

Wenn es um Bilibili geht, glaube ich, dass viele Freunde wie ich die Webcrawler-Technologie verwenden möchten, um das Video von Bilibili zu erhalten ist eigentlich gar nicht so einfach zu bekommen, ab an Station B um das Video zu bekommen, wurde schon einmal durch die you-get-Bibliothek vorgestellt, interessierte Freunde können das lesen Artikel:You-Get ist so stark! .经 经
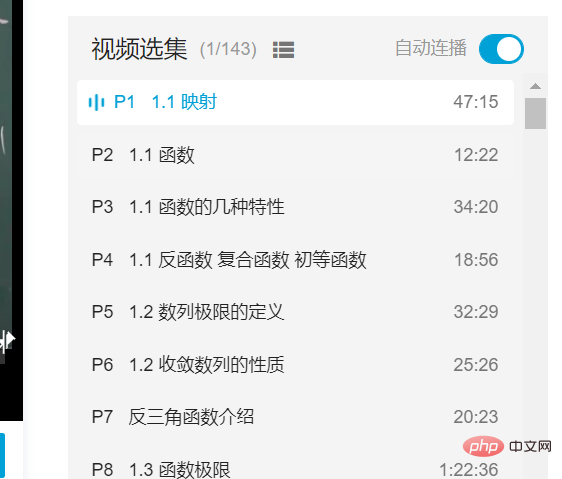
Natürlichdiese Auswahlfeldersind auch mit bloßem Auge zu erkennen. Nur Wenn Sie es über ein Programm implementieren, ist es möglicherweise nicht so einfach, wie Sie denken. Das Ziel dieses Artikels besteht also darin, eine Videoauswahl mithilfe der Python-Webcrawler-Technologie und basierend auf der Selenium-Bibliothek zu erhalten.
Die Bibliothek, die wir in diesem Artikel verwenden, ist Selenium, eine Bibliothek, die zur Simulation der Benutzeranmeldung verwendet wird, obwohl sie sich im Bereich der Webcrawler langsam anfühlt Wird immer noch häufig verwendet und hat sich bewährt, um die Anmeldung zu simulieren und Daten abzurufen. Nachfolgend finden Sie den gesamten Code zur Implementierung der Videoauswahlsammlung. Sie können ihn gerne selbst üben.
# coding: utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
class Item:
page_num = ""
part = ""
duration = ""
def __init__(self, page_num, part, duration):
self.page_num = page_num
self.part = part
self.duration = duration
def get_second(self):
str_list = self.duration.split(":")
sum = 0
for i, item in enumerate(str_list):
sum += pow(60, len(str_list) - i - 1) * int(item)
return sum
def get_bilili_page_items(url):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2,
# "profile.managed_default_content_settings.flash": 0})
browser = webdriver.Chrome(options=options)
# browser = webdriver.PhantomJS()
print("正在打开网页...")
browser.get(url)
print("等待网页响应...")
# 需要等一下,直到页面加载完成
wait = WebDriverWait(browser, 10)
wait.until(EC.visibility_of_element_located((By.XPATH, '//*[@class="list-box"]/li/a')))
print("正在获取网页数据...")
list = browser.find_elements_by_xpath('//*[@class="list-box"]/li')
# print(list)
itemList = []
second_sum = 0
# 2.循环遍历出每一条搜索结果的标题
for t in list:
# print("t text:",t.text)
element = t.find_element_by_tag_name('a')
# print("a text:",element.text)
arr = element.text.split('\n')
print(" ".join(arr))
item = Item(arr[0], arr[1], arr[2])
second_sum += item.get_second()
itemList.append(item)
print("总数量:", len(itemList))
# browser.page_source
print("总时长/分钟:", round(second_sum / 60, 2))
print("总时长/小时:", round(second_sum / 3600.0, 2))
browser.close()
return itemList
get_bilili_page_items("https://www.bilibili.com/video/BV1Eb411u7Fw")Der hier verwendete Selektor ist xpath, und das Videobeispiel ist die Tongji-Version „Advanced Mathematics“ des vollständigen Lehrvideos (Teacher Song Hao) von Station B. Wenn Sie es sich schnappen möchten Andere Videos Zur Auswahl müssen Sie lediglich den URL-Link in der letzten Zeile des obigen Codes ändern.
在运行过程中小伙伴们应该会经常遇到这个问题,如下图所示。
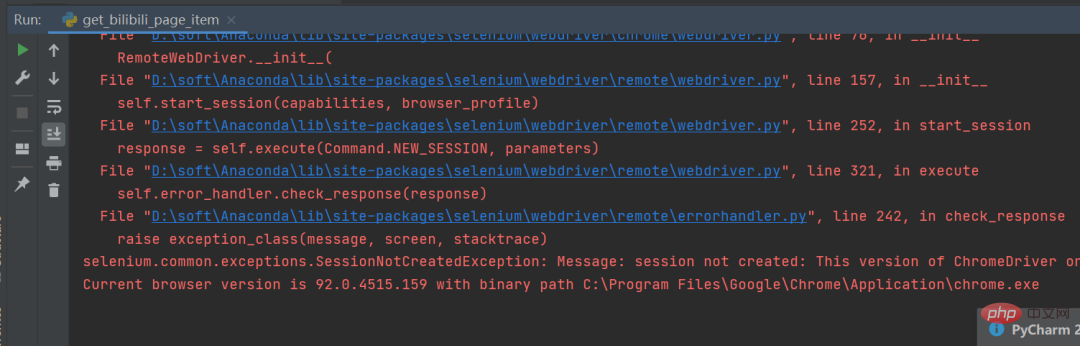
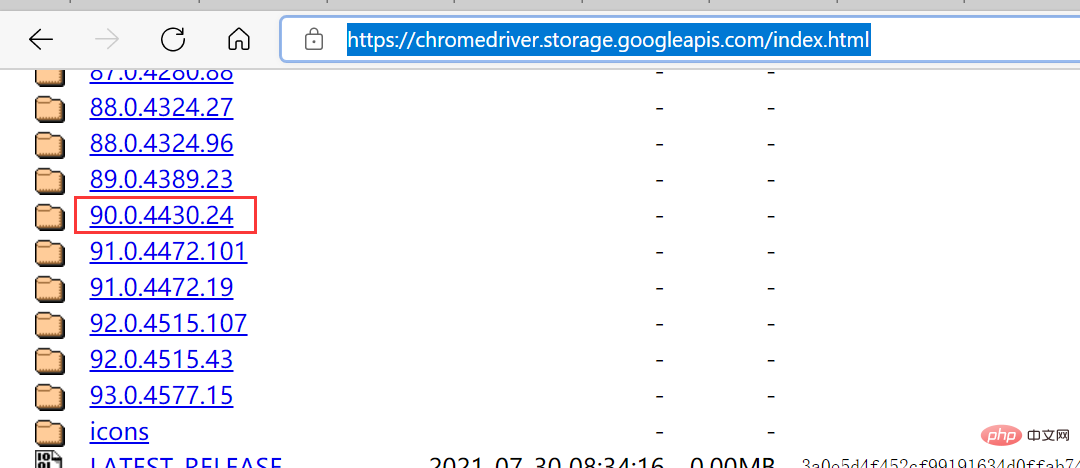
这个是因为谷歌驱动版本问题导致的,只需要根据提示,去下载对应的驱动版本即可,驱动下载链接:
https://chromedriver.storage.googleapis.com/index.html
Das obige ist der detaillierte Inhalt vonBringen Sie Ihnen Schritt für Schritt bei, wie Sie den Python-Webcrawler verwenden, um den Videoauswahlinhalt von Bilibili abzurufen (Quellcode beigefügt).. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



