


Der Hauptinhalt dieses Artikels ist eine Diskussion über Methoden zur generativen Textzusammenfassung, wobei der Schwerpunkt auf dem neuesten Trainingsparadigma unter Verwendung von kontrastivem Lernen und großen Modellen liegt. Es handelt sich hauptsächlich um zwei Artikel: Der eine ist BRIO: Bringing Order to Abstractive Summarization (2022), der kontrastives Lernen verwendet, um Ranking-Aufgaben in generativen Modellen einzuführen, der andere ist On Learning to Summarize with Large Language Models as References (2023) in Based Auf BRIO werden weiterhin große Modelle eingeführt, um hochwertige Trainingsdaten zu generieren.
Beim Generative-Text-Zusammenfassungstraining wird im Allgemeinen die maximale Ähnlichkeitsschätzung verwendet. Zuerst wird ein Encoder verwendet, um das Dokument zu codieren, und dann wird ein Decoder verwendet, um jeden Text in der Zusammenfassung rekursiv vorherzusagen. Das passende Ziel ist eine künstlich erstellte zusammenfassende Standardantwort. Das Ziel, an jeder Position Text zu generieren, der der Standardantwort am nächsten kommt, wird durch eine Optimierungsfunktion dargestellt:
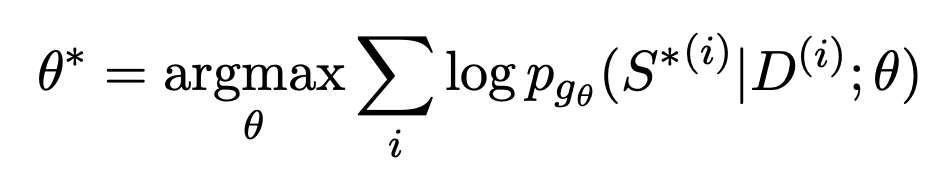
Das Problem bei diesem Ansatz besteht darin, dass das Training nicht mit den tatsächlichen nachgelagerten Aufgaben übereinstimmt. Für ein Dokument können mehrere Zusammenfassungen generiert werden, die von guter oder schlechter Qualität sein können. MLE verlangt, dass das Ziel der Anpassung die einzige Standardantwort sein darf. Diese Lücke erschwert es Textzusammenfassungsmodellen auch, die Vor- und Nachteile zweier Zusammenfassungen unterschiedlicher Qualität effektiv zu vergleichen. Beispielsweise wurde im BRIO-Artikel ein Experiment durchgeführt, das bei der Beurteilung der relativen Reihenfolge zweier Zusammenfassungen mit unterschiedlichen Qualitäten sehr schlechte Ergebnisse liefert.
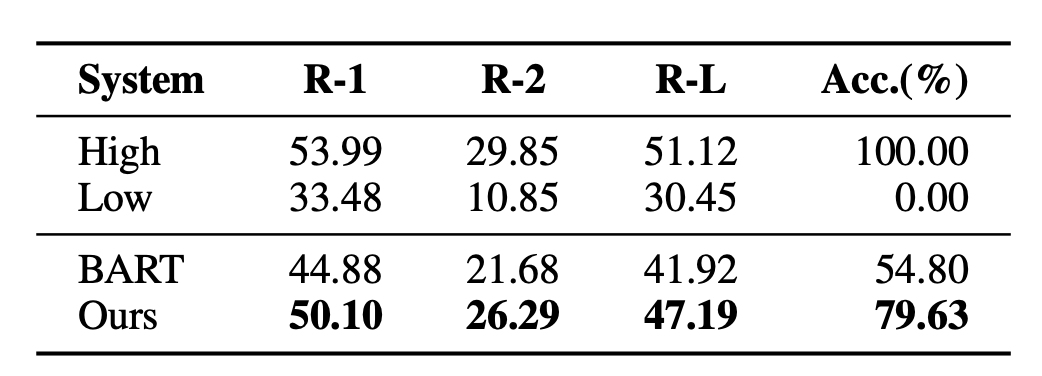
Um die im traditionellen generativen Textzusammenfassungsmodell bestehenden Probleme zu lösen, schlug BRIO: Bringing Order to Abstractive Summarization (2022) vor, kontrastive Lernaufgaben weiter einzuführen in das generative Modell. Verbessern Sie die Fähigkeit des Modells, Zusammenfassungen unterschiedlicher Qualität einzustufen.
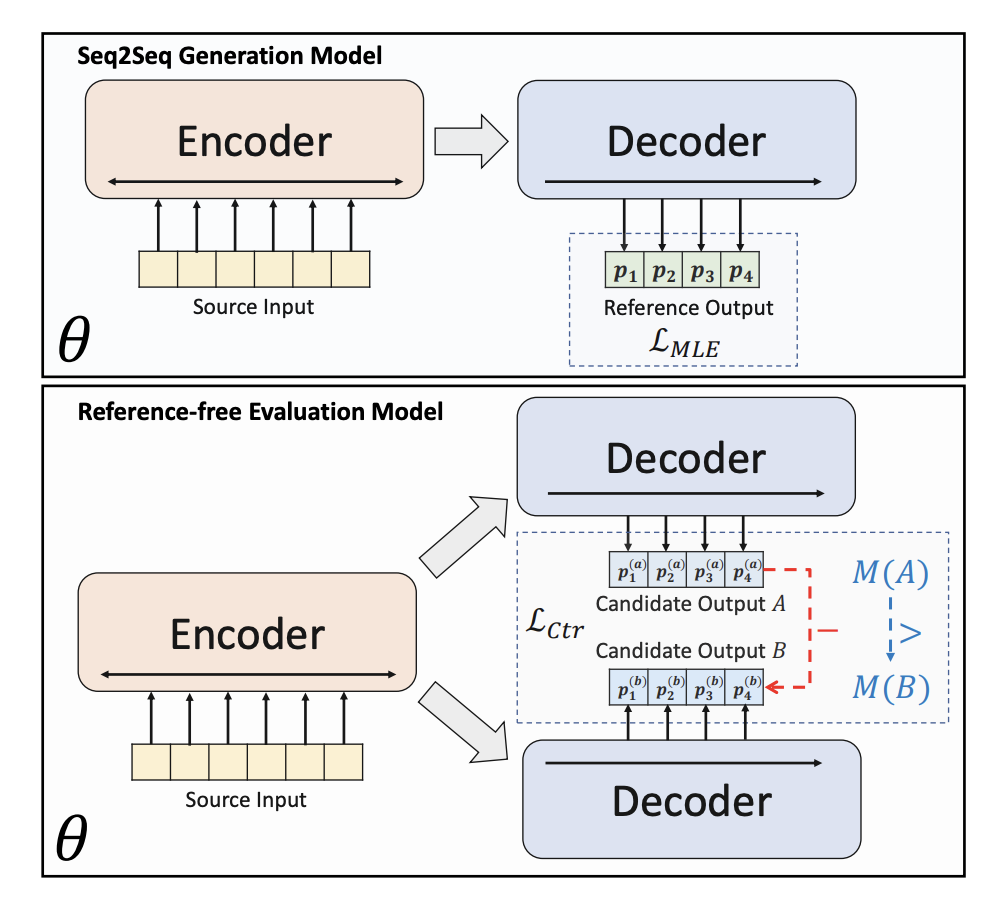
BRIO nutzt Multitasking-Training. Die erste Aufgabe verwendet die gleiche Methode wie herkömmliche generative Modelle, d. h. die Anpassung von Standardantworten durch MLE. Die zweite Aufgabe ist eine kontrastive Lernaufgabe, bei der ein vorab trainiertes Textzusammenfassungsmodell die Strahlsuche verwendet, um zwei verschiedene Ergebnisse zu generieren, und ROUGE verwendet wird, um zu bewerten, welches der beiden generierten Ergebnisse besser ist, und die Standardantwort, um zu bestimmen, welches davon besser ist zwei Sortierung der Abstracts. Die beiden Zusammenfassungsergebnisse werden in den Decoder eingegeben, um die Wahrscheinlichkeiten der beiden Zusammenfassungen zu erhalten. Durch vergleichenden Lernverlust kann das Modell qualitativ hochwertigen Zusammenfassungen höhere Bewertungen verleihen. Die Berechnungsmethode für diesen Teil des vergleichenden Lernverlusts lautet wie folgt:
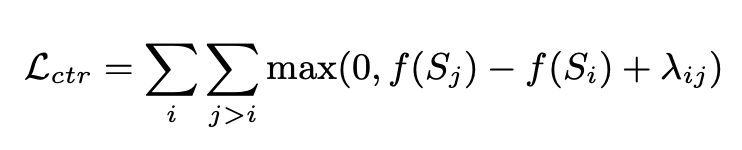
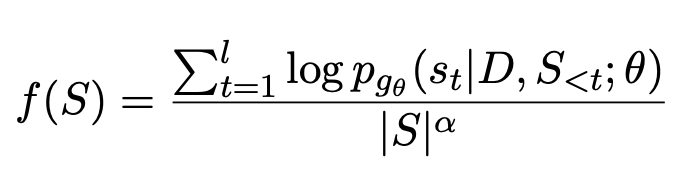
Es wurde festgestellt, dass die Qualität von Zusammenfassungen, die mit großen Modellen wie z GPT ist sogar besser als manuell generierte, daher erfreuen sich solche großen Modelle immer größerer Beliebtheit. In diesem Fall begrenzt die Verwendung künstlich generierter Standardantworten die Obergrenze der Modelleffektivität. Daher schlägt On Learning to Summarize with Large Language Models as References (2023) vor, große Modelle wie GPT zu verwenden, um Trainingsdaten zu generieren, um das Lernen zusammenfassender Modelle zu steuern.
Dieser Artikel schlägt drei Möglichkeiten vor, große Modelle zum Generieren von Trainingsbeispielen zu verwenden.
Die erste besteht darin, die vom großen Modell generierte Zusammenfassung direkt zu verwenden, um die manuell generierte Zusammenfassung zu ersetzen. Dies entspricht der direkten Anpassung der Zusammenfassungsgenerierungsfähigkeit des großen Modells an das Downstream-Modell. Die Trainingsmethode ist immer noch MLE.
Die zweite Methode ist GPTScore, die hauptsächlich ein vorab trainiertes großes Modell verwendet, um die generierte Zusammenfassung zu bewerten, diese Bewertung als Grundlage für die Bewertung der Qualität der Zusammenfassung verwendet und dann eine BRIO-ähnliche Methode für vergleichendes Lerntraining verwendet. GPTScore ist eine in Gptscore: Evaluate as you want (2023) vorgeschlagene Methode zur Bewertung der Qualität von generiertem Text auf der Grundlage eines großen Modells.

Die dritte Methode ist GPTRank. Diese Methode ermöglicht es dem großen Modell, jede Zusammenfassung zu sortieren, anstatt sie direkt zu bewerten, und ermöglicht es dem großen Modell, die Sortierlogik zu erklären, um vernünftigere Sortierergebnisse zu erhalten.

Die Fähigkeit großer Modelle zur Erstellung von Zusammenfassungen wird immer mehr anerkannt. Daher wird die Verwendung großer Modelle als Generator für zusammenfassende Modellanpassungsziele als Ersatz für manuelle Anmerkungsergebnisse zu einem zukünftigen Entwicklungstrend werden. Gleichzeitig ermöglicht die Verwendung von Ranking-Vergleichslernen zum Trainieren der Zusammenfassungsgenerierung, dass das Zusammenfassungsmodell die Qualität der Zusammenfassung wahrnimmt und die ursprüngliche Punktanpassung übertrifft, was auch für die Verbesserung der Wirkung des Zusammenfassungsmodells von entscheidender Bedeutung ist.
Das obige ist der detaillierte Inhalt vonVerwendung großer Modelle zur Schaffung eines neuen Paradigmas für das Textzusammenfassungstraining. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



