

urllib bietet eine Reihe von Funktionen zum Bearbeiten von URLs. Klassifizieren Sie verwandte Inhalte.
urllib’srequestrequest模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:
例如,对豆瓣的URLhttps://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078 Modul kann problemlos URL-Inhalte erfassen, das heißt, eine GET-Anfrage an die angegebene Seite senden und dann eine HTTP-Antwort zurückgeben: Zum Beispiel die URL von Douban
https://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078🎜🎜crawlen und die Antwort zurückgeben: 🎜🎜🎜🎜
from urllib import request
with request.urlopen('https://api.growingio.com/v2/22c937bbd8ebd703f2d8e9445f7dfd03/web/pv?stm=1593747087078') as f:
data = f.read()
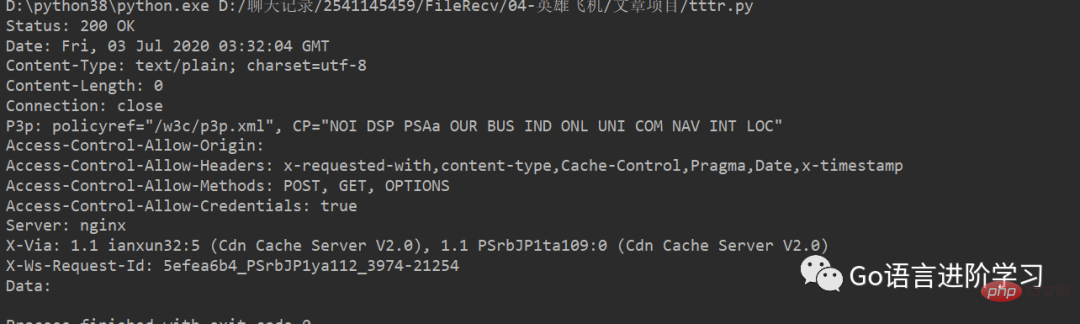
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', data.decode('utf-8'))Sie können die Header und JSON-Daten der HTTP-Antwort sehen:
Wenn Sie den Browser simulieren möchten, der eine GET-Anfrage sendet, müssen Sie < verwenden code style="box -sizing: border-box;font-family: var(--monospace);vertical-align: initial;border-width: 1px;border-style: solid;border-color: rgb(231, 234 , 237);background -color: rgb(243, 244, 244);border-radius: 3px;padding-right: 2px;padding-left: 2px;font-size: 0.9em;">RequestRequest对象,通过往Request对象添加HTTP头,就可以把请求伪装成浏览器。例如,模拟iPhone 6去请求豆瓣首页:
from urllib import request
req = request.Request('http://www.douban.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
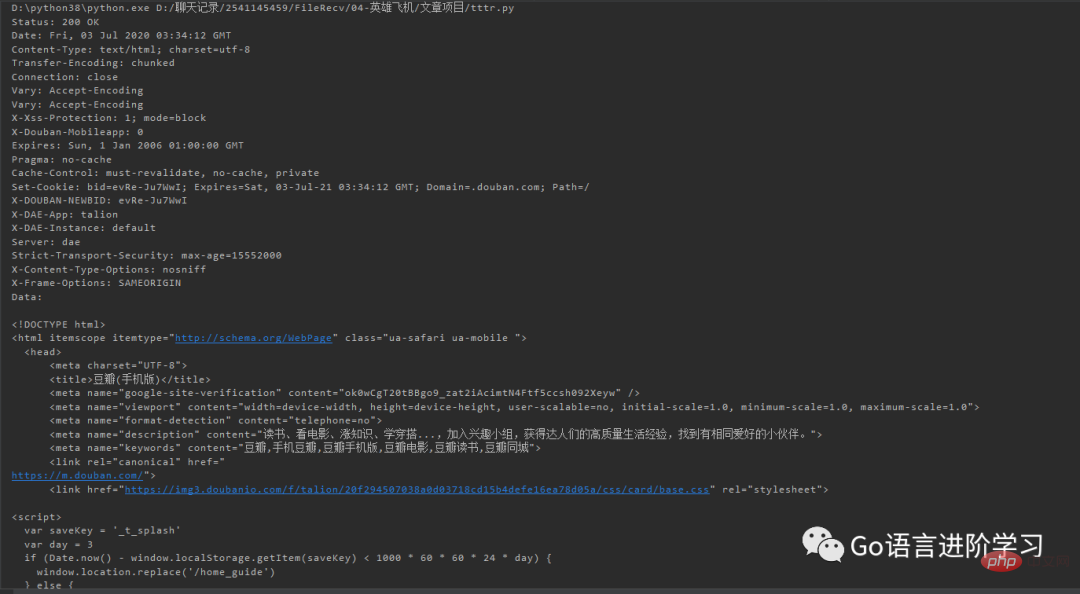
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))这样豆瓣会返回适合iPhone的移动版网页:
如果要以POST发送一个请求,只需要把参数data Objekt, indem Sie zu gehenAnfrage</ Durch Hinzufügen eines HTTP-Headers zum Code><br/></p>-Objekt können Sie die Anfrage als Browser tarnen. Simulieren Sie beispielsweise das iPhone 6, um die Douban-Homepage anzufordern: 🎜🎜🎜🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:python;toolbar:false;">from urllib import request, parse
print(&#39;Login to weibo.cn...&#39;)
#电子邮件
email = input(&#39;Email: &#39;)
#密码
passwd = input(&#39;Password: &#39;)
#相关的参数
login_data = parse.urlencode([
(&#39;username&#39;, email),
(&#39;password&#39;, passwd),
(&#39;entry&#39;, &#39;mweibo&#39;),
(&#39;client_id&#39;, &#39;&#39;),
(&#39;savestate&#39;, &#39;1&#39;),
(&#39;ec&#39;, &#39;&#39;),
(&#39;pagerefer&#39;, &#39;https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F&#39;)
])
#网址请求
req = request.Request(&#39;https://passport.weibo.cn/sso/login&#39;)
req.add_header(&#39;Origin&#39;, &#39;https://passport.weibo.cn&#39;)
#构造User-Agent
req.add_header(&#39;User-Agent&#39;, &#39;Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25&#39;)
req.add_header(&#39;Referer&#39;, &#39;https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F&#39;)
with request.urlopen(req, data=login_data.encode(&#39;utf-8&#39;)) as f:
print(&#39;Status:&#39;, f.status, f.reason)
for k, v in f.getheaders():
print(&#39;%s: %s&#39; % (k, v))
print(&#39;Data:&#39;, f.read().decode(&#39;utf-8&#39;))</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>🎜<p cid="n13" mdtype="paragraph" style="box-sizing: border-box;line-height: inherit;orphans: 4 ;margin -top: 0,8em;margin-bottom: 0,8em;white-space: pre-wrap;font-family: „Open Sans“, „Clear Sans“, „Helvetica Neue“, Helvetica, Arial, „Segoe UI Emoji ", sans-serif;font-size: 16px;text-align: start;">🎜Auf diese Weise gibt Douban die mobile Version der Webseite zurück, die für das iPhone geeignet ist: 🎜🎜🎜🎜<img src="https: //img.php.cn/upload /article/001/272/559/3cc6e1ba7918c056ef7c4a4c129bd136-2.png"/ alt="Ein Artikel führt Sie durch die urllib-Bibliothek in Python (Bedienung von URLs)." >🎜🎜🎜🎜<h2 cid="n15" mdtype="heading" style="max-width:90%">🎜Three, Post()🎜</h2>🎜<img src="https://img.php.cn/upload/article /001/272/559/3cc6e1ba7918c056ef7c4a4c129bd136- 3.png"/ alt="Ein Artikel führt Sie durch die urllib-Bibliothek in Python (Bedienung von URLs)." >🎜<p cid="n16" mdtype="paragraph" style="max-width:90%">🎜Wenn Sie eine Anfrage mit POST senden möchten, müssen Sie nur die Parameter 🎜🎜<code style="box-sizing: border-box ;Schriftfamilie: var(--monospace);vertikal-ausrichten: initial;Rahmenbreite: 1px;Rahmenstil: einfarbig;Rahmenfarbe: rgb(231, 234, 237);Hintergrundfarbe: rgb(243 , 244, 244);border-radius: 3px;padding- right: 2px;padding-left: 2px;font-size: 0.9em;">data🎜🎜 wird in Bytes übergeben. 🎜🎜🎜
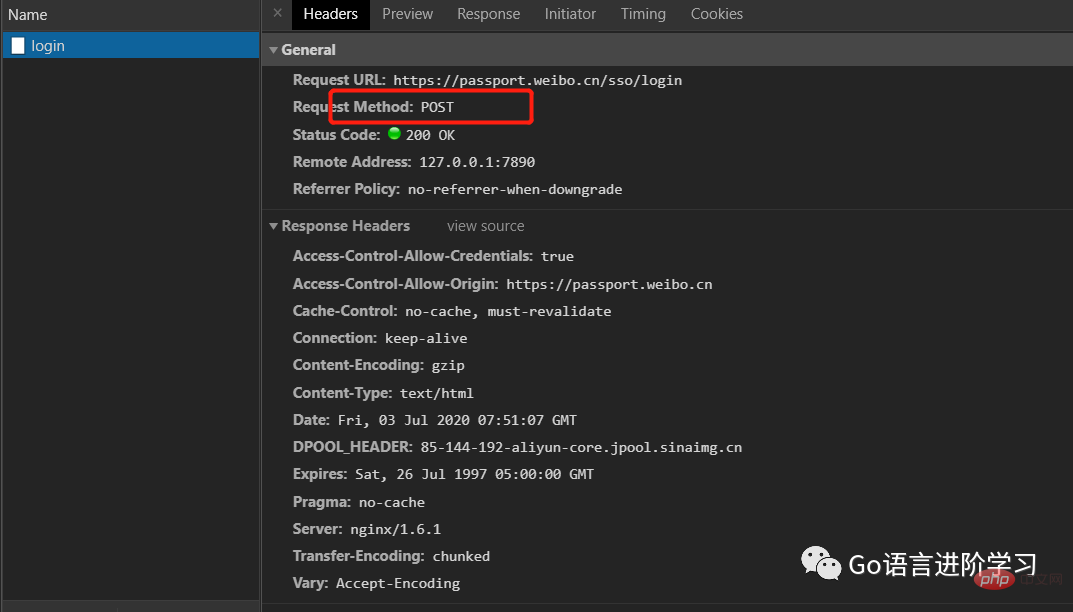
模拟一个微博登录,先读取登录的邮箱和口令,然后按照weibo.cn的登录页的格式以username=xxx&password=xxx的编码传入:
from urllib import request, parse
print('Login to weibo.cn...')
#电子邮件
email = input('Email: ')
#密码
passwd = input('Password: ')
#相关的参数
login_data = parse.urlencode([
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
#网址请求
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
#构造User-Agent
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
for k, v in f.getheaders():
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8'))如果登录成功,获得的响应如下:
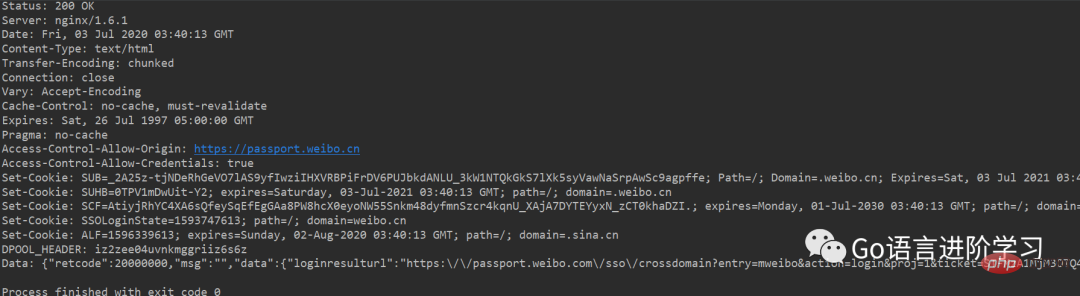
如果登录失败,获得的响应如下:
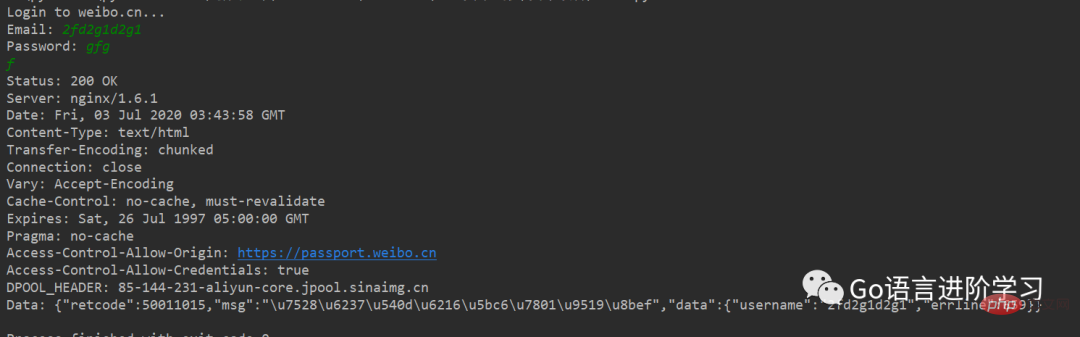
如果还需要更复杂的控制,比如通过一个Proxy去访问网站,需要利用ProxyHandler来处理,示例代码如下:
import urllib.request
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"https": "27.191.234.69:9999"})
nullproxy_handler = urllib.request.ProxyHandler({})
# 定义一个代理开关
proxySwitch = True
# 通过 urllib.request.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request("http://www.baidu.com/")
# 1. 如果这么写,只有使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。
response = opener.open(request)
# 2. 如果这么写,就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urllib.request.urlopen(request)
# 获取服务器响应内容
html = response.read().decode("utf-8")
# 打印结果
print(html)如果代理成功返回网址的信息。
Wenn die URL falsch ist oder die Proxy-Adresse falsch ist, kehren Sie zur Benutzeroberfläche unten zurück.

Die Verwendung der Python-Sprache kann jedem helfen, Python besser zu lernen. Die von urllib bereitgestellte Funktion besteht darin, mithilfe von Programmen verschiedene HTTP-Anfragen auszuführen. Wenn Sie einen Browser simulieren möchten, um eine bestimmte Funktion auszuführen, müssen Sie die Anforderung als Browser tarnen. Die Tarnungsmethode besteht darin, zunächst die vom Browser gesendeten Anforderungen zu überwachen und sie dann basierend auf dem Anforderungsheader des Browsers zu tarnen. Der User-Agent-Header wird zur Identifizierung des Browsers verwendet.
Das obige ist der detaillierte Inhalt vonEin Artikel führt Sie durch die urllib-Bibliothek in Python (Bedienung von URLs).. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



































