


Inländische, selbst entwickelte große Modelle heißen neue Gesichter willkommen und sind Open Source, sobald sie veröffentlicht werden!
Die neueste Nachricht ist, dass das multimodale große Sprachmodell TigerBot offiziell vorgestellt wurde, einschließlich zwei Versionen von 7 Milliarden Parametern und 180 Milliarden Parametern, beide Open Source.
Die von diesem Modell unterstützte Konversations-KI wird gleichzeitig gestartet.
Das Schreiben von Slogans, das Erstellen von Formularen und das Korrigieren von Grammatikfehlern sind allesamt sehr effektiv; außerdem wird die Multimodalität unterstützt und es können Bilder generiert werden.

Die Evaluierungsergebnisse zeigen, dass TigerBot-7B 96 % der Gesamtleistung von OpenAI-Modellen gleicher Größe erreicht hat.
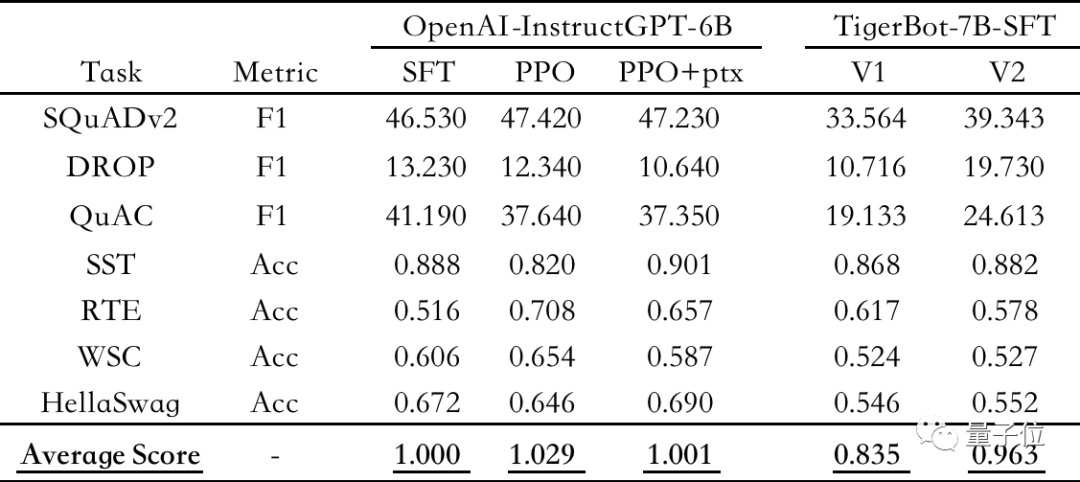
△Automatische Auswertung öffentlicher NLP-Datensätze unter Verwendung von OpenAI-instruct GPT-6B-SFT als Benchmark, Normalisierung und Mittelung der Ergebnisse jedes Modells
Und der größere TigerBot-180B oder Es ist derzeit der größtes Open-Source-Großsprachenmodell der Branche. Darüber hinaus verfügt das Team auch über offene
100G-Pre-Training-Daten und überwachte Feinabstimmung von 1G oder 1 Million Datenstücken. Basierend auf TigerBot können Entwickler in
einem halben Tagihre eigenen großen Modelle erstellen. Derzeit wurde TigerBot Dialogue AI zu internen Tests eingeladen und die Open-Source-Code-Daten wurden auf GitHub hochgeladen
(detaillierte Links finden Sie am Ende des Artikels).
. Aber dieses Team ist keineswegs unbekannt.
Seit 2017 haben sie ihr Unternehmen im Bereich NLP gegründet und sich auf die vertikale Feldsuche spezialisiert.
Er beherrscht den datenintensiven Finanzbereich am besten und hat intensiv mit Founder Securities, Guosen Securities usw. zusammengearbeitet.Gründer und CEO, verfügt über mehr als 20 Jahre Erfahrung in der Branche, war Gastprofessor an der UC Berkeley, hält die 3 besten Konferenzbeiträge und 10 Technologiepatente.
Jetzt sind sie entschlossen, von Spezialgebieten zu allgemeinen Großmodellen überzugehen.
Und wir haben von Anfang an mit dem niedrigsten Basismodell begonnen,
3.000 experimentelle Iterationen innerhalb von 3 Monaten abgeschlossenund wir haben immer noch das Vertrauen, die schrittweisen Ergebnisse der Außenwelt als Open Source zugänglich zu machen. Man kann nicht anders, als die Leute neugierig zu machen: Wer sind sie? Was möchten Sie tun? Welche schrittweisen Ergebnisse wurden bisher erzielt?
Was ist TigerBot?
Umfasst 15 Hauptkategorien von Funktionen wie Generierung, offene Fragen und Antworten, Programmierung, Zeichnen, Übersetzung, Brainstorming usw. und unterstützt mehr als 60 Unteraufgaben.
Es unterstützt auch die
Plug-in-Funktion, die es ermöglicht, das Modell mit dem Internet zu verbinden und aktuellere Daten und Informationen zu erhalten.
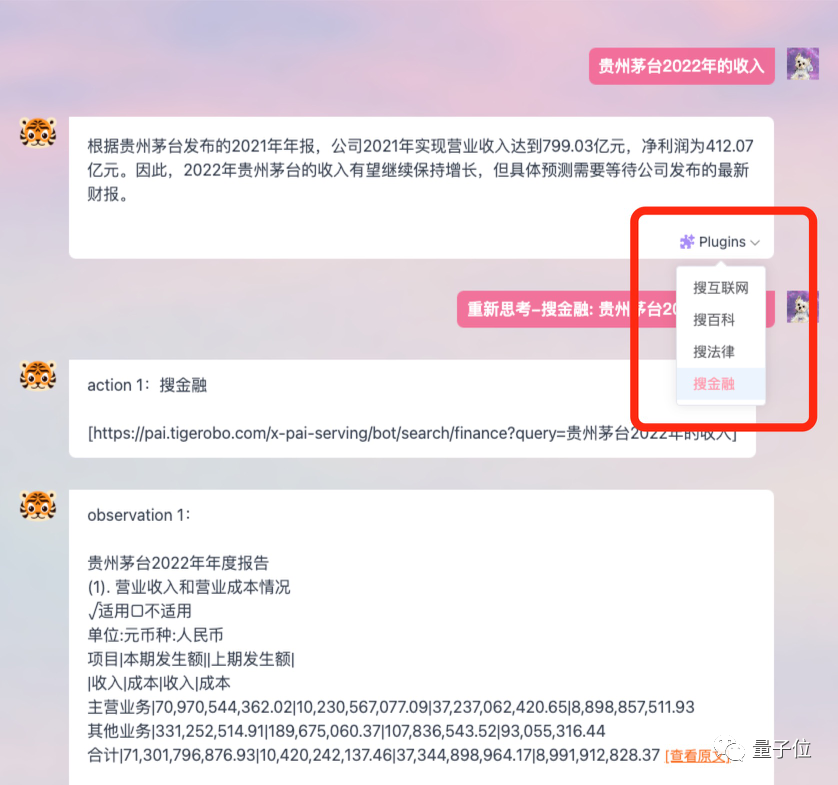
Lassen Sie es mir zum Beispiel helfen, einen Newsflash über Apple Vision Pro zu schreiben, der Effekt ist beeindruckend:

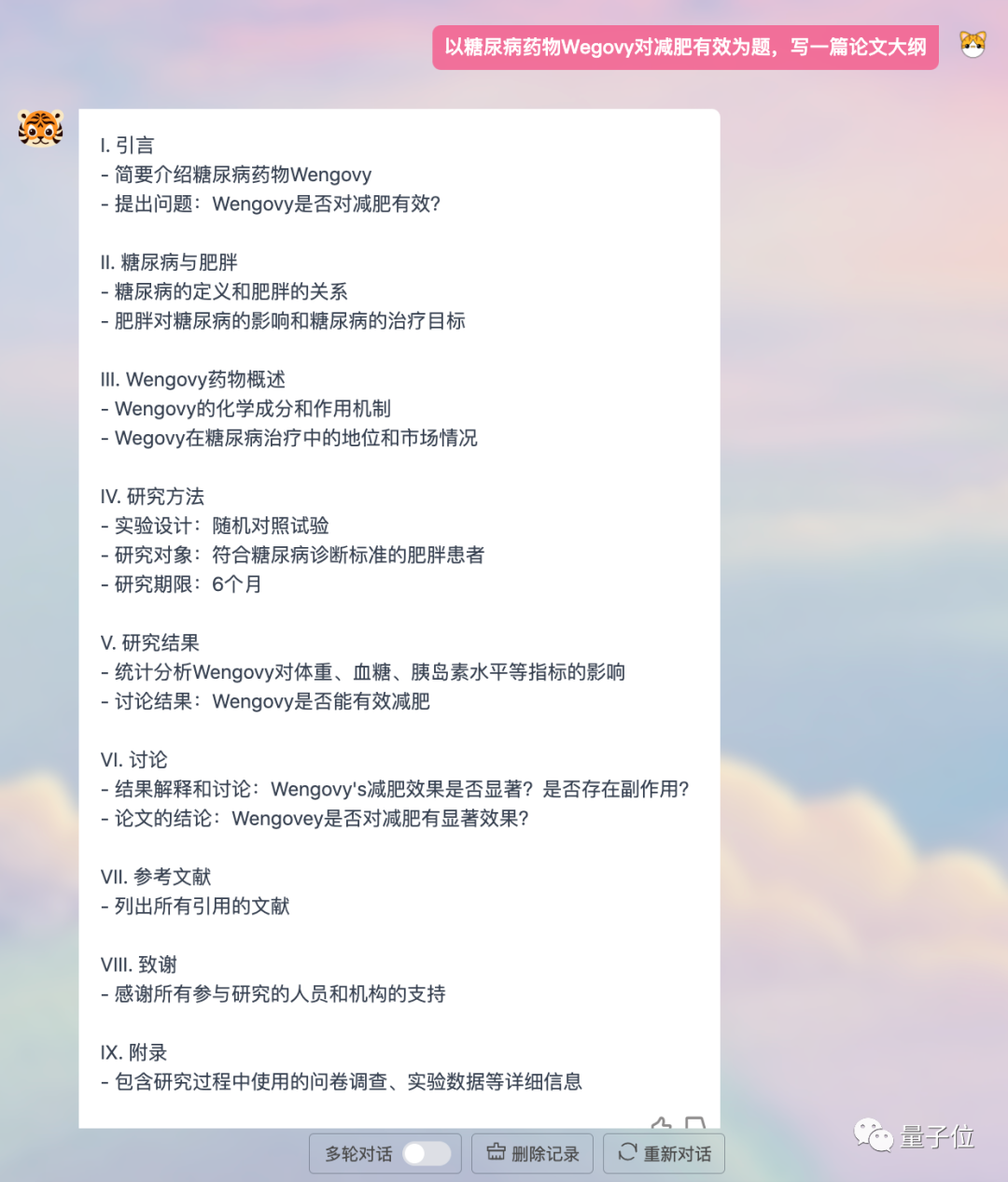 Keine Programmierkenntnisse stellt Fragen und unterstützt den englischen Dialog.
Keine Programmierkenntnisse stellt Fragen und unterstützt den englischen Dialog.
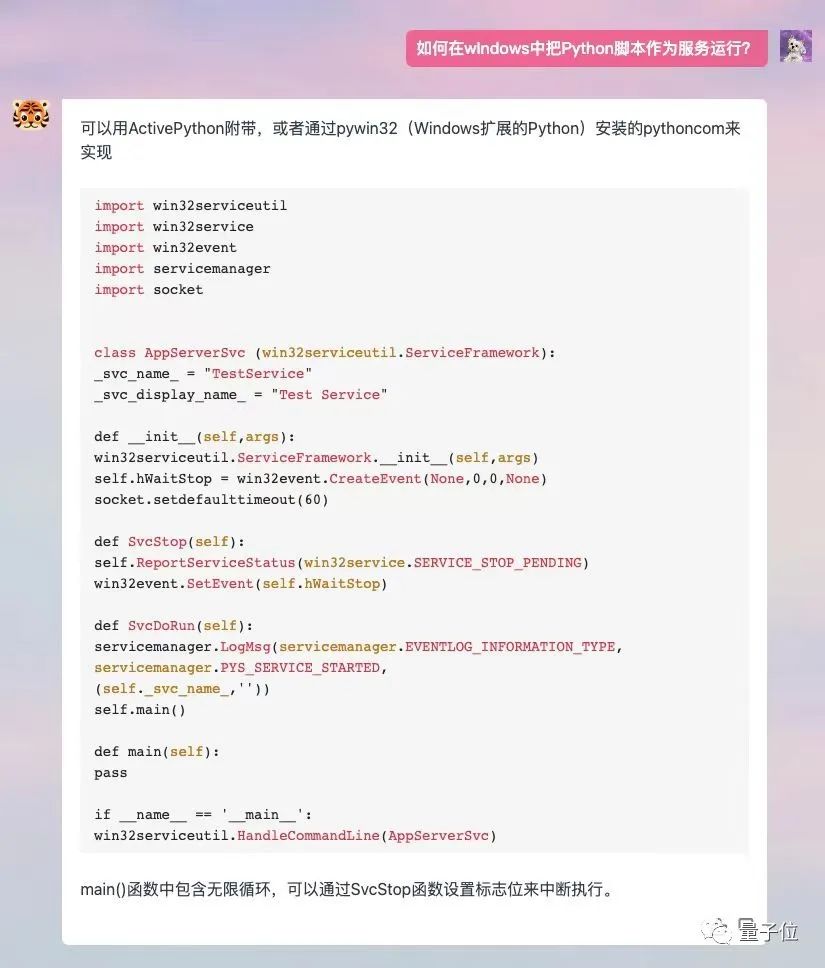

In dieser Version hat TigerBot zwei Größen eingeführt: 7 Milliarden Parameter (TigerBot-7B) und 180 Milliarden Parameter (TigerBot-180B).
Das Team wird alle bisher erzielten schrittweisen Ergebnisse – Modelle, Codes und Daten – als Open Source veröffentlichen.
Das Open-Source-Modell umfasst drei Versionen:
Unter diesen schneidet TigerBot-7B-base besser ab als vergleichbare OpenAI-Modelle , BLÜTE . TigerBot-180B-Research ist derzeit möglicherweise das größte Open-Source-Modell der Branche (Meta Open Source OPT hat eine Parametergröße von 175 Milliarden und BLOOM hat eine Größe von 176 Milliarden).
Der Open-Source-Code umfasst grundlegenden Trainings- und Inferenzcode, Quantisierungs- und Inferenzcode für das Dual-Card-Inferenz-180B-Modell.
Die Daten umfassen 100G-Daten vor dem Training und überwachte Feinabstimmung von 1G oder 1 Million Daten.
Laut der automatischen Auswertung des OpenAI InstructGPT-Papiers zum öffentlichen NLP-Datensatz hat TigerBot-7B 96 % der Gesamtleistung von OpenAI-Modellen gleicher Größe erreicht.
Und diese Version ist nur MVP (Minimum Viable Model).
Diese Ergebnisse sind hauptsächlich auf die weitere Optimierung der Modellarchitektur und des Algorithmus basierend auf GPT und BLOOM zurückzuführen. Dies ist auch die wichtigste Innovationsarbeit des TigerBot-Teams in den letzten Monaten, die die Lernfähigkeit und die Erstellung von Modellen ermöglicht und die Steuerbarkeit der Erzeugung wurden deutlich verbessert.
Wie setzt man es konkret um? Schauen Sie nach unten.
Die von TigerBot eingeführten Innovationen umfassen hauptsächlich die folgenden Aspekte:
schauen wir uns zunächst die Methode zur Überwachung der Befehlsvervollständigung an.
Es ermöglicht dem Modell, schnell zu verstehen, welche Arten von Fragen Menschen gestellt haben, und die Genauigkeit der Antworten zu verbessern, während nur eine kleine Anzahl von Parametern verwendet wird.
Grundsätzlich wird zur Steuerung stärker überwachtes Lernen eingesetzt.
Verwendung von Markup-Sprache (Markup-Sprache) und probabilistischen Methoden, um große Modelle in die Lage zu versetzen, Befehlskategorien genauer zu unterscheiden. Sind die Unterrichtsfragen beispielsweise eher sachlich oder divergierend? Ist es Code? Ist es ein Formular?
TigerBot deckt also 10 Hauptkategorien und 120 Kategorien kleiner Aufgaben ab. Lassen Sie das Modell dann basierend auf Ihrer Beurteilung in die entsprechende Richtung optimieren. Der direkte Vorteil von
besteht darin, dass die Anzahl der aufzurufenden Parameter geringer ist und das Modell eine bessere Anpassungsfähigkeit an neue Daten oder Aufgaben aufweist, d. h. die Lernfähigkeit wird verbessert.
Unter den gleichen Trainingsbedingungen von 500.000 Daten ist die Konvergenzgeschwindigkeit von TigerBot fünfmal schneller als die von Alpaca, die von Stanford eingeführt wurde, und die Auswertung öffentlicher Datensätze zeigt, dass die Leistung um 17 % verbessert wird.
Zweitens ist es auch sehr wichtig, wie das Modell die Kreativität und die sachliche Steuerbarkeit der generierten Inhalte besser in Einklang bringen kann.
TigerBot übernimmt einerseits die Ensemble-Methode, bei der mehrere Modelle kombiniert werden, um Kreativität und sachliche Kontrollierbarkeit zu berücksichtigen.
Sie können sogar den Kompromiss des Modells zwischen den beiden entsprechend den Benutzeranforderungen anpassen. Andererseits übernimmt es auch die klassische Methode derProbabilistischen Modellierung (Probabilistische Modellierung) im Bereich der KI.
Es ermöglicht dem Modell, während des Generierungsprozesses von Inhalten zwei Wahrscheinlichkeiten basierend auf dem zuletzt generierten Token anzugeben. Eine Wahrscheinlichkeit bestimmt, ob der Inhalt weiterhin abweichen soll, und eine Wahrscheinlichkeit gibt den Grad der Abweichung des generierten Inhalts vom tatsächlichen Inhalt an. Durch die Kombination der Werte der beiden Wahrscheinlichkeiten wird das Modell einen Kompromiss zwischen Kreativität und Kontrollierbarkeit eingehen. Die beiden Wahrscheinlichkeiten in TigerBot werden mit speziellen Daten trainiert. Wenn man bedenkt, dass es beim Generieren des nächsten Tokens durch das Modell oft unmöglich ist, den vollständigen Text zu sehen, wird TigerBot auch nach dem Schreiben der Antwort ein weiteres Urteil fällen. Wenn sich herausstellt, dass die Antwort letztendlich ungenau ist, muss das Modell dies tun umgeschrieben werden. Wir haben während der Erfahrung auch festgestellt, dass die von TigerBot generierten Antworten nicht im wörtlichen Ausgabemodus wie ChatGPT vorliegen, sondern nach „Nachdenken“ vollständige Antworten liefern.
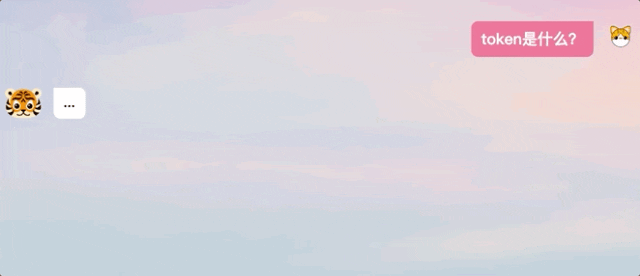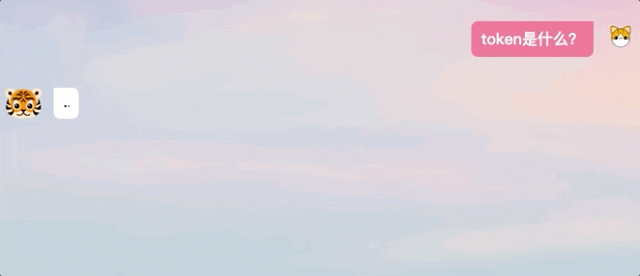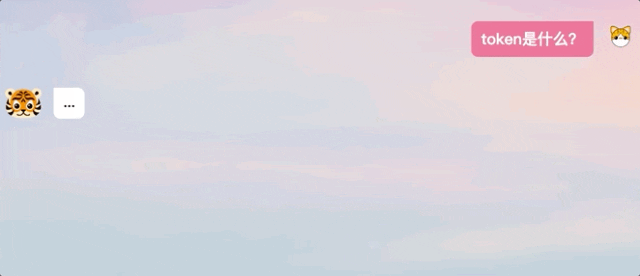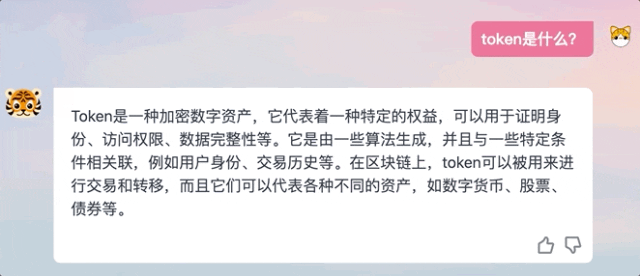
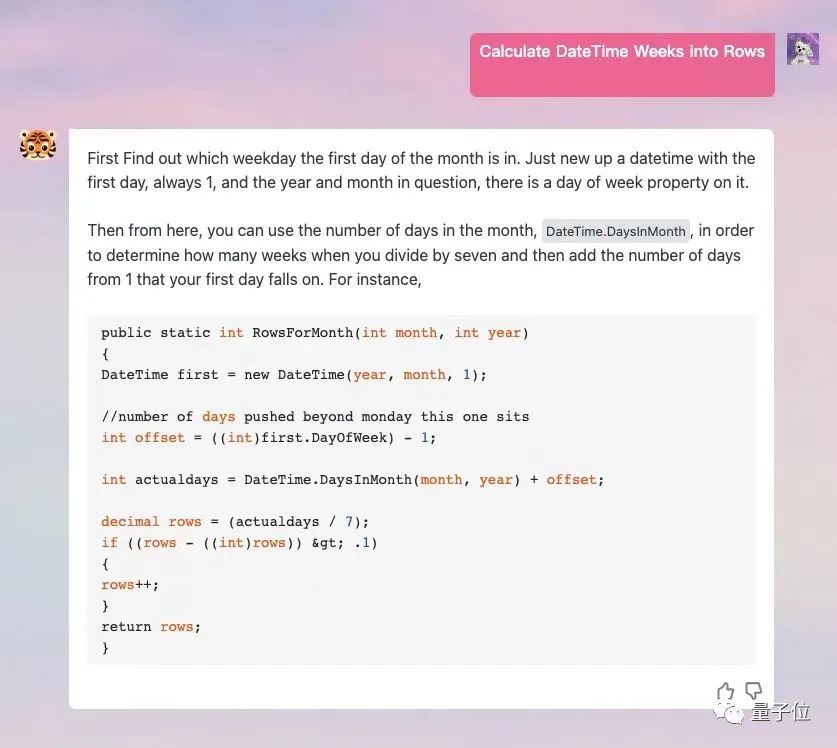
Und da die Inferenzgeschwindigkeit von TigerBot sehr hoch ist, kann es ein schnelles Umschreiben von Modellen unterstützen.
Hier sprechen wir über die Innovationen von TigerBot im Bereich Training und Argumentation.
Neben der Optimierung der zugrunde liegenden Architektur des Modells ist das TigerBot-Team der Ansicht, dass in der aktuellen Ära großer Modelle auch das technische Niveau sehr wichtig ist.
Einerseits liegt es an der Notwendigkeit, die betriebliche Effizienz zu berücksichtigen – da der Trend zu großen Modellen anhält, ist es sehr wichtig, wer das Modell schneller iterieren kann, andererseits natürlich an der Wirtschaftlichkeit der Rechenleistung muss auch berücksichtigt werden.
Daher haben sie im Hinblick auf paralleles Training mehrere Gedächtnis- und Kommunikationsprobleme in Mainstream-Frameworks wie Deep-Speed durchbrochen und mehrere Monate lang ununterbrochenes Training in einer Kilokalorien-Umgebung erreicht.
Dadurch können sie Hunderttausende an monatlichen Schulungskosten einsparen.
Schließlich hat TigerBot entsprechende Optimierungen vom Tokenizer bis zum Trainingsalgorithmus vorgenommen, um die Probleme starker Kontinuität und mehrfacher Mehrdeutigkeit im Chinesischen zu bewältigen.
Zusammenfassend lässt sich sagen, dass die von TigerBot erzielten technologischen Innovationen alle in den Bereichen angesiedelt sind, die im aktuellen Großmodellbereich die meiste Aufmerksamkeit erhalten.
Es geht nicht nur um die Optimierung der zugrunde liegenden Architektur, sondern berücksichtigt auch die Benutzerbedürfnisse, Gemeinkosten und andere Probleme auf der Implementierungsebene. Und der gesamte Innovationsprozess ist sehr schnell und kann in wenigen Monaten von einem kleinen Team von etwa 10 Leuten umgesetzt werden.
Dies stellt sehr hohe Anforderungen an die eigenen Entwicklungskapazitäten, technischen Erkenntnisse und Implementierungserfahrung des Teams.
Also, wer ist mit TigerBot plötzlich in die Öffentlichkeit gelangt?
Das Entwicklungsteam hinter TigerBot verbirgt sich tatsächlich in seinem Namen – Hubo Technology.
Es wurde im Jahr 2017 gegründet, was oft als die letzte Runde der KI-Explosion bezeichnet wird.
Hubo Technology positioniert sich als „ein Unternehmen, das von der Technologie der künstlichen Intelligenz angetrieben wird“ und konzentriert sich auf die Anwendung der NLP-Technologie. Seine Vision ist es, die nächste Generation intelligenter und einfacher Sucherlebnisse zu schaffen.
Auf dem spezifischen Implementierungspfad wählten sie einen der empfindlichsten Bereiche für Dateninformationen – Finanzen. Es verfügt über selbst entwickelte Technologien wie intelligente Suche, intelligente Empfehlung, maschinelles Leseverständnis, Zusammenfassung und Übersetzung in vertikalen Bereichen und hat das intelligente Finanzsuch- und Frage- und Antwortsystem „Hubo Search“ eingeführt.
Der Gründer und CEO des Unternehmens ist Chen Ye, ein erstklassiger KI-Wissenschaftler.

Er schloss sein Studium an der University of Wisconsin-Madison mit einem Ph.D. ab und war Gastprofessor an der University of California, Berkeley. Er praktiziert nun seit mehr als 20 Jahren.
Er bekleidete nacheinander wichtige Positionen wie Chefwissenschaftler und F&E-Direktor bei Microsoft, eBay und Yahoo und leitete die Entwicklung des Behavioral-Targeting-Systems von Yahoo, des Empfehlungssystems von eBay und des Marktmechanismus für Suchmaschinenwerbung von Microsoft.
Im Jahr 2014 kam Chen Ye zu Dianping. Nach der Fusion von Meituan-Dianping war er als Senior Vice President von Meituan-Dianping für die Werbeplattform der Gruppe verantwortlich und trug dazu bei, dass die jährlichen Werbeeinnahmen der Gruppe von 10 Millionen auf über 4 Milliarden stiegen.
In akademischer Hinsicht hat Chen Ye dreimal den Preis für den besten Beitrag auf Top-Konferenzen (KDD und SIGIR) gewonnen, 20 Artikel auf akademischen Konferenzen für künstliche Intelligenz wie SIGKKD, SIGIR und IEEE veröffentlicht und ist Inhaber von 10 Patenten.
Im Juli 2017 gründete Chen Ye offiziell Hubo Technology. Ein Jahr nach seiner Gründung erhielt Hubo schnell eine Finanzierung von über 100 Millionen Yuan. Das Unternehmen gibt derzeit bekannt, dass sich der Gesamtfinanzierungsbetrag auf 400 Millionen Yuan beläuft.

Selbst technische Experten wie Chen Ye, die seit vielen Jahren im Bereich KI arbeiten, beschreiben es als „beispiellosen Schock in ihrer Karriere“.
Abgesehen vom Schock ist es noch aufregender.
Chen Ye sagte, nachdem er ChatGPT gesehen hatte, musste er fast nicht mehr nachdenken oder eine Entscheidung treffen. Der Ruf aus seinem Herzen ließ ihn definitiv dem Trend folgen.
Also gründete TigerBot ab Januar offiziell das erste Entwicklungsteam von TigerBot.
Aber es ist anders, als ich es mir vorgestellt habe. Das ist ein Team mit einem sehr ausgeprägten Geek-Stil.
In ihren eigenen Worten würdigen sie das klassische „
Garage Startup“-Modell im Silicon Valley in den 1990er Jahren. Das Team bestand ursprünglich nur aus 5 Personen. Chen Ye war der Chefprogrammierer und Wissenschaftler, der für die Kerncodearbeit verantwortlich war. Obwohl sich die Mitgliederzahl später erhöhte, war sie nur auf 10 Personen begrenzt, grundsätzlich eine Person pro Beitrag.
Warum machst du das?
Chen Yes Antwort lautet:
Ich denke, die Schöpfung von 0 auf 1 ist eine sehr geekige Sache, und kein Geek-Team besteht aus mehr als 10 Leuten.
Neben rein technischen und wissenschaftlichen Themen sind kleine Teams schärfer.
Tatsächlich zeigte der Entwicklungsprozess von TigerBot Entschlossenheit und Sensibilität in jeder Hinsicht.
Chen Ye unterteilt diesen Zyklus in drei Phasen.
In der ersten Phase, kurz nachdem ChatGPT populär wurde, durchsuchte das Team schnell die gesamte relevante Literatur von OpenAI und anderen Institutionen der letzten fünf Jahre, um ein allgemeines Verständnis der Methoden und Mechanismen von ChatGPT zu erlangen.
Da der ChatGPT-Code selbst kein Open Source ist und es zu diesem Zeitpunkt relativ wenig damit verbundene Open-Source-Arbeit gab, Chen Ye machte sich an die Arbeit und schrieb selbst den TigerBot-Code und begann dann sofort mit der Durchführung von Experimenten.
Ihre Logik ist sehr einfach: Lassen Sie das Modell zunächst anhand kleiner Daten erfolgreich verifizieren und durchlaufen Sie dann eine systematische wissenschaftliche Überprüfung, dh es wird eine Reihe stabiler Codes erstellt.
Innerhalb eines Monats verifizierte das Team, dass das Modell 80 % der Wirkung des OpenAI-Modells im gleichen Maßstab auf einer Skala von 7 Milliarden erreichen kann.
In der zweiten Phase konnte das Team durch kontinuierliche Nutzung der Vorteile von Open-Source-Modellen und -Codes und spezieller Optimierung chinesischer Daten schnell eine echte und nutzbare Version des Modells entwickeln. Die früheste interne Beta-Version wurde im Februar veröffentlicht. .
Gleichzeitig stellten sie auch fest, dass das Modell ein Emergenzphänomen zeigte, nachdem die Anzahl der Parameter das Zehnmilliarden-Niveau erreicht hatte.
In der dritten Phase, also in den letzten ein bis zwei Monaten, hat das Team einige Ergebnisse und Durchbrüche in der Grundlagenforschung erzielt. Viele der oben vorgestellten Innovationen wurden in diesem Zeitraum fertiggestellt. Gleichzeitig wurde in dieser Phase eine größere Menge an Rechenleistung integriert, um eine schnellere Iterationsgeschwindigkeit zu erreichen. Innerhalb von 1–2 Wochen stieg die Leistungsfähigkeit von TigerBot-7B schnell von 80 % von InstructGPT. Chen Ye sagte, dass das Team während dieses Entwicklungszyklus stets einen äußerst effizienten Betrieb aufrechterhalten habe. TigerBot-7B durchlief in wenigen Monaten 3.000 Iterationen. Der Vorteil eines kleinen Teams besteht darin, dass es schnell reagieren kann. Es kann die Arbeit am Morgen bestätigen und den Code am Nachmittag fertig schreiben. Das Datenteam kann innerhalb weniger Stunden hochwertige Reinigungsarbeiten erledigen. Aber die schnelle Entwicklungsiteration ist nur eine der Manifestationen des Geek-Stils von TigerBot.Weil sie sich nur auf die Ergebnisse verlassen, die von 10 Leuten in ein paar Monaten produziert wurden, und sie der Industrie in Form eines vollständigen Satzes von APIs zugänglich machen.
Der Einsatz von Open Source in diesem Ausmaß ist im aktuellen Trend relativ selten, insbesondere im Bereich der Kommerzialisierung. Schließlich ist der Aufbau technischer Barrieren im harten Wettbewerb ein Problem, mit dem sich gewerbliche Unternehmen auseinandersetzen müssen.Warum wagt sich Hubo Technology an Open Source?
Chen Ye nannte zwei Gründe:Erstens: Als Techniker im Bereich KI ist er aus instinktivem Glauben an die Technik ein wenig leidenschaftlich und ein wenig sensationell.
Wir wollen mit einem Weltklasse-Großmodell zur Innovation Chinas beitragen. Wenn der Branche ein brauchbares allgemeines Modell mit einer soliden Grundlage zur Verfügung gestellt wird, können mehr Menschen schnell große Berufsmodelle ausbilden und die ökologische Schaffung von Industrieclustern realisieren.Zweitens: TigerBot wird weiterhin
die Hochgeschwindigkeits-Iteration aufrechterhalten, dass sie in dieser Rennsituation ihren Positionsvorteil behaupten können. Selbst wenn wir sehen, dass jemand ein Produkt mit besserer Leistung auf Basis von TigerBot entwickelt, ist das nicht eine gute Sache für die Branche? Chen Ye gab bekannt, dass Hubo Technology die Arbeit von TigerBot weiterhin rasch vorantreiben und die Daten weiter erweitern wird, um die Modellleistung zu verbessern.
„Der Trend zu großen Modellen ist wie ein Goldrausch“Sechs Monate nach der Veröffentlichung von ChatGPT, mit dem Aufkommen großer Modelle nacheinander und der schnellen Nachfolge von Giganten, verändert sich die Landschaft der KI-Branche schnell umgestaltet. Obwohl es im Moment noch relativ chaotisch ist, ist es grob gesagt grundsätzlich in drei Schichten unterteilt: Modellschicht, Mittelschicht und Anwendungsschicht. Die Modellebene bestimmt die zugrunde liegenden Fähigkeiten, was sehr wichtig ist. Sein Grad an Innovation, Stabilität und Offenheit bestimmt direkt den Reichtum der Anwendungsschicht. Die Entwicklung der Anwendungsschicht ist die äußere Manifestation der Entwicklung großer Modelltrends und ein wichtiger Einflussfaktor für die nächste Stufe des menschlichen sozialen Lebens in der AIGC-Vision. Zu Beginn des großen Modelltrends muss die Branche also darüber nachdenken, wie sie das zugrunde liegende Modellfundament konsolidieren kann. Nach Ansicht von Chen Ye haben Menschen erst 10–20 % des Potenzials großer Modelle entwickelt, und auf grundlegender Ebene gibt es noch viel Raum für Innovation und Verbesserung.Genau wie der Goldrausch im Westen, wo ursprünglich die Goldmine gefunden wurde.
Die heimische KI-Innovation schreitet mit hoher Geschwindigkeit voran. Ich glaube, dass wir in Zukunft mehr Teams mit Ideen und Fähigkeiten sehen werden, die neue Erkenntnisse einbringen und neue Veränderungen in den Bereich der großen Modelle bringen. Und das ist vielleicht der faszinierendste Teil der rasanten Entwicklung des Trends. Wohlfahrtsmoment: Wenn Sie die Kinderschuhe von TigerBot erleben möchten, können Sie die Website über den untenstehenden Link aufrufen oder auf „Originaltext lesen“ klicken, auf „Für interne Tests beantragen“ klicken und „qubit“ in den Organisationscode schreiben um die internen Tests zu bestehen~Offizielle Website-Adresse: https://www.tigerbot.com/chatAngesichts solcher Trends und Branchenentwicklungsanforderungen hält Hubo Technology als Vertreter der Innovation im heimischen Bereich das Banner von Open Source hoch, hat schnell begonnen, mit der weltweit modernsten Technologie Schritt zu halten, und hat es tatsächlich geschafft ein Unterschied zum Branchenatem.
GitHub Open-Source-Adresse: https://github.com/TigerResearch/TigerBot
Das obige ist der detaillierte Inhalt vonDer Effekt erreicht 96 % des OpenAI-Modells im gleichen Maßstab und ist bei Veröffentlichung Open Source! Das heimische Team veröffentlicht ein neues großes Modell und der CEO macht sich daran, Code zu schreiben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



