


Der KI-Agent von DeepMind neckt sich wieder selbst!
Schauen Sie sich diesen Kerl namens BBF an. Er hat 26 Atari-Spiele in nur 2 Stunden gemeistert. Seine Effizienz ist mit der von Menschen vergleichbar und übertrifft alle seine Vorgänger.
Sie müssen wissen, dass KI-Agenten bei der Lösung von Problemen durch verstärkendes Lernen schon immer effektiv waren, aber das größte Problem besteht darin, dass diese Methode sehr ineffizient ist und lange Zeit zum Erkunden benötigt.
 Bilder
Bilder
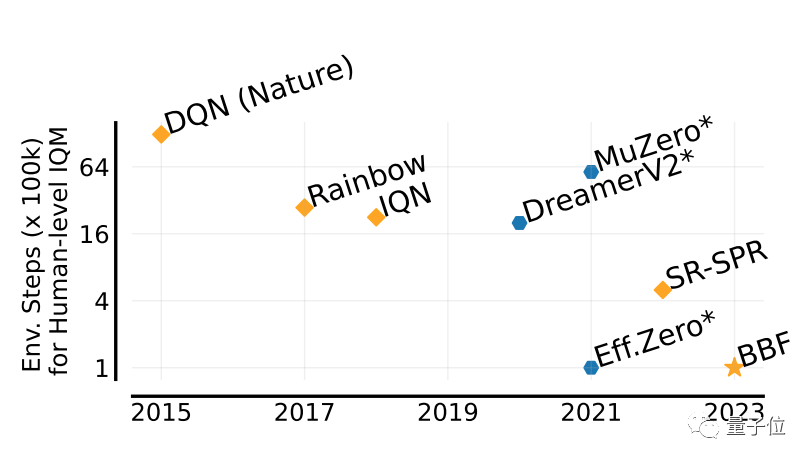
Der Durchbruch von BBF liegt gerade in der Effizienz.
Kein Wunder, dass der vollständige Name Bigger, Better oder Faster lauten kann.
Und es kann das Training auf nur einer einzigen Karte absolvieren, und auch der Bedarf an Rechenleistung wird deutlich reduziert.
BBF wurde gemeinsam von Google DeepMind und der Universität Montreal vorgeschlagen. Die Daten und der Code sind derzeit Open Source.
Der Wert, der zur Bewertung der Leistung von BBF-Spielen verwendet wird, wird als IQM bezeichnet.
IQM ist eine umfassende Bewertung der vielschichtigen Spielleistung. Die IQM-Bewertungen in diesem Artikel basieren auf Menschen.
Verglichen mit mehreren früheren Ergebnissen erreichte BBF den höchsten IQM-Wert im Atari 100K-Testdatensatz mit 26 Atari-Spielen.
Und in den 26 Spielen, in denen es trainiert wurde, hat die Leistung von BBF die von Menschen übertroffen.
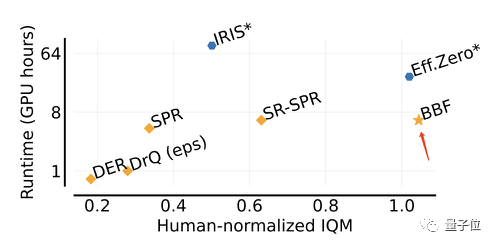
Im Vergleich zu Eff.Zero, das eine ähnliche Leistung erbringt, verbraucht BBF fast die Hälfte der GPU-Zeit.
Was SPR und SR-SPR betrifft, die ähnlich viel GPU-Zeit verbrauchen, liegt ihre Leistung weit hinter BBF.
 Bild
Bild
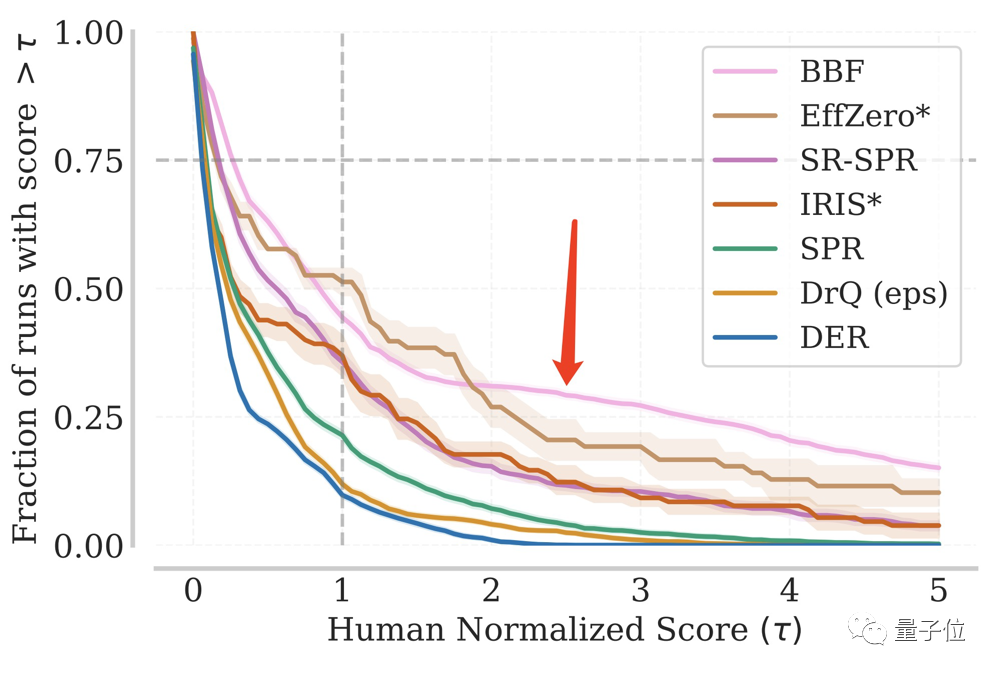
In wiederholten Tests blieb der Anteil der BBF, die einen bestimmten IQM-Wert erreichten, immer auf einem hohen Niveau.
Selbst in mehr als 1/8 der gesamten Testläufe erreichte es die 5-fache Leistung des Menschen.
 Bilder
Bilder
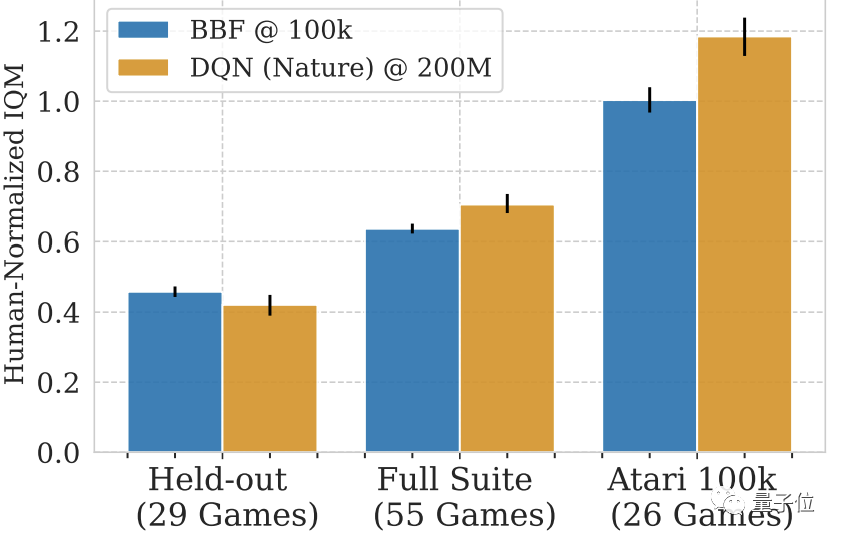
Selbst mit der Hinzunahme anderer Atari-Spiele ohne Training kann BBF mehr als die Hälfte des IQM-Scores eines Menschen erreichen.
Wenn man sich allein diese 29 untrainierten Spiele anschaut, beträgt die Punktzahl von BBF 40 bis 50 % der Punktzahl von Menschen.
 Bilder
Bilder
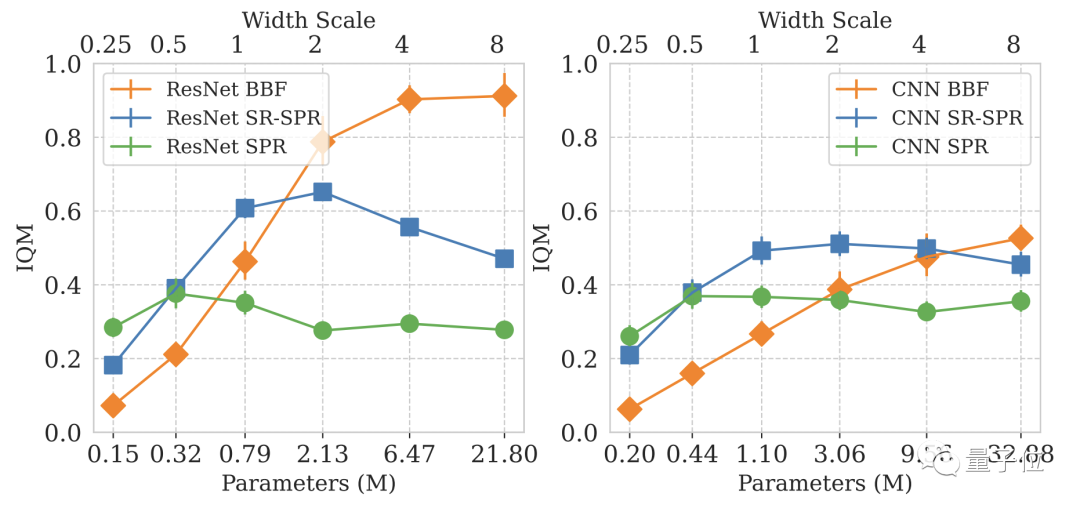
Das Problem, das die BBF-Forschung antreibt, besteht darin, wie man tiefe Verstärkungslernnetzwerke erweitern kann, wenn die Stichprobengröße gering ist.
Um dieses Problem zu untersuchen, konzentrierte sich DeepMind auf den Atari 100K-Benchmark.
Aber DeepMind stellte bald fest, dass eine einfache Vergrößerung der Modellgröße die Leistung nicht verbesserte.
 Bilder
Bilder
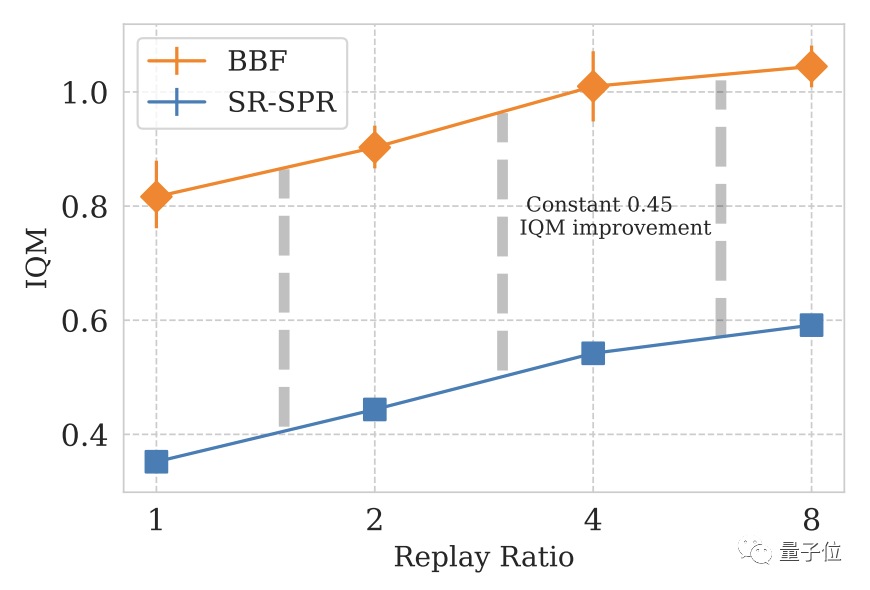
Beim Design von Deep-Learning-Modellen ist die Anzahl der Aktualisierungen pro Schritt (Replay Ratio, RR) ein wichtiger Parameter.
Speziell bei Atari-Spielen gilt: Je höher der RR-Wert, desto höher ist die Leistung des Modells im Spiel.
Schließlich verwendet DeepMind SR-SPR als Basismotor und der RR-Wert von SR-SPR kann bis zu 16 erreichen.
Nach umfassender Überlegung wählte DeepMind 8 als RR-Wert von BBF.
Da einige Benutzer nicht bereit sind, die Rechenkosten von RR=8 auszugeben, hat DeepMind auch die RR=2-Version von BBF entwickelt
 Bilder
Bilder
Nachdem DeepMind viele Inhalte in SR-SPR geändert hatte, übernahm es seine eigenen Die von BBF erworbene Supervisionsausbildung umfasst hauptsächlich die folgenden Aspekte:
Bilder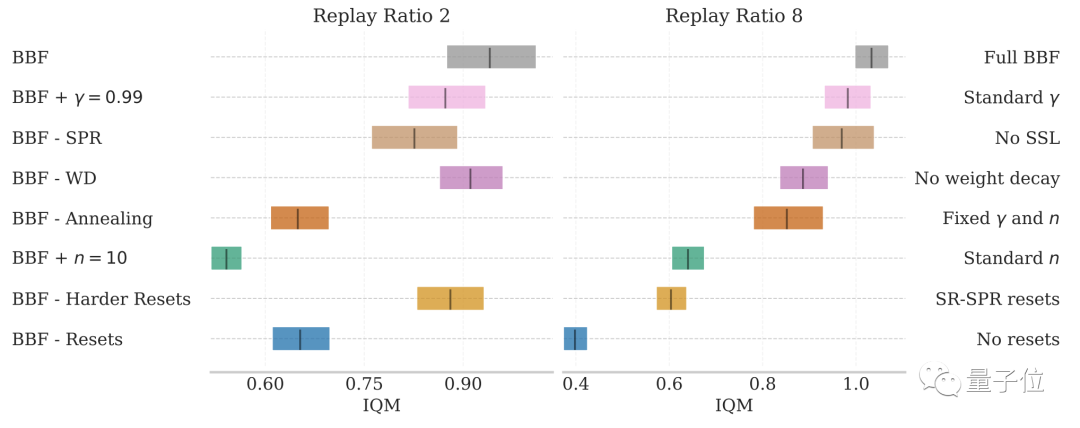 Unter diesen sind die Auswirkungen eines Hard-Resets und einer Verringerung der Update-Reichweite am bedeutendsten.
Unter diesen sind die Auswirkungen eines Hard-Resets und einer Verringerung der Update-Reichweite am bedeutendsten.
Bilder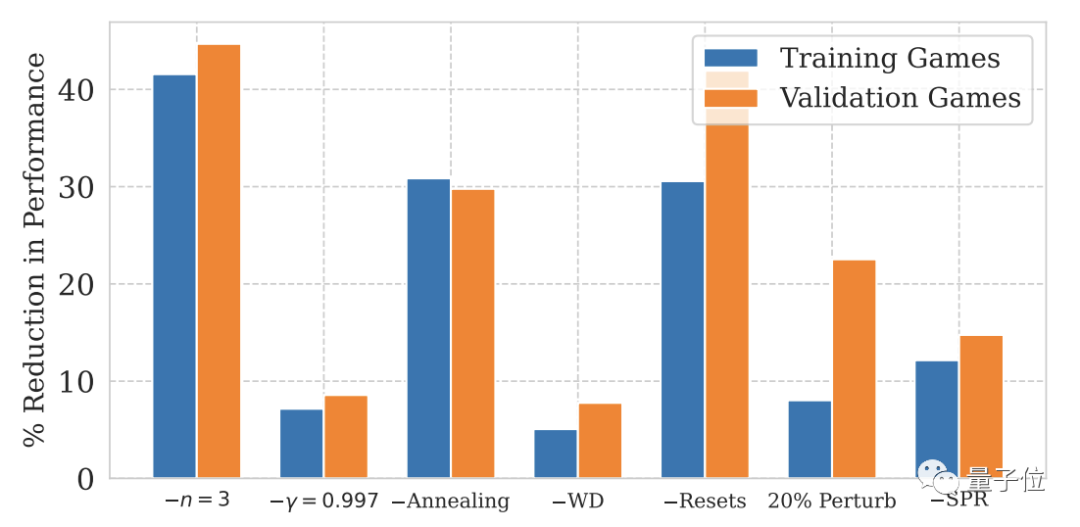 Für NoisyNet, das in den beiden obigen Abbildungen nicht erwähnt wird, ist der Einfluss auf die Modellleistung nicht signifikant.
Für NoisyNet, das in den beiden obigen Abbildungen nicht erwähnt wird, ist der Einfluss auf die Modellleistung nicht signifikant.
Bilder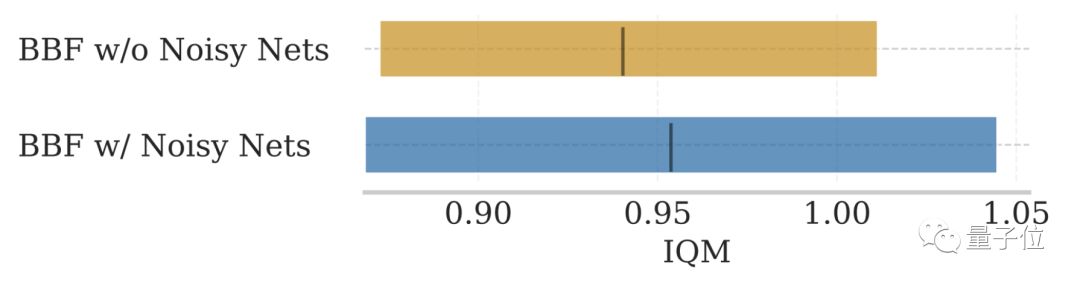 Papieradresse:
Papieradresse:
[2]https://www.marktechpost.com/2023/06/12/superhuman-performance-on-the -atari-100k-benchmark-the-power-of-bbf-a-new-value-based-rl-agent-from-google-deepmind-mila-and-universite-de-montreal/
– Ende –
Das obige ist der detaillierte Inhalt vonEr kann Menschen in zwei Stunden übertreffen! Die neueste KI von DeepMind führt 26 Atari-Spiele im Speedrun aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 CSS deaktiviert das Klickereignis
CSS deaktiviert das Klickereignis
 So registrieren Sie eine geschäftliche E-Mail-Adresse
So registrieren Sie eine geschäftliche E-Mail-Adresse
 Yiou-Handelssoftware herunterladen
Yiou-Handelssoftware herunterladen
 Warum kommt vom Computer kein Ton?
Warum kommt vom Computer kein Ton?
 Was sind die Klassifizierungen von Linux-Systemen?
Was sind die Klassifizierungen von Linux-Systemen?
 So deaktivieren Sie die ICS-Netzwerkfreigabe
So deaktivieren Sie die ICS-Netzwerkfreigabe
 So eröffnen Sie ein Konto bei U-Währung
So eröffnen Sie ein Konto bei U-Währung
 Anhand welcher Dateitypen können Sie diese identifizieren?
Anhand welcher Dateitypen können Sie diese identifizieren?

























