


Kürzlich wurden mehrere Beiträge des Volcano Voice-Teams für Interspeech 2023 ausgewählt, die innovative Durchbrüche in verschiedenen Anwendungsrichtungen wie kurze Video-Spracherkennung, sprachübergreifende Klangfarbe und Stil sowie Beurteilung der mündlichen Sprachkompetenz behandeln. Interspeech ist eine der Top-Konferenzen im Bereich der Sprachforschung, die von der International Speech Communications Association (ISCA) organisiert wird. Sie gilt auch als die weltweit größte umfassende Veranstaltung zur Sprachsignalverarbeitung und hat bei Menschen im globalen Sprachbereich große Aufmerksamkeit erregt.

Interspeech2023Veranstaltungsseite
Datenerweiterung basierend auf zufälliger Satzverkettung zur Verbesserung der Kurzvideo-Spracherkennung (Random Utterance Concatenation Based Data Augmentation for Improving Short-video Speech. Recognition )
Normal Eine der Einschränkungen eines End-to-End-Frameworks zur automatischen Spracherkennung (ASR) besteht beispielsweise darin, dass seine Leistung beeinträchtigt werden kann, wenn die Längen der Trainings- und Testsätze nicht übereinstimmen. In diesem Artikel schlägt das Huoshan Speech-Team eine Datenverbesserungsmethode vor, die auf der sofortigen zufälligen Satzverkettung (RUC) als Front-End-Datenverbesserung basiert, um das Problem der Nichtübereinstimmung der Trainings- und Testsatzlänge bei kurzen Video-ASR-Aufgaben zu lindern.
Konkret stellte das Team fest, dass die folgenden Beobachtungen eine wichtige Rolle in der innovativen Praxis spielten: Typischerweise sind Trainingssätze aus kurzer Video-Spontansprache viel kürzer als von Menschen transkribierte Sätze (durchschnittlich etwa 3 Sekunden), während Trainingssätze aus Sprache trainiert werden Die vom Aktivitätserkennungs-Frontend generierten Testanweisungen sind viel länger (durchschnittlich etwa 10 Sekunden). Daher kann diese Nichtübereinstimmung zu einer schlechten Leistung führen
Das Volcano Speech-Team gab an, dass wir für empirische Zwecke ASR-Modelle mit mehreren Klassen aus 15 Sprachen verwendet haben. Die Datensätze für diese Sprachen umfassen 1.000 bis 30.000 Stunden. Während der Feinabstimmungsphase des Modells haben wir auch Daten hinzugefügt, die in Echtzeit aus mehreren Datenteilen abgetastet und gespleißt wurden. Im Vergleich zu den nicht erweiterten Daten erreicht diese Methode eine durchschnittliche Reduzierung der relativen Wortfehlerrate von 5,72 % über alle Sprachen hinweg.
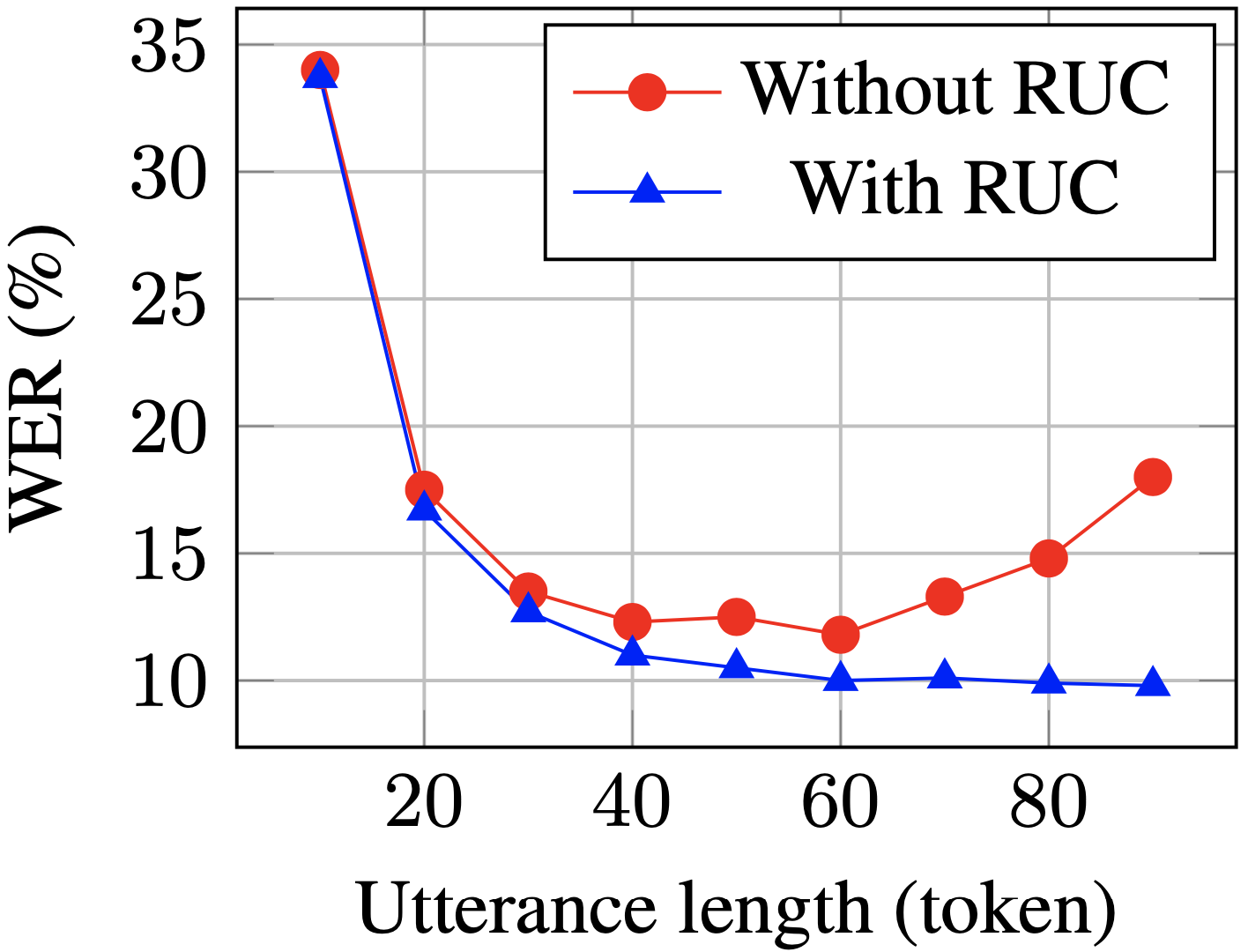
Die WER langer Sätze auf dem Testsatz wird nach dem Training mit RUC deutlich reduziert (blau vs. rot). )
Experimentellen Beobachtungen zufolge verbessert die RUC-Methode die Erkennungsfähigkeit langer Sätze deutlich, während die Leistung kurzer Sätze nicht abnimmt. Weitere Analysen ergaben, dass die vorgeschlagene Datenerweiterungsmethode die Empfindlichkeit des ASR-Modells gegenüber Längennormalisierungsänderungen verringern kann, was bedeuten kann, dass das ASR-Modell in verschiedenen Umgebungen robuster ist. Zusammenfassend lässt sich sagen, dass die RUC-Datenverbesserungsmethode zwar einfach zu bedienen ist, der Effekt jedoch erheblich ist.
Sprachkompetenzbewertung basierend auf phonetischem und prosodiebewusstem, selbstüberwachtem Lernansatz für die Bewertung nicht-muttersprachlicher Sprachkompetenz
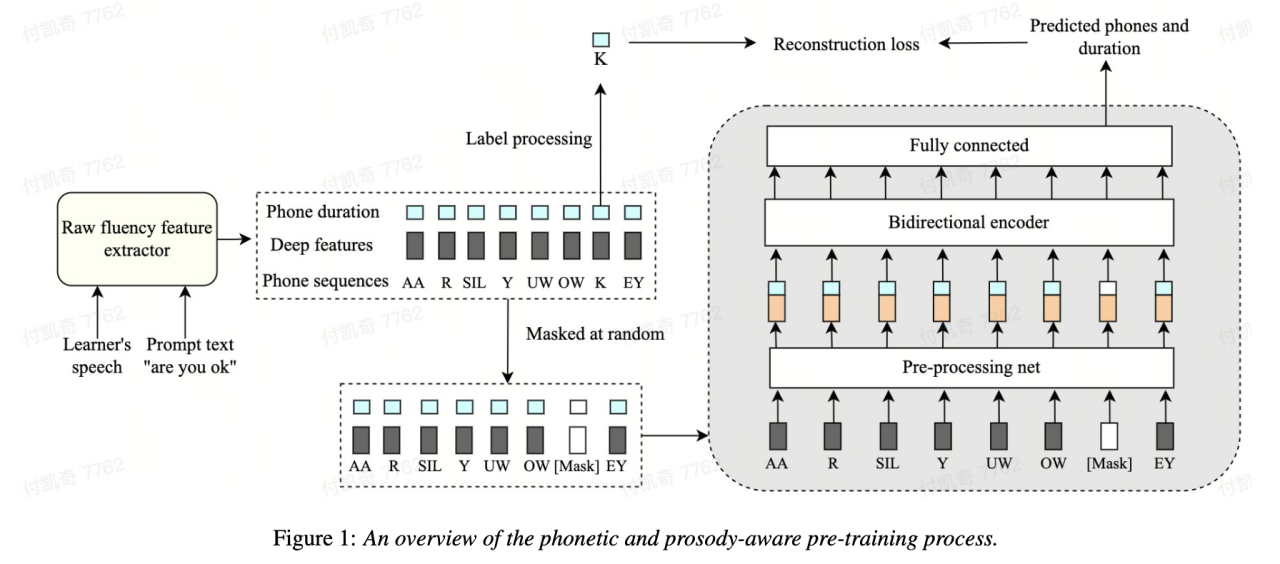
Einer der wichtigsten Punkte Der wichtigste Maßstab für die Bewertung der Sprachkenntnisse von Zweitsprachenlernern ist die mündliche Gewandtheit. Eine flüssige Aussprache zeichnet sich vor allem durch die Fähigkeit aus, Sprache leicht und normal wiederzugeben, ohne dass beim Sprechen viele abnormale Phänomene wie Pausen, Zögern oder Selbstkorrekturen auftreten. Die meisten Zweitsprachenlerner sprechen normalerweise langsamer und machen häufiger Pausen als Muttersprachler. Um die gesprochene Sprachkompetenz zu bewerten, schlug das Volcano Speech-Team eine selbstüberwachte Modellierungsmethode vor, die auf Sprache und Prosodie basiert. Insbesondere wurden in der Vortrainingsphase die Eingabesequenzmerkmale des Modells (akustische Merkmale, Phonem-IDs, Phonemdauer) ermittelt. wird maskiert, und die maskierten Merkmale werden in das Modell eingespeist, und der kontextbezogene Encoder wird verwendet, um die Phonem-ID und die Phonemdauerinformationen des maskierten Teils basierend auf den Timing-Informationen wiederherzustellen, sodass das Modell eine leistungsfähigere Sprache und Prosodik aufweist Darstellungsfähigkeiten.
Diese Lösung maskiert und rekonstruiert die drei Merkmale Originaldauer, Phonem und akustische Informationen im Sequenzmodellierungsrahmen, sodass die Maschine automatisch die Sprach- und Dauerdarstellung des Kontexts lernen kann, was besser für die Bewertung der Sprachkompetenz verwendet werden kann.
0,833, mit Die Korrelation zwischen Experten und Experten beträgt 0,831. Im Open-Source-Datensatz erreichte die Korrelation zwischen maschinellen Vorhersageergebnissen und menschlichen Expertenbewertungen 0,835, und die Leistung übertraf einige in der Vergangenheit für diese Aufgabe vorgeschlagene selbstüberwachte Methoden. In Bezug auf Anwendungsszenarien kann diese Methode auf Szenarien angewendet werden, die eine automatische Beurteilung der Sprachkompetenz erfordern, wie z. B. mündliche Prüfungen und verschiedene mündliche Online-Übungen.
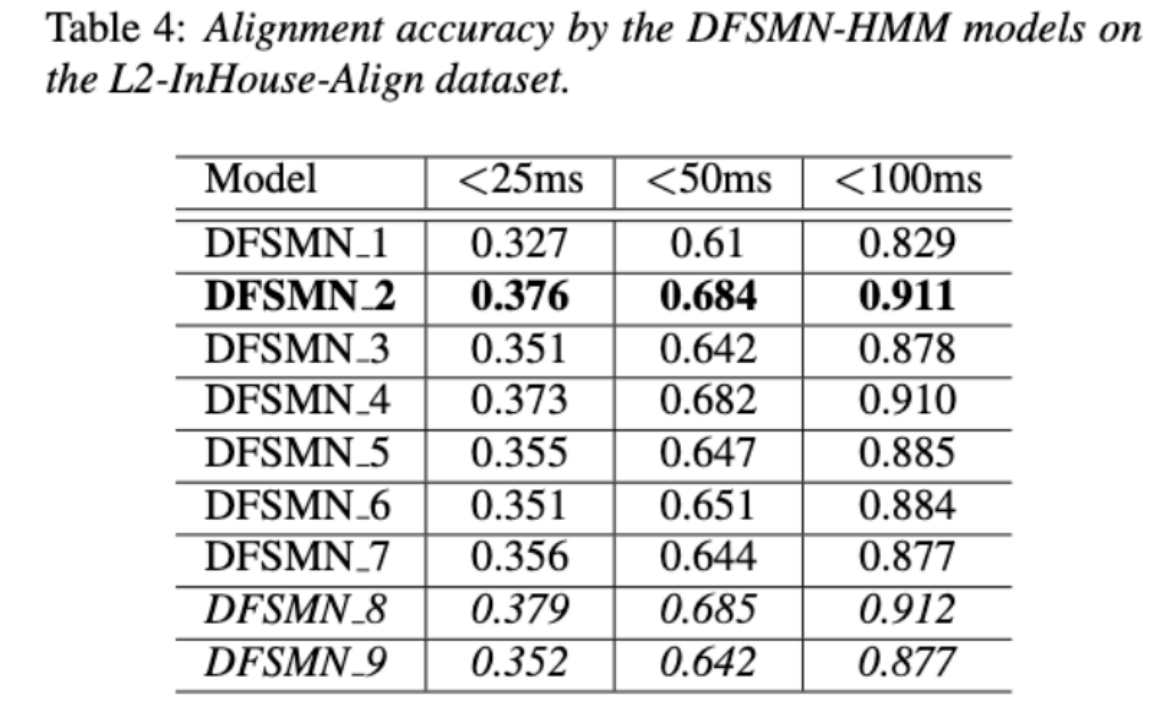
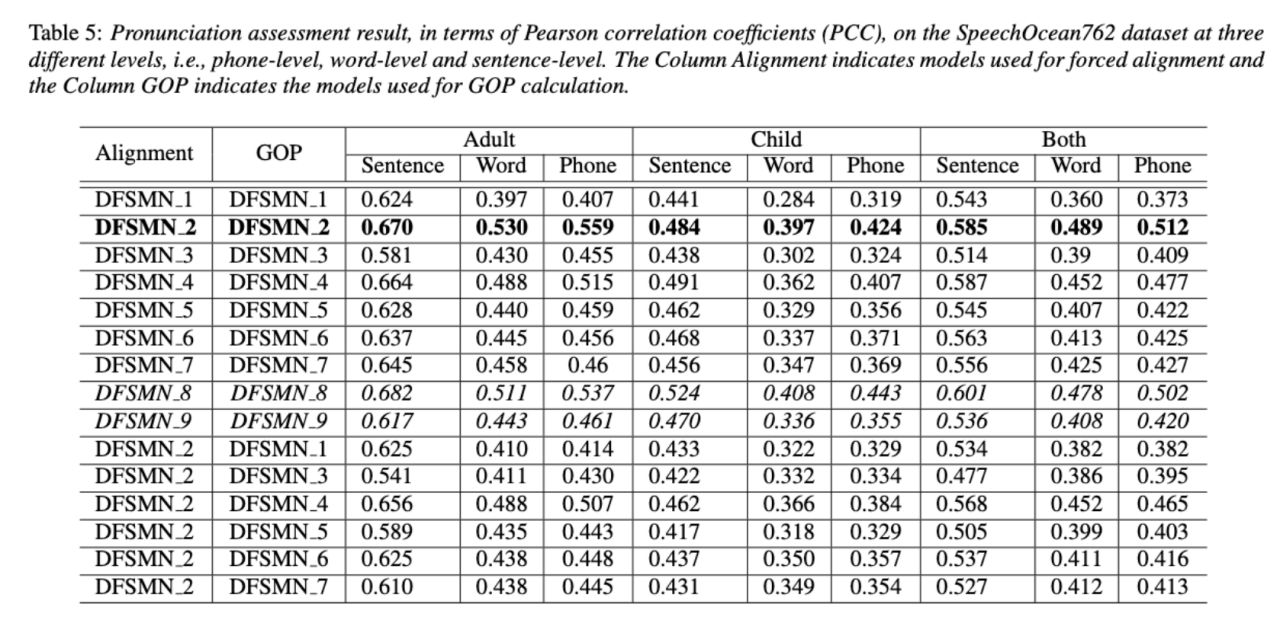
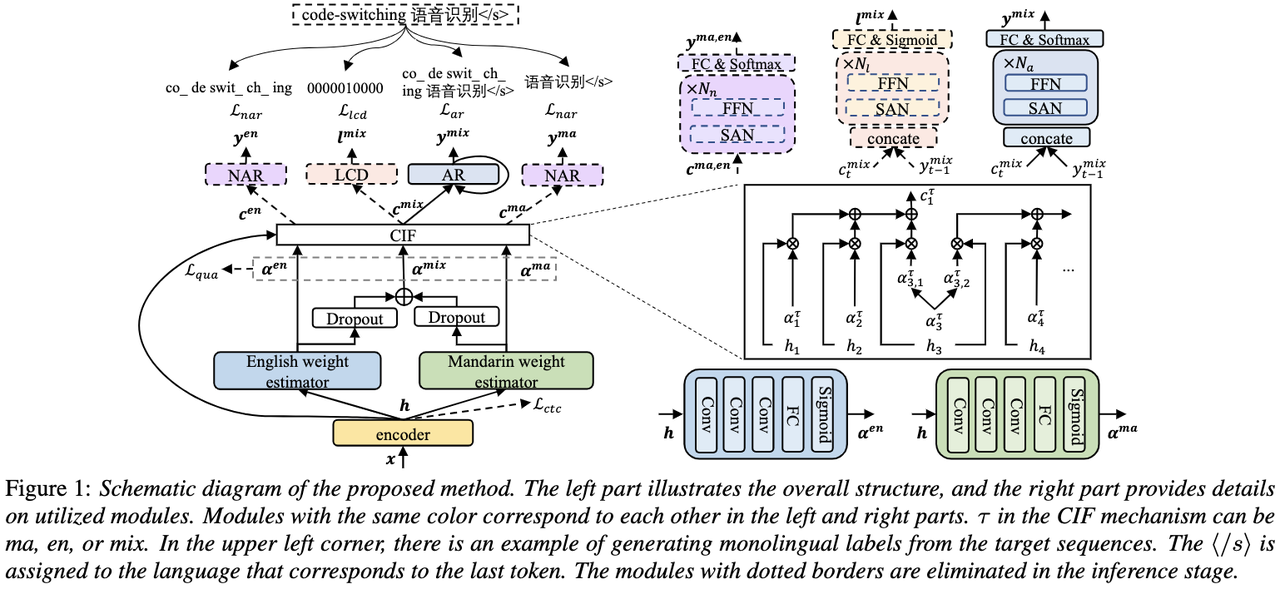
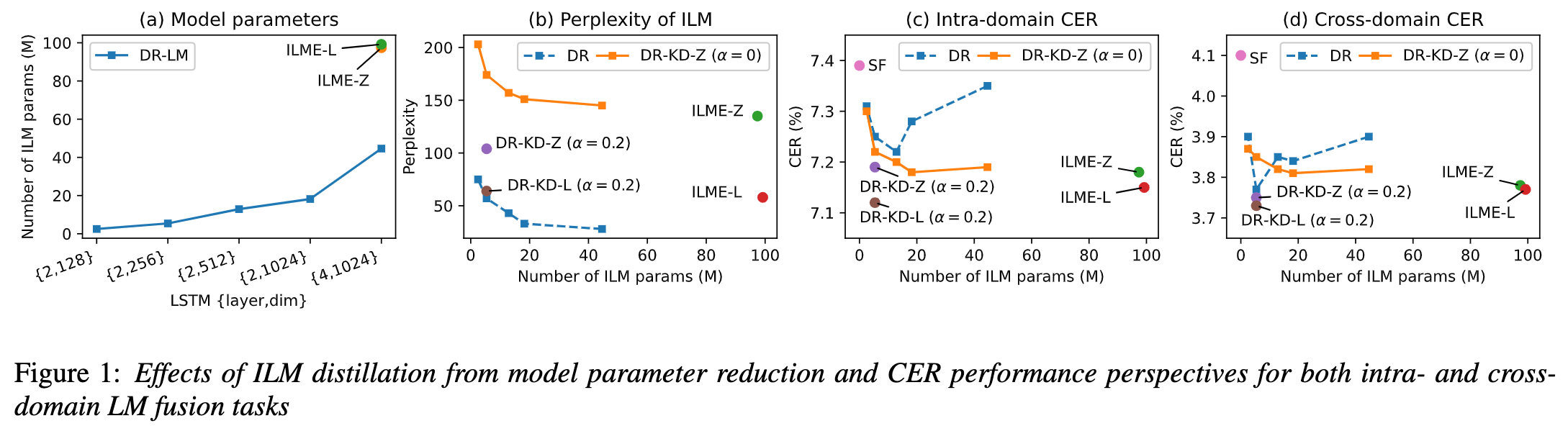
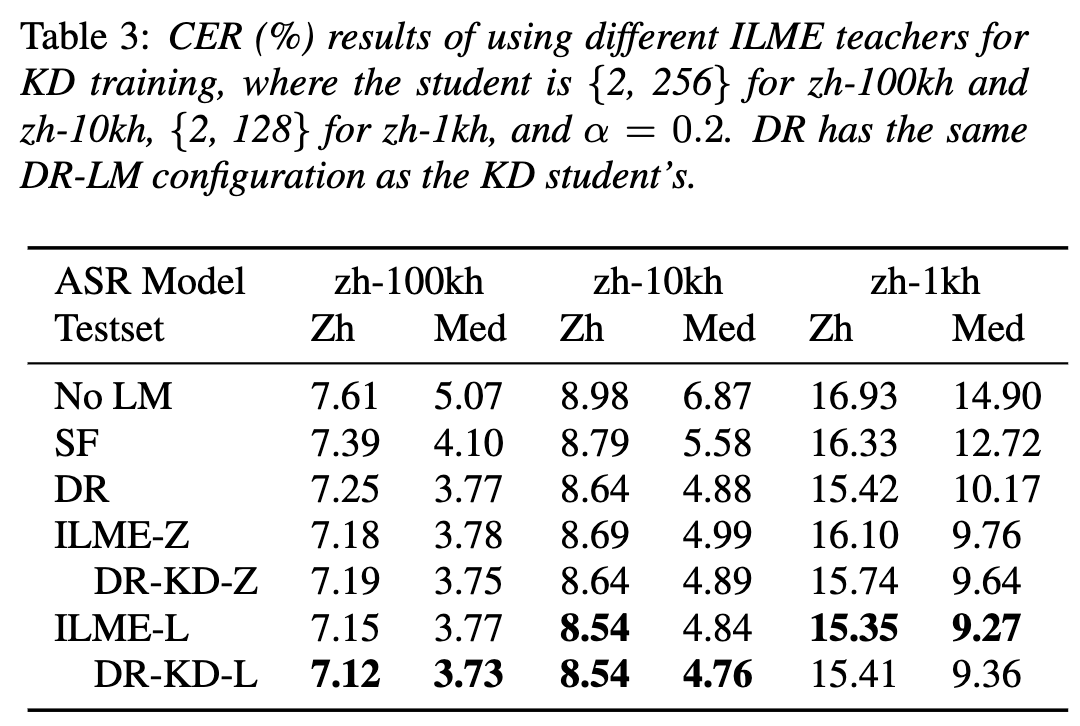
Entwirrung des Beitrags nicht-muttersprachlicher Sprache bei der automatisierten Aussprachebewertung(Entschlüsselung des Beitrags nicht-muttersprachlicher Sprache bei der automatisierten Aussprachebewertung) Eine Grundidee der nicht-muttersprachlichen Aussprachebewertung besteht darin, die Abweichung zwischen der Aussprache des Lernenden und der Aussprache des Muttersprachlers zu quantifizieren. Daher verwenden frühe akustische Modelle, die zur Aussprachebewertung verwendet werden, normalerweise nur Zielsprachendaten für das Training, aber einige neuere Studien haben damit begonnen Integration nicht-muttersprachlicher Aussprache in Daten wird in das Modelltraining integriert. Es besteht ein grundlegender Unterschied zwischen dem Zweck der Einbeziehung nicht-muttersprachlicher Sprache in die L2-ASR und der nicht-muttersprachlichen Beurteilung oder Erkennung von Aussprachefehlern: Das Ziel der ersteren besteht darin, das Modell so weit wie möglich an nicht-muttersprachliche Daten anzupassen, um eine optimale ASR zu erreichen Leistung; Letzteres erfordert ein Abwägen der beiden Perspektiven. Es gibt scheinbar widersprüchliche Anforderungen, das heißt eine höhere Erkennungsgenauigkeit nicht-muttersprachlicher Sprache und eine objektive Beurteilung des Ausspracheniveaus nicht-muttersprachlicher Aussprache. Das Volcano Speech-Team möchte den Beitrag nicht-muttersprachlicher Sprache zur Aussprachebewertung aus zwei verschiedenen Perspektiven untersuchen, nämlich der Ausrichtungsgenauigkeit und der Bewertungsleistung. Zu diesem Zweck haben sie beim Training akustischer Modelle unterschiedliche Datenkombinationen und Texttranskriptionsformen entworfen, wie in der Abbildung oben gezeigt. Die beiden obigen Tabellen zeigen jeweils die Ausrichtungsgenauigkeit und Bewertung der Leistung verschiedener Kombinationen akustischer Modelle . Experimentelle Ergebnisse zeigen, dass die ausschließliche Verwendung nicht-muttersprachlicher Sprachdaten mit manuell annotierten Phonemsequenzen während des akustischen Modelltrainings die Ausrichtung nicht-muttersprachlicher Sprache und die höchste Genauigkeit bei der Aussprachebewertung ermöglicht. Insbesondere das Mischen von halb muttersprachlichen Daten und halb nicht-muttersprachlichen Daten (von Menschen annotierte Phonemsequenzen) im Training kann etwas schlechter sein, ist aber vergleichbar mit der Verwendung nur von nicht-muttersprachlichen Daten mit von Menschen annotierten Phonemsequenzen. Darüber hinaus schneidet der obige gemischte Fall besser ab, wenn die Aussprache anhand muttersprachlicher Daten bewertet wird. Bei begrenzten Ressourcen verbesserte das Hinzufügen von 10 Stunden nicht-muttersprachlicher Daten die Ausrichtungsgenauigkeit und Bewertungsleistung im Vergleich zum akustischen Modelltraining, bei dem nur muttersprachliche Daten verwendet wurden, erheblich, unabhängig vom verwendeten Texttranskriptionstyp. Diese Forschung hat wichtige Leitbedeutung für Datenanwendungen im Bereich der Sprachauswertung. Bei der End-to-End-Spracherkennung ist die Lösung des Zeitstempelproblems durch Nicht-Peak-CTC-Optimierungsrahmenklassifikator ( End-to-End-Systeme im Bereich der automatischen Spracherkennung (ASR) haben eine mit Hybridsystemen vergleichbare Leistung gezeigt. Als Nebenprodukt von ASR sind Zeitstempel in vielen Anwendungen von entscheidender Bedeutung, insbesondere in Szenarien wie der Untertitelgenerierung und dem rechnergestützten Aussprachetraining. Ziel dieses Artikels ist es, den Klassifikator auf Frame-Ebene in einem End-to-End-System zu optimieren, um Zeitstempel zu erhalten. . In diesem Zusammenhang führte das Team die Verwendung von CTC-Verlusten (konnektionistische zeitliche Klassifizierung) ein, um den Klassifikator auf Frame-Ebene zu trainieren, und führte Label-Prior-Informationen ein, um das Spike-Phänomen von CTC zu lindern. Außerdem wurde die Ausgabe des Mel-Filters mit dem ASR kombiniert Encoder als Eingabefunktionen. In internen chinesischen Experimenten erreichte diese Methode eine Genauigkeit von 95,68 %/94,18 % im Wortzeitstempel von 200 ms, während das traditionelle Hybridsystem nur 93,0 %/90,22 % erreichte. Darüber hinaus erreichte das Team im Vergleich zum vorherigen End-to-End-Ansatz eine absolute Leistungsverbesserung von 4,80 %/8,02 % in den 7 internen Sprachen. Die Genauigkeit des Wort-Timings wird auch durch einen Ansatz zur Wissensdestillation Bild für Bild weiter verbessert, obwohl dieses Experiment nur für LibriSpeech durchgeführt wurde. Die Ergebnisse dieser Studie zeigen, dass die Zeitstempelleistung in End-to-End-Spracherkennungssystemen durch die Einführung von Label-Priors und die Zusammenführung verschiedener Funktionsebenen effektiv optimiert werden kann. In internen chinesischen Experimenten hat diese Methode erhebliche Verbesserungen im Vergleich zu Hybridsystemen und früheren End-to-End-Methoden erzielt. Darüber hinaus zeigt die Methode durch die Anwendung von Wissensdestillationsmethoden offensichtliche Vorteile Timing-Genauigkeit. Diese Ergebnisse sind nicht nur von großer Bedeutung für Anwendungen wie die Generierung von Untertiteln und das Training der Aussprache, sondern liefern auch nützliche Erkundungsrichtungen für die Entwicklung automatischer Spracherkennungstechnologie. Chinesisch-Englisch gemischte Spracherkennung basierend auf sprachspezifischem akustischem Grenzlernen (Sprachspezifisches akustisches Grenzlernen für Mandarin-Englisch Code-Switching Speech Recognition Umgeschriebener Inhalt: Wie wir alle wissen, Code Switching (Das Hauptziel von CS) besteht darin, eine effektive Kommunikation zwischen verschiedenen Sprachen oder technischen Bereichen zu ermöglichen. CS erfordert die abwechselnde Verwendung von zwei oder mehr Sprachen in einem Satz. Das Zusammenführen von Wörtern oder Phrasen aus mehreren Sprachen kann jedoch zu Fehlern und Verwirrung bei der Spracherkennung führen, was die Code-Switched-Speech-Erkennung (CSSR) zu einer größeren Herausforderung macht Missionen Übliche End-to-End-ASR-Modelle bestehen aus Encodern, Decodern und Ausrichtungsmechanismen. Die meisten der vorhandenen End-to-End-CSASR-Modelle konzentrieren sich nur auf die Optimierung der Encoder- und Decoderstrukturen und diskutieren selten, ob ein sprachbezogenes Design des Ausrichtungsmechanismus erforderlich ist. Die meisten vorhandenen Arbeiten verwenden eine Mischung aus Mandarin-Schriftzeichen und englischen Unterwörtern als Modellierungseinheiten für gemischte chinesische und englische Szenarien. Mandarin-Schriftzeichen stellen in der Regel einzelne Silben in Mandarin dar und haben klare akustische Grenzen, während englische Unterwörter ohne Bezug zu akustischen Kenntnissen erhalten werden, sodass ihre akustischen Grenzen unscharf sein können. Um im CSASR-System gute akustische Grenzen (Alignment) zwischen Mandarin und Englisch zu erhalten, ist sprachbezogenes Lernen akustischer Grenzen unbedingt erforderlich. Daher haben wir das CIF-Modell verbessert und eine sprachdifferenzierte Lernmethode für akustische Grenzen für die CSASR-Aufgabe vorgeschlagen. Einzelheiten zur Modellarchitektur finden Sie in der folgenden Abbildung. Das Modell besteht aus sechs Komponenten, nämlich dem Encoder, dem sprachdifferenzierten Gewichtsschätzer (LSWE), dem CIF-Modul, dem autoregressiven (AR) Decoder und der nicht automatischen Regression ( NAR-Decoder und Sprachänderungserkennungsmodul (LCD). Der Berechnungsprozess des Encoders, des autoregressiven Decoders und des CIF ist der gleiche wie bei der ursprünglichen CIF-basierten ASR-Methode. Der sprachspezifische Gewichtsschätzer ist für die Vervollständigung der Modellierung sprachunabhängiger akustischer Grenzen verantwortlich und Das Modul zur Erkennung von Sprachänderungen (Language Change Detection, LCD) soll das Modelltraining unterstützen und wird in der Dekodierungsphase nicht mehr beibehalten. Experimentelle Ergebnisse zeigen, dass diese Methode bei den beiden Testsätzen des Open-Source-Chinesisch-Englischens neue Ergebnisse erzielt hat Gemischter Datensatz SEAME. Die SOTA-Effekte betragen 16,29 % bzw. 22,81 % MER. Um die Wirkung dieser Methode auf größere Datenmengen weiter zu verifizieren, führte das Team Experimente mit einem internen Datensatz von 9.000 Stunden durch und erreichte schließlich einen relativen MER-Gewinn von 7,9 %. Es versteht sich, dass dieses Papier auch die erste Arbeit zum akustischen Grenzlernen zur Sprachdifferenzierung in der CSASR-Aufgabe ist. USTR : Domain Adaptation (Text-only Domain Adaptation using Unified Speech-Text Representation in Transducer)Wie wir alle wissen, Domänenmigration war schon immer eine sehr wichtige Aufgabe in ASR, aber das Erhalten gepaarter Sprachdaten in der Zieldomäne ist sehr zeitaufwändig und kostspielig. Daher verwenden viele Arbeiten Textdaten, die sich auf die Zieldomäne beziehen, um den Erkennungseffekt zu verbessern. Unter den traditionellen Methoden erhöht TTS den Trainingszyklus und die Speicherkosten der zugehörigen Daten, während Methoden wie ILME und Shallow Fusion die Komplexität der Inferenz erhöhen. Basierend auf dieser Aufgabe teilte das Team den Encoder in einen Audio-Encoder und einen Shared Encoder auf, der auf RNN-T basiert, und führte einen Text-Encoder ein, um die Darstellung von Sprache und Text mithilfe von RNN-T zu erlernen. Der T-Verlust für das Training wird USTR (Unified Speech-Text Representation) genannt. „Für den Text-Encoder-Teil haben wir verschiedene Arten von Darstellungen untersucht, darunter Zeichenfolge, Phone-Sequenz und Unterwort-Sequenz. Die Endergebnisse zeigten, dass die Phone-Sequenz die beste Wirkung hat. Was die Trainingsmethode betrifft, wird in diesem Artikel die Methode untersucht Basierend auf der gegebenen RNN-Mehrschritt-Trainingsmethode des T-Modells und der Einzelschritt-Trainingsmethode mit vollständig zufälliger Initialisierung „ Konkret verwendete das Team den LibriSpeech-Datensatz als Quelldomäne und verwendete den kommentierten Text von SPGISpeech als Klartext für das Domänenmigrationsexperiment. Experimentelle Ergebnisse zeigen, dass der Effekt dieser Methode im Zielbereich im Wesentlichen derselbe sein kann wie der von TTS. Der Effekt ist im Wesentlichen derselbe wie bei Multi-Step Die USTR-Methode kann die Leistung von Plug-in-Sprachmodellen wie ILME Combined weiter verbessern, selbst wenn LM denselben Texttrainingskorpus verwendet. Schließlich erreichte diese Methode auf dem Zieldomänen-Testsatz ohne Kombination externer Sprachmodelle einen relativen Rückgang von 43,7 % im Vergleich zum Basis-WER von 23,55 % -> 13,25 %. Obwohl sich die interne Sprachmodellschätzung (Internal Language Model Estimation, ILME) bei der End-to-End-ASR-Sprachmodellfusion bewährt hat, führt ILME im Vergleich zur herkömmlichen Shallow-Fusion zusätzlich die Berechnung interner Sprachmodelle ein, was die Inferenzkosten erhöht. Um das interne Sprachmodell abzuschätzen, ist eine zusätzliche Vorwärtsberechnung basierend auf dem ASR-Decoder erforderlich, oder es wird ein unabhängiges Sprachmodell (DR-LM) trainiert, indem der ASR-Trainingssatztext basierend auf der Density Ratio-Methode als interne Sprache verwendet wird. Modellnäherung. Die auf dem ASR-Decoder basierende ILME-Methode kann normalerweise eine bessere Leistung erzielen als die Dichteverhältnismethode, da sie ASR-Parameter direkt zur Schätzung verwendet. Ihr Berechnungsumfang hängt jedoch von der Parametermenge des ASR-Decoders ab dass es durch gesteuert werden kann. Die Größe von DR-LM ermöglicht eine effiziente Schätzung des internen Sprachmodells. Aus diesem Grund schlug das Volcano Voice-Team vor, die auf dem ASR-Decoder basierende ILME-Methode als Lehrer im Rahmen der Dichteverhältnismethode zu verwenden, um DR-LM zu destillieren und zu lernen, wodurch die Rechenkosten von ILME bei gleichzeitiger Aufrechterhaltung erheblich gesenkt werden die Leistung von ILME. Experimentelle Ergebnisse zeigen, dass diese Methode 95 % der internen Sprachmodellparameter reduzieren kann und in der Leistung mit der auf dem ASR-Decoder basierenden ILME-Methode vergleichbar ist. Wenn als Lehrer die ILME-Methode mit besserer Leistung verwendet wird, kann das entsprechende Schülermodell auch bessere Ergebnisse erzielen. Im Vergleich zur herkömmlichen Dichteverhältnismethode mit einem ähnlichen Berechnungsumfang weist diese Methode in Szenarien mit hohem Ressourcenaufwand eine etwas bessere Leistung auf. In Szenarios mit domänenübergreifender Migration mit geringen Ressourcen kann der CER-Gewinn 8 % erreichen und ist robuster Fusionsgewichte GenerTTS: Ausspracheentflechtung für die Verallgemeinerung von Klangfarbe und Stil in der sprachübergreifenden Text-zu-Sprache Die sprachübergreifende Klang- und Stilgeneralisierbare Sprachsynthese (TTS) zielt darauf ab, Sprache mit einer bestimmten Referenzklangfarbe zu synthetisieren oder Stil, der nicht in der Zielsprache trainiert wurde. Es steht vor Herausforderungen wie der Schwierigkeit, Klangfarbe und Aussprache zu trennen, da es oft schwierig ist, mehrsprachige Sprachdaten für einen bestimmten Sprecher zu erhalten, und die Aussprache ist gemischt, da der Sprachstil sowohl sprachunabhängige als auch sprachabhängige Teile enthält. Um diese Herausforderungen anzugehen, hat das Volcano Voice-Team GenerTTS vorgeschlagen. Sie haben sorgfältig HuBERT-basierte Informationsengpässe entworfen, um die Verbindung zwischen Klangfarbe und Aussprache/Stil zu entkoppeln. Gleichzeitig eliminieren sie auch sprachspezifische Informationen in Stilen, indem sie die gegenseitige Information zwischen Stilen und Sprachen minimieren. Experimente beweisen, dass GenerTTS Basissysteme in Bezug auf Stilähnlichkeit und Aussprachegenauigkeit übertrifft Es wird eine Generalisierbarkeit über Sprachklangfarben und -stile hinweg erreicht. Das Volcano Voice-Team hat den internen Geschäftsbereichen von ByteDance stets hochwertige Sprach-KI-Technologiefunktionen und Full-Stack-Sprachproduktlösungen bereitgestellt und über die Volcano-Engine externe Dienste bereitgestellt. Seit seiner Gründung im Jahr 2017 konzentriert sich das Team auf die Forschung und Entwicklung branchenführender intelligenter KI-Sprachtechnologie und erforscht ständig die effiziente Kombination von KI und Geschäftsszenarien, um einen größeren Benutzernutzen zu erzielen. 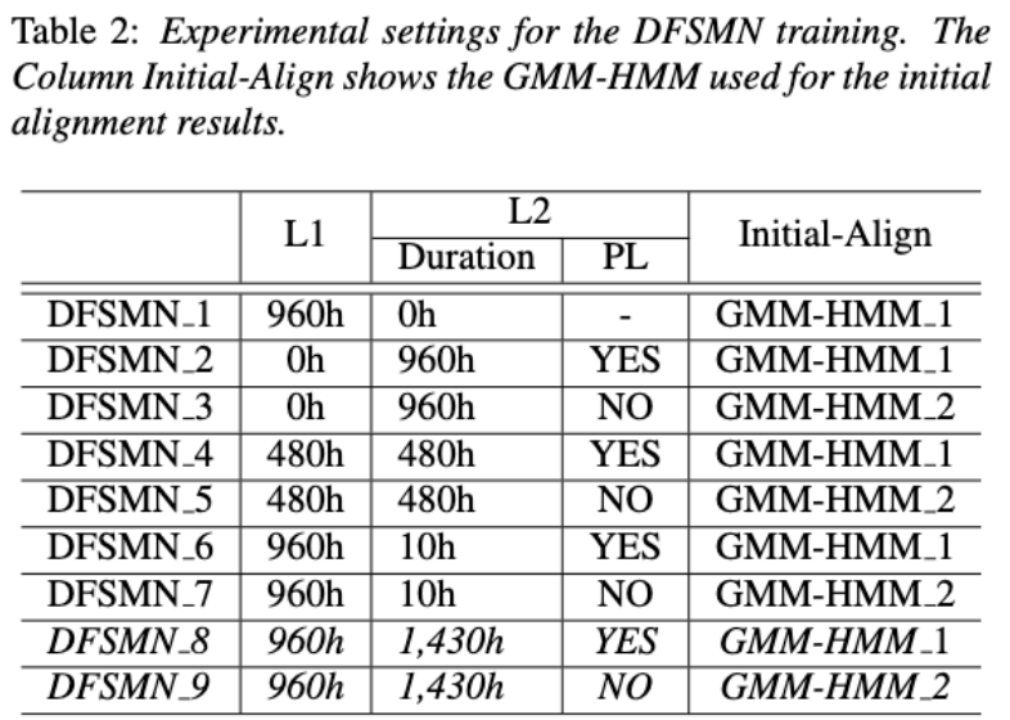

 ASR basierend auf einheitlicher Darstellung und Klartext
ASR basierend auf einheitlicher Darstellung und Klartext 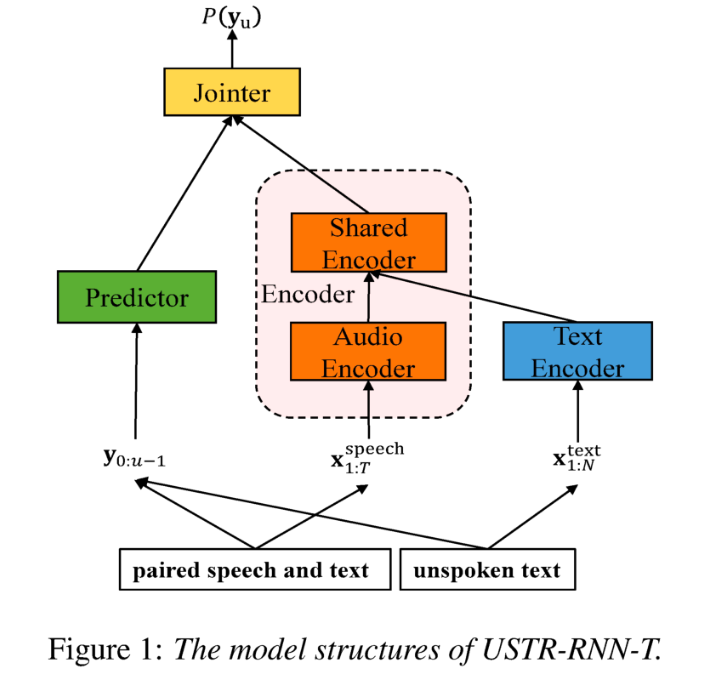
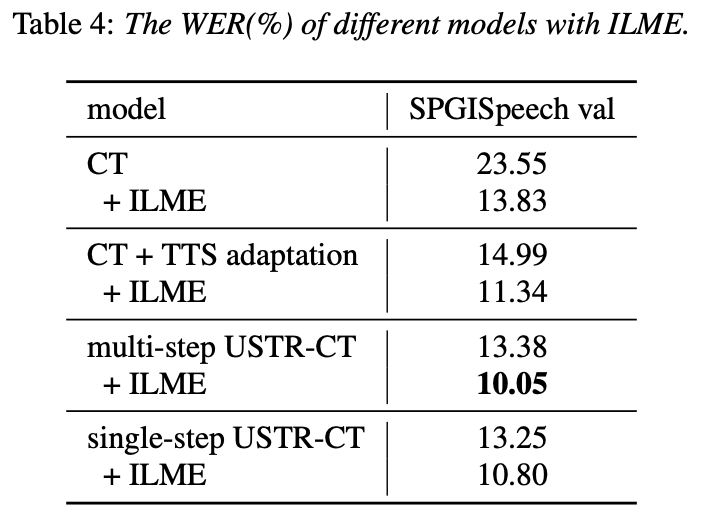
Das obige ist der detaillierte Inhalt vonFür Interspeech 2023 wurden mehrere Beiträge ausgewählt, und Huoshan Speech löste effektiv viele Arten praktischer Probleme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 vim-Befehl zum Speichern und Beenden
vim-Befehl zum Speichern und Beenden
 So wechseln Sie auf dem Laptop in den abgesicherten Modus
So wechseln Sie auf dem Laptop in den abgesicherten Modus
 Wie wurde der Name von tt voice geändert?
Wie wurde der Name von tt voice geändert?
 Was ist der Baidu-Index?
Was ist der Baidu-Index?
 Was sind die Befehle zur Datenträgerbereinigung?
Was sind die Befehle zur Datenträgerbereinigung?
 Was bedeutet Harmonios?
Was bedeutet Harmonios?
 Drei häufig verwendete Kodierungsmethoden
Drei häufig verwendete Kodierungsmethoden
 Befehl zum Neustart der Netzwerkkarte unter Linux
Befehl zum Neustart der Netzwerkkarte unter Linux








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



