


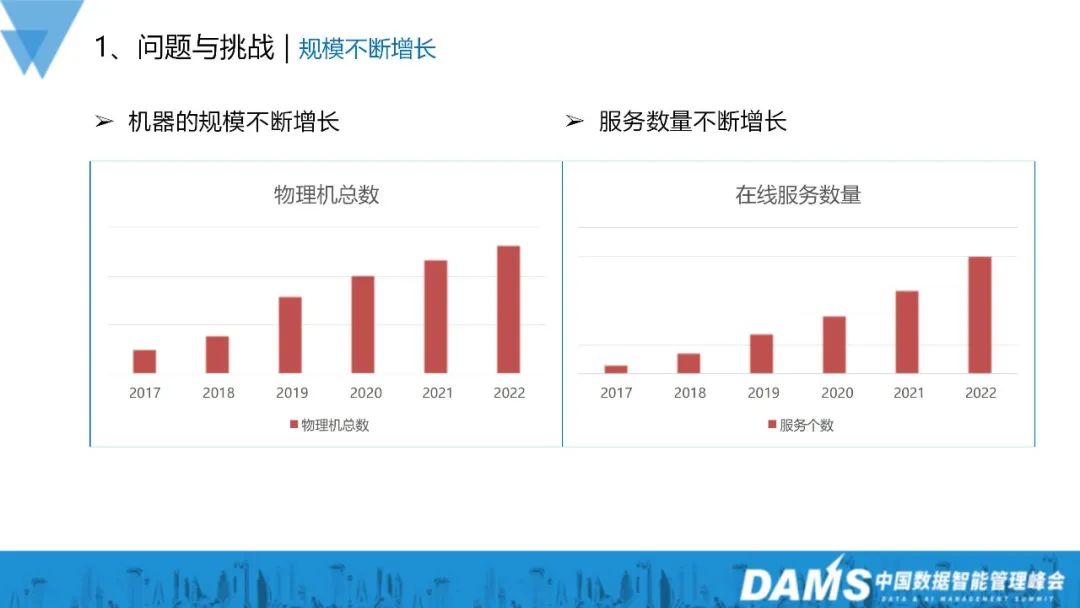
Seit 2017 sind der Maschinenumfang und die Anzahl der Dienste von vivo erheblich gewachsen, was aus der Tabelle ersichtlich ist. Die Größe der Maschine hat sich etwa verfünffacht, und die Anzahl der Dienste hat sich grundsätzlich um mehr als das Zehnfache erhöht. Der Zeitraum reicht von 2017 bis 2022.

Mit zunehmender Größe werden die Herausforderungen und die Komplexität definitiv zunehmen. Typische Herausforderungen in vivo werden hauptsächlich in Veränderungsherausforderungen und Misserfolgsherausforderungen unterteilt.
Es gibt viele große Geschäftsmigrationsszenarien Google SRE hat ein solches Konzept: 70 % der Ausfälle werden durch Änderungen verursacht. Diese Situation besteht auch in vivo und Änderungen werden große Auswirkungen auf die Online-Stabilität haben. 2. Ausfallherausforderungen Kapazitätsanforderungen.
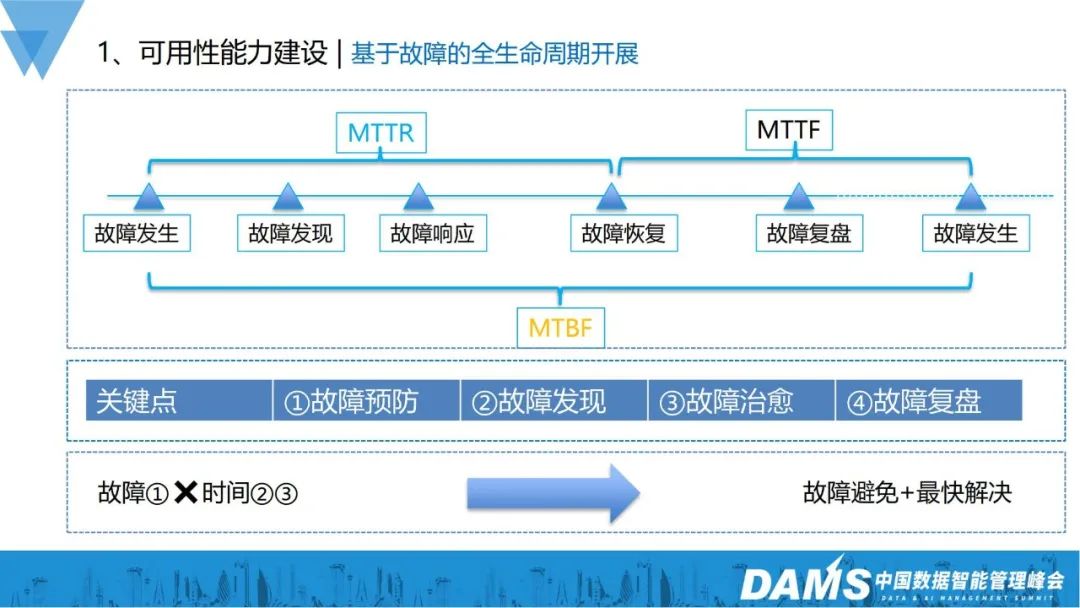
Im Rahmen dieser Herausforderung haben wir die Konstruktion in zwei Dimensionen unterteilt: Verfügbarkeitsfähigkeit und Verfügbarkeitsphase, um die Stabilität des Unternehmens sicherzustellen. 2. Aufbau der Verfügbarkeitsfähigkeit ure Auftreten, Erkennung, Reaktion, Wiederherstellung, Überprüfung und vorbeugende Maßnahmen. Die Zeit vom Auftreten eines Fehlers bis zur Wiederherstellung wird als MTTR bezeichnet; die Zeit von der Wiederherstellung bis zum Auftreten eines Fehlers, von stabil bis instabil, wird als MTTF bezeichnet, die Zeit zwischen dem Auftreten eines Fehlers wird MTBF genannt; Indikatoren. Fehlermanagement ist nichts anderes als diese 4 Punkte:Wie verhindert man das Auftreten von Fehlern?
Wie kann der Fehler schnell behoben werden?
1) Service-Perspektive
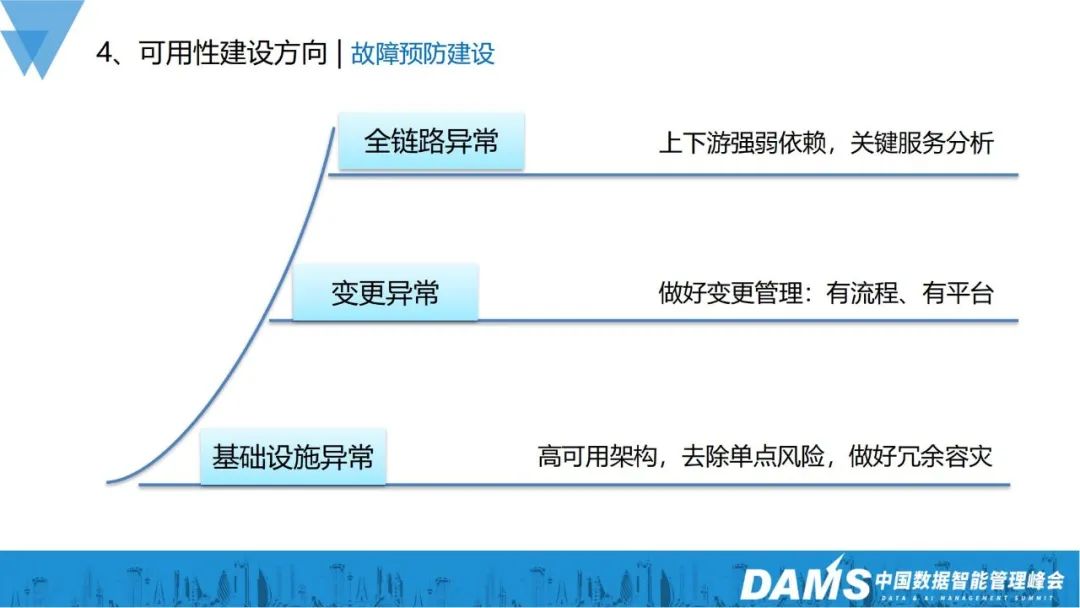
2) Mehrere Eingänge: In der Vergangenheit verfügten viele Unternehmen nach dem Aufbau der Mehrfachzugangsfunktionen von IDC nur über einen einzigen Zugangsebeneneingang und öffentliche Cloud, ein einzelner Die Auswirkungen von Zugangsausnahmen auf den gesamten Dienstzugriff werden geringer sein; Um übermäßige Anfragen zu verhindern, werden die folgenden Dienste ausgeschaltet.
5. Fehlererkennung
Wir haben eine Fehlererkennungsfunktion basierend auf der gesamten Verbindung aufgebaut, die den Kunden umfasst Überwachung, Serverüberwachung und Basisüberwachung: 1) Client-Überwachung: selbst erstelltes Wähltestsystem, Überwachung der Verfügbarkeit jedes Dienstes durch Umgehung des simulierten Benutzerzugriffs 2) Serverüberwachung: Einschließlich Domänennamenüberwachung, Protokollüberwachung und Anrufüberwachung zwischen Diensten, hauptsächlich durch Metriken/Protokolle/Trace; 3) Grundlegende Überwachung: Überwachen Sie die Hardwareressourcennutzung des Hosts, hauptsächlich durch Metriken. 6. Fehlerbehebung umfasst hauptsächlich Fehleranalyse und Fehlerbehandlung.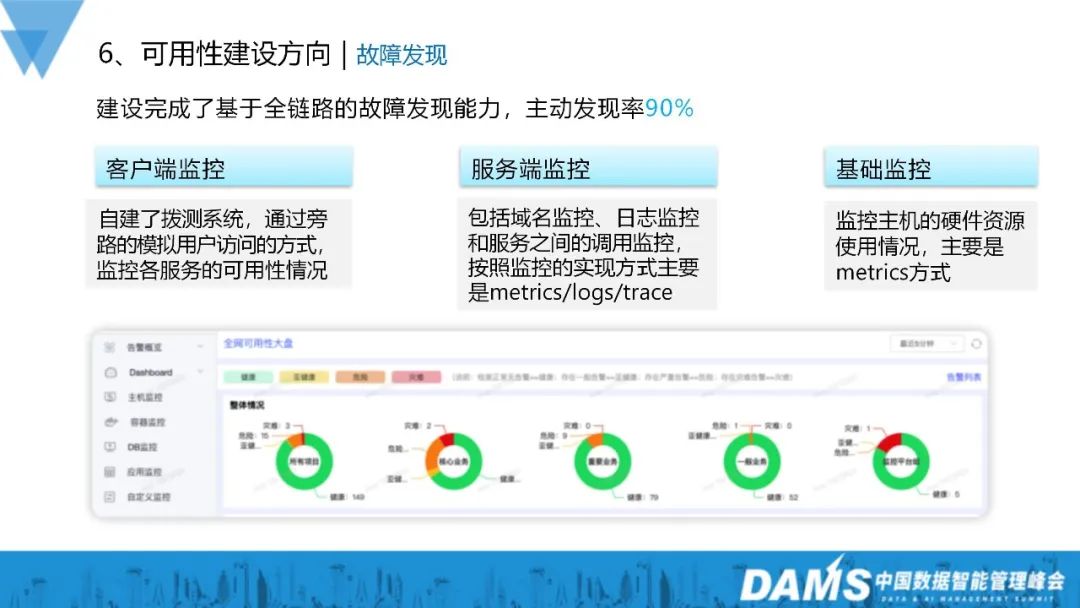
Fehleranalyse: verknüpft mit dem Überwachungssystem zur Unterstützung der Analyse grundlegender Servicefehler, Analyse der Domänennamenverfügbarkeit usw.; usw.
7. Fehlerüberprüfung Die Fehlerüberprüfung ist ein sehr wichtiger Teil des gesamten Hochverfügbarkeits-Konstruktionszyklus.Wir stellen die Stabilität des Unternehmens durch geschäftsbasierte SLA-Klassifizierung sicher und erfassen jeden Ausfall des Unternehmens, verbessern und überprüfen den Kompetenzaufbau:


Nach dem Aufbau der Usability-Fähigkeit unterteilen wir ihn in drei Phasen, um die Usability aufzubauen: Standardisierungsphase, Prozessphase und Plattformphase.
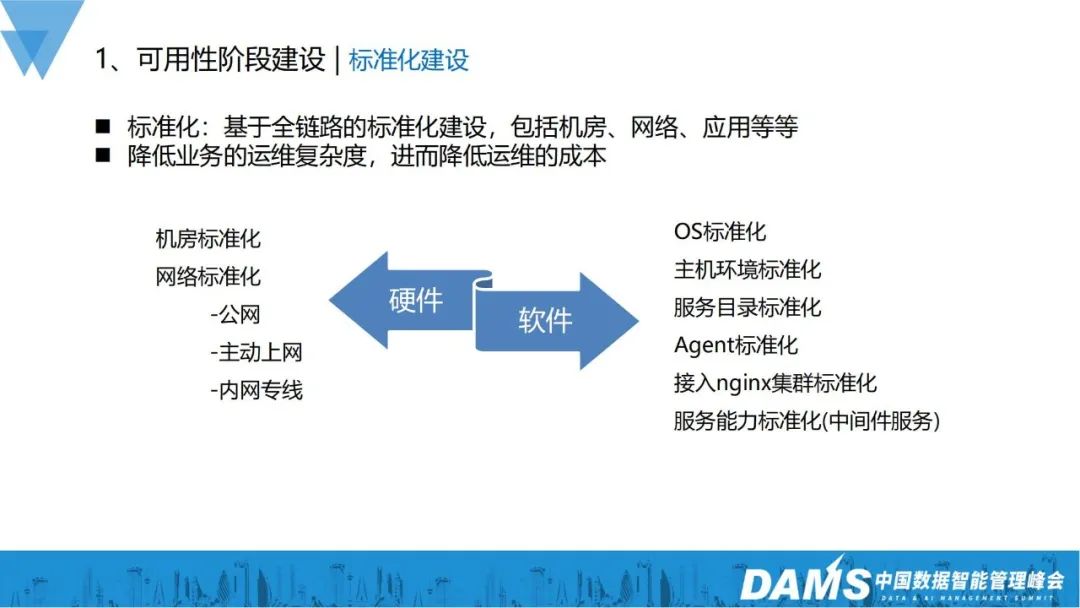
Warum sollten wir Standardisierung aufbauen?
Standardisierung kann die Komplexität des Geschäftsbetriebs und der Wartung erheblich reduzieren und dadurch die Betriebs- und Wartungskosten senken. Wir haben sowohl auf Hardware- als auch auf Softwareebene viel Standardisierungsarbeit geleistet.
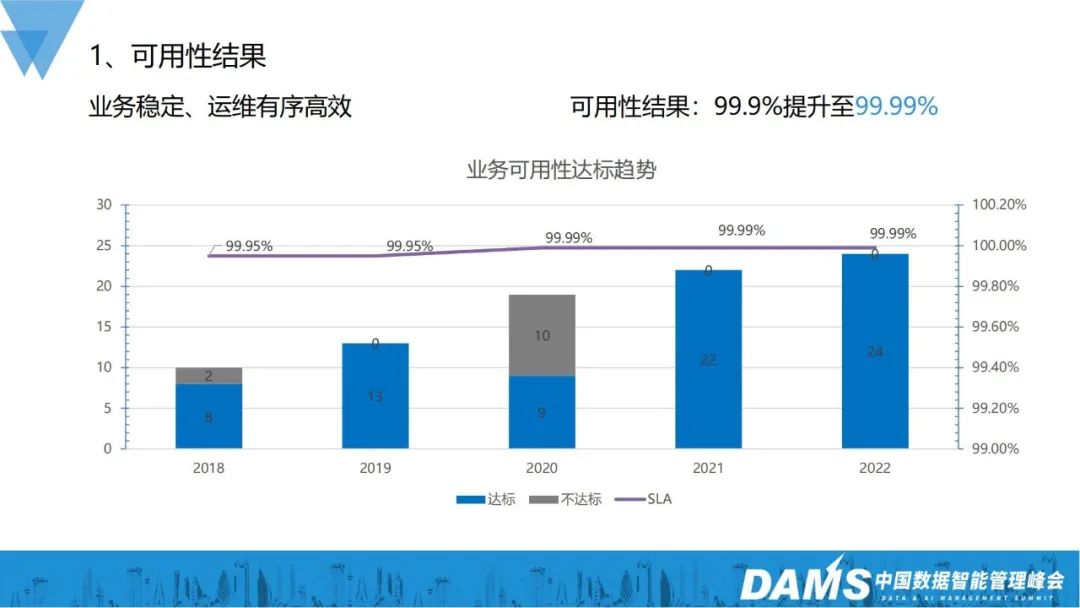
Bis 2022 wird der Betrieb und die Wartung der gesamten Geschäftsstabilität ordnungsgemäß und effizient sein, und die Geschäftsverfügbarkeit wird von den vorherigen 3 9s auf die aktuellen 4 9s steigen, und die Anzahl der Auch die Zahl der Unternehmen, die die Standards erfüllen, steigt von bisher 8 auf jetzt 24.
Verfügbarkeitsphase Aufbau: Standardisierung, Prozess/Normalisierung, Plattform/Automatisierung
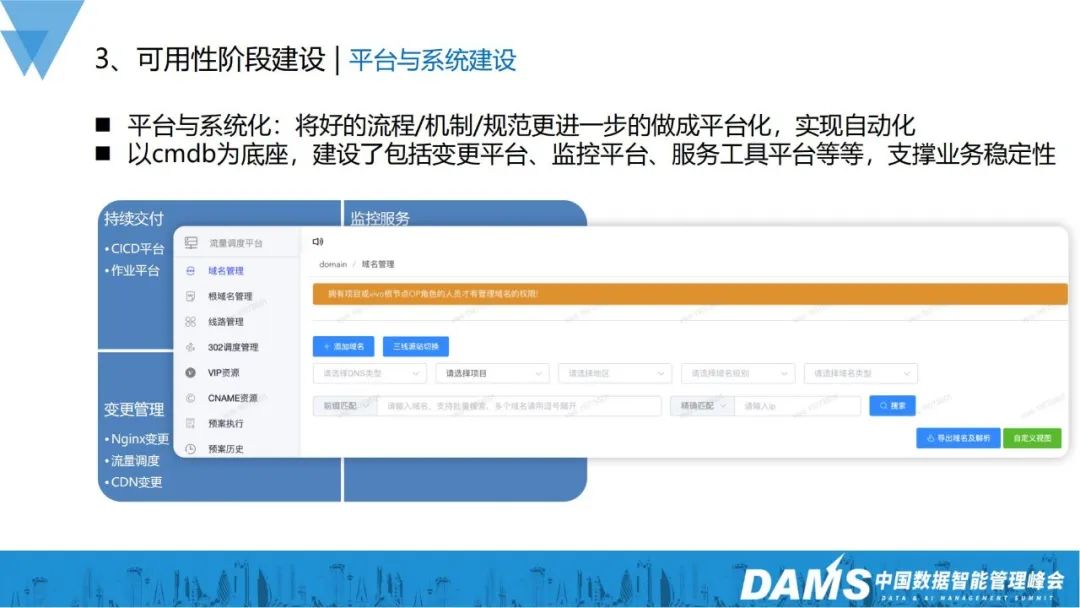
 Früher haben wir mehr reine physische Maschinen verwendet, dann virtuelle Maschinen hinzugefügt und später öffentliche Clouds hinzugefügt, um die Kosten weiter zu senken Gleichzeitig arbeiten wir an Containern und Cloud-Native, um Ressourcen zu vereinen und flexibel zu planen, um die direkte Abhängigkeit von physischen Hardware-Ressourcen zu verringern.
Früher haben wir mehr reine physische Maschinen verwendet, dann virtuelle Maschinen hinzugefügt und später öffentliche Clouds hinzugefügt, um die Kosten weiter zu senken Gleichzeitig arbeiten wir an Containern und Cloud-Native, um Ressourcen zu vereinen und flexibel zu planen, um die direkte Abhängigkeit von physischen Hardware-Ressourcen zu verringern.
Ich persönlich glaube, dass wir nicht nur die Verfügbarkeit, sondern auch die Qualität und die Betriebskosten des Unternehmens berücksichtigen und anschließend in die Phase der verfeinerten Betriebsgarantie eintreten.
F1: Was sind die größten Schwierigkeiten bei der Umsetzung der Usability-Konstruktion?
A1: Der erste Punkt sind die Konstruktionsspezifikationen der zugrunde liegenden technischen Fähigkeiten. Die Nichteinhaltung dieser Spezifikationen führt zu großer Unsicherheit in den Ergebnissen der Geschäftsverfügbarkeit, daher müssen bestimmte Spezifikationen für das Team formuliert werden, und zwar auch Seien Sie sicher Der Bottom-Keeping-Mechanismus;
Der zweite Punkt ist die Anerkennung von der oberen Ebene. Wenn die Stabilität nicht gut gemacht wird, wirkt sich dies auf das Geschäft, den Ruf und den Umsatz aus. Nach Erhalt der Genehmigung der oberen Ebene lässt sich auch die Usability-Konstruktion leichter fördern.
F2: Welche weiteren Informationen wurden während der CMDB-Implementierung neben der verantwortlichen Entwicklungsperson, dem Host und anderen Informationen mit dem eigentlichen Prozess verknüpft? Hängt es beispielsweise mit Middleware-Informationen zusammen?
A2: Viele unserer Systeme basieren derzeit auf CMDB, viele Systeme werden auch in Verbindung mit CMDB erstellt basierend auf CMDB für Service Discovery und Governance.
Vorstellung des Kursleiters
Zhou Jiali ist jetzt Betriebs- und Wartungsleiter von vivo und verantwortlich für den Betrieb und die Wartung des Internetgeschäfts von vivo. Diese Person, die bei Baidu und Tencent gearbeitet hat, verfügt über Erfahrung im Offline-Geschäftsbetrieb und -wartung wie Kunden, Internationalisierung und Big-Data-Algorithmen. Nachdem ich zu vivo gekommen war, leitete ich den Aufbau der Business-Hochverfügbarkeit und verbesserte die Business-Verfügbarkeit auf ein Niveau von 99,99 %.
Das obige ist der detaillierte Inhalt vonDas Geschäft wächst exponentiell. Kann die Usability-Konstruktion so stabil sein?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was tun, wenn die Installation des Soundkartentreibers fehlschlägt?
Was tun, wenn die Installation des Soundkartentreibers fehlschlägt? Verwendung von Elementen in Python
Verwendung von Elementen in Python Was ist eine Bitcoin-Wallet?
Was ist eine Bitcoin-Wallet? So nehmen Sie den Gasverbrauch nach der Zahlung wieder auf
So nehmen Sie den Gasverbrauch nach der Zahlung wieder auf So geben Sie das Kleiner-gleich-Symbol in Windows ein
So geben Sie das Kleiner-gleich-Symbol in Windows ein Was bedeutet Taobao b2c?
Was bedeutet Taobao b2c? Eigenschaft mit linearem Gradienten
Eigenschaft mit linearem Gradienten So stellen Sie eine Verbindung zum LAN her
So stellen Sie eine Verbindung zum LAN her
























