


Selbstüberwachte Lernalgorithmen haben in Bereichen wie der Verarbeitung natürlicher Sprache und Computer Vision erhebliche Fortschritte gemacht. Obwohl diese selbstüberwachten Lernalgorithmen vom Konzept her allgemein sind, basieren ihre spezifischen Operationen auf spezifischen Datenmodalitäten. Das bedeutet, dass für unterschiedliche Datenmodalitäten unterschiedliche selbstüberwachte Lernalgorithmen entwickelt werden müssen. Zu diesem Zweck schlägt dieser Artikel eine allgemeine Datenerweiterungstechnik vor, die auf jede Datenmodalität angewendet werden kann. Im Vergleich zum bestehenden allgemeinen selbstüberwachten Lernen kann diese Methode erhebliche Leistungsverbesserungen erzielen und eine Reihe komplexer Datenverbesserungsmethoden ersetzen, die für bestimmte Modalitäten entwickelt wurden, und eine ähnliche Leistung erzielen.

Umgeschriebener Inhalt: Derzeit erfordert das siamesische Repräsentationslernen/kontrastive Lernen die Verwendung von Datenerweiterungstechniken, um verschiedene Stichproben derselben Daten zu erstellen und diese in zwei parallele Netzwerkstrukturen einzugeben, um ein ausreichend starkes Überwachungssignal zu erzeugen. Diese Datenerweiterungstechniken basieren jedoch in der Regel stark auf modalitätsspezifischem Vorwissen und erfordern oft einen manuellen Entwurf oder die Suche nach der besten Kombination, die für die aktuelle Modalität geeignet ist. Die besten gefundenen Datenanreicherungsmethoden sind nicht nur zeit- und arbeitsintensiv, sondern lassen sich auch nur schwer auf andere Bereiche übertragen. Beispielsweise kann das übliche Farbjittern für natürliche RGB-Bilder nicht auf andere Datenmodalitäten als natürliche Bilder angewendet werden. Im Allgemeinen können die Eingabedaten als Binärdaten bestehend aus Sequenzdimensionen und Kanaldimensionen dargestellt werden. Die Sequenzdimension hängt häufig mit der Modalität der Daten zusammen, beispielsweise mit der räumlichen Dimension von Bildern, der zeitlichen Dimension von Sprache und der syntaktischen Dimension von Sprache. Die Kanaldimension ist unabhängig von der Modalität. Beim selbstüberwachten Lernen hat sich die Okklusionsmodellierung oder die Verwendung von Okklusion als Datenerweiterung zu einer effektiven Lernmethode entwickelt. Diese Operationen werden jedoch in der Sequenzdimension ausgeführt. Um eine breite Anwendbarkeit auf verschiedene Datenmodalitäten zu gewährleisten, wird in diesem Artikel eine Datenverbesserungsmethode vorgeschlagen, die auf die Kanaldimension einwirkt: Zufallsquantisierung. Durch die dynamische Quantisierung der Daten in jedem Kanal mithilfe eines ungleichmäßigen Quantisierers werden die quantisierten Werte zufällig aus zufällig unterteilten Intervallen abgetastet. Auf diese Weise wird der Informationsunterschied der ursprünglichen Eingabe im selben Intervall gelöscht, während die relative Größe der Daten in verschiedenen Intervallen beibehalten wird, wodurch der Effekt der Maskierung erzielt wird
Diese Methode kann in verschiedenen Daten verwendet werden Modalitäten Es übertrifft bestehende selbstüberwachte Lernmethoden in jeder Modalität, einschließlich natürlicher Bilder, 3D-Punktwolken, Sprache, Text, Sensordaten, medizinische Bilder usw. Bei einer Vielzahl von Lernaufgaben vor dem Training, wie z. B. kontrastivem Lernen (z. B. MoCo-v3) und selbstüberwachtem Lernen durch Selbstdestillation (z. B. BYOL), werden Funktionen erlernt, die besser sind als bestehende Methoden. Die Methode wurde auch für verschiedene Backbone-Netzwerkstrukturen wie CNN und Transformer validiert. 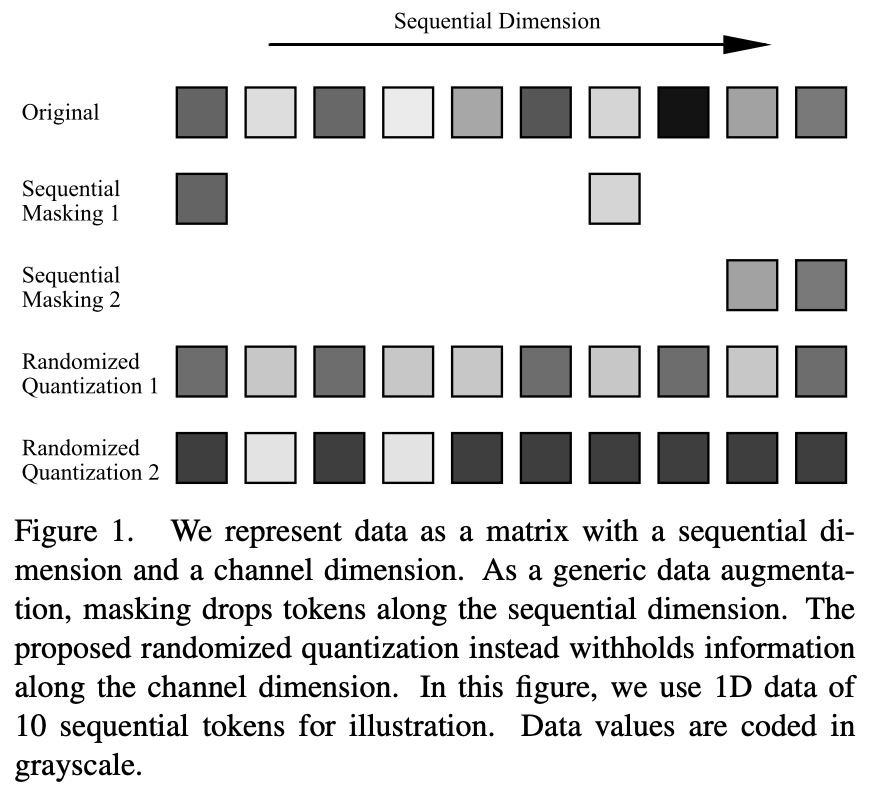
Methode
Dieser Artikel schlägt eine randomisierte Quantisierungsoperation vor, die die Daten jedes Eingangskanals unabhängig in mehrere nicht überlappende Zufallsintervalle (
) aufteilt und die in jedes Intervall fallenden Originaleingaben auf eine zufällig ausgewählte Konstante 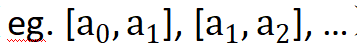 abbildet aus dem Intervall.
abbildet aus dem Intervall. 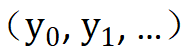
Die Fähigkeit der Zufallsquantisierung zur Maskierung von Kanaldimensionsdaten in selbstüberwachten Lernaufgaben hängt von der Gestaltung der folgenden drei Aspekte ab: 1) zufälliges Teilen numerischer Intervalle 2) zufälliges Abtasten von Ausgabewerten und 3 ) geteilte numerische Intervalle Zahl. 
Konkret führt der Zufallsprozess zu umfangreicheren Stichproben, und dieselben Daten können jedes Mal, wenn eine Zufallsquantisierungsoperation durchgeführt wird, unterschiedliche Datenstichproben erzeugen. Gleichzeitig bringt der Zufallsprozess auch eine größere Verbesserung der Originaldaten mit sich. Beispielsweise werden große Datenintervalle zufällig aufgeteilt, oder wenn der Zuordnungspunkt vom Medianpunkt des Intervalls abweicht, kann dies dazu führen, dass die ursprüngliche Eingabe und Ausgabe beeinträchtigt wird fallen zwischen den Intervallen größere Unterschiede zwischen.
Durch eine entsprechende Reduzierung der Anzahl der Teilintervalle kann die Verstärkungsintensität leicht erhöht werden. Auf diese Weise können die beiden Netzwerkzweige bei Anwendung auf das siamesische Repräsentationslernen Eingabedaten mit ausreichenden Informationsunterschieden empfangen und so ein starkes Lernsignal konstruieren, das das Feature-Lernen erleichtert
Die folgende Abbildung veranschaulicht die Wirkung verschiedener Datenmodelle Verwenden dieser Datenerweiterungsmethode:
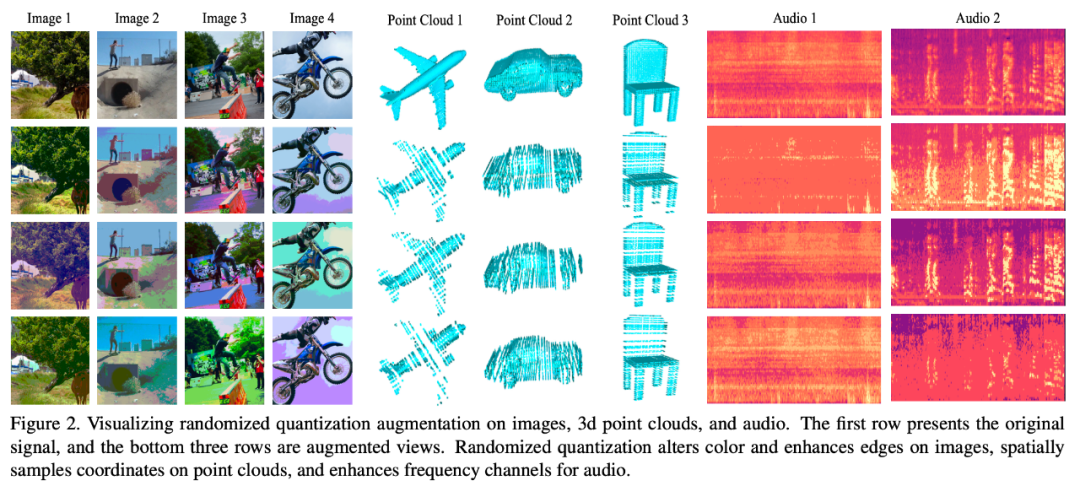
Umgeschriebener Inhalt ist: Modus 1: Bild
Dieser Artikel wird auf den ImageNet-1K-Datensatz ausgewertet. Die Auswirkung der angewendeten randomisierten Quantisierung MoCo-v3 und BYOL, der Bewertungsindex ist eine lineare Bewertung. Bei alleiniger Verwendung als einzige Datenerweiterungsmethode, d. h. die Erweiterung in diesem Artikel wird auf den mittleren Ausschnitt des Originalbilds angewendet, und bei Verwendung in Verbindung mit dem üblichen RRC (Random Resized Crop) wurden mit dieser Methode bessere Ergebnisse erzielt als bestehende allgemeine selbstüberwachte Studienmethoden für bessere Ergebnisse.
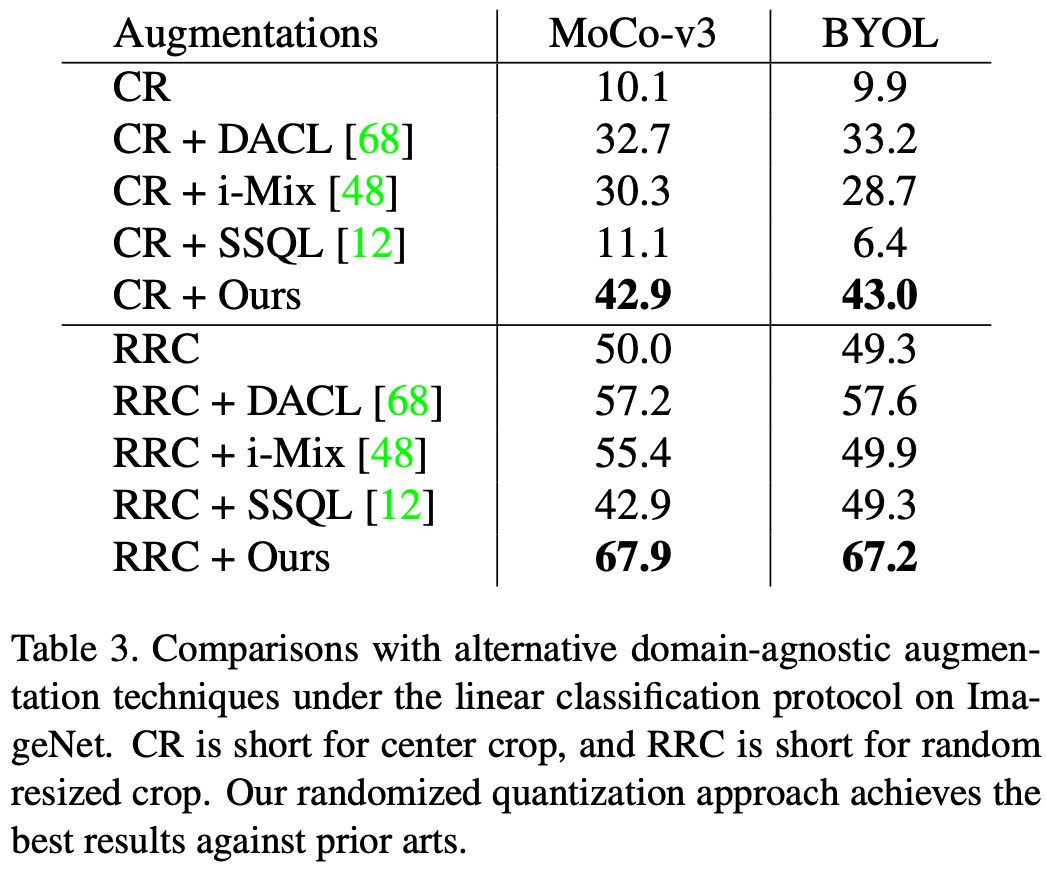
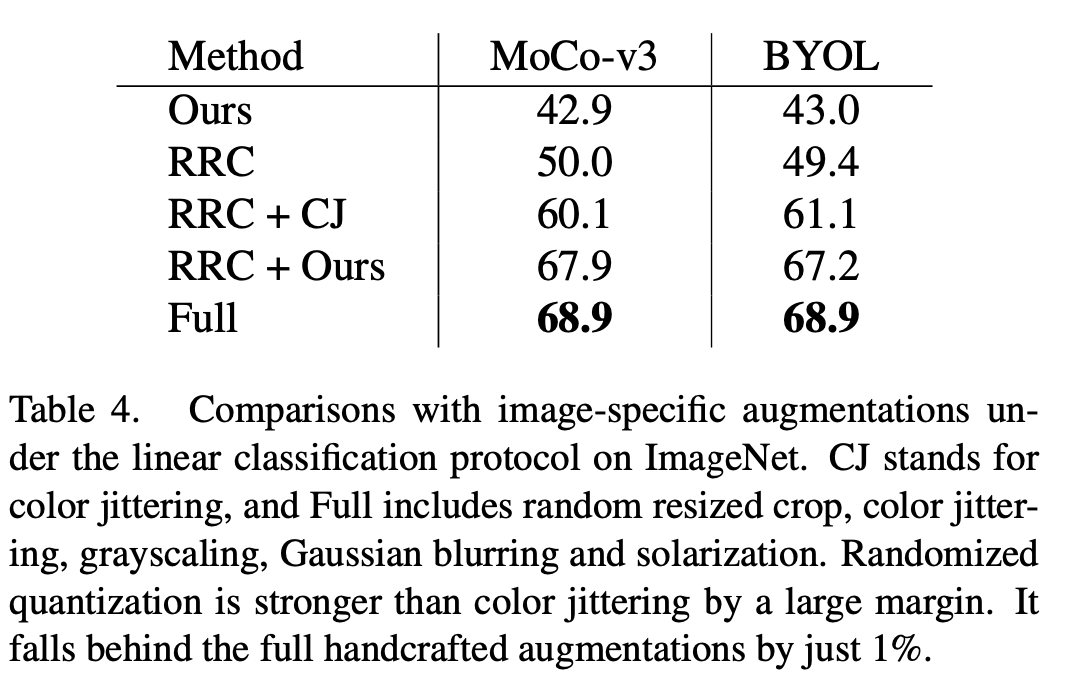
Im Vergleich zu vorhandenen Datenverbesserungsmethoden, die für Bilddaten entwickelt wurden, wie z. B. Farbjitter (CJ), weist die Methode in diesem Artikel offensichtliche Leistungsvorteile auf. Gleichzeitig kann diese Methode auch eine Reihe komplexer Datenverbesserungsmethoden (vollständig) in MoCo-v3/BYOL ersetzen, einschließlich Farbzittern, zufällige Graustufen, zufällige Gaußsche Unschärfe, zufällige Belichtung (Solarisierung) und ähnliche Effekte erzielen komplexe Datenanreicherungsmethoden.
Der Inhalt, der neu geschrieben werden muss, ist: Modus 2: 3D-Punktwolke
In der Klassifizierungsaufgabe des ModelNet40-Datensatzes und der Segmentierungsaufgabe des ShapeNet-Part-Datensatzes wurde in dieser Studie der Zufall überprüft Quantisierung Überlegenheit gegenüber bestehenden selbstüberwachten Methoden. Insbesondere wenn die Datenmenge im Downstream-Trainingssatz gering ist, übertrifft die Methode dieser Studie den bestehenden selbstüberwachten Punktwolken-Algorithmus deutlich
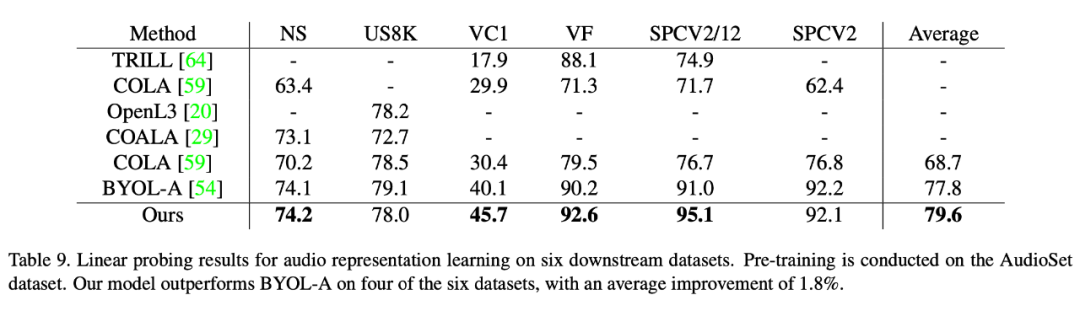
Diese Methode erzielt auch eine bessere Leistung als bestehende selbstüberwachte Lernmethoden für Sprachdatensätze. In diesem Artikel wird die Überlegenheit dieser Methode anhand von sechs Downstream-Datensätzen überprüft. Unter anderem hat diese Methode beim schwierigsten Datensatz VoxCeleb1 (der die größte Anzahl an Kategorien enthält und die Anzahl anderer Datensätze bei weitem übertrifft) eine erhebliche Leistungsverbesserung erzielt (5,6 Punkte).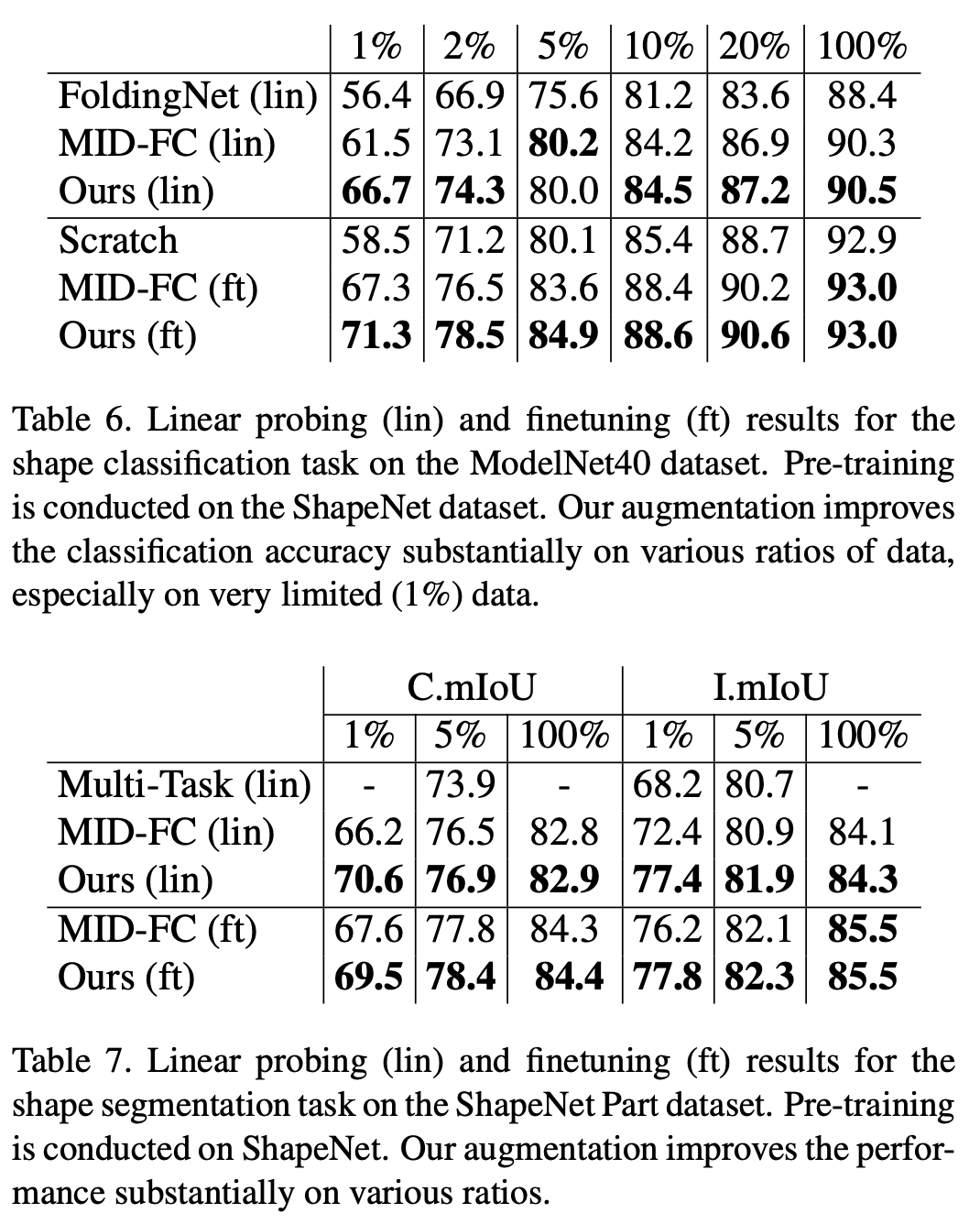
Der neu geschriebene Inhalt ist: Modus 4: DABS
DABS ist ein allgemeiner Benchmark für selbstüberwachtes Lernen, der eine Vielzahl modaler Daten abdeckt, einschließlich natürlicher Bilder, Text, Sprache und Sensoren Daten, medizinische Bilder und Grafiken usw. Unsere Methode ist auch besser als jede bestehende modale selbstüberwachte Lernmethode für verschiedene modale Daten, die von DABS abgedeckt werden. Interessierte Leser können das Originalpapier lesen, um die Details des Forschungsinhalts zu verstehen
Das obige ist der detaillierte Inhalt vonUniverselle Datenverbesserungstechnologie, Zufallsquantisierung ist für jede Datenmodalität geeignet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 Chinesisches Änderungs-Tutorial für C++-Software
Chinesisches Änderungs-Tutorial für C++-Software
 Worauf bezieht sich Bean in Java?
Worauf bezieht sich Bean in Java?
 Was sind die Oracle-Wildcards?
Was sind die Oracle-Wildcards?
 Der Unterschied zwischen currentregion und usedrange
Der Unterschied zwischen currentregion und usedrange
 Was führt dazu, dass der Computerbildschirm gelb wird?
Was führt dazu, dass der Computerbildschirm gelb wird?
 CSS außerhalb der Anzeige ...
CSS außerhalb der Anzeige ...
 Einführung in Softwareentwicklungstools
Einführung in Softwareentwicklungstools








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



