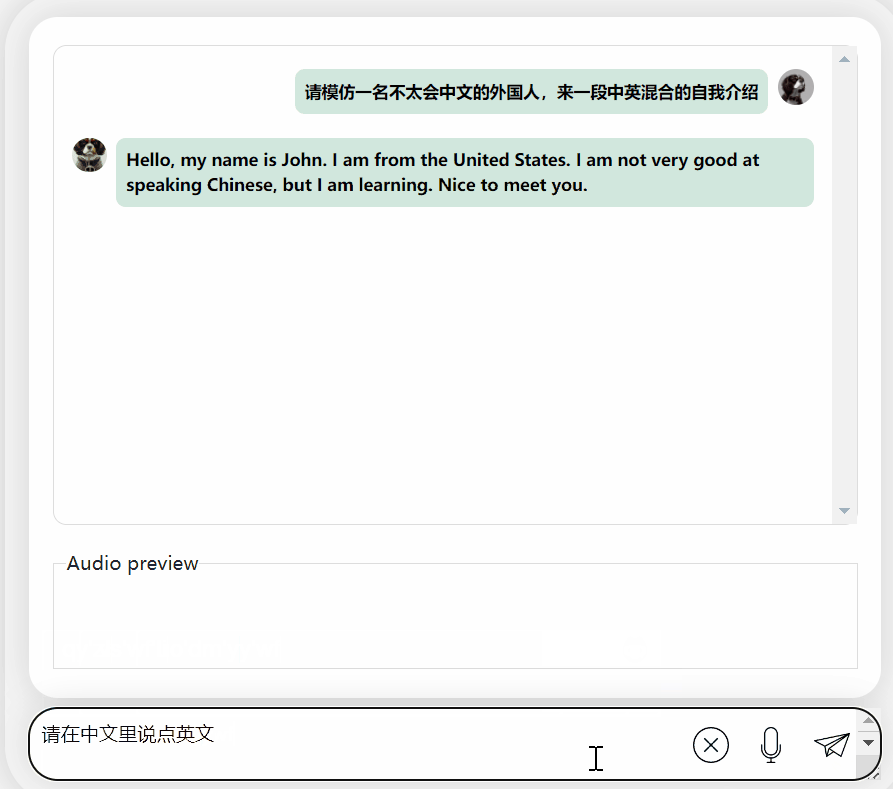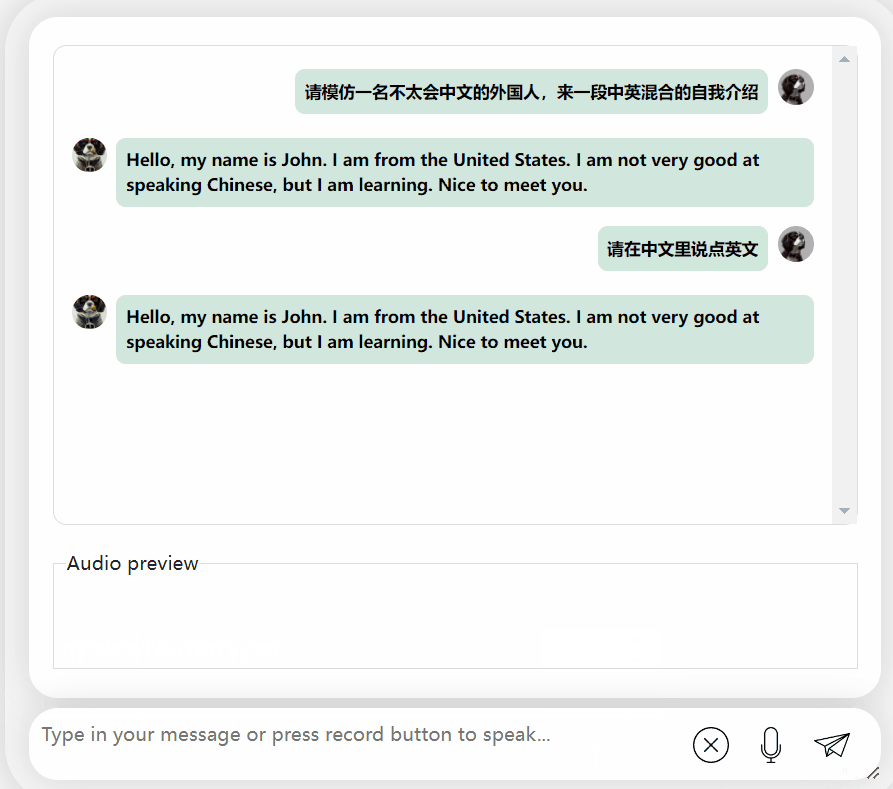
Aufgefordert, eine Mischung aus Chinesisch und Englisch auszugeben, gab es vor, es nicht zu verstehen und gab es auf Englisch aus:
 Bilder
Bilder
Als eine Mischung aus Chinesisch und Englisch fragte, ob es „Taylor Swift's Red“ hören wollte , das Modell hatte einen schwerwiegenden Fehler und gab immer wieder denselben Satz aus und konnte sogar nicht aufhören ...
 Bilder
Bilder
Insgesamt ist die Ausgabefähigkeit des Modells bei gemischten Fragen oder Wünschen in Chinesisch und Englisch immer noch nicht sehr gut.
Aber wenn man es trennt, ist seine Fähigkeit, Chinesisch und Englisch auszudrücken, immer noch gut.
Wie wird ein solches Modell umgesetzt?
Der Testversion zufolge verfügt LLaSM über zwei Hauptmerkmale: Zum einen unterstützt es die Eingabe von Chinesisch und Englisch, zum anderen die doppelte Eingabe von Sprache und Text.
Um diese beiden Punkte zu erreichen, müssen wir einige Anpassungen an der Architektur bzw. den Trainingsdaten vornehmen.
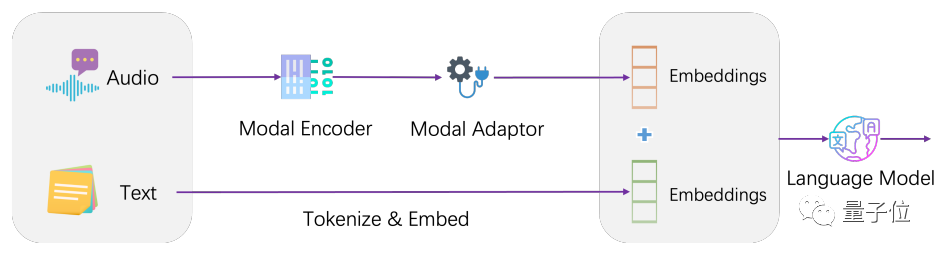
Architektonisch integriert LLaSM das aktuelle Spracherkennungsmodell und das große Sprachmodell.
LLaSM besteht aus drei Teilen, darunter dem automatischen Spracherkennungsmodell Whisper, dem Modaladapter und dem großen Modell LLaMA.
In diesem Prozess ist Whisper dafür verantwortlich, die ursprüngliche Spracheingabe zu empfangen und eine Vektordarstellung der Sprachmerkmale auszugeben. Die Rolle des Modaladapters besteht darin, Sprach- und Texteinbettungen auszurichten. LLaMA ist dafür verantwortlich, Sprach- und Texteingabeanweisungen zu verstehen und Antworten (
 Bilder) zu generieren. Das Training des Modells ist in zwei Phasen unterteilt. Der erste Schritt besteht darin, den Modalitätsadapter zu trainieren, wobei der Encoder und das große Modell eingefroren werden, sodass das Modell die Ausrichtung von Sprache und Text lernen kann. Die zweite Stufe besteht darin, den Encoder einzufrieren, Modaladapter und große Modelle zu trainieren, um die multimodalen Dialogfähigkeiten des Modells zu verbessern. Anhand der Trainingsdaten haben die Forscher eine Datenbank mit 199.000 Dialogen und 508.000 Sprachtextproben zusammengestellt -Audio-Anleitungen.
Bilder) zu generieren. Das Training des Modells ist in zwei Phasen unterteilt. Der erste Schritt besteht darin, den Modalitätsadapter zu trainieren, wobei der Encoder und das große Modell eingefroren werden, sodass das Modell die Ausrichtung von Sprache und Text lernen kann. Die zweite Stufe besteht darin, den Encoder einzufrieren, Modaladapter und große Modelle zu trainieren, um die multimodalen Dialogfähigkeiten des Modells zu verbessern. Anhand der Trainingsdaten haben die Forscher eine Datenbank mit 199.000 Dialogen und 508.000 Sprachtextproben zusammengestellt -Audio-Anleitungen.
Dies ist derzeit der größte chinesische und englische Sprachtext-Befehlsfolgedatensatz, der jedoch noch aussortiert wird. Nach Angaben der Forscher wird er nach der Aussortierung als Open Source verfügbar sein. 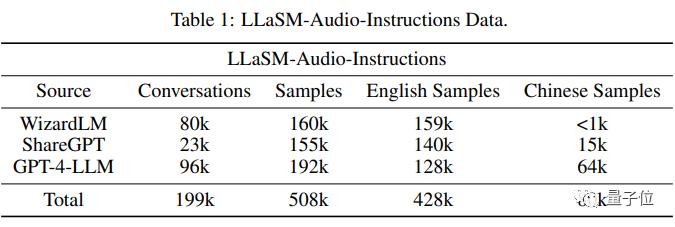 Allerdings gibt es derzeit keinen Vergleich der Ausgabeeffekte dieses Papiers mit anderen Sprachmodellen oder Textmodellen
Allerdings gibt es derzeit keinen Vergleich der Ausgabeeffekte dieses Papiers mit anderen Sprachmodellen oder Textmodellen
Als großes Modellunternehmen im Besitz von Kai-fu Lee haben auch Zero One und One World zu dieser Forschung beigetragen. Die Hugging Face-Seite des Autors Wenhao Huang zeigt, dass er seinen Abschluss an der Fudan-Universität gemacht hat. 
Papieradresse:  //m.sbmmt.com/link/47c917b09f2bc64b2916c0824c715923
//m.sbmmt.com/link/47c917b09f2bc64b2916c0824c715923
Demoadresse:
//m.sbmmt.com/ link/bcd 0049c35799cdf57d06eaf2eb3cff6
Das obige ist der detaillierte Inhalt vonIn China wird ein neues groß angelegtes Sprachdialogmodell eingeführt: unter der Leitung von Kai-Fu Lee, mit Beteiligung von Zero One and All, das chinesische und englische Zweisprachigkeit und Multimodalität unterstützt, Open Source und im Handel erhältlich ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So beheben Sie den Fehler aufgrund einer ungültigen MySQL-ID
So beheben Sie den Fehler aufgrund einer ungültigen MySQL-ID
 So löschen Sie leere Seiten in Word, ohne dass sich dies auf andere Formate auswirkt
So löschen Sie leere Seiten in Word, ohne dass sich dies auf andere Formate auswirkt
 js-Split-Nutzung
js-Split-Nutzung
 Verwendung der Stripslashes-Funktion
Verwendung der Stripslashes-Funktion
 So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
 Einführung in die Verwendung von vscode
Einführung in die Verwendung von vscode
 Linux fügt die Update-Quellenmethode hinzu
Linux fügt die Update-Quellenmethode hinzu
 Grundlegende Verwendung der Insert-Anweisung
Grundlegende Verwendung der Insert-Anweisung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



