


Im Februar dieses Jahres veröffentlichte Meta die groß angelegte Sprachmodellreihe LLaMA, die die Entwicklung von Open-Source-Chat-Robotern erfolgreich voranbrachte. Da LLaMA weniger Parameter hat als viele zuvor veröffentlichte große Modelle (die Anzahl der Parameter reicht von 7 bis 65 Milliarden), aber eine bessere Leistung aufweist. Beispielsweise ist das größte LLaMA-Modell mit 65 Milliarden Parametern mit Chinchilla-70B und PaLM von Google vergleichbar -540B, so viele Forscher waren begeistert, als es veröffentlicht wurde.
Allerdings ist LLaMA nur für die Nutzung durch akademische Forscher lizenziert, wodurch die kommerzielle Anwendung des Modells eingeschränkt ist.
Daher begannen Forscher, nach LLaMAs zu suchen, die für kommerzielle Zwecke genutzt werden können. Das von Hao Liu, einem Doktoranden an der UC Berkeley, initiierte Projekt OpenLLaMA ist eine der beliebtesten Open-Source-Kopien von LLaMA, die verwendet werden genau das gleiche LLaMA wie das ursprüngliche LLaMA Für die Vorverarbeitung und das Training von Hyperparametern kann man sagen, dass OpenLLaMA vollständig den Trainingsschritten von LLaMA folgt. Am wichtigsten ist, dass das Modell im Handel erhältlich ist.
OpenLLaMA wird auf dem von Together Company veröffentlichten RedPajama-Datensatz trainiert. Es gibt drei Modellversionen, nämlich 3B, 7B und 13B. Diese Modelle wurden mit 1T-Tokens trainiert. Die Ergebnisse zeigen, dass die Leistung von OpenLLaMA bei mehreren Aufgaben mit der des ursprünglichen LLaMA vergleichbar ist oder diese sogar übertrifft.
Neben der ständigen Veröffentlichung neuer Modelle untersuchen Forscher ständig die Fähigkeit des Modells, mit Token umzugehen.
Vor ein paar Tagen erweiterte die neueste Forschung des Teams von Tian Yuandong den LLaMA-Kontext mit weniger als 1000 Feinabstimmungsschritten auf 32K. Noch weiter zurückgehend: GPT-4 unterstützt 32.000 Token (was 50 Textseiten entspricht), Claude kann 100.000 Token verarbeiten (ungefähr gleichbedeutend mit der Zusammenfassung des ersten Teils von „Harry Potter“ mit einem Klick) und so weiter.
Jetzt kommt ein neues groß angelegtes Sprachmodell auf Basis von OpenLLaMA, das die Länge des Kontexts auf 256.000 Token und noch mehr erweitert. Die Forschung wurde gemeinsam von IDEAS NCBR, der Polnischen Akademie der Wissenschaften, der Universität Warschau und Google DeepMind durchgeführt.
 Pictures
Pictures
LongLLaMA basiert auf OpenLLaMA und die Feinabstimmungsmethode verwendet FOT (Focused Transformer). Dieser Artikel zeigt, dass FOT zur Feinabstimmung bereits vorhandener großer Modelle verwendet werden kann, um ihre Kontextlänge zu erweitern.
Die Studie verwendet die Modelle OpenLLaMA-3B und OpenLLaMA-7B als Ausgangspunkt und verfeinert sie mithilfe von FOT. Die resultierenden Modelle, LONGLLAMAs genannt, sind in der Lage, über die Länge ihres Trainingskontexts hinaus zu extrapolieren (sogar bis zu 256 KB) und die Leistung bei Aufgaben mit kurzem Kontext aufrechtzuerhalten.
Jemand hat diese Forschung als beschrieben Mit der unbegrenzten Kontextversion von OpenLLaMA kann das Modell problemlos auf längere Sequenzen extrapoliert werden. Beispielsweise kann ein auf 8K-Tokens trainiertes Modell problemlos auf eine Fenstergröße von 256K extrapoliert werden.
 Bilder
Bilder
Dieser Artikel verwendet die FOT-Methode, eine Plug-and-Play-Erweiterung des Transformer-Modells und kann zum Trainieren neuer Modelle oder zur Feinabstimmung vorhandener größerer Modelle mit längeren Kontexten verwendet werden.
Um dies zu erreichen, verwendet FOT eine Gedächtnis-Aufmerksamkeitsschicht und einen stapelübergreifenden Trainingsprozess:
Eine Übersicht über die FOT-Architektur finden Sie in Abbildung 2:
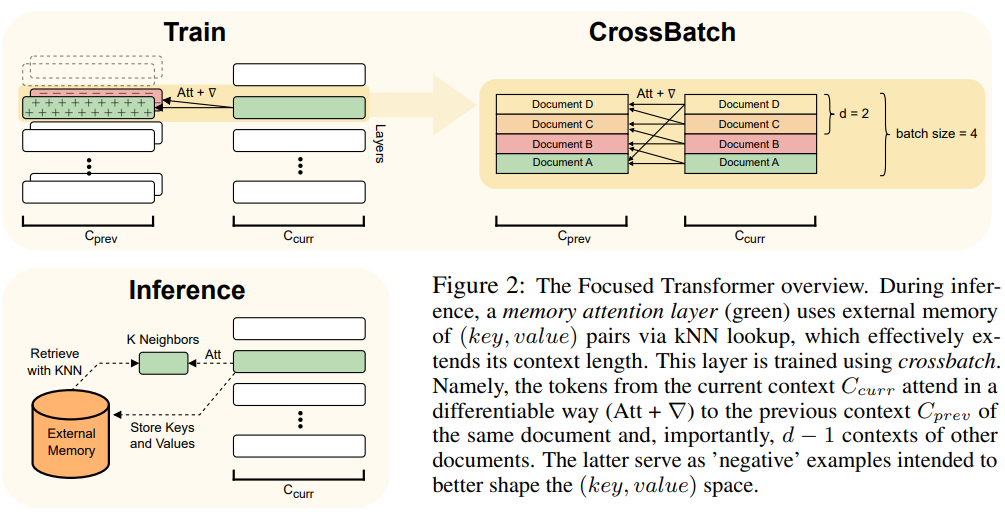 Bilder
Bilder
Die folgende Tabelle zeigt einige Modellinformationen für LongLLaMA:
 Bilder
Bilder
Endlich die Im Projekt werden auch Vergleichsergebnisse zwischen LongLLaMA und dem ursprünglichen OpenLLaMA-Modell bereitgestellt.
Das Bild unten zeigt einige experimentelle Ergebnisse von LongLLaMA. Bei der Aufgabe zum Abrufen von Passwörtern erzielte LongLLaMA eine gute Leistung. Insbesondere hat das LongLLaMA 3B-Modell seine Trainingskontextlänge von 8 KB bei weitem überschritten und eine Genauigkeit von 94,5 % für 100.000 Token und 73 % für 256.000 Token erreicht.
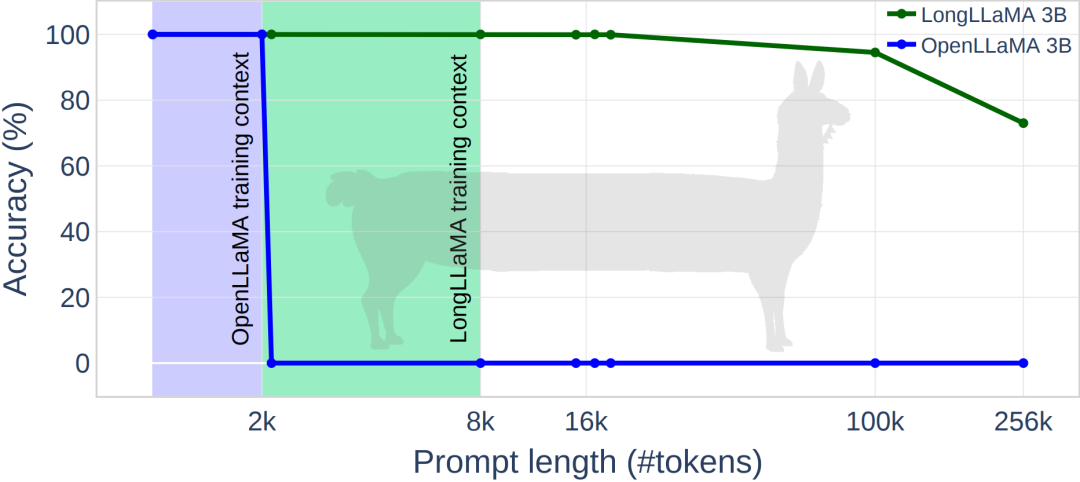 Bilder
Bilder
Die folgende Tabelle zeigt die Ergebnisse des LongLLaMA 3B-Modells für zwei nachgelagerte Aufgaben (TREC-Fragenklassifizierung und WebQS-Fragenbeantwortung). Die Ergebnisse zeigen, dass sich die LongLLaMA-Leistung bei Verwendung eines langen Kontexts erheblich verbessert.
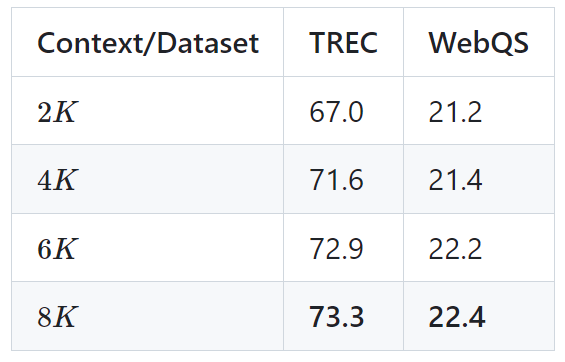 Bild
Bild
Die Tabelle unten zeigt, wie LongLLaMA auch bei Aufgaben gut abschneidet, die keinen langen Kontext erfordern. Die Experimente vergleichen LongLLaMA und OpenLLaMA in einer Null-Sample-Umgebung.
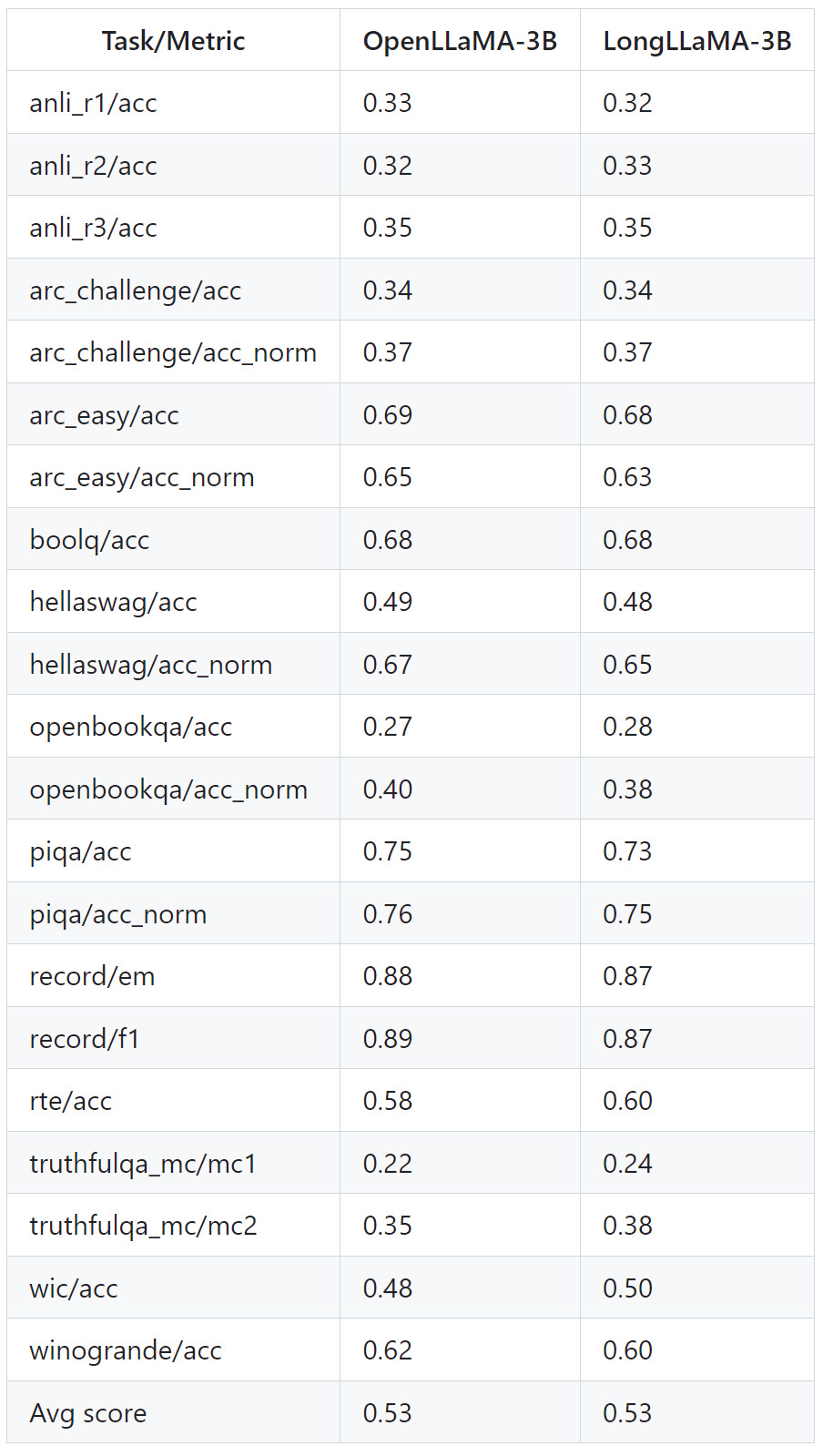 Bilder
Bilder
Weitere Einzelheiten finden Sie im Originalpapier und im Projekt.
Das obige ist der detaillierte Inhalt vonErweitern Sie die Kontextlänge auf 256 KB. Kommt die unbegrenzte Kontextversion von LongLLaMA?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Blockchain-Abfrage des Ethereum-Browsers
Blockchain-Abfrage des Ethereum-Browsers
 Was tun, wenn das Desktopsymbol des Computers nicht geöffnet werden kann?
Was tun, wenn das Desktopsymbol des Computers nicht geöffnet werden kann?
 Was ist der Unterschied zwischen Datenbankansichten und Tabellen?
Was ist der Unterschied zwischen Datenbankansichten und Tabellen?
 So verwenden Sie eine Python-for-Schleife
So verwenden Sie eine Python-for-Schleife
 Zu welcher Währung gehört USDT?
Zu welcher Währung gehört USDT?
 So deaktivieren Sie den automatischen WeChat-Download
So deaktivieren Sie den automatischen WeChat-Download
 Tutorial zur Symboleingabe in voller Breite
Tutorial zur Symboleingabe in voller Breite
 Erstellen Sie einen Internetserver
Erstellen Sie einen Internetserver












