


Prometheus ist ein Open-Source-Überwachungs- und Alarmsystem, das auf einer Zeitreihendatenbank basiert. Wenn wir von Prometheus sprechen, müssen wir SoundCloud erwähnen, eine Online-Plattform zum Teilen von Musik, ähnlich wie YouTube zum Teilen von Videos Während sie die Entwicklung der Microservice-Architektur immer weiter vorantreiben und Hunderte oder Tausende von Diensten auftauchen, gibt es viele Einschränkungen bei der Verwendung der herkömmlichen Überwachungssysteme StatsD und Graphite.
Also begannen sie 2012 mit der Entwicklung eines neuen Überwachungssystems. Der ursprüngliche Autor von Prometheus ist Matt T. Proud, der ebenfalls 2012 zu SoundCloud kam. Tatsächlich hatte Matt vor seinem Beitritt zu SoundCloud bei Google gearbeitet und sich von Googles Clustermanager Borg und dessen Überwachungssystem Borgmon inspirieren lassen Wie bei vielen Google-Projekten wird als Programmiersprache Go verwendet.
Als Lösung für das Überwachungssystem der Microservice-Architektur ist Prometheus natürlich auch untrennbar mit Containern verbunden. Bereits am 9. August 2006 stellte Eric Schmidt auf der Suchmaschinenkonferenz erstmals das Konzept des Cloud Computing vor. In den folgenden zehn Jahren verlief die Entwicklung des Cloud Computing rasant.
Im Jahr 2013 schlug Matt Stine von Pivotal das Konzept von Cloud Native vor, das aus einer Microservice-Architektur, DevOps und einer agilen Infrastruktur besteht, die durch Container dargestellt wird, um Unternehmen dabei zu helfen, Software schnell, kontinuierlich, zuverlässig bereitzustellen und zu skalieren.
Um Cloud-Computing-Schnittstellen und verwandte Standards zu vereinheitlichen, wurde im Juli 2015 die Cloud Native Computing Foundation (CNCF) ins Leben gerufen, die der Linux Foundation angegliedert ist. Das erste Projekt, das der CNCF beitrat, war Googles Kubernetes, und Prometheus war das zweite, das sich der CNCF anschloss (im Jahr 2016).
Auf dem offiziellen Blog von SoundCloud finden Sie einen Artikel darüber, warum sie ein neues Monitoring-System entwickeln müssen, Prometheus: Monitoring bei SoundCloud Der Bedarf muss die folgenden vier Merkmale erfüllen:
Einfach ausgedrückt sind es die folgenden vier Merkmale:
Tatsächlich das zweiteilige mehrdimensionale Datenmodell und die leistungsstarke Abfragesprache Diese Funktion ist genau das, was eine Zeitreihendatenbank benötigt, sodass Prometheus nicht nur ein Überwachungssystem, sondern auch eine Zeitreihendatenbank ist. Warum nutzt Prometheus also nicht direkt die vorhandene Zeitreihendatenbank als Back-End-Speicher? Denn SoundCloud möchte, dass sein Monitoring-System nicht nur die Eigenschaften einer Zeitreihendatenbank aufweist, sondern auch sehr einfach bereitzustellen und zu warten sein.
Wenn man sich die populäreren Zeitreihendatenbanken ansieht (siehe Anhang unten), haben sie entweder zu viele Komponenten oder starke externe Abhängigkeiten. Zum Beispiel: Druid verfügt über eine Reihe von Komponenten wie Historical, MiddleManager, Broker, Coordinator, Overlord. und Router, und es hängt auch davon ab Für ZooKeeper, Deep Storage (HDFS oder S3 usw.), Metadatenspeicher (PostgreSQL oder MySQL) sind die Bereitstellungs- und Wartungskosten sehr hoch. Prometheus verwendet eine dezentrale Architektur, die unabhängig bereitgestellt werden kann und nicht auf externen verteilten Speicher angewiesen ist. Sie können in wenigen Minuten ein Überwachungssystem erstellen.
Darüber hinaus ist die Datenerfassungsmethode von Prometheus auch sehr flexibel. Um die Überwachungsdaten des Ziels zu sammeln, müssen Sie zunächst die Datenerfassungskomponente auf dem Ziel installieren. Diese wird als Exporter bezeichnet und stellt eine HTTP-Schnittstelle bereit, die Prometheus über Pull abfragen kann .Daten, dies unterscheidet sich vom herkömmlichen Push-Modus.
Prometheus bietet jedoch auch eine Möglichkeit, den Push-Modus zu unterstützen. Sie können Ihre Daten an Push Gateway senden, und Prometheus erhält Daten von Push Gateway über Pull. Der aktuelle Exporter kann bereits die meisten Daten von Drittanbietern sammeln, z. B. Docker, HAProxy, StatsD, JMX usw. Auf der offiziellen Website finden Sie eine Liste der Exporter.
Zusätzlich zu diesen vier Hauptfunktionen unterstützt Prometheus im Zuge der weiteren Entwicklung immer mehr erweiterte Funktionen, wie z. B. Serviceerkennung, umfangreichere Diagrammanzeige, Verwendung von externem Speicher, leistungsstarke Alarmregeln und verschiedene Benachrichtigungsmethoden.
Das folgende Bild ist das Gesamtarchitekturdiagramm von Prometheus:
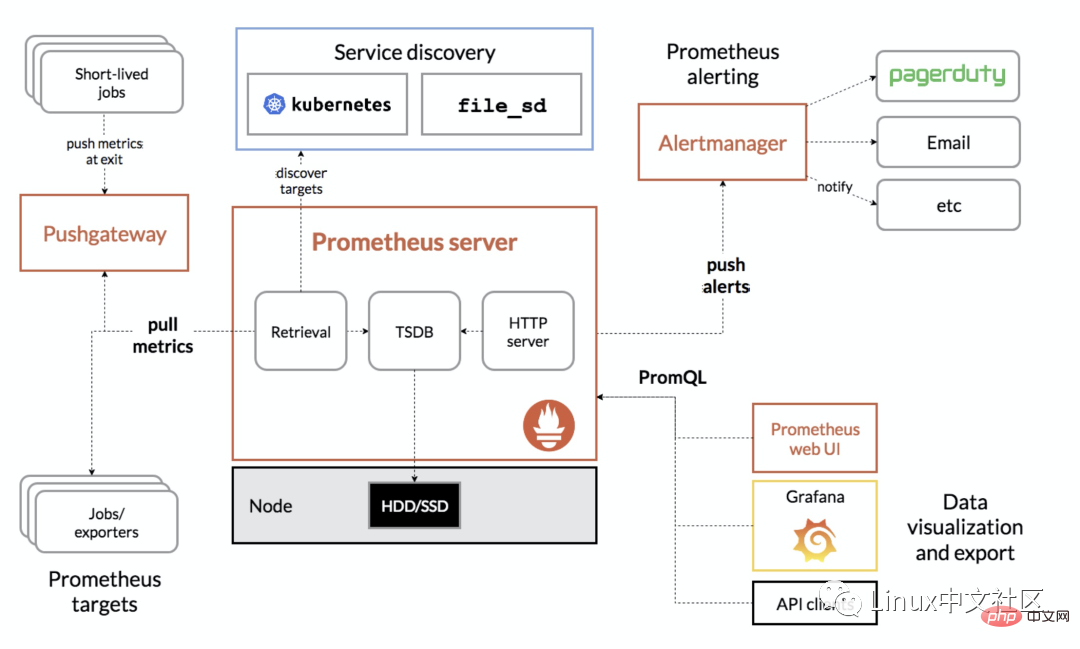
Prometheus kann eine Vielzahl von Installationsmethoden unterstützen, einschließlich Docker, Ansible, Chef, Puppet, Saltstack usw. Die beiden einfachsten Methoden werden im Folgenden vorgestellt. Eine besteht darin, die kompilierte ausführbare Datei direkt zu verwenden, die sofort verwendet werden kann, und die andere darin, ein Docker-Image zu verwenden.
Besorgen Sie sich zunächst die neueste Version und Download-Adresse von der Download-Seite der offiziellen Website. Die neueste Version ist 2.4.3 (Oktober 2018). Führen Sie zum Herunterladen und Dekomprimieren den folgenden Befehl aus
$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz $ tar xvfz prometheus-2.4.3.linux-amd64.tar.gz
$ cd prometheus-2.4.3.linux-amd64 $ ./prometheus --version prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449) build user: root@1e42b46043e9 build date: 20181004-08:42:02 go version: go1.11.1
$ ./prometheus --config.file=prometheus.yml
$ sudo docker run -d -p 9090:9090 prom/prometheus
$ sudo docker run -d -p 9090:9090 \ -v ~/docker/prometheus/:/etc/prometheus/ \ prom/prometheus
Speicherort ab, dem Standardspeicherort der Konfigurationsdatei, der von Prometheus in den Container geladen wird. ~/docker/prometheus/prometheus.yml,这样可以方便编辑和查看,通过 -v 参数将本地的配置文件挂载到 /etc/prometheus/
如果我们不确定默认的配置文件在哪,可以先执行上面的不带 -v 参数的命令,然后通过 docker inspect 命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):
$ sudo docker inspect 0c [...] "Id": "0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46", "Created": "2018-10-15T22:27:34.56050369Z", "Path": "/bin/prometheus", "Args": [ "--config.file=/etc/prometheus/prometheus.yml", "--storage.tsdb.path=/prometheus", "--web.console.libraries=/usr/share/prometheus/console_libraries", "--web.console.templates=/usr/share/prometheus/consoles" ], [...]
正如上面两节看到的,Prometheus 有一个配置文件,通过参数 <span style="outline: 0px;color: rgb(0, 0, 0);">--config.file</span> 来指定,配置文件格式为 YAML。我们可以打开默认的配置文件 <span style="outline: 0px;color: rgb(0, 0, 0);">prometheus.yml</span> 看下里面的内容:
/etc/prometheus $ cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
Prometheus 默认的配置文件分为四大块:
scrape_interval stellt dar, wie long Prometheus braucht Fetch data einmal, evaluation_interval gibt an, wie oft die Alarmregel erkannt wird ;scrape_interval 表示 Prometheus 多久抓取一次数据,evaluation_interval 表示多久检测一次告警规则;scrape_config 块:这里定义了 Prometheus 要抓取的目标,我们可以看到默认已经配置了一个名称为 prometheus 的 job,这是因为 Prometheus 在启动的时候也会通过 HTTP 接口暴露自身的指标数据,这就相当于 Prometheus 自己监控自己,虽然这在真正使用 Prometheus 时没啥用处,但是我们可以通过这个例子来学习如何使用 Prometheus;可以访问 http://localhost:9090/metrics 查看 Prometheus 暴露了哪些指标;
通过上面的步骤安装好 Prometheus 之后,我们现在可以开始体验 Prometheus 了。Prometheus 提供了可视化的 Web UI 方便我们操作,直接访问 http://localhost:9090/
scrape_config block: Prometheus ist hier definiert. Für das erfasste Ziel können wir sehen, dass es mit einem Namen namens prometheus</code > job, das liegt daran, dass Prometheus beim Start auch seine eigenen Indikatordaten über die HTTP-Schnittstelle offenlegt, was der Überwachung durch Prometheus selbst entspricht. Obwohl dies bei der tatsächlichen Verwendung von Prometheus von geringem Nutzen ist, können wir dies tun Verwenden Sie dieses Beispiel, um zu erfahren, wie Sie Prometheus verwenden. Besuchen Sie <code style="margin: 3px;padding: 3px;outline: 0px;font-size: 14px;border-radius: 4px;font-family: "Operator Mono", Consolas , Monaco, Menlo , Monospace;word-break: break-all;color: rgb(155, 110, 35);background-color: rgb(255, 245, 227);">http://localhost:9090/metrics Sehen Sie, welche Indikatoren Prometheus offenlegt; 🎜
Nachdem wir Prometheus mithilfe der oben genannten Schritte installiert haben, können wir nun damit beginnen, Prometheus zu erleben. Prometheus bietet eine visuelle Web-Benutzeroberfläche, um unsere Vorgänge zu erleichtern. , Consolas, Monaco, Menlo, Monospace;word-break: break-all;color: rgb(155, 110, 35);background-color: rgb(255, 245, 227);">http://localhost:9090 / , wird standardmäßig zur Diagrammseite gesprungen: 🎜
Wenn Sie diese Seite zum ersten Mal besuchen, können Sie sich zunächst den Inhalt unter anderen Menüs ansehen. In „Alerts“ können Sie beispielsweise alle definierten Alarmregeln anzeigen, einschließlich Laufzeit- und Build-Informationen. , Befehlszeilenflags, Konfiguration, Regeln, Ziele, Diensterkennung usw.
Tatsächlich ist die Graph-Seite die leistungsstärkste Funktion von Prometheus. Hier können wir einen speziellen Ausdruck verwenden, der von Prometheus bereitgestellt wird, um Überwachungsdaten abzufragen. Dieser Ausdruck heißt PromQL (Prometheus Query Language). Sie können Daten auf der Graph-Seite nicht nur über PromQL abfragen, sondern auch über die von Prometheus bereitgestellte HTTP-API. Die abgefragten Überwachungsdaten können in zwei Formen angezeigt werden: Liste und Diagramm (entsprechend den beiden Bezeichnungen Konsole und Diagramm in der obigen Abbildung).
Wie oben erwähnt, stellt Prometheus selbst auch viele Überwachungsindikatoren bereit, die auch auf der Diagrammseite abgefragt werden können, und Sie können viele Indikatornamen sehen, die wir auswählen können eine nach Belieben, zum Beispiel: promhttp_metric_handler_requests_total, dieser Indikator stellt /metrics Die Anzahl der Besuche auf der Seite. Prometheus verwendet diese Seite, um seine eigenen Überwachungsdaten zu erfassen . Die Abfrageergebnisse im Console-Tag lauten wie folgt: promhttp_metric_handler_requests_total,这个指标表示 /metrics 页面的访问次数,Prometheus 就是通过这个页面来抓取自身的监控数据的。在 Console 标签中查询结果如下:

上面在介绍 Prometheus 的配置文件时,可以看到 scrape_interval 参数是 15s,也就是说 Prometheus 每 15s 访问一次 /metrics
scrape_interval Parameter ist 15s, das heißt, Prometheus greift alle 15 Sekunden einmal zu /metrics Seite, also haben wir die Aktualisierung der Seite in 15 Sekunden bestanden und Sie werden sehen, dass der Indikatorwert automatisch erhöht wird. Dies ist im Graph-Tag deutlicher zu erkennen: 🎜🎜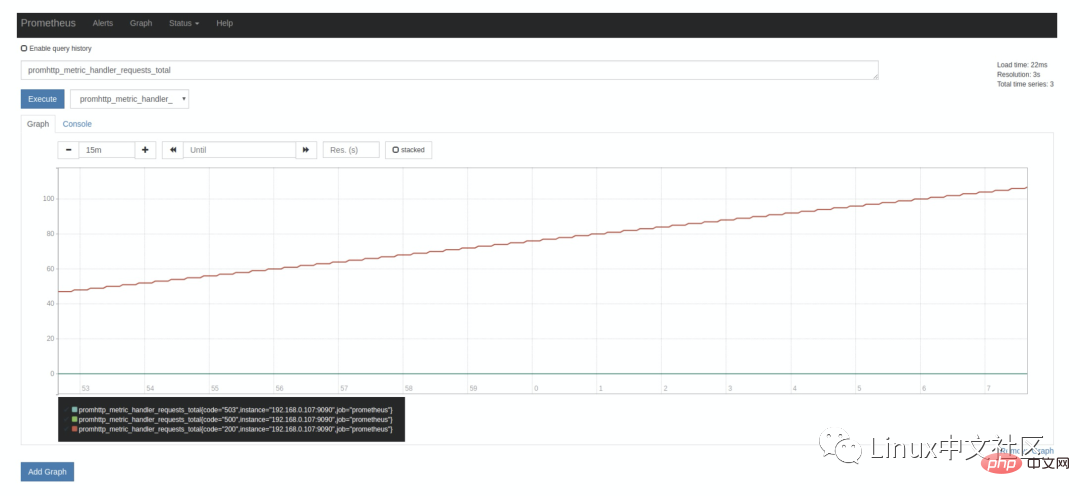
要学习 PromQL,首先我们需要了解下 Prometheus 的数据模型,一条 Prometheus 数据由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,比如下面这个例子:
promhttp_metric_handler_requests_total{code="200",instance="192.168.0.107:9090",job="prometheus"} 106这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。
Dieses Datenmodell ähnelt dem Datenmodell von OpenTSDB. Weitere Informationen finden Sie im offiziellen Website-Dokument Datenmodell. Darüber hinaus gibt es auf der offiziellen Website einige Leitvorschläge für die Benennung von Indikatoren und Etiketten. Sie können sich auf die Benennung von Metriken und Etiketten beziehen.
Obwohl es sich bei den in Prometheus gespeicherten Daten um einen Float64-Wert handelt, können Prometheus-Daten bei Aufteilung nach Typ in vier Hauptkategorien unterteilt werden:
Zähler wird zum Zählen verwendet, z. B. der Anzahl der Anfragen, der Anzahl der Aufgabenabschlüsse und der Anzahl der Fehler. Dieser Wert wird immer erhöht und nicht verringert. Gauge ist ein allgemeiner Wert, der groß oder klein sein kann, z. B. Temperaturänderungen und Änderungen der Speichernutzung. Histogramm ist ein Histogramm oder Histogramm, das häufig zur Verfolgung des Ausmaßes von Ereignissen verwendet wird, z. B. der Anforderungszeit und der Antwortgröße.
Das Besondere daran ist, dass es die aufgezeichneten Inhalte gruppieren und Zähl- und Summierungsfunktionen bereitstellen kann. Zusammenfassung ist dem Histogramm sehr ähnlich und wird auch zur Verfolgung des Ausmaßes des Auftretens von Ereignissen verwendet. Der Unterschied besteht darin, dass es eine Quantilfunktion bietet, die die Verfolgungsergebnisse durch Prozentsätze dividieren kann. Beispiel: Ein Quantilwert von 0,95 bedeutet, dass 95 % der Daten in den Stichprobenwert einbezogen werden. Weitere Informationen finden Sie im offiziellen Website-Dokument „Metriktypen“. Die Konzepte „Zusammenfassung“ und „Histogramm“ sind relativ leicht zu verwechseln. Sie können sich hier auf die Beschreibung von Histogrammen und Zusammenfassungen beziehen.
这四种类型的数据只在指标的提供方作区分,也就是上面说的 Exporter,如果你需要编写自己的 Exporter 或者在现有系统中暴露供 Prometheus 抓取的指标,你可以使用 Prometheus client libraries,这个时候你就需要考虑不同指标的数据类型了。如果你不用自己实现,而是直接使用一些现成的 Exporter,然后在 Prometheus 里查查相关的指标数据,那么可以不用太关注这块,不过理解 Prometheus 的数据类型,对写出正确合理的 PromQL 也是有帮助的。
我们从一些例子开始学习 PromQL,最简单的 PromQL 就是直接输入指标名称,比如:
# 表示 Prometheus 能否抓取 target 的指标,用于 target 的健康检查 up
这条语句会查出 Prometheus 抓取的所有 target 当前运行情况,譬如下面这样:
up{instance="192.168.0.107:9090",job="prometheus"} 1 up{instance="192.168.0.108:9090",job="prometheus"} 1 up{instance="192.168.0.107:9100",job="server"} 1 up{instance="192.168.0.108:9104",job="mysql"} 0也可以指定某个 label 来查询:
up{job="prometheus"}这种写法被称为 Instant vector selectors,这里不仅可以使用 = 号,还可以使用 !=、=~、!~,比如下面这样:
up{job!="prometheus"} up{job=~"server|mysql"} up{job=~"192\.168\.0\.107.+"}=~ 是根据正则表达式来匹配,必须符合 RE2 的语法。
和 Instant vector selectors 相应的,还有一种选择器,叫做 Range vector selectors,它可以查出一段时间内的所有数据:
http_requests_total[5m]
这条语句查出 5 分钟内所有抓取的 HTTP 请求数,注意它返回的数据类型是 Range vector,没办法在 Graph 上显示成曲线图,一般情况下,会用在 Counter 类型的指标上,并和 rate() 或 irate() 函数一起使用(注意 rate 和 irate 的区别)。
搜索公众号Java后端栈回复“面试”,送你一份惊喜礼包。
# 计算的是每秒的平均值,适用于变化很慢的 counter # per-second average rate of increase, for slow-moving counters rate(http_requests_total[5m]) # 计算的是每秒瞬时增加速率,适用于变化很快的 counter # per-second instant rate of increase, for volatile and fast-moving counters irate(http_requests_total[5m])
此外,PromQL 还支持 count、sum、min、max、topk 等 聚合操作,还支持 rate、abs、ceil、floor 等一堆的 内置函数,更多的例子,还是上官网学习吧。如果感兴趣,我们还可以把 PromQL 和 SQL 做一个对比,会发现 PromQL 语法更简洁,查询性能也更高。
我们不仅仅可以在 Prometheus 的 Graph 页面查询 PromQL,Prometheus 还提供了一种 HTTP API 的方式,可以更灵活的将 PromQL 整合到其他系统中使用,譬如下面要介绍的 Grafana,就是通过 Prometheus 的 HTTP API 来查询指标数据的。实际上,我们在 Prometheus 的 Graph 页面查询也是使用了 HTTP API。
我们看下 Prometheus 的 HTTP API 官方文档,它提供了下面这些接口:
Ab Prometheus v2.1 wurden mehrere neue hinzugefügt Schnittstelle zur Verwaltung der TSDB:
Obwohl die von Prometheus bereitgestellte Web-Benutzeroberfläche auch eine gute Ansicht verschiedener Indikatoren bieten kann, ist diese Funktion sehr einfach und nur zum Debuggen geeignet. Um ein leistungsstarkes Überwachungssystem zu implementieren, benötigen Sie außerdem ein Panel, das die Anzeige verschiedener Indikatoren anpassen und verschiedene Arten von Darstellungsmethoden unterstützen kann (Kurvendiagramme, Kreisdiagramme, Heatmaps, TopN usw.). Dies ist die Dashboard-Funktion.
Also entwickelte Prometheus ein Dashboard-System PromDash, aber dieses System wurde bald aufgegeben. Beamte begannen, die Verwendung von Grafana zur Visualisierung von Prometheus-Indikatordaten zu empfehlen. Dies liegt nicht nur daran, dass Grafana sehr leistungsfähig ist, sondern auch, weil es perfekt und nahtlos sein kann integriert mit Prometheus.
Grafana ist ein Open-Source-System zur Visualisierung umfangreicher Messdaten. Es verfügt über sehr leistungsstarke Funktionen und eine sehr schöne Oberfläche. Sie können damit ein individuelles Bedienfeld erstellen im Panel. Es unterstützt viele verschiedene Datenquellen, wie zum Beispiel: Graphite, InfluxDB, OpenTSDB, Elasticsearch, Prometheus usw., und es unterstützt auch viele Plug-Ins.
Versuchen wir, Grafana zu verwenden, um Prometheus-Indikatordaten anzuzeigen. Zuerst installieren wir Grafana, wir verwenden die einfachste Docker-Installationsmethode:
$ docker run -d -p 3000:3000 grafana/grafana
运行上面的 docker 命令,Grafana 就安装好了!你也可以采用其他的安装方式,参考 官方的安装文档。安装完成之后,我们访问 http://localhost:3000/ 进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。
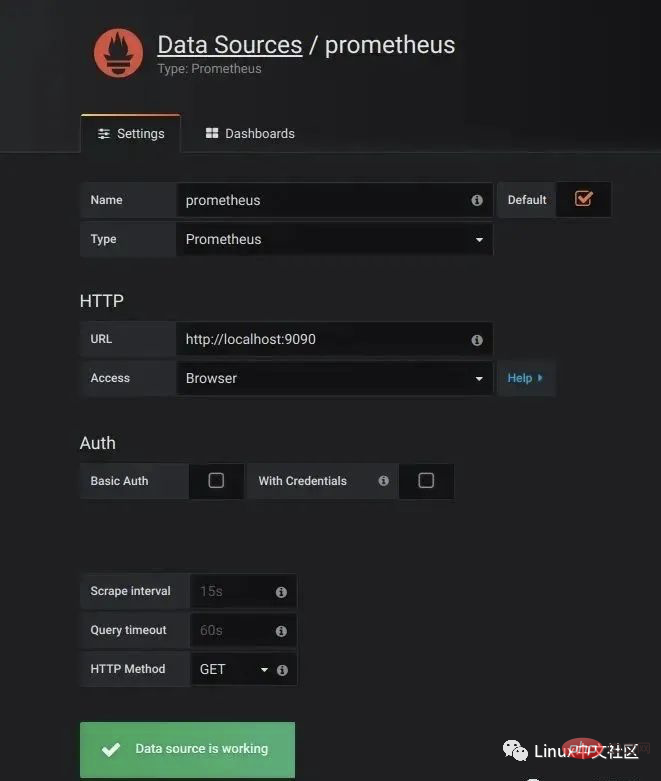
要使用 Grafana,第一步当然是要配置数据源,告诉 Grafana 从哪里取数据,我们点击 Add data source 进入数据源的配置页面:
 图片
图片
我们在这里依次填上:
要注意的是,这里的 Access 指的是 Grafana 访问数据源的方式,有 Browser 和 Proxy 两种方式。Browser 方式表示当用户访问 Grafana 面板时,浏览器直接通过 URL 访问数据源的;而 Proxy 方式表示浏览器先访问 Grafana 的某个代理接口(接口地址是 /api/datasources/proxy/),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。
Nach der Konfiguration der Datenquelle stellt Grafana mehrere konfigurierte Panels zur Verfügung, die Sie standardmäßig verwenden können. Wie in der Abbildung unten gezeigt, werden standardmäßig drei Panels bereitgestellt: Prometheus Stats, Prometheus 2.0 Stats und Grafana-Metriken. Klicken Sie auf „Importieren“, um dieses Panel zu importieren und zu verwenden.
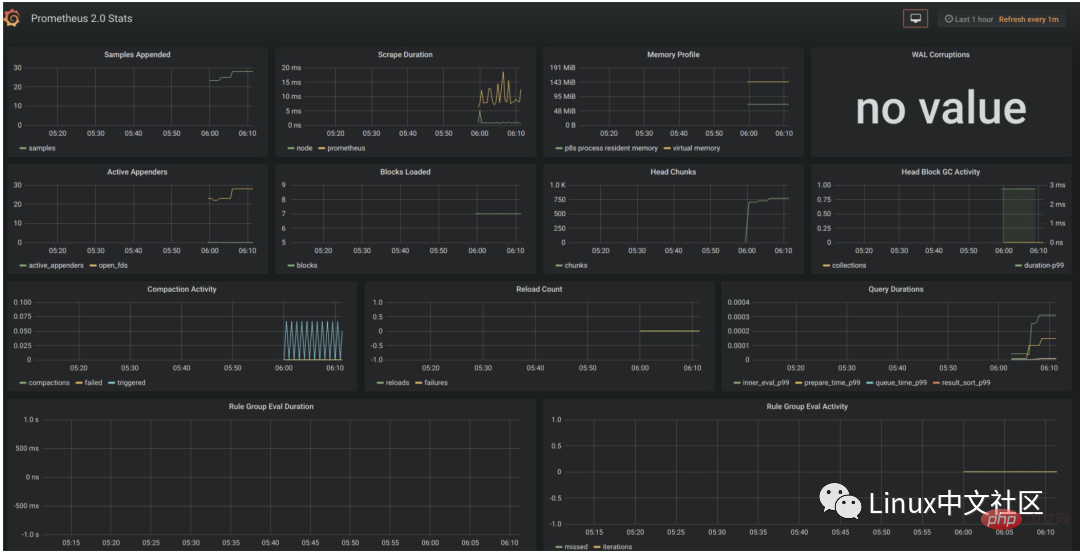
Was wir bisher gesehen haben, sind nur einige Indikatoren, die keinen praktischen Nutzen haben. Wenn wir Prometheus wirklich in unserer Produktionsumgebung verwenden wollen, brauchen wir das oft Achten Sie auf verschiedene Indikatoren, z. B. CPU-Auslastung des Servers, Speichernutzung, E/A-Overhead, ein- und ausgehender Netzwerkverkehr usw.
Wie oben erwähnt, verwendet Prometheus die Pull-Methode, um Indikatordaten abzurufen. Damit Prometheus Daten vom Ziel abrufen kann, müssen Sie zunächst das Indikatorerfassungsprogramm auf dem Ziel installieren und die HTTP-Schnittstelle für die Abfrage dieses Indikators verfügbar machen Das Erfassungsprogramm wird als Exporter bezeichnet. Für die Erfassung verschiedener Indikatoren sind derzeit zahlreiche Exporter verfügbar, die nahezu alle Arten von Systemen und Software abdecken, die wir üblicherweise verwenden.
Die offizielle Website listet eine Liste häufig verwendeter Exporter auf, um Portkonflikte zu vermeiden, d. h. beginnend mit 9100 und aufsteigend. Hier ist die vollständige Exporter-Portliste. Es ist auch erwähnenswert, dass einige Software und Systeme Exporter nicht installieren müssen, da sie selbst die Funktion zum Offenlegen von Indikatordaten im Prometheus-Format bereitstellen, wie z. B. Kubernetes, Grafana, Etcd, Ceph usw.
这一节就让我们来收集一些有用的数据。
首先我们来收集服务器的指标,这需要安装 node_exporter,这个 exporter 用于收集 *NIX 内核的系统,如果你的服务器是 Windows,可以使用 WMI exporter。
和 Prometheus server 一样,node_exporter 也是开箱即用的:
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz $ tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz $ cd node_exporter-0.16.0.linux-amd64 $ ./node_exporter
node_exporter 启动之后,我们访问下 /metrics 接口看看是否能正常获取服务器指标:
$ curl http://localhost:9100/metrics
如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到 scrape_configs 中:
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['192.168.0.107:9090'] - job_name: 'server' static_configs: - targets: ['192.168.0.107:9100']
修改配置后,需要重启 Prometheus 服务,或者发送 HUP 信号也可以让 Prometheus 重新加载配置:
$ killall -HUP prometheus
在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器:
在 Graph 页面的指标下拉框可以看到很多名称以 node 开头的指标,譬如我们输入 node_load1 观察服务器负载:
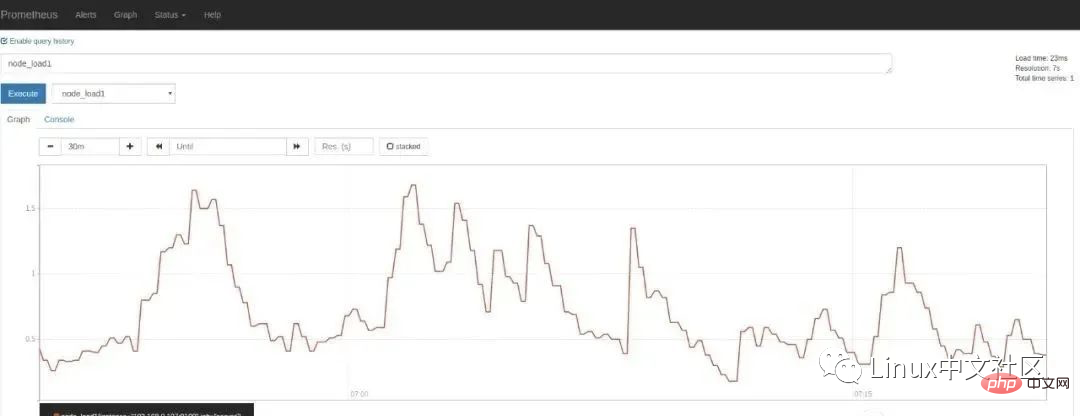
如果想在 Grafana 中查看服务器的指标,可以在 Grafana 的 Dashboards 页面 搜索 node exporter,有很多的面板模板可以直接使用,譬如:Node Exporter Server Metrics 或者 Node Exporter Full 等。我们打开 Grafana 的 Import dashboard 页面,输入面板的 URL(https://grafana.com/dashboards/405)或者 ID(405)即可。
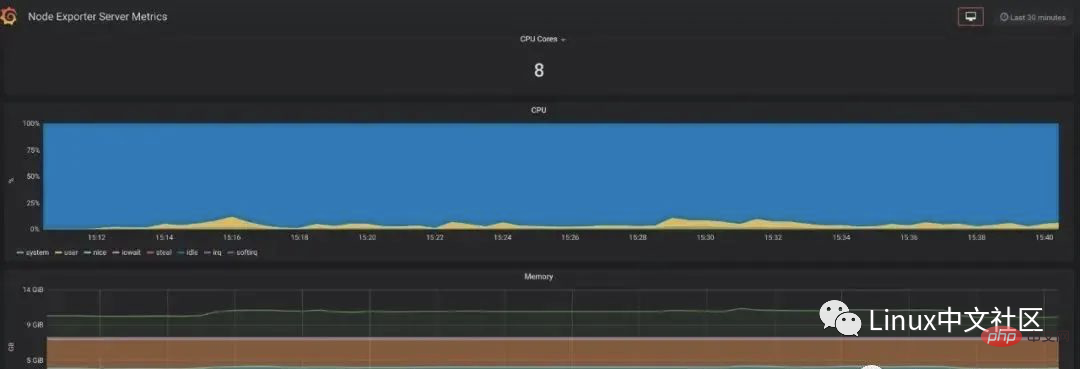
一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
docker run -d \ --net="host" \ --pid="host" \ -v "/:/host:ro,rslave" \ quay.io/prometheus/node-exporter \ --path.rootfs /host
关于 node_exporter 的更多信息,可以参考 node_exporter 的文档 和 Prometheus 的官方指南 Monitoring Linux host metrics with the Node Exporter,另外,Julius Volz 的这篇文章 How To Install Prometheus using Docker on Ubuntu 14.04 也是很好的入门材料。
mysqld_exporter 是 Prometheus 官方提供的一个 exporter,我们首先 下载最新版本 并解压(开箱即用):
$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz $ tar xvfz mysqld_exporter-0.11.0.linux-amd64.tar.gz $ cd mysqld_exporter-0.11.0.linux-amd64/
mysqld_exporter 需要连接到 mysqld 才能收集它的指标,可以通过两种方式来设置 mysqld 数据源。第一种是通过环境变量 DATA_SOURCE_NAME,这被称为 DSN(数据源名称),它必须符合 DSN 的格式,一个典型的 DSN 格式像这样:user:password@(host:port)/。
$ export DATA_SOURCE_NAME='root:123456@(192.168.0.107:3306)/' $ ./mysqld_exporter
另一种方式是通过配置文件,默认的配置文件是 ~/.my.cnf,或者通过 --config.my-cnf 参数指定:
$ ./mysqld_exporter --config.my-cnf=".my.cnf"
配置文件的格式如下:
$ cat .my.cnf [client] host=localhost port=3306 user=root password=123456
如果要把 MySQL 的指标导入 Grafana,可以参考 这些 Dashboard JSON。另外,MySQL 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
这里为简单起见,在 mysqld_exporter 中直接使用了 root 连接数据库,在真实环境中,可以为 mysqld_exporter 创建一个单独的用户,并赋予它受限的权限(PROCESS、REPLICATION CLIENT、SELECT),最好还限制它的最大连接数(MAX_USER_CONNECTIONS)。
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
官方提供了两种收集 Nginx 指标的方式。另外,Nginx 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
第一种是 Nginx metric library,这是一段 Lua 脚本(prometheus.lua),Nginx 需要开启 Lua 支持(libnginx-mod-http-lua 模块)。为方便起见,也可以使用 OpenResty 的 OPM(OpenResty Package Manager) 或者 luarocks(The Lua package manager) 来安装。
第二种是 Nginx VTS exporter,这种方式比第一种要强大的多,安装要更简单,支持的指标也更丰富,它依赖于 nginx-module-vts 模块,vts 模块可以提供大量的 Nginx 指标数据,可以通过 JSON、HTML 等形式查看这些指标。Nginx VTS exporter 就是通过抓取 /status/format/json 接口来将 vts 的数据格式转换为 Prometheus 的格式。
Allerdings wurde der neuesten Version von nginx-module-vts eine neue Schnittstelle hinzugefügt: /status/format/prometheus,这个接口可以直接返回 Prometheus 的格式,从这点这也能看出 Prometheus 的影响力,估计 Nginx VTS exporter 很快就要退役了(TODO:待验证)。
除此之外,还有很多其他的方式来收集 Nginx 的指标,比如:nginx_exporter 通过抓取 Nginx 自带的统计页面 /nginx_status 可以获取一些比较简单的指标(需要开启 ngx_http_stub_status_module 模块);nginx_request_exporter 通过 syslog 协议 收集并分析 Nginx 的 access log 来统计 HTTP 请求相关的一些指标;nginx-prometheus-shiny-exporter 和 nginx_request_exporter 类似,也是使用 syslog 协议来收集 access log,不过它是使用 Crystal 语言 写的。还有 vovolie/lua-nginx-prometheus
nginx_request_exporter Sammelt und analysiert das Nginx-Zugriffsprotokoll über das Syslog-Protokoll, um Statistiken zu HTTP-Anfragen zu sammeln. Einige Indikatoren;nginx-prometheus-shiny-exporter und nginx_request_exporter Ähnlich verwendet es auch das Syslog-Protokoll zum Sammeln von Zugriffsprotokollen, ist jedoch in der Crystal-Sprache geschrieben . Auch vovolie/lua-nginx-prometheus Basierend auf Openresty, Prometheus, Consul, Grafana implementiert Verkehrsstatistiken auf Domänennamen- und Endpunktebene. Studenten, die es benötigen oder interessiert sind, können es anhand der Dokumentation selbst installieren und erleben, aber ich werde es hier nicht einzeln ausprobieren. 🎜最后让我们来看下如何收集 Java 应用的指标,Java 应用的指标一般是通过 JMX(Java Management Extensions) 来获取的,顾名思义,JMX 是管理 Java 的一种扩展,它可以方便的管理和监控正在运行的 Java 程序。
JMX Exporter 用于收集 JMX 指标,很多使用 Java 的系统,都可以使用它来收集指标,比如:Kafaka、Cassandra 等。首先我们下载 JMX Exporter:
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar
JMX Exporter 是一个 Java Agent 程序,在运行 Java 程序时通过 -javaagent 参数来加载:
$ java -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9404:config.yml -jar spring-boot-sample-1.0-SNAPSHOT.jar
其中,9404 是 JMX Exporter 暴露指标的端口,config.yml 是 JMX Exporter 的配置文件,它的内容可以 参考 JMX Exporter 的配置说明 。
然后检查下指标数据是否正确获取:
$ curl http://localhost:9404/metrics
至此,我们能收集大量的指标数据,也能通过强大而美观的面板展示出来。不过作为一个监控系统,最重要的功能,还是应该能及时发现系统问题,并及时通知给系统负责人,这就是 Alerting(告警)。
Prometheus 的告警功能被分成两部分:一个是告警规则的配置和检测,并将告警发送给 Alertmanager,另一个是 Alertmanager,它负责管理这些告警,去除重复数据,分组,并路由到对应的接收方式,发出报警。常见的接收方式有:Email、PagerDuty、HipChat、Slack、OpsGenie、WebHook 等。
我们在上面介绍 Prometheus 的配置文件时了解到,它的默认配置文件 prometheus.yml 有四大块:global、alerting、rule_files、scrape_config,其中 rule_files 块就是告警规则的配置项,alerting 块用于配置 Alertmanager,这个我们下一节再看。现在,先让我们在 rule_files 块中添加一个告警规则文件:
rule_files: - "alert.rules"
然后参考 官方文档,创建一个告警规则文件 alert.rules:
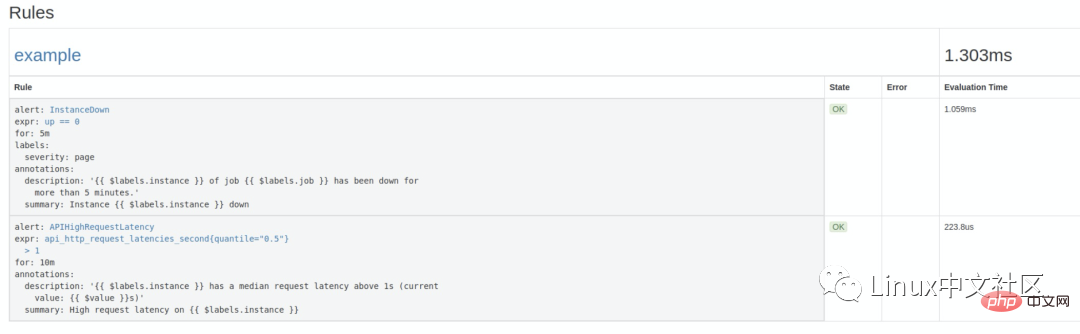
groups: - name: example rules: # Alert for any instance that is unreachable for >5 minutes. - alert: InstanceDown expr: up == 0 for: 5m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes." # Alert for any instance that has a median request latency >1s. - alert: APIHighRequestLatency expr: api_http_request_latencies_second{quantile="0.5"} > 1 for: 10m annotations: summary: "High request latency on {{ $labels.instance }}" description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"这个规则文件里,包含了两条告警规则:InstanceDown 和 APIHighRequestLatency。顾名思义,InstanceDown 表示当实例宕机时(up === 0)触发告警,APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警。
搜索公众号GitHub猿回复“理财”,送你一份惊喜礼包。
配置好后,需要重启下 Prometheus server,然后访问 http://localhost:9090/rules 可以看到刚刚配置的规则:
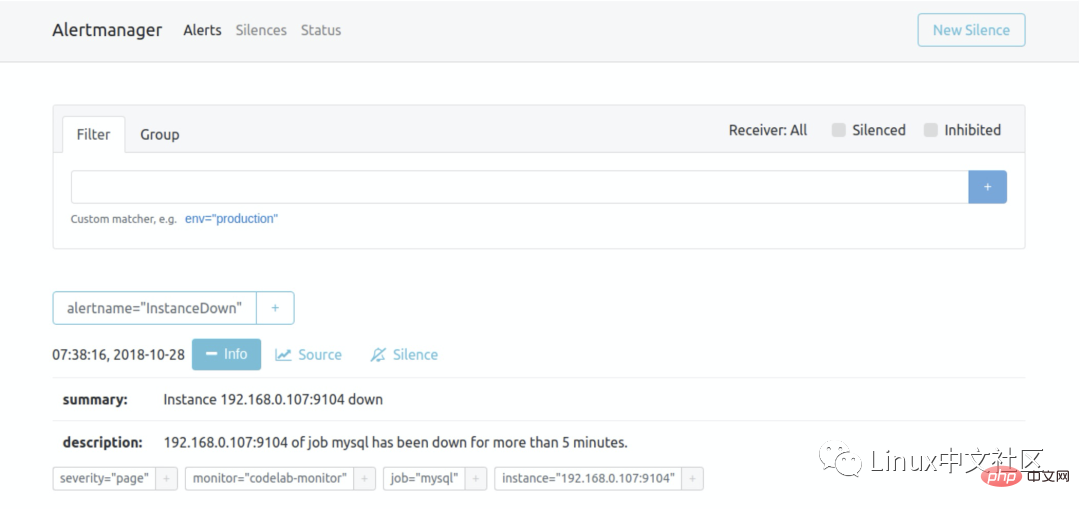
访问 http://localhost:9090/alerts 可以看到根据配置的规则生成的告警:
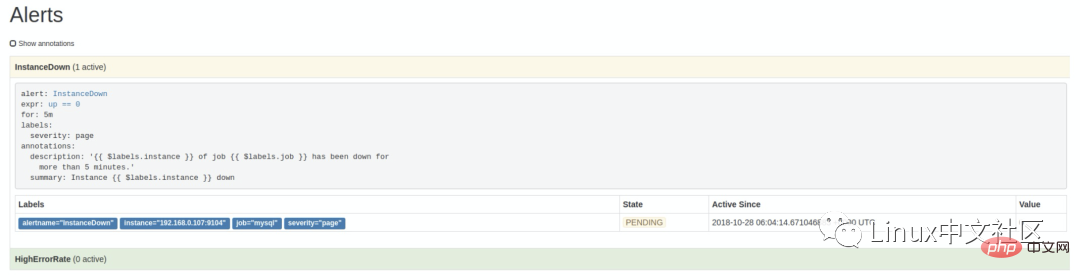
这里我们将一个实例停掉,可以看到有一条 alert 的状态是 PENDING,这表示已经触发了告警规则,但还没有达到告警条件。这是因为这里配置的 for 参数是 5m,也就是 5 分钟后才会触发告警,我们等 5 分钟,可以看到这条 alert 的状态变成了 FIRING。
虽然 Prometheus 的 <span style="outline: 0px;color: rgb(0, 0, 0);">/alerts</span> 页面可以看到所有的告警,但是还差最后一步:触发告警时自动发送通知。这是由 Alertmanager 来完成的,我们首先 下载并安装 Alertmanager,和其他 Prometheus 的组件一样,Alertmanager 也是开箱即用的:
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz $ tar xvfz alertmanager-0.15.2.linux-amd64.tar.gz $ cd alertmanager-0.15.2.linux-amd64 $ ./alertmanager
Alertmanager 启动后默认可以通过 http://localhost:9093/ 来访问,但是现在还看不到告警,因为我们还没有把 Alertmanager 配置到 Prometheus 中,我们回到 Prometheus 的配置文件 prometheus.yml,添加下面几行:
alerting: alertmanagers: - scheme: http static_configs: - targets: - "192.168.0.107:9093"
这个配置告诉 Prometheus,当发生告警时,将告警信息发送到 Alertmanager,Alertmanager 的地址为 http://192.168.0.107:9093。也可以使用命名行的方式指定 Alertmanager:
$ ./prometheus -alertmanager.url=http://192.168.0.107:9093
这个时候再访问 Alertmanager,可以看到 Alertmanager 已经接收到告警了:
下面的问题就是如何让 Alertmanager 将告警信息发送给我们了,我们打开默认的配置文件 alertmanager.ym:
global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
参考 官方的配置手册 了解各个配置项的功能,其中 global 块表示一些全局配置;route 块表示通知路由,可以根据不同的标签将告警通知发送给不同的 receiver,这里没有配置 routes 项,表示所有的告警都发送给下面定义的 web.hook 这个 receiver;如果要配置多个路由,可以参考 这个例子:
routes: - receiver: 'database-pager' group_wait: 10s match_re: service: mysql|cassandra - receiver: 'frontend-pager' group_by: [product, environment] match: team: frontend
紧接着,receivers 块表示告警通知的接收方式,每个 receiver 包含一个 name 和一个 xxx_configs,不同的配置代表了不同的接收方式,Alertmanager 内置了下面这些接收方式:
while Empfangen Es gibt viele Möglichkeiten, sie zu empfangen, aber die meisten davon werden in China selten genutzt. Die am häufigsten verwendete ist, dass email_config 和 webhook_config,另外 wechat_configs die Verwendung von WeChat zur Alarmierung unterstützen kann, was auch durchaus den nationalen Gegebenheiten entspricht.
Tatsächlich ist es schwierig, eine umfassende Alarmbenachrichtigungsmethode bereitzustellen, da es verschiedene Messaging-Software gibt und jedes Land anders sein kann, sodass es unmöglich ist, diese vollständig abzudecken. Daher hat Alertmanager beschlossen, keine neue hinzuzufügen Es wird jedoch empfohlen, Webhooks zu verwenden, um benutzerdefinierte Empfangsmethoden zu integrieren. Sie können sich auf diese Integrationsbeispiele beziehen, z. B. auf die Verbindung von DingTalk mit Prometheus AlertManager WebHook.
Bis jetzt haben wir gelernt, dass die Kombination von Prometheus + Grafana + Alertmanager ein sehr vollständiges Überwachungssystem aufbauen kann. Bei der tatsächlichen Verwendung werden wir jedoch auf weitere Probleme stoßen.
Da Prometheus aktiv Überwachungsdaten über Pull erhält, muss die Liste der Überwachungsknoten manuell angegeben werden. Wenn die Anzahl der überwachten Knoten zunimmt, muss die Konfigurationsdatei jedes Mal geändert werden, wenn ein Knoten hinzugefügt wird. Dies ist sehr problematisch und muss über den Service Discovery (SD)-Mechanismus gelöst werden.
Prometheus unterstützt mehrere Service-Erkennungsmechanismen und kann die zu erfassenden Ziele automatisch abrufen. Zu den enthaltenen Service-Erkennungsmechanismen gehören: Azure, Consul, DNS, EC2, OpenStack, File, GCE, Kubernetes, Marathon, Triton , zookeeper (nerve, serverset). Informationen zur Konfigurationsmethode finden Sie auf der Konfigurationsseite des Handbuchs. Man kann sagen, dass der SD-Mechanismus sehr umfangreich ist, aber derzeit werden aufgrund begrenzter Entwicklungsressourcen keine neuen SD-Mechanismen mehr entwickelt und nur dateibasierte SD-Mechanismen gepflegt.
Es gibt viele Tutorials zum Thema Service Discovery im Internet. Dieser Artikel im offiziellen Prometheus-Blog, Advanced Service Discovery in Prometheus 0.14.0, enthält beispielsweise eine relativ systematische Einführung und erklärt umfassend die Relabeling-Konfiguration und wie um DNS-SRV und Consul und Dateien zur Diensterkennung zu verwenden.
Darüber hinaus bietet die offizielle Website auch ein Einführungsbeispiel für die dateibasierte Diensterkennung. Das von Julius Volz verfasste Einführungs-Tutorial zum Prometheus-Workshop verwendet auch DNS-SRV für die Diensterkennung. Darüber hinaus wurden die Interviewfragen und -antworten der Microservice-Serie auf WeChat nach Internetarchitekten gesucht und im Hintergrund gesendet, die online gelesen werden können.
Unabhängig von der Konfiguration von Prometheus oder der Konfiguration von Alertmanager gibt es keine API, die wir dynamisch ändern können. Ein sehr häufiges Szenario besteht darin, dass wir ein Alarmsystem mit anpassbaren Regeln basierend auf Prometheus erstellen müssen. Benutzer können auf der Seite Alarmregeln gemäß ihren eigenen Anforderungen erstellen, ändern oder löschen oder die Alarmbenachrichtigungsmethode und die Kontaktperson ändern, wie in Frage dieses Benutzers in Prometheus Google Groups: Wie füge ich dynamisch Warnregeln in der Datei „rules.conf“ und „prometheus yml“ über eine API oder ähnliches hinzu?
Allerdings sagte Simon Pasquier unten leider, dass es derzeit keine solche API gibt und es auch keine Pläne gibt, eine solche API in Zukunft zu entwickeln, da solche Funktionen an Tools wie Puppet, Chef, Ansible, übergeben werden sollten. und Salt. Ein solches Konfigurationsmanagementsystem.
Dieser Blog bezieht sich auf eine große Anzahl chinesischer Materialien über Prometheus im Internet, darunter Dokumente und Blogs, wie das inoffizielle chinesische Handbuch von Prometheus von 1046102779, Song Jiayangs E-Book „Prometheus in Action“ , hier ein großes Lob an diese Originalautoren. Die Medienseite der offiziellen Prometheus-Dokumentation bietet außerdem viele Lernressourcen.
In Bezug auf Prometheus gibt es noch einen sehr wichtigen Teil, der in diesem Blog nicht behandelt wurde. Wie zu Beginn des Blogs erwähnt, ist Prometheus nach Kubernetes das zweite Projekt, das CNCF beitritt. Die Integration von Prometheus mit Docker und Kubernetes steht kurz bevor. Der Einsatz von Prometheus als Überwachungssystem für Docker und Kubernetes wird immer mehr zum Mainstream.
Informationen zur Docker-Überwachung finden Sie auf der offiziellen Website: Überwachen von Docker-Container-Metriken mit cAdvisor, in der erläutert wird, wie Sie cAdvisor zur Überwachung von Containern verwenden. Bitte beachten Sie: Dockers offizielle Website: Sammeln Sie Docker-Metriken mit Prometheus. In Bezug auf die Kubernetes-Überwachung gibt es in der chinesischen Kubernetes-Community viele Ressourcen. Darüber hinaus enthält das E-Book „How to Monitor Kubernetes with Elegant Posture“ auch eine relativ umfassende Einführung in Kubernetes Überwachung.
In den letzten zwei Jahren hat sich Prometheus sehr schnell entwickelt, auch die Community ist sehr aktiv und immer mehr Menschen in China studieren Prometheus. Mit der Popularisierung von Konzepten wie Microservices, DevOps, Cloud Computing und Cloud Native beginnen immer mehr Unternehmen, Docker und Kubernetes zum Aufbau eigener Systeme und Anwendungen zu verwenden. Alte Überwachungssysteme wie Nagios und Cacti werden immer beliebter Je weniger anwendbar es ist, desto mehr glaube ich, dass sich Prometheus irgendwann zu einem Überwachungssystem entwickeln wird, das am besten für Cloud-Umgebungen geeignet ist.
Wie oben erwähnt, ist Prometheus ein Überwachungssystem, das auf einer Zeitreihendatenbank basiert. Die Zeitreihendatenbank wird oft als TSDB (Time Series Database) abgekürzt. Viele gängige Überwachungssysteme verwenden Zeitreihendatenbanken zum Speichern von Daten, da die Eigenschaften von Zeitreihendatenbanken mit denen von Überwachungssystemen übereinstimmen.
InfluxDB: https://influxdata.com/
Das obige ist der detaillierte Inhalt vonDas als Überwachungssystem der nächsten Generation bekannte System – mal sehen, wie leistungsstark es ist!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



