


In den letzten Jahren hat das visuelle Vortraining auf großen realen Daten erhebliche Fortschritte gemacht und zeigt ein großes Potenzial für das auf Pixelbeobachtung basierende Roboterlernen. Diese Studien unterscheiden sich jedoch hinsichtlich der Daten, Methoden und Modelle vor dem Training. Daher ist es immer noch eine offene Frage, welche Art von Daten, Pre-Training-Methoden und Modellen die Robotersteuerung besser unterstützen können Drei grundlegende Perspektiven von Trainingsmethoden untersuchten umfassend die Auswirkungen visueller Vortrainingsstrategien auf Roboterbetriebsaufgaben und lieferten einige wichtige experimentelle Ergebnisse, die für das Roboterlernen von Vorteil sind. Darüber hinaus schlugen sie ein visuelles Vortrainingsschema für die Roboterbedienung namens
Vi-PRoM vor, das selbstüberwachtes Lernen und überwachtes Lernen kombiniert.Ersteres nutzt kontrastives Lernen, um latente Muster aus großen, unbeschrifteten Daten zu erhalten, während letzteres darauf abzielt, visuelle Semantik und zeitliche dynamische Veränderungen zu lernen. Eine Vielzahl von Experimenten zum Roboterbetrieb, die in verschiedenen Simulationsumgebungen und an realen Robotern durchgeführt wurden, haben die Überlegenheit dieser Lösung bewiesen.
 Papieradresse: https://arxiv.org/pdf/2308.03620.pdf
Papieradresse: https://arxiv.org/pdf/2308.03620.pdf
 Vorab trainierte Daten
Vorab trainierte Daten
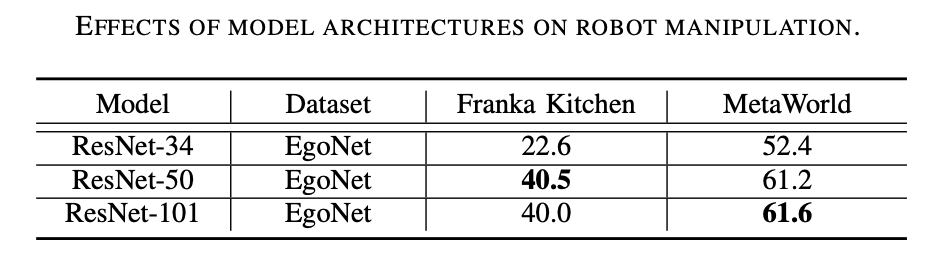
EgoNet ist leistungsfähiger als ImageNet. Trainieren Sie visuelle Encoder anhand verschiedener Datensätze (z. B. ImageNet und EgoNet) durch kontrastive Lernmethoden vor und beobachten Sie ihre Leistung bei Robotermanipulationsaufgaben. Wie aus Tabelle 1 unten ersichtlich ist, erzielte das auf EgoNet vorab trainierte Modell eine bessere Leistung bei Roboterbetriebsaufgaben. Offensichtlich bevorzugen Roboter im Hinblick auf Bedienaufgaben das in Videos enthaltene interaktive Wissen und die zeitlichen Zusammenhänge. Darüber hinaus verfügen die egozentrischen natürlichen Bilder in EgoNet über einen globaleren Kontext zur Welt, was bedeutet, dass umfassendere visuelle Merkmale erlernt werden können. Die Modellstruktur ist besser. ResNet-50 schneidet besser ab. Wie aus Tabelle 2 unten ersichtlich ist, schneiden ResNet-50 und ResNet-101 bei Robotermanipulationsaufgaben besser ab als ResNet-34. Darüber hinaus verbessert sich die Leistung nicht, wenn das Modell von ResNet-50 auf ResNet-101 steigt.
Vortrainingsmethode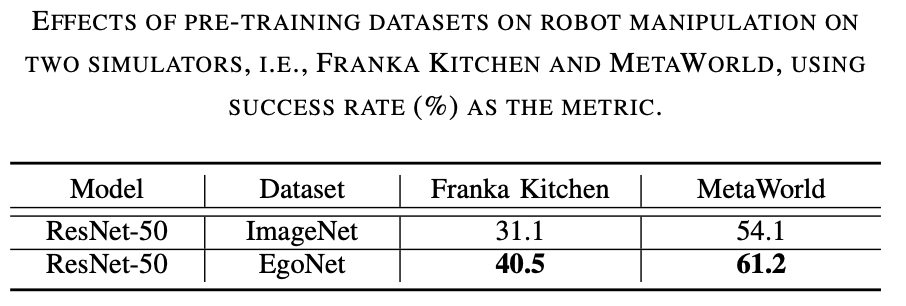
Entsprechend der Bedeutung des Originaltextes lautet der Inhalt, der neu geschrieben werden muss: „Die Vortrainingsmethode bevorzugt kontrastives Lernen.“ Wie in Tabelle 3 gezeigt Im Folgenden zeigt MoCo-v3 eine gute Leistung bei ImageNet- und EgoNet-Daten in allen Sätzen, was beweist, dass kontrastives Lernen effektiver ist als Maskenbildmodellierung. Darüber hinaus ist die durch kontrastives Lernen erhaltene visuelle Semantik für den Roboterbetrieb wichtiger die durch Maskenbildmodellierung erlernten Strukturinformationen. Umgeschriebener Inhalt: Kontrastives Lernen ist die bevorzugte Methode vor dem Training. Wie aus Tabelle 3 ersichtlich ist, übertrifft MoCo-v3 MAE sowohl bei ImageNet- als auch bei EgoNet-Datensätzen, was darauf hinweist, dass kontrastives Lernen effektiver ist als die Maskenbildmodellierung. Darüber hinaus ist die durch kontrastives Lernen erhaltene visuelle Semantik für den Roboterbetrieb wichtiger als die durch Maskenbildmodellierung gelernten Strukturinformationen.
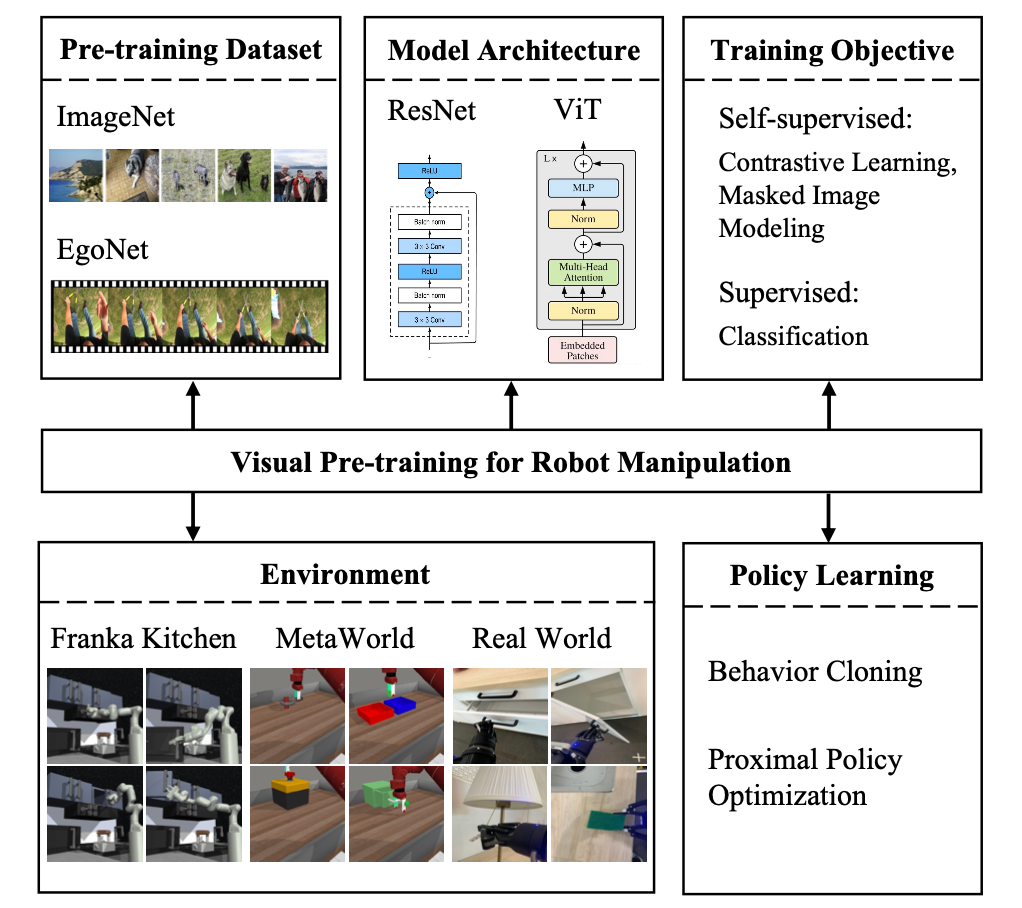
Einführung in den Algorithmus. Basierend auf der obigen Untersuchung schlägt diese Studie Folgendes vor: Vision-Pre-Training-Lösung für den Roboterbetrieb (Vi-PRoM). Diese Lösung extrahiert eine umfassende visuelle Darstellung der Roboteroperationen, indem ResNet-50 vorab auf dem EgoNet-Datensatz trainiert wird. Konkret nutzen wir zunächst kontrastives Lernen, um durch Selbstüberwachung die Interaktionsmuster zwischen Menschen und Objekten aus dem EgoNet-Datensatz zu ermitteln. Anschließend werden zwei zusätzliche Lernziele vorgeschlagen, nämlich die visuelle semantische Vorhersage und die zeitliche dynamische Vorhersage, um die Darstellung des Encoders weiter zu bereichern. Die folgende Abbildung zeigt den grundlegenden Prozess von Vi-PRoM. Bemerkenswert ist, dass diese Studie keine manuelle Beschriftung erfordert, um visuelle Semantik und zeitliche Dynamik zu lernen
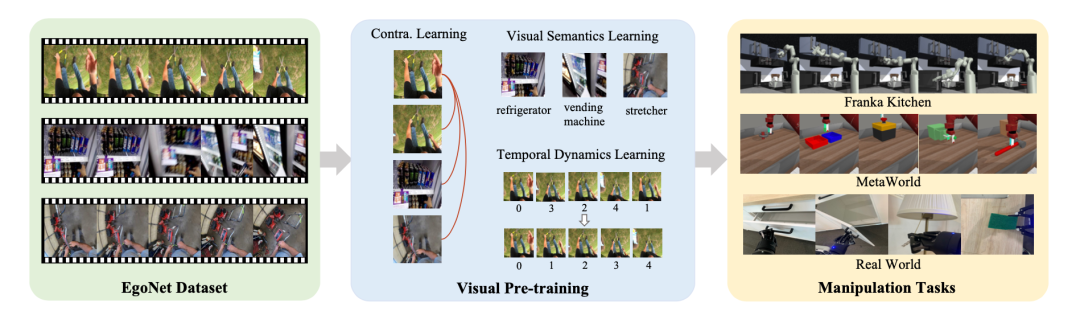
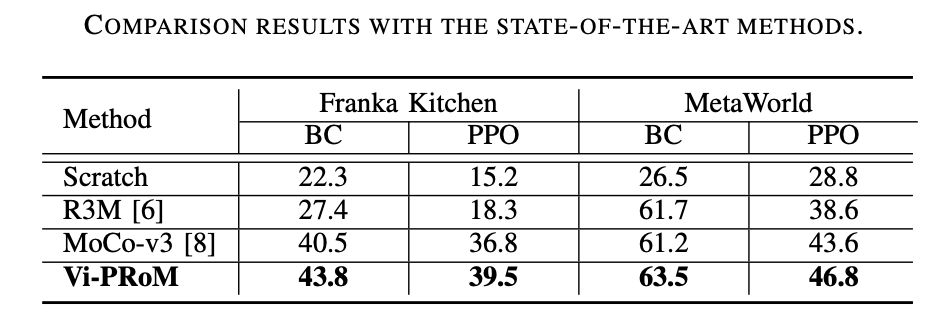
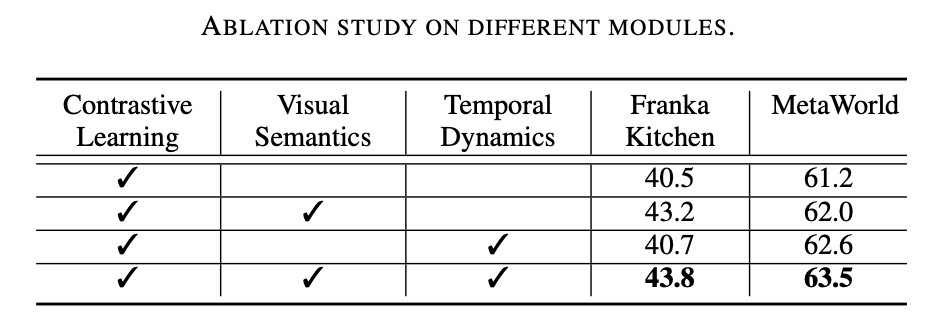
Diese Forschungsarbeit führte umfangreiche Experimente in zwei Simulationsumgebungen (Franka Kitchen und MetaWorld) durch. Experimentelle Ergebnisse zeigen, dass das vorgeschlagene Vortrainingsschema bisherige, hochmoderne Methoden im Roboterbetrieb übertrifft. Die Ergebnisse des Ablationsexperiments sind in der folgenden Tabelle aufgeführt und können die Bedeutung des visuellen semantischen Lernens und des zeitlich dynamischen Lernens für den Roboterbetrieb belegen. Wenn beide Lernziele fehlen, sinkt außerdem die Erfolgsquote von Vi-PRoM erheblich, was die Wirksamkeit der Zusammenarbeit zwischen visuellem semantischem Lernen und zeitlich dynamischem Lernen zeigt.
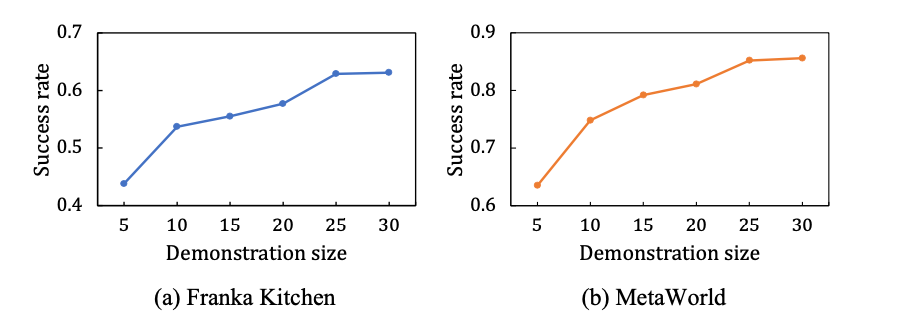
Diese Arbeit untersucht auch die Skalierbarkeit von Vi-PRoM. Wie in der Abbildung unten links dargestellt, verbessert sich in den Simulationsumgebungen Franka Kitchen und MetaWorld die Erfolgsquote von Vi-PRoM mit zunehmender Größe der Demodaten stetig. Nach dem Training an einem größeren Experten-Demonstrationsdatensatz zeigt das Vi-PRoM-Modell seine Skalierbarkeit für Robotermanipulationsaufgaben.

Aufgrund der leistungsstarken visuellen Darstellungsfähigkeiten von Vi-PRoM können echte Roboter erfolgreich Schubladen und Schranktüren öffnen
Wie aus den experimentellen Ergebnissen von Franka Kitchen, Vi- PRoM Es weist bei allen fünf Aufgaben eine höhere Erfolgsquote und einen höheren Abschlussgrad der Maßnahmen auf als R3M.
R3M:





Vi-PRoM:





Auf MetaWorld wurde aufgrund der visuellen Darstellung von Vi eine gute Leistung erlernt. PRoM verfügt über semantische und dynamische Funktionen und kann besser zur Aktionsvorhersage verwendet werden. Im Vergleich zu R3M erfordert Vi-PRoM daher weniger Schritte, um den Vorgang abzuschließen.
R3M:

Vi-PRoM:


Das obige ist der detaillierte Inhalt vonUmgeschriebener Titel: Byte führt das visuelle Vorschulungsprogramm Vi-PRoM ein, um die Erfolgsrate und Wirkung des Roboterbetriebs zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




















