


Hohe Parallelität und schnelle Reaktion entsprechen den beiden Kernindikatoren der Leistungsoptimierung: Durchsatz und Latenz

Der Kern des Leistungsproblems besteht darin, dass die Systemressourcen den Engpass erreicht haben, die Anforderungsverarbeitung jedoch nicht schnell genug ist, um weitere Anforderungen zu unterstützen. Bei der Leistungsanalyse geht es eigentlich darum, die Engpässe der Anwendung oder des Systems zu finden und zu versuchen, diese zu vermeiden oder zu lindern.
Der unterbrechungsfreie Zustand ist eigentlich ein Schutzmechanismus des Systems für Prozesse und Hardwaregeräte.
CPU-intensive Prozesse führen zu einem Anstieg der durchschnittlichen Auslastung Zu diesem Zeitpunkt ist die CPU-Auslastung nicht unbedingt hoch. Eine große Anzahl von Prozessen, die auf die CPU-Planung warten, führt zu einem Anstieg der durchschnittlichen Last Mit der Zeit wird auch die CPU-Auslastung relativ hoch sein
Der Linux-Prozess unterteilt den laufenden Bereich des Prozesses entsprechend in Kernelraum und Benutzerraum Berechtigungsstufe. Der Übergang vom Benutzermodus zum Kernelmodus muss durch Systemaufrufe abgeschlossen werden.
Ein Systemaufrufprozess führt tatsächlich zwei CPU-Kontextwechsel durch:
Der Systemaufrufprozess umfasst keine Prozessbenutzermodusressourcen wie virtuellen Speicher und wechselt auch nicht den Prozess. Es unterscheidet sich vom Prozesskontextwechsel im herkömmlichen Sinne. Daher wird der Systemaufruf oft als privilegierter Moduswechsel bezeichnet .
Prozesse werden vom Kernel verwaltet und geplant, und der Prozesskontextwechsel kann nur im Kernelmodus erfolgen. Daher müssen im Vergleich zu Systemaufrufen vor dem Speichern des Kernelstatus und der CPU-Register des aktuellen Prozesses zunächst der virtuelle Speicher und der Stapel des Prozesses gespeichert werden. Nach dem Laden des Kernelstatus des neuen Prozesses müssen der virtuelle Speicher und der Benutzerstapel des Prozesses aktualisiert werden.
Der Prozess muss nur dann den Kontext wechseln, wenn die Ausführung auf der CPU geplant ist. Es gibt die folgenden Szenarien: CPU-Zeitscheiben werden abwechselnd zugewiesen, unzureichende Systemressourcen führen dazu, dass der Prozess hängt, der Prozess bleibt aktiv während der Ruhezustandsfunktion hängen und Vorlaufzeit für Prozesse mit hoher Priorität. Wenn ein Hardware-Interrupt auftritt, wird der Prozess auf der CPU angehalten und führt stattdessen den Interrupt-Dienst im Kernel aus.
Thread-Kontextwechsel ist in zwei Typen unterteilt:
Thread-Wechsel im selben Prozess verbraucht weniger Ressourcen, was auch der Vorteil von Multithreading ist.
Der Interrupt-Kontextwechsel betrifft nicht den Benutzerstatus des Prozesses, sodass der Interrupt-Kontext nur den Status enthält, der für die Ausführung des Kernel-Status-Interrupt-Dienstprogramms erforderlich ist (CPU-Register, Kernel-Stack, Hardware-Interrupt). Parameter usw.).
Die Priorität der Interrupt-Verarbeitung ist höher als die des Prozesses, sodass Interrupt-Kontextwechsel und Prozesskontextwechsel nicht gleichzeitig stattfinden
Sie können die allgemeine Kontextwechselsituation des Systems über vmstat überprüfen
vmstat 5 #每隔5s输出一组数据 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 103388 145412 511056 0 0 18 60 1 1 2 1 96 0 0 0 0 0 103388 145412 511076 0 0 0 2 450 1176 1 1 99 0 0 0 0 0 103388 145412 511076 0 0 0 8 429 1135 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 0 431 1132 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 10 467 1195 1 1 98 0 0 1 0 0 103388 145412 511076 0 0 0 2 426 1139 1 0 99 0 0 4 0 0 95184 145412 511108 0 0 0 74 500 1228 4 1 94 0 0 0 0 0 103512 145416 511076 0 0 0 455 723 1573 12 3 83 2 0
So zeigen Sie die Details jedes Prozesses an: In diesem Fall müssen Sie pidstat verwenden, um den Kontextwechsel jedes Prozesses anzuzeigen
pidstat -w 5 14时51分16秒 UID PID cswch/s nvcswch/s Command 14时51分21秒 0 1 0.80 0.00 systemd 14时51分21秒 0 6 1.40 0.00 ksoftirqd/0 14时51分21秒 0 9 32.67 0.00 rcu_sched 14时51分21秒 0 11 0.40 0.00 watchdog/0 14时51分21秒 0 32 0.20 0.00 khugepaged 14时51分21秒 0 271 0.20 0.00 jbd2/vda1-8 14时51分21秒 0 1332 0.20 0.00 argusagent 14时51分21秒 0 5265 10.02 0.00 AliSecGuard 14时51分21秒 0 7439 7.82 0.00 kworker/0:2 14时51分21秒 0 7906 0.20 0.00 pidstat 14时51分21秒 0 8346 0.20 0.00 sshd 14时51分21秒 0 20654 9.82 0.00 AliYunDun 14时51分21秒 0 25766 0.20 0.00 kworker/u2:1 14时51分21秒 0 28603 1.00 0.00 python3
vmstat 1 1 #首先获取空闲系统的上下文切换次数 sysbench --threads=10 --max-time=300 threads run #模拟多线程切换问题 vmstat 1 1 #新终端观察上下文切换情况 此时发现cs数据明显升高,同时观察其他指标: r列: 远超系统CPU个数,说明存在大量CPU竞争 us和sy列:sy列占比80%,说明CPU主要被内核占用 in列: 中断次数明显上升,说明中断处理也是潜在问题
说明运行/等待CPU的进程过多,导致大量的上下文切换,上下文切换导致系统的CPU占用率高
pidstat -w -u 1 #查看到底哪个进程导致的问题
从结果中看出是sysbench导致CPU使用率过高,但是pidstat输出的上下文次数加起来也并不多。分析sysbench模拟的是线程的切换,因此需要在pidstat后加-t参数查看线程指标。
另外对于中断次数过多,我们可以通过/proc/interrupts文件读取
watch -d cat /proc/interrupts
发现次数变化速度最快的是重调度中断(RES),该中断用来唤醒空闲状态的CPU来调度新的任务运行。分析还是因为过多任务的调度问题,和上下文切换分析一致。
Linux, als Multitasking-Betriebssystem, teilt die CPU-Zeit in kurze Zeitscheiben auf und weist diese über den Scheduler der Reihe nach jeder Aufgabe zu. Um die CPU-Zeit aufrechtzuerhalten, löst Linux Zeitunterbrechungen durch vordefinierte Beat-Raten aus und verwendet globale Jiffies, um die Anzahl der Beats seit dem Booten aufzuzeichnen. Die Zeitunterbrechung erfolgt, sobald dieser Wert + 1.
CPU-Auslastung , der Prozentsatz der gesamten CPU-Zeit außer der Leerlaufzeit. Die CPU-Auslastung kann anhand der Daten in /proc/stat berechnet werden. Denn der kumulative Wert der Anzahl der Beats seit dem Booten in /proc/stat wird als durchschnittliche CPU-Auslastung seit dem Booten berechnet, was im Allgemeinen von geringer Aussagekraft ist. Sie können die durchschnittliche CPU-Auslastung während dieses Zeitraums berechnen, indem Sie die Differenz zwischen zwei Werten ermitteln, die in Abständen eines Zeitraums ermittelt wurden. Das Leistungsanalysetool gibt die durchschnittliche CPU-Auslastung über einen bestimmten Zeitraum an. Achten Sie auf die Einstellung des Intervalls.
Die CPU-Auslastung kann über top oder ps angezeigt werden. Sie können die CPU-Probleme des Prozesses mithilfe von Perf analysieren, das auf der Stichprobenerhebung von Leistungsereignissen basiert. Es kann nicht nur verschiedene Ereignisse des Systems und der Kernelleistung analysieren, sondern auch zur Analyse der Leistungsprobleme bestimmter Anwendungen verwendet werden.
Perf Top / Perf Record / Perf Report (-g aktiviert die Stichprobe von Anrufbeziehungen)
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm ab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能
发现此时每秒可承受请求给长少,此时将测试的请求数从100增加到10000。在另外一个终端运行top查看每个CPU的使用率。发现系统中几个php-fpm进程导致CPU使用率骤升。
接着用perf来分析具体是php-fpm中哪个函数导致该问题。
perf top -g -p XXXX #对某一个php-fpm进程进行分析
发现其中sqrt和add_function占用CPU过多, 此时查看源码找到原来是sqrt中在发布前没有删除测试代码段,存在一个百万次的循环导致。将该无用代码删除后发现nginx负载能力明显提升
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx:sp sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp ab -c 100 -n 1000 http://XXX.XXX.XXX.XXX:10000/ #并发100个请求测试
实验结果中每秒请求数依旧不高,我们将并发请求数降为5后,nginx负载能力依旧很低。
此时用top和pidstat发现系统CPU使用率过高,但是并没有发现CPU使用率高的进程。
出现这种情况一般时我们分析时遗漏的什么信息,重新运行top命令并观察一会。发现就绪队列中处于Running状态的进行过多,超过了我们的并发请求次数5. 再仔细查看进程运行数据,发现nginx和php-fpm都处于sleep状态,真正处于运行的却是几个stress进程。
下一步就利用pidstat分析这几个stress进程,发现没有任何输出。用ps aux交叉验证发现依旧不存在该进程。说明不是工具的问题。再top查看发现stress进程的进程号变化了,此时有可能时以下两种原因导致:
可以通过pstree来查找 stress的父进程,找出调用关系。
pstree | grep stress
发现是php-fpm调用的该子进程,此时去查看源码可以看出每个请求都会调用一个stress命令来模拟I/O压力。之前top显示的结果是CPU使用率升高,是否真的是由该stress命令导致的,还需要继续分析。代码中给每个请求加了verbose=1的参数后可以查看stress命令的输出,在中断测试该命令结果显示stress命令运行时存在因权限问题导致的文件创建失败的bug。
Dies ist immer noch nur eine Vermutung. Der nächste Schritt besteht darin, die Analyse mit dem Perf-Tool fortzusetzen. Der Leistungsbericht zeigt, dass Stress tatsächlich viel CPU beansprucht, was durch die Behebung des Berechtigungsproblems gelöst werden kann.
对于不可中断状态,一般都是在很短时间内结束,可忽略。但是如果系统或硬件发生故障,进程可能会保持不可中断状态很久,甚至系统中出现大量不可中断状态,此时需注意是否出现了I/O性能问题。
僵尸进程一般多进程应用容易遇到,父进程来不及处理子进程状态时子进程就提前退出,此时子进程就变成了僵尸进程。大量的僵尸进程会用尽PID进程号,导致新进程无法建立。
sudo docker run --privileged --name=app -itd feisky/app:iowait ps aux | grep '/app'
可以看到此时有多个app进程运行,状态分别时Ss+和D+。其中后面s表示进程是一个会话的领导进程,+号表示前台进程组。
其中进程组表示一组相互关联的进程,子进程是父进程所在组的组员。会话指共享同一个控制终端的一个或多个进程组。
用top查看系统资源发现:1)平均负载在逐渐增加,且1分钟内平均负载达到了CPU个数,说明系统可能已经有了性能瓶颈;2)僵尸进程比较多且在不停增加;3)us和sys CPU使用率都不高,iowait却比较高;4)每个进程CPU使用率也不高,但有两个进程处于D状态,可能在等待IO。
分析目前数据可知:iowait过高导致系统平均负载升高,僵尸进程不断增长说明有程序没能正确清理子进程资源。
用dstat来分析,因为它可以同时查看CPU和I/O两种资源的使用情况,便于对比分析。
dstat 1 10 #间隔1秒输出10组数据
可以看到当wai(iowait)升高时磁盘请求read都会很大,说明iowait的升高和磁盘的读请求有关。接下来分析到底时哪个进程在读磁盘。
之前top查看的处于D状态的进程号,用pidstat -d -p XXX 展示进程的I/O统计数据。发现处于D状态的进程都没有任何读写操作。在用pidstat -d 查看所有进程的I/O统计数据,看到app进程在进行磁盘读操作,每秒读取32MB的数据。进程访问磁盘必须使用系统调用处于内核态,接下来重点就是找到app进程的系统调用。
sudo strace -p XXX #对app进程调用进行跟踪
报错没有权限,因为已经时root权限了。所以遇到这种情况,首先要检查进程状态是否正常。ps命令查找该进程已经处于Z状态,即僵尸进程。
这种情况下top pidstat之类的工具无法给出更多的信息,此时像第5篇一样,用perf record -d和perf report进行分析,查看app进程调用栈。
看到app确实在通过系统调用sys_read()读取数据,并且从new_sync_read和blkdev_direct_IO看出进程时进行直接读操作,请求直接从磁盘读,没有通过缓存导致iowait升高。
Nach einer schichtweisen Analyse liegt die Hauptursache im direkten Festplatten-I/O innerhalb der App. Suchen Sie dann den spezifischen Codespeicherort zur Optimierung.
Nach der oben genannten Optimierung ist Iowait deutlich zurückgegangen, aber die Anzahl der Zombie-Prozesse nimmt immer noch zu. Suchen Sie zunächst den übergeordneten Prozess des Zombie-Prozesses. Drucken Sie mit pstree -aps XXX den Aufrufbaum des Zombie-Prozesses aus und stellen Sie fest, dass der übergeordnete Prozess der App-Prozess ist.
Überprüfen Sie den App-Code, um zu sehen, ob das Ende des untergeordneten Prozesses korrekt behandelt wird (ob wait()/waitpid() aufgerufen wird, ob eine SIGCHILD-Signalverarbeitungsfunktion registriert ist usw.).
Wenn Sie auf einen Anstieg von Iowait stoßen, verwenden Sie zunächst Tools wie dstat und pidstat, um zu bestätigen, ob ein Festplatten-E/A-Problem vorliegt, und finden Sie dann heraus, welche Prozesse das E/A verursachen. Wenn Sie strace nicht verwenden können Analysieren Sie den Prozessaufruf direkt. Sie können ihn mit dem Perf-Tool analysieren.
Für das Zombie-Problem verwenden Sie pstree, um den übergeordneten Prozess zu finden, und sehen Sie sich dann den Quellcode an, um die Verarbeitungslogik für das Ende des untergeordneten Prozesses zu überprüfen.
CPU-Auslastung
Einschließlich freiwilliger Umschaltung, wenn Ressourcen nicht abgerufen werden können, und unfreiwilliger Umschaltung, wenn das System die Planung selbst erzwingt, ist eine Kernfunktion, um den normalen Betrieb von Linux sicherzustellen. Übermäßiges Umschalten verbraucht die CPU-Zeit des ursprünglich laufenden Prozesses im Register und im Kernel In Bezug auf das Speichern und Wiederherstellen von Daten wie dem virtuellen Speicher (CPU-Cache-Trefferrate) ist die Leistung umso besser, je höher die Trefferrate ist Kern, und L3 wird in Multi-Core verwendet
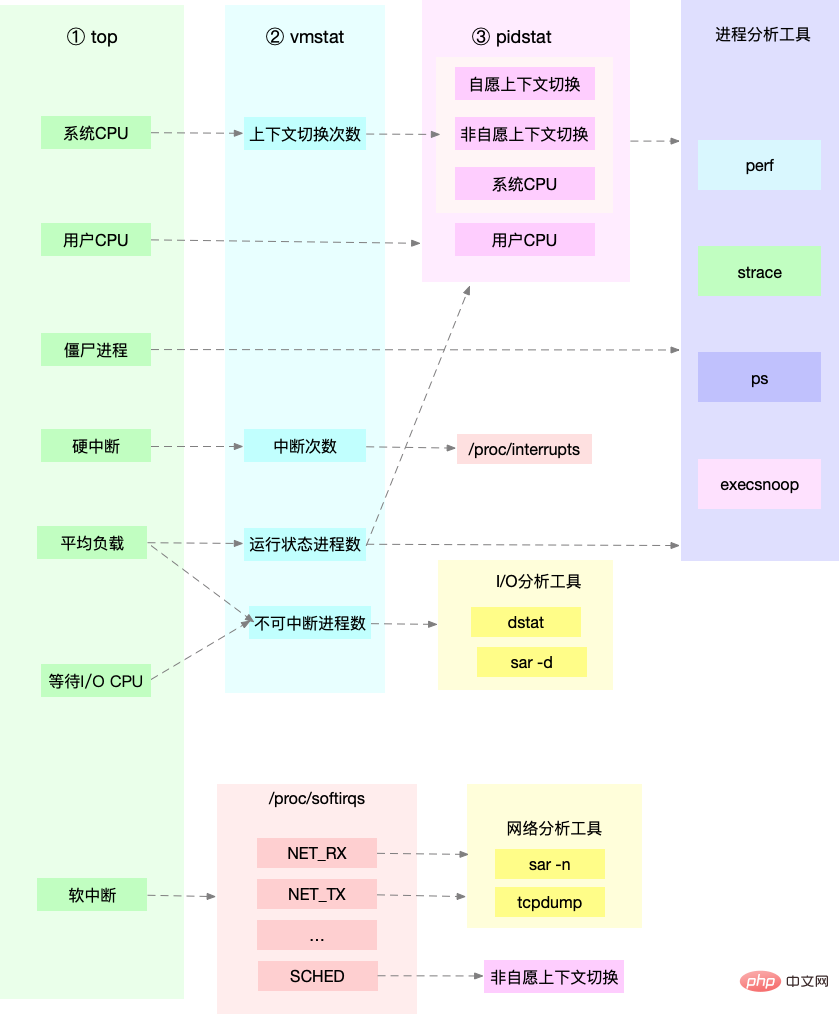
Führen Sie zunächst einige Tools aus, die weitere Indikatoren unterstützen, z. B. top/vmstat/pidstat. Anhand ihrer Ausgabe können Sie feststellen, um welche Art von Leistungsproblem es sich handelt Prozess Verwenden Sie dann strace/perf, um die Aufrufsituation zur weiteren Analyse zu analysieren. Wenn sie durch einen Soft-Interrupt verursacht wird, verwenden Sie /proc/softirqs. Bild von: www.ctq6.cn
Interrupt-Lastausgleich: irpbalance, automatischer Lastausgleich des Interrupt-Verarbeitungsprozesses auf jede CPU
Parallelitätsanzahl
Antwortzeit
QPS(TPS)=Parallelitätsanzahl/durchschnittliche Antwortzeit
Benutzeranfrage. Server
Interne Serververarbeitung
Der Server kehrt zum Client zurück
QPS ähnelt TPS, aber ein Besuch einer Seite bildet einen TPS, aber eine Seitenanforderung kann mehrere Anfragen an den Server umfassen, die als mehrere QPS gezählt werden können
QPS (Abfragen pro Sekunde) Abfragerate pro Sekunde, die Anzahl der Abfragen, auf die ein Server pro Sekunde antworten kann.
TPS (Transaktionen pro Sekunde) Anzahl der Transaktionen pro Sekunde, das Ergebnis von Softwaretests
Der von den meisten Computern verwendete Hauptspeicher ist dynamisch Nur Ally-Random-Access-Speicher (DRAM). Der Kernel kann direkt auf den physischen Speicher zugreifen. Der Linux-Kernel stellt für jeden Prozess einen unabhängigen virtuellen Adressraum bereit, und dieser Adressraum ist kontinuierlich. Auf diese Weise kann der Prozess problemlos auf den Speicher (virtuellen Speicher) zugreifen.
Das Innere des virtuellen Adressraums ist in zwei Teile unterteilt: Kernelraum und Benutzerraum. Der Adressraumbereich von Prozessoren mit unterschiedlichen Wortlängen ist unterschiedlich. Der 32-Bit-Systemkernel-Speicherplatz belegt 1 GB und der Benutzerspeicherplatz belegt 3 GB. Der Kernelraum und der Benutzerraum von 64-Bit-Systemen sind beide 128T groß und belegen den höchsten bzw. niedrigsten Teil des Speicherraums, und der mittlere Teil ist undefiniert.
Nicht dem gesamten virtuellen Speicher wird physischer Speicher zugewiesen, sondern nur dem tatsächlich genutzten. Der zugewiesene physische Speicher wird durch Speicherzuordnung verwaltet. Um die Speicherzuordnung abzuschließen, verwaltet der Kernel für jeden Prozess eine Seitentabelle, um die Zuordnungsbeziehung zwischen virtuellen Adressen und physischen Adressen aufzuzeichnen. Die Seitentabelle wird tatsächlich in der Speicherverwaltungseinheit MMU der CPU gespeichert, und der Prozessor kann direkt über die Hardware den Speicher ermitteln, auf den zugegriffen werden soll.
Wenn die virtuelle Adresse, auf die der Prozess zugreift, nicht in der Seitentabelle gefunden werden kann, generiert das System eine Seitenfehlerausnahme, betritt den Kernel-Speicherplatz, um physischen Speicher zuzuweisen, aktualisiert die Prozessseitentabelle und kehrt dann zum Fortfahren in den Benutzerbereich zurück den Ablauf des Prozesses.
MMU verwaltet den Speicher in Seiteneinheiten mit einer Seitengröße von 4 KB. Um das Problem zu vieler Seitentabelleneinträge zu lösen, bietet Linux die Mechanismen „Mehrstufige Seitentabelle“ und „HugePage“. Virtuelle Speicherplatzverteilung
Der Cache des ersteren kann das Auftreten von Ausnahmen aufgrund fehlender Seiten reduzieren und die Effizienz des Speicherzugriffs verbessern. Da der Speicher jedoch nicht an das System zurückgegeben wird, führt eine häufige Speicherzuweisung/-freigabe zu einer Speicherfragmentierung, wenn der Speicher ausgelastet ist.
Letzteres wird bei der Freigabe direkt an das System zurückgegeben, sodass jedes Mal, wenn mmap auftritt, eine Seitenfehlerausnahme auftritt. Wenn die Speicherarbeit ausgelastet ist, führt die häufige Speicherzuweisung zu einer großen Anzahl von Seitenfehlerausnahmen, was die Belastung durch die Kernelverwaltung erhöht.
Die beiden oben genannten Aufrufe weisen keinen Speicher zu. Dieser Speicher gelangt nur über eine Seitenfehlerausnahme in den Kernel und wird vom Kernel zugewiesen.
, das System fordert es auf folgende Weise zurück: Speicher:
回收缓存:LRU算法回收最近最少使用的内存页面;
回收不常访问内存:把不常用的内存通过交换分区写入磁盘
杀死进程:OOM内核保护机制 (进程消耗内存越大oom_score越大,占用CPU越多oom_score越小,可以通过/proc手动调整oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj
free来查看整个系统的内存使用情况
top/ps来查看某个进程的内存使用情况
Cache-Trefferquote bezieht sich auf die Anzahl der Anfragen, Daten direkt über den Cache abzurufen Prozentsatz aller Anfragen. Je höher die Trefferquote, desto höher sind die Vorteile des Caches und desto besser ist die Leistung der Anwendung.
Nach der Installation des bcc-Pakets können Sie Cache-Lese- und Schreibtreffer über Cachestat und Cachetop überwachen.
Nach der Installation von pcstat können Sie die Cache-Größe und das Cache-Verhältnis der Dateien im Speicher überprüfen
#首先安装Go export GOPATH=~/go export PATH=~/go/bin:$PATH go get golang.org/x/sys/unix go ge github.com/tobert/pcstat/pcstat
dd if=/dev/sda1 of=file bs=1M count=512 #生产一个512MB的临时文件 echo 3 > /proc/sys/vm/drop_caches #清理缓存 pcstat file #确定刚才生成文件不在系统缓存中,此时cached和percent都是0 cachetop 5 dd if=file of=/dev/null bs=1M #测试文件读取速度 #此时文件读取性能为30+MB/s,查看cachetop结果发现并不是所有的读都落在磁盘上,读缓存命中率只有50%。 dd if=file of=/dev/null bs=1M #重复上述读文件测试 #此时文件读取性能为4+GB/s,读缓存命中率为100% pcstat file #查看文件file的缓存情况,100%全部缓存
cachetop 5 sudo docker run --privileged --name=app -itd feisky/app:io-direct sudo docker logs app #确认案例启动成功 #实验结果表明每读32MB数据都要花0.9s,且cachetop输出中显示1024次缓存全部命中
但是凭感觉可知如果缓存命中读速度不应如此慢,读次数时1024,页大小为4K,五秒的时间内读取了1024*4KB数据,即每秒0.8MB,和结果中32MB相差较大。说明该案例没有充分利用缓存,怀疑系统调用设置了直接I/O标志绕过系统缓存。因此接下来观察系统调用.
strace -p $(pgrep app) #strace 结果可以看到openat打开磁盘分区/dev/sdb1,传入参数为O_RDONLY|O_DIRECT
这就解释了为什么读32MB数据那么慢,直接从磁盘读写肯定远远慢于缓存。找出问题后我们再看案例的源代码发现flags中指定了直接IO标志。删除该选项后重跑,验证性能变化。
对应用程序来说,动态内存的分配和回收是核心又复杂的一个逻辑功能模块。管理内存的过程中会发生各种各样的“事故”:
Heap: Von der Anwendung selbst zugewiesen und verwaltet. Diese Heap-Speicher werden vom System nicht automatisch freigegeben, es sei denn, das Programm wird beendet.
预先安装systat,docker,bcc
sudo docker run --name=app -itd feisky/app:mem-leak sudo docker logs app vmstat 3
可以看到free在不断下降,buffer和cache基本保持不变。说明系统的内存一致在升高。但并不能说明存在内存泄漏。此时可以通过memleak工具来跟踪系统或进程的内存分配/释放请求
/usr/share/bcc/tools/memleak -a -p $(pidof app)
从memleak输出可以看到,应用在不停地分配内存,并且这些分配的地址并没有被回收。通过调用栈看到是fibonacci函数分配的内存没有释放。定位到源码后查看源码来修复增加内存释放函数即可.
系统内存资源紧张时通过内存回收和OOM杀死进程来解决。其中可回收内存包括:
Für den vom Programm automatisch zugewiesenen Heap-Speicher, der unser ist Anonyme Seite in der Speicherverwaltung. Obwohl dieser Speicher nicht direkt freigegeben werden kann, stellt Linux den Swap-Mechanismus bereit. Der Speicher, auf den nicht häufig zugegriffen wird, wird auf die Festplatte geschrieben, um den Speicher freizugeben, und der Speicher kann bei erneutem Zugriff von der Festplatte gelesen werden .
Die Essenz von Swap besteht darin, einen Teil des Speicherplatzes oder eine lokale Datei als Speicher zu verwenden, einschließlich zweier Prozesse des Ein- und Auslagerns:
Wie misst Linux, ob die Speicherressourcen knapp sind?
Direkte Speicherrückgewinnung Neue große Blockspeicherzuweisung angefordert, aber nicht genügend Speicher übrig. Zu diesem Zeitpunkt fordert das System einen Teil des Speichers zurück.
kswapd0 Der Kernel-Thread fordert regelmäßig Speicher zurück. Um die Speichernutzung zu messen, werden die drei Schwellenwerte „pages_min“, „pages_low“ und „pages_high“ definiert und darauf basierend Speicherrecyclingvorgänge durchgeführt.
Verbleibender Speicher < Seiten_min, der verfügbare Speicher für den Prozess ist erschöpft, nur der Kernel kann Speicher zuweisen
Seiten_min < Führt Speicherrecycling durch, bis der verbleibende Speicher >pages_high
istpages_low < 剩余内存 < pages_high,内存有一定压力,但可以满足新内存请求
剩余内存 > pages_high,说明剩余内存较多,无内存压力
pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2
很多情况下系统剩余内存较多,但SWAP依旧升高,这是由于处理器的NUMA架构。
在NUMA架构下多个处理器划分到不同的Node,每个Node都拥有自己的本地内存空间。在分析内存的使用时应该针对每个Node单独分析
numactl --hardware #查看处理器在Node的分布情况,以及每个Node的内存使用情况
内存三个阈值可以通过/proc/zoneinfo来查看,该文件中还包括活跃和非活跃的匿名页/文件页数。
当某个Node内存不足时,系统可以从其他Node寻找空闲资源,也可以从本地内存中回收内存。通过/proc/sys/vm/zone_raclaim_mode来调整。
在实际回收过程中Linux根据/proc/sys/vm/swapiness选项来调整使用Swap的积极程度,从0-100,数值越大越积极使用Swap,即更倾向于回收匿名页;数值越小越消极使用Swap,即更倾向于回收文件页。
注意:这只是调整Swap积极程度的权重,即使设置为0,当剩余内存+文件页小于页高阈值时,还是会发生Swap。
free #首先通过free查看swap使用情况,若swap=0表示未配置Swap #先创建并开启swap fallocate -l 8G /mnt/swapfile chmod 600 /mnt/swapfile mkswap /mnt/swapfile swapon /mnt/swapfile free #再次执行free确保Swap配置成功 dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模拟大文件读取 sar -r -S 1 #查看内存各个指标变化 -r内存 -S swap #根据结果可以看出,%memused在不断增长,剩余内存kbmemfress不断减少,缓冲区kbbuffers不断增大,由此可知剩余内存不断分配给了缓冲区 #一段时间之后,剩余内存很小,而缓冲区占用了大部分内存。此时Swap使用之间增大,缓冲区和剩余内存只在小范围波动 停下sar命令 cachetop5 #观察缓存 #可以看到dd进程读写只有50%的命中率,未命中数为4w+页,说明正式dd进程导致缓冲区使用升高 watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #观察内存指标变化 #发现升级内存在一个小范围不停的波动,低于页低阈值时会突然增大到一个大于页高阈值的值
说明剩余内存和缓冲区的波动变化正是由于内存回收和缓存再次分配的循环往复。有时候Swap用的多,有时候缓冲区波动更多。此时查看swappiness值为60,是一个相对中和的配置,系统会根据实际运行情况来选去合适的回收类型.
So finden Sie schnell und genau Probleme mit dem SystemspeicherPuffer: temporäre Speicherung der ursprünglichen Festplattenblöcke, Zwischenspeicherung der auf die Festplatte zu schreibenden Daten
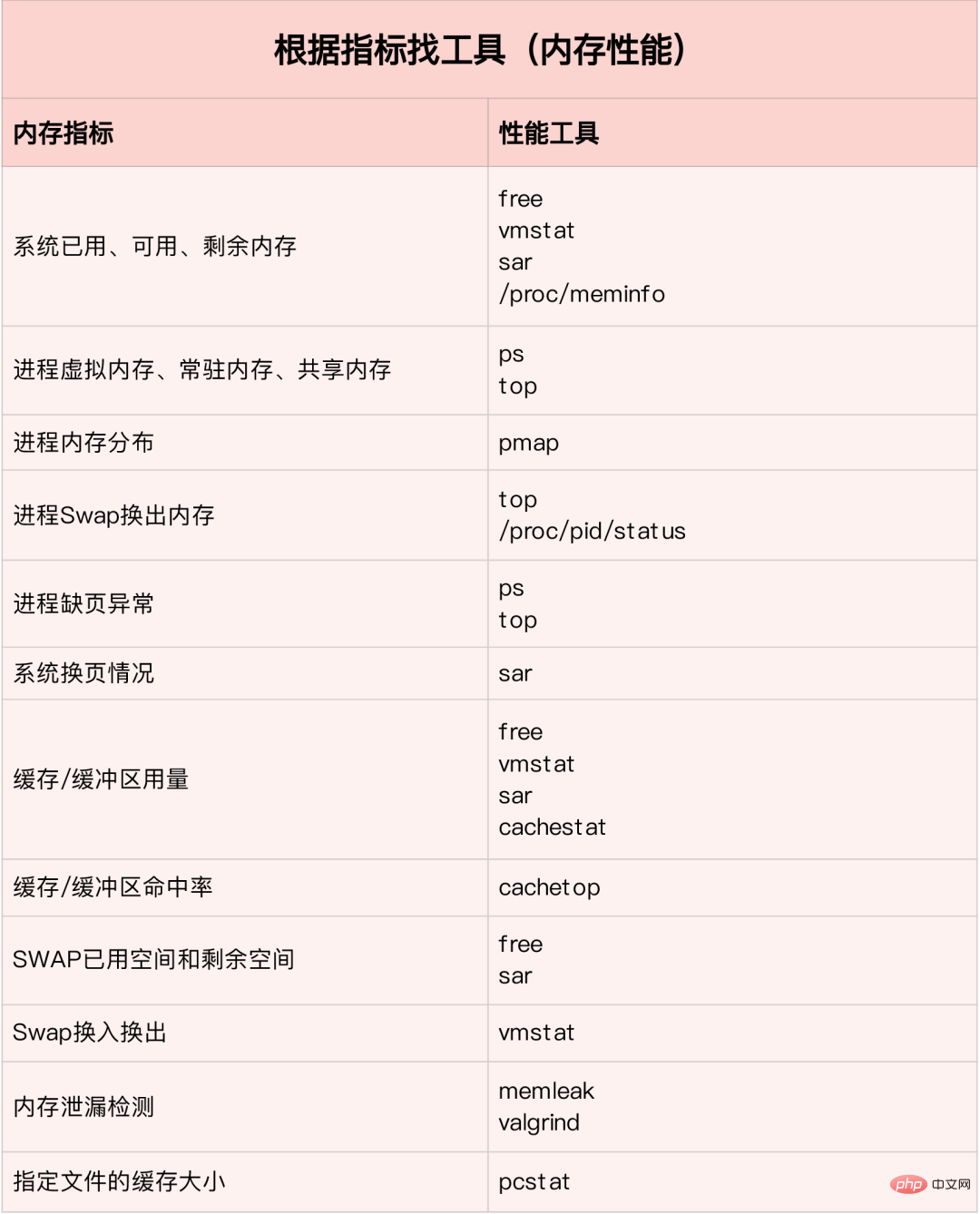
Im Speicheranalysetool enthaltene Leistungsindikatoren:
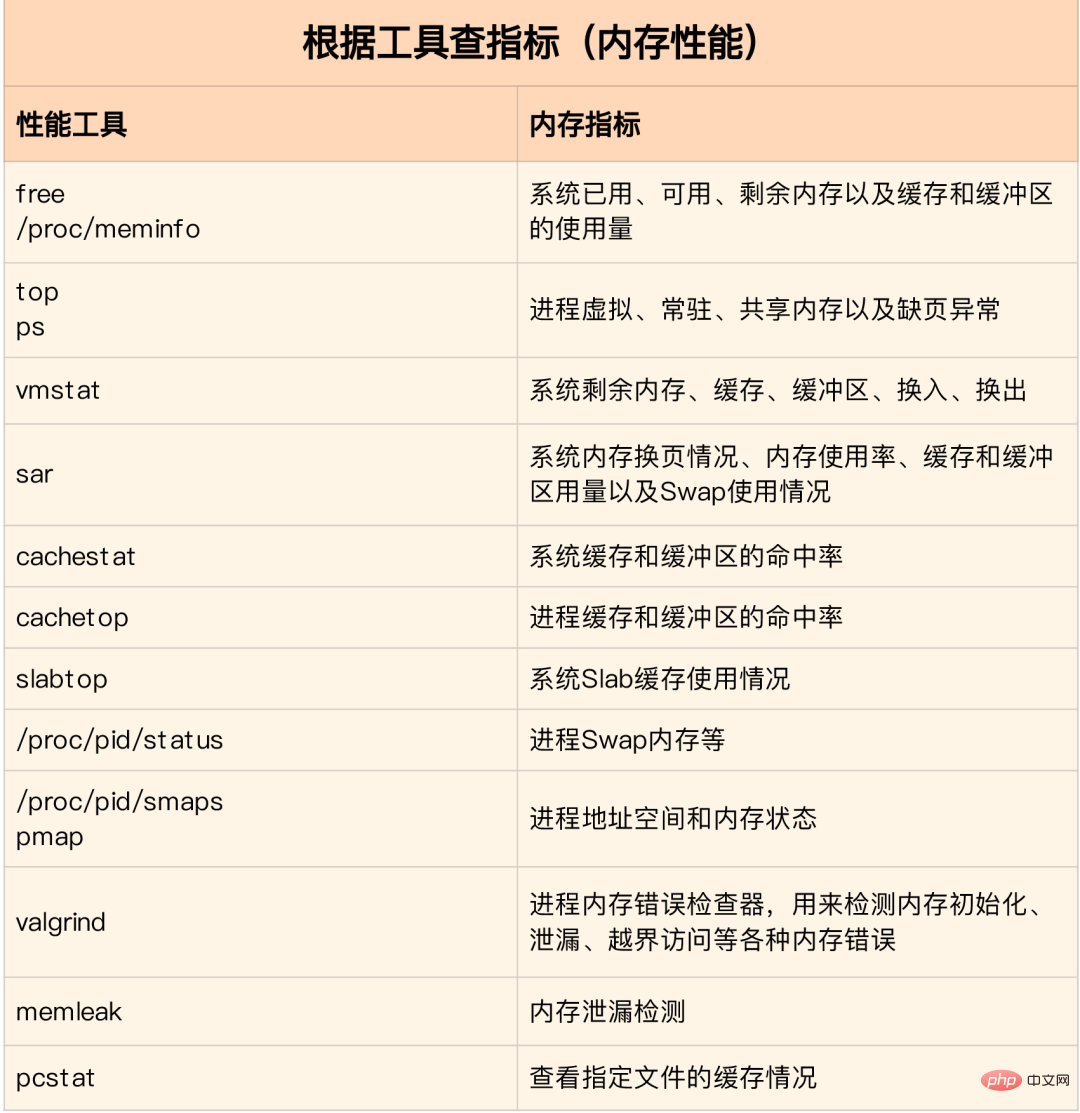
Normalerweise Führen Sie zunächst mehrere Leistungstools mit relativ großer Abdeckung aus, z. B. free, top, vmstat, pidstat usw.
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
vmstat 2 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0 0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0 0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0 0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0 0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0 0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0 1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0 1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0 1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0 1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0 0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0 0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0 1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0 0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0 0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0 1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0 # 结果说明 - r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。 - b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。 - swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。 - free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。 - buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M - cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。) - si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。 - so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。 - bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒 - bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。 - in 每秒CPU的中断次数,包括时间中断 - cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。 - us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。 - sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。 - id 空闲CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。 - wt 等待IO CPU时间
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。
Wie benutzt man:
1
pidstat -d 1 10 03:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command 03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-8 03:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun 03:02:03 PM 997 7326 0.00 1904.95 918.81 java 03:02:03 PM 997 8539 0.00 3.96 0.00 java 03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent 03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command 03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-8 03:02:04 PM 997 7326 0.00 11156.00 1888.00 java 03:02:04 PM 997 8539 0.00 4.00 0.00 java
2、统计CPU使用情况
# 统计CPU pidstat -u 1 10 03:03:33 PM UID PID %usr %system %guest %CPU CPU Command 03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible 03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat 03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java 03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java 03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java 03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansible
3、统计内存使用情况
# 统计内存 pidstat -r 1 10 Average: UID PID minflt/s majflt/s VSZ RSS %MEM Command Average: 0 1 0.20 0.00 191256 3064 0.01 systemd Average: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDun Average: 0 6642 0.10 0.00 6301904 107680 0.33 java Average: 997 7326 10.89 0.00 13468904 8395848 26.04 java Average: 0 7795 348.15 0.00 108376 1233 0.00 pidstat Average: 997 8539 0.50 0.00 8242256 2062228 6.40 java Average: 987 9518 0.20 0.00 6300944 1242924 3.85 java Average: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-service Average: 984 15517 0.40 0.00 6386464 1464572 4.54 java Average: 0 16066 236.46 0.00 2678332 71020 0.22 cmagent Average: 995 20955 0.30 0.00 6312520 1408040 4.37 java Average: 995 20956 0.20 0.00 6093764 1505028 4.67 java Average: 0 23936 0.10 0.00 5302416 110804 0.34 java Average: 0 24406 0.70 0.00 10211672 2361304 7.32 java Average: 0 26870 1.40 0.00 1470212 36084 0.11 promtail
4、查看具体进程使用情况
pidstat -T ALL -r -p 20955 1 10 03:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command 03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java 03:12:16 PM UID PID minflt-nr majflt-nr Command 03:12:17 PM 995 20955 0 0 java
Das obige ist der detaillierte Inhalt vonZusammenfassung der Wissenspunkte zur Linux-Leistungsoptimierung · Practice + Collection Edition. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



