


Im Bereich der KI-Malerei haben der von Alibaba vorgeschlagene Composer und der von Stanford vorgeschlagene ControlNet auf der Grundlage der stabilen Diffusion die theoretische Entwicklung der kontrollierbaren Bilderzeugung vorangetrieben. Allerdings ist die Erforschung der steuerbaren Videoerzeugung in der Branche noch relativ unklar.
Im Vergleich zur Bilderzeugung ist steuerbares Video komplexer, da es neben der Steuerbarkeit des Raums des Videoinhalts auch die Steuerbarkeit der Zeitdimension erfüllen muss. Auf dieser Grundlage übernahmen die Forschungsteams von Alibaba und Ant Group die Führung bei einem Versuch und schlugen VideoComposer vor, der durch ein kombiniertes Generierungsparadigma gleichzeitig Videosteuerbarkeit in Zeit- und Raumdimensionen erreicht.

Vorne Zu dieser Zeit stellte Alibaba das Vincent-Videomodell in der Magic Community und Hugging Face als Open-Source-Version zur Verfügung, was unerwartet große Aufmerksamkeit bei in- und ausländischen Entwicklern erregte. Die vom Modell generierten Videos erhielten sogar Reaktionen von Musk selbst Das Modell war in der Magic-Community weiterhin beliebt und erhielt an vielen Tagen Zehntausende internationale Besuche.
Text-to-Video auf Twitter
VideoComposer hat noch einmal die neuesten Ergebnisse wurde von der internationalen Gemeinschaft weithin aufgenommen konzentrieren Sie sich auf. V ideoComposer auf Twitter
Tatsächlich ist die Steuerbarkeit visueller Inhalte zu einem höheren Maßstab für die Erstellung geworden, die bei der benutzerdefinierten Bildgenerierung erhebliche Fortschritte gemacht hat, aber immer noch drei große Herausforderungen im Bereich der Videogenerierung aufweist:

Experimentelle Ergebnisse zeigen, dass VideoComposer die zeitlichen und räumlichen Muster von Videos flexibel steuern kann, z. B. das Generieren spezifischer Videos durch einzelne Bilder, handgezeichnete Zeichnungen usw., und sogar den Bewegungsstil des Ziels durch einfache Steuerung steuern kann handgezeichnete Wegbeschreibungen. In dieser Studie wurde die Leistung von VideoComposer direkt bei 9 verschiedenen klassischen Aufgaben getestet und alle erzielten zufriedenstellende Ergebnisse, was die Vielseitigkeit von VideoComposer beweist.
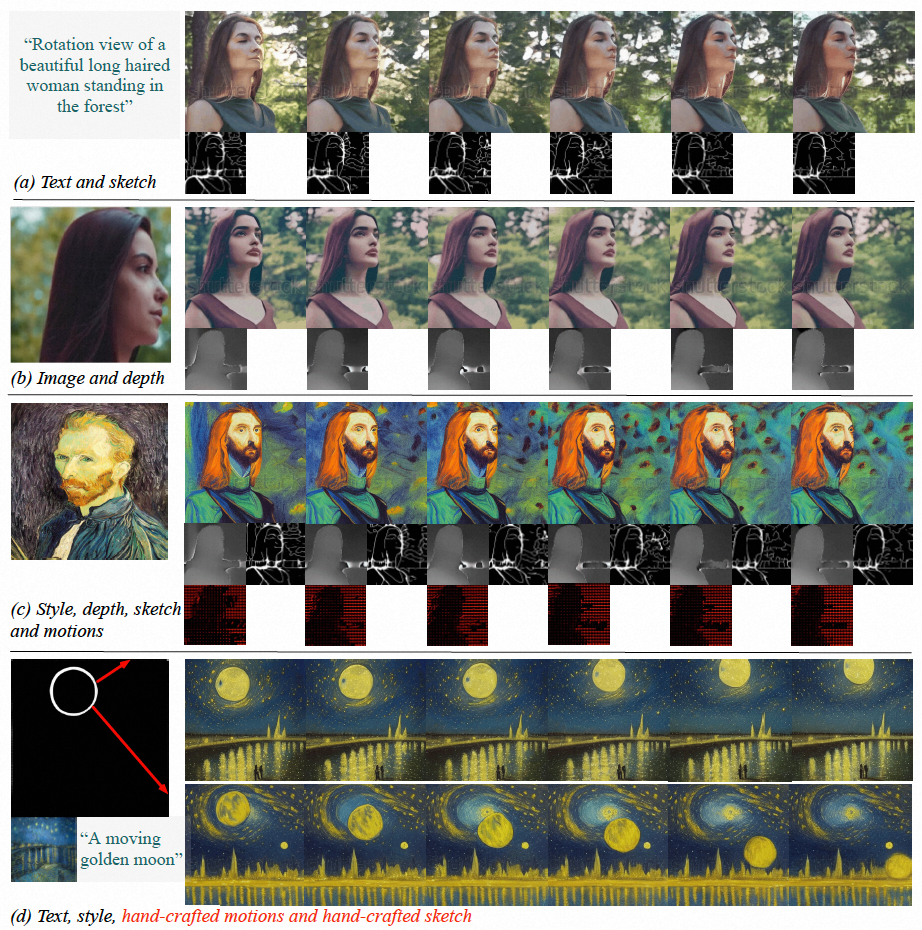
Einführung in die Methode
Video LDM
Versteckter Raum. Video LDM führt zunächst einen vorab trainierten Encoder ein, um das Eingabevideo einer latenten Raumdarstellung zuzuordnen, wobei Um die tatsächliche Verbreitung von Videoinhalten zu erlernen 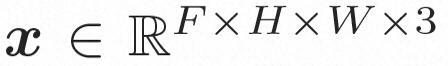
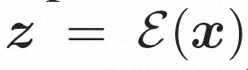
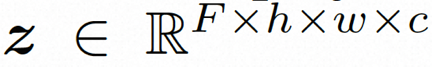 . Anschließend wird der vorab trainierte Decoder D verwendet, um den latenten Raum dem Pixelraum zuzuordnen
. Anschließend wird der vorab trainierte Decoder D verwendet, um den latenten Raum dem Pixelraum zuzuordnen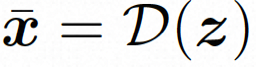 .
. 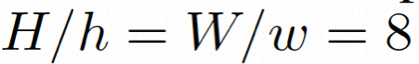
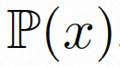
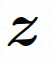
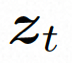
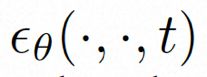
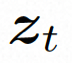
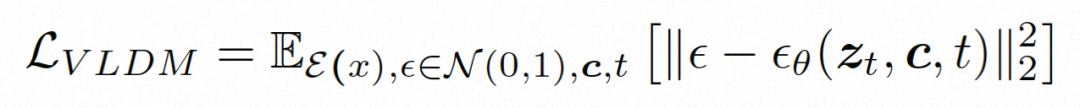
Um das räumliche Lokal vollständig zu erkunden und zu nutzen induktive Vorspannung und Sequenz Für die Rauschunterdrückung mithilfe der zeitlichen Induktionsvorspannung instanziiert VideoComposer 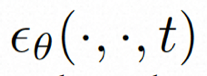
VideoComposer
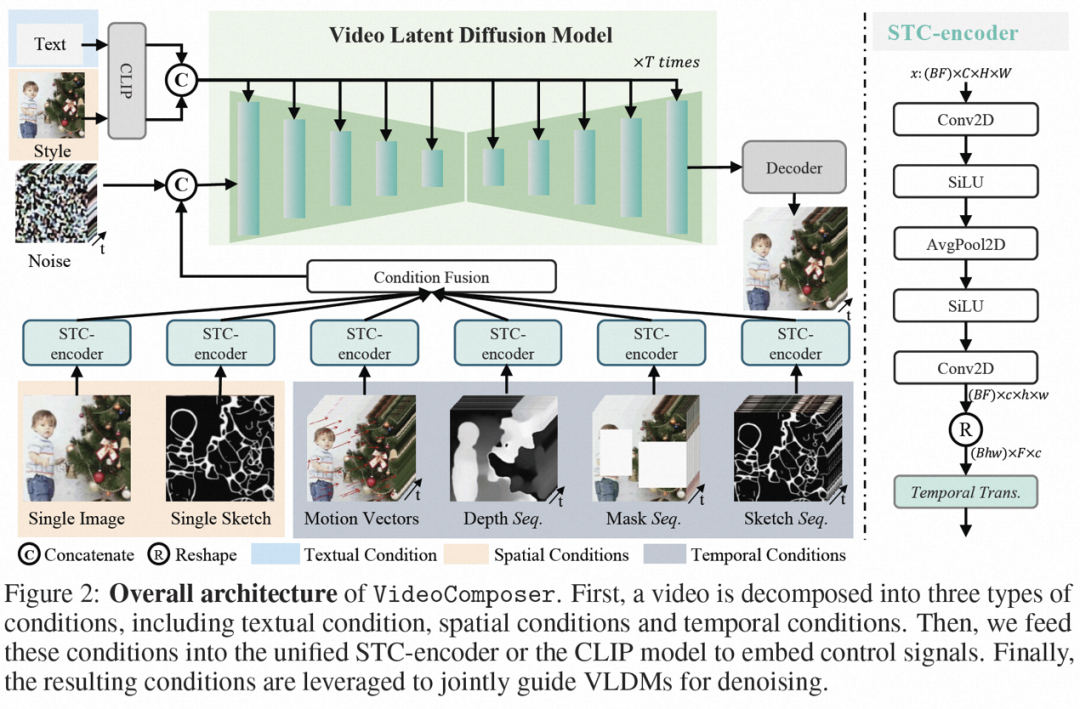
Kombinierte Bedingungen. VideoComposer zerlegt Videos in drei verschiedene Arten von Bedingungen, nämlich Textbedingungen, räumliche Bedingungen und kritische Zeitbedingungen, die zusammen räumliche und zeitliche Muster im Video bestimmen. VideoComposer ist ein allgemeines kombiniertes Videogenerierungs-Framework, sodass je nach nachgeschalteter Anwendung individuellere Bedingungen in VideoComposer integriert werden können, die nicht auf die unten aufgeführten Bedingungen beschränkt sind:
Einzelne Skizze, verwenden Sie PiDiNet, um die Skizze des ersten Videobilds als zweite räumliche Bedingung zu extrahieren; ), um den Stil eines einzelnen Bildes weiter auf das synthetisierte Video zu übertragen, wird die Bilderinbettung als Styleguide ausgewählt
Nach der Verarbeitung der Bedingungen durch den STC-Encoder hat die endgültige Bedingungssequenz die gleiche räumliche Form wie und wird dann durch elementweise Addition verschmolzen. Schließlich wird die zusammengeführte bedingte Sequenz entlang der Kanaldimension als Steuersignal verkettet. Für Text- und Stilbedingungen wird ein Queraufmerksamkeitsmechanismus verwendet, um Text- und Stilanweisungen einzufügen. Training und Inferenz
Zweistufige Trainingsstrategie.
Obwohl VideoComposer durch Vortraining von Bild-LDM initialisiert werden kann, was die Trainingsschwierigkeiten bis zu einem gewissen Grad lindern kann, ist es für das Modell schwierig, die zeitliche Dynamik wahrzunehmen und mehrere Bedingungen zu generieren Gleichzeitig wird der Schwierigkeitsgrad der kombinierten Videogenerierung erhöht. Daher wurde in dieser Studie eine zweistufige Optimierungsstrategie angewendet. In der ersten Stufe wurde das Modell zunächst durch T2V-Training mit Timing-Modellierungsfunktionen ausgestattet. In der zweiten Stufe wurde VideoComposer durch kombiniertes Training optimiert.Begründung.
Während des Argumentationsprozesses wird DDIM verwendet, um die Effizienz des Denkens zu verbessern. Und übernehmen Sie eine klassifikatorfreie Anleitung, um sicherzustellen, dass die generierten Ergebnisse die angegebenen Bedingungen erfüllen. Der Generierungsprozess kann wie folgt formalisiert werden:wobei ω das Führungsverhältnis ist; c1 und c2 sind zwei Sätze von Bedingungen. Dieser Führungsmechanismus wird anhand zweier Bedingungen beurteilt und kann dem Modell durch Intensitätssteuerung eine flexiblere Steuerung ermöglichen.
Experimentelle Ergebnisse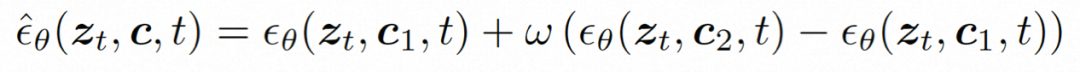
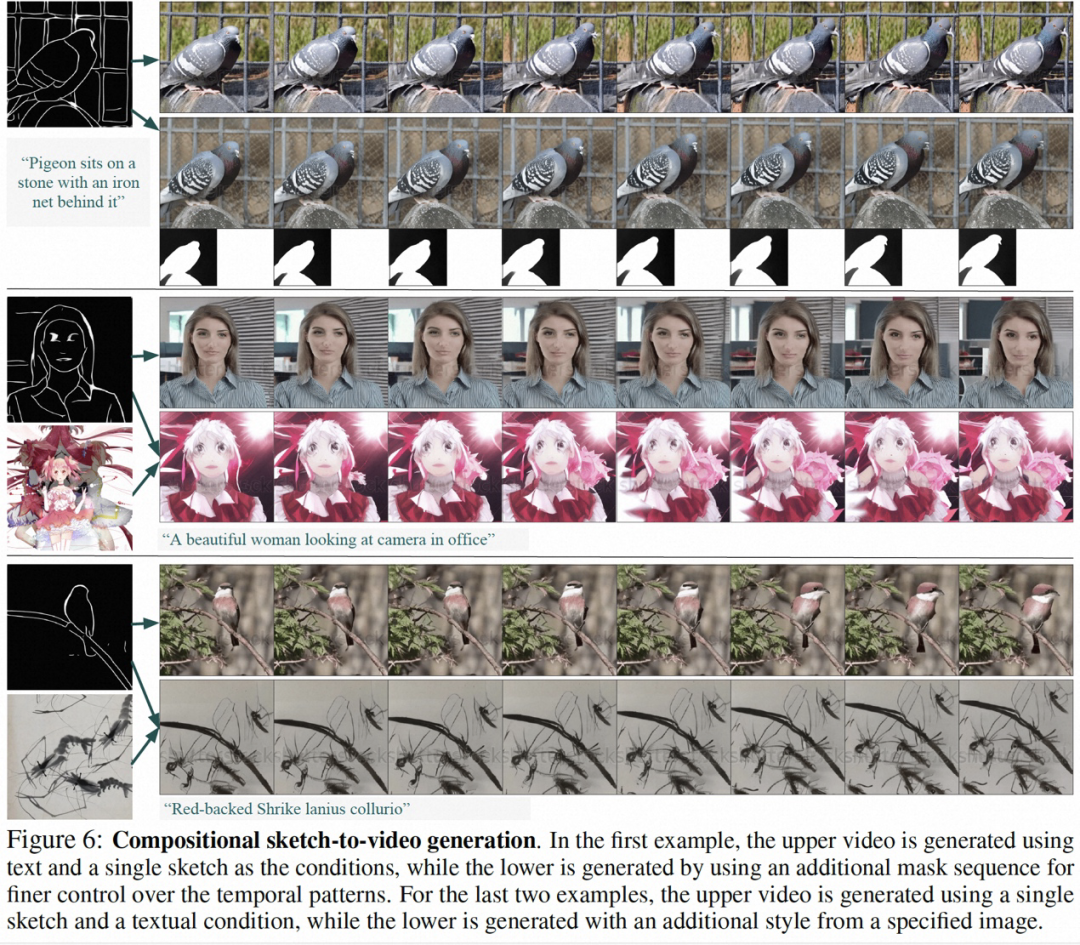
Ein Teil der Ergebnisse dieser Forschung ist wie folgt: statische Bild-zu-Video-Generierung (Abbildung 4), Video-Inpainting (Abbildung 5), statische Skizzen-Generierung zu Video (Abbildung 6), handgezeichnetes Bewegungssteuerungsvideo ( Abbildung 8), Bewegungsübertragung (Abbildung A12) können alle die Vorteile der steuerbaren Videoerzeugung widerspiegeln.


Öffentliche Informationen zeigen, dass sich Alibabas Forschung zu visuellen Basismodellen hauptsächlich auf visuelle Darstellung großer Modelle, visuelle generative große Modelle und Forschung konzentriert Es ist Downstream-Anwendungen und hat mehr als 60 CCF-A-Artikel in verwandten Bereichen veröffentlicht und mehr als 10 internationale Meisterschaften in mehreren Branchenwettbewerben gewonnen, beispielsweise bei der steuerbaren Bilderzeugungsmethode Composer und den Grafik- und Text-Vortrainingsmethoden RA-CLIP und RLEG , unbeschnittene lange Videos zum selbstüberwachten Lernen von HiCo/HiCo++ und die Methode zur Generierung sprechender Gesichter LipFormer stammen alle von diesem Team.
Das obige ist der detaillierte Inhalt vonDie Videogenerierung mit kontrollierbarer Zeit und Raum ist Realität geworden und Alibabas neues Großmodell VideoComposer erfreut sich großer Beliebtheit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



