

 Backend-Entwicklung
Python-Tutorial
Dinge, die es zu beachten gilt: Liste der Python-Grundlagen
Backend-Entwicklung
Python-Tutorial
Dinge, die es zu beachten gilt: Liste der Python-Grundlagen
Dinge, die es zu beachten gilt: Liste der Python-Grundlagen
1. Listenformat
Beispiel:
namesList = ['xiaoWang','xiaoZhg','xiaa']
Was leistungsfähiger als C-Spracharrays ist, ist, dass die Elemente in der Liste unterschiedlichen Typs sein können. ?? Sie können Elemente durch Anhängen zur Liste hinzufügen. <br/>
testList = [1, 'a']
Operationsergebnis: <br/>
<2> Beim Ändern des Elements ("Ändern")
durch Subskription Entscheiden Sie, welches Element Sie möchten ändern, bevor Sie es ändern können.
Beispiel:<br/>
# 定义变量A,默认有3个元素
A = ['rr', 'rag', 'rte']
print("-----添加之前,列表A的数据-----")
for tempName in A:
print(tempName)
# 提示、并添加元素
temp = input('请输入要添加的学生姓名:')
A.append(temp)
print("-----添加之后,列表A的数据-----")
for tempName in A:
print(tempName) Ergebnis:
Ergebnis:
<3> 查找元素("查"in, not in, index, count)<br/> python中查找的常用方法为: in(存在),如果存在那么结果为true,否则为false。 not in(不存在),如果不存在那么结果为true,否则false。 运行结果:(找到)<br/> 运行结果:(没有找到) 注:<br/> in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在。 <4> 删除元素("删"del, pop, remove) del (根据下标进行删除) 结果:<br/> pop(删除最后一个元素) 运行结果: remove (根据元素的值进行删除) 结果:<br/> <5> 排序(sort, reverse) sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。 reverse方法是将list逆置。 运行结果:<br/> <br/> 类似while循环的嵌套,列表也是支持嵌套的。 一个列表中的元素又是一个列表,那么这就是列表的嵌套。 例: 列表中包含字典。比如花名册: 运行结果:<br/> 有的应用场景,会在列表中包含大量的字典, 而且其中的每个字典都会包含拥有众多属性的大对象。<br/> 字典包含列表。比如图书的标签,一本书会被标注多个标签: 运行结果: 本文详细的讲解了Python基础 。介绍了常见的列表操作,以及在实际操作中会遇到的问题,提供了解决方案。最后通过一个小项目,使读者能够更好的理解Python列表的使用方法。希望可以帮助你更好的学习。 Das obige ist der detaillierte Inhalt vonDinge, die es zu beachten gilt: Liste der Python-Grundlagen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
<br/>
#待查找的列表 A = ['rr', 'rag', 'rte']
#获取用户要查找的名字 findName = input('请输入要查找的内容:')
#查找是否存在 if findName in A: print('在字典中找到了相同的内容') else: print('没有找到')
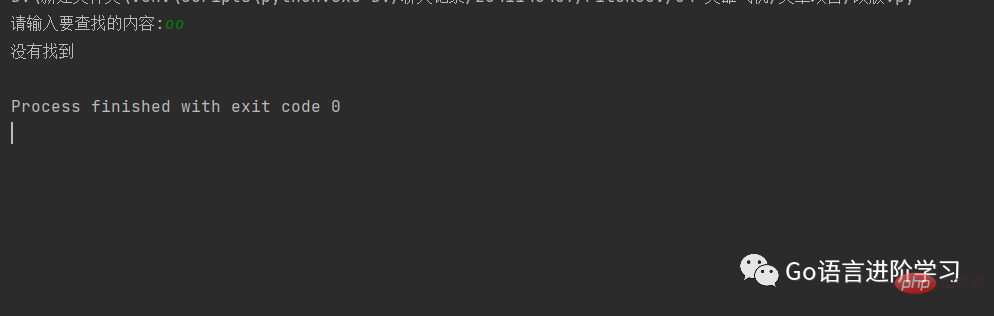
<br/>
Name = ['加勒比海盗','骇客帝国','第一滴血','霍比特人','速度与激情']
print('------删除之前------')for tempName in Name: print(tempName)
del Name[2]
print('------删除之后------')for tempName in Name: print(tempName)

Subject= ['数学', '语文', '英语', '地理', '历史']
print('------删除之前------')for tempSubject in Subject: print(tempSubject)
del Subject[2] #删除第二个元素
print('------删除之后------')for tempSubject in Subject: print(tempSubject)

<br/>
Subject= ['数学', '语文', '英语', '地理', '历史']
print('------删除之前------')for tempSubject in Subject: print(tempSubject)
# del Subject[2] #删除第二个元素Subject.remove('英语')
print('------删除之后------')for tempSubject in Subject: print(tempSubject)

a = [1, 4, 2, 3]print(a)
a.reverse()print(a) # 运行结果a.sort()print(a) # 运行结果a.sort(reverse=True)print(a) # 运行结果
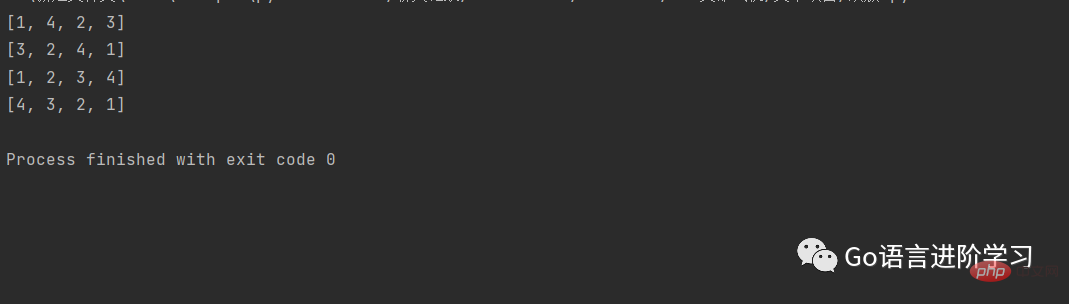
三、列表的嵌套<br/>
1. 列表嵌套
Letter= [['A', 'B'], ['C', 'D', 'E'], ['F', 'R']]
2. 字典列表<br/>
pep1 = {'name': '蔡同学', 'school': '北京大学'}pep2 = {'name': '陈作同', 'school': '中山大学'}pep_list = [pep1, pep2]for pepo in pep_list: print(pepo)
3. 列表字典
book = {'title': '现代艺术150年', 'tags': ['数学', '历史学']}for tags in book['tags']: print(tags)
四、总结

Heiße KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Python verbinden sich mit SQL Server PyoDBC -Beispiel
Jul 30, 2025 am 02:53 AM
Python verbinden sich mit SQL Server PyoDBC -Beispiel
Jul 30, 2025 am 02:53 AM
Installieren Sie PYODBC: Verwenden Sie den Befehl pipinstallpyoDBC, um die Bibliothek zu installieren. 2. SQLServer verbinden: Verwenden Sie die Verbindungszeichenfolge, die Treiber, Server, Datenbank, UID/PWD oder Trusted_Connection über die Methode Pyodbc.Connect () und die SQL -Authentifizierung bzw. der Windows -Authentifizierung unterstützen; 3. Überprüfen Sie den installierten Treiber: Führen Sie Pyodbc.Drivers () aus und filtern Sie den Treibernamen mit 'SQLServer', um sicherzustellen, dass der richtige Treiberame wie 'ODBCDRIVER17 für SQLServer' verwendet wird. 4. Schlüsselparameter der Verbindungszeichenfolge
 Optimierung von Python für Speichervorgänge
Jul 28, 2025 am 03:22 AM
Optimierung von Python für Speichervorgänge
Jul 28, 2025 am 03:22 AM
PythoncanbeoptimizedFormemory-BoundoperationsByreducingoverheadThroughGeneratoren, effiziente Datastrukturen und ManagingObjectLifetimes.First, UseGeneratorsinSteadofListStoprocesslargedatasetasetasematatime, Vermeidung von loloadingeNthertomemory.Secondatasetasetematatime, Choos
 Python Shutil Rmtree Beispiel
Aug 01, 2025 am 05:47 AM
Python Shutil Rmtree Beispiel
Aug 01, 2025 am 05:47 AM
Shutil.rmtree () ist eine Funktion in Python, die den gesamten Verzeichnisbaum rekursiv löscht. Es kann bestimmte Ordner und alle Inhalte löschen. 1. Basisnutzung: Verwenden Sie Shutil.rmtree (Pfad), um das Verzeichnis zu löschen, und Sie müssen FilenotFoundError, Erlaubnissekror und andere Ausnahmen verarbeiten. 2. Praktische Anwendung: Sie können Ordner, die Unterverzeichnisse und Dateien enthalten, in einem Klick löschen, z. B. temporäre Daten oder zwischengespeicherte Verzeichnisse. 3. ANMERKUNGEN: Der Löschvorgang wird nicht wiederhergestellt; FilenotFoundError wird geworfen, wenn der Weg nicht existiert. Es kann aufgrund von Berechtigungen oder Einstellungen fehlschlagen. 4. Optionale Parameter: Fehler können von ignore_errors = true ignoriert werden
 Python Psycopg2 Connection Pool Beispiel
Jul 28, 2025 am 03:01 AM
Python Psycopg2 Connection Pool Beispiel
Jul 28, 2025 am 03:01 AM
Verwenden Sie PSYCOPG2.POOL.SimpleconnectionPool, um Datenbankverbindungen effektiv zu verwalten und den Leistungsaufwand zu vermeiden, der durch die häufige Erstellung und Zerstörung von Verbindungen verursacht wird. 1. Geben Sie beim Erstellen eines Verbindungspools die minimale und maximale Anzahl von Verbindungen und Datenbankverbindungsparametern an, um sicherzustellen, dass der Verbindungspool erfolgreich initialisiert wird. 2. Nehmen Sie die Verbindung über getConn () ab und verwenden Sie PutConn (), um die Verbindung nach Ausführung des Datenbankvorgangs zum Pool zurückzugeben. Conn.Close () ständig aufrufen ist verboten; 3. SimpleConnectionPool ist mit Thread-sicher und für Umgebungen mit mehreren Threaden geeignet. 4.. Es wird empfohlen, einen Kontextmanager in Kombination mit Context Manager zu implementieren, um sicherzustellen, dass die Verbindung korrekt zurückgegeben werden kann, wenn Ausnahmen festgestellt werden.
 Python Iter und nächstes Beispiel
Jul 29, 2025 am 02:20 AM
Python Iter und nächstes Beispiel
Jul 29, 2025 am 02:20 AM
Iter () wird verwendet, um das Iteratorobjekt zu erhalten, und als nächstes () wird das nächste Element erhalten. 1. Verwenden Sie Iterator (), um iterable Objekte wie Listen in Iteratoren umzuwandeln. 2. Rufen Sie als nächstes an () an, um Elemente nacheinander zu erhalten, und auslösen Sie die Ausnahme der Stopperation, wenn die Elemente erschöpft sind. 3. Verwenden Sie als nächstes (Iterator, Standard), um Ausnahmen zu vermeiden. 4. Benutzerdefinierte Iteratoren müssen die Methoden __iter __ () und __Next __ () implementieren, um die Iterationslogik zu kontrollieren; Die Verwendung von Standardwerten ist ein häufiger Weg zum sicheren Traversal, und der gesamte Mechanismus ist prägnant und praktisch.
 Was ist statistische Arbitrage in Kryptowährungen? Wie funktioniert statistische Arbitrage?
Jul 30, 2025 pm 09:12 PM
Was ist statistische Arbitrage in Kryptowährungen? Wie funktioniert statistische Arbitrage?
Jul 30, 2025 pm 09:12 PM
Die Einführung in statistische Arbitrage Statistical Arbitrage ist eine Handelsmethode, die auf der Grundlage mathematischer Modelle Preisfehlanpassungen auf dem Finanzmarkt erfasst. Die Kernphilosophie beruht auf der mittleren Regression, dh, dass die Vermögenspreise kurzfristig von langfristigen Trends abweichen, aber schließlich zu ihrem historischen Durchschnitt zurückkehren. Händler verwenden statistische Methoden, um die Korrelation zwischen Vermögenswerten zu analysieren und nach Portfolios zu suchen, die normalerweise synchron verändern. Wenn das Preisverhältnis dieser Vermögenswerte ungewöhnlich abgewichen ist, ergeben sich Arbitrage -Möglichkeiten. Auf dem Kryptowährungsmarkt ist die statistische Arbitrage besonders weit verbreitet, hauptsächlich aufgrund der Ineffizienz und drastischen Marktschwankungen des Marktes selbst. Im Gegensatz zu den traditionellen Finanzmärkten arbeiten Kryptowährungen rund um die Uhr und ihre Preise sind äußerst anfällig für Verstöße gegen Nachrichten, Social -Media -Stimmung und technologische Upgrades. Diese konstante Preisschwankung schafft häufig Preisgestaltung und liefert Arbitrageure mit
 Wie führe ich SQL -Abfragen in Python aus?
Aug 02, 2025 am 01:56 AM
Wie führe ich SQL -Abfragen in Python aus?
Aug 02, 2025 am 01:56 AM
Installieren Sie den entsprechenden Datenbanktreiber; 2. verwenden Sie Connect (), um eine Verbindung zur Datenbank herzustellen. 3. Erstellen Sie ein Cursorobjekt; V. 5. Verwenden Sie Fetchall () usw., um Ergebnisse zu erhalten. 6. Commit () ist nach der Änderung erforderlich; 7. Schließlich schließen Sie die Verbindung oder verwenden Sie einen Kontextmanager, um sie automatisch zu behandeln. Der vollständige Prozess stellt sicher, dass die SQL -Operationen sicher und effizient sind.
 So erstellen Sie eine virtuelle Umgebung in Python
Aug 05, 2025 pm 01:05 PM
So erstellen Sie eine virtuelle Umgebung in Python
Aug 05, 2025 pm 01:05 PM
Um eine virtuelle Python -Umgebung zu erstellen, können Sie das Venv -Modul verwenden. Die Schritte sind: 1. Geben Sie das Projektverzeichnis ein, um die Python-Mvenvenv-Umgebung auszuführen, um die Umgebung zu schaffen. 2. verwenden Sie SourceEnv/bin/aktivieren Sie in Mac/Linux und Env \ Skripts \ aktivieren in Windows; 3.. Verwenden Sie das Pipinstall -Installationspaket, Pipfreeze> Anforderungen.txt, um Abhängigkeiten zu exportieren. V. Virtuelle Umgebungen können Projektabhängigkeiten isolieren, um Konflikte zu verhindern, insbesondere für die Entwicklung von Mehrfachprojekten, und Redakteure wie Pycharm oder VSCODE sind es ebenfalls
