


Ich hätte nicht erwartet, dass ChatGPT bis heute noch dumme Fehler machen würde?
Meister Andrew Ng hat in der letzten Klasse darauf hingewiesen:
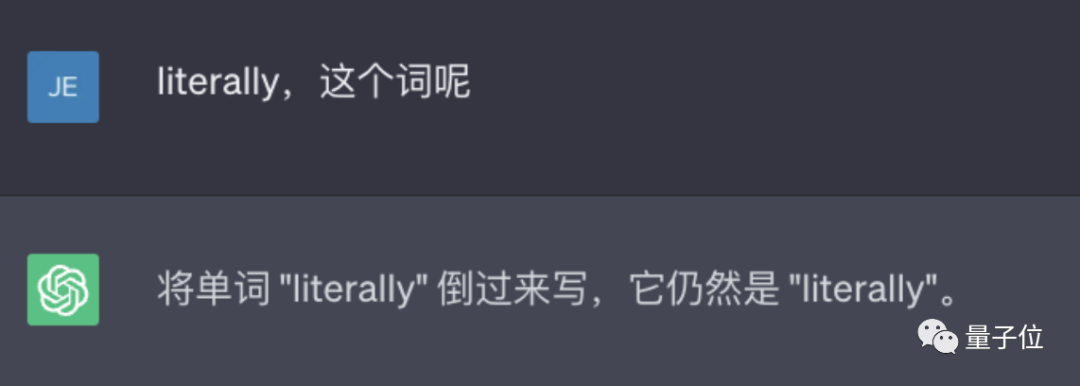
ChatGPT kehrt Wörter nicht um!
Wenn Sie beispielsweise das Wort „Lollipop“ umkehren, lautet die Ausgabe „pilollol“, was völlig verwirrend ist.

Oh, das ist tatsächlich ein bisschen schockierend.
So sehr, dass, nachdem ein Internetnutzer den auf Reddit geposteten Kurs angehört hatte, dieser sofort eine große Anzahl von Zuschauern anzog und der Beitrag schnell 6.000 Aufrufe erreichte.
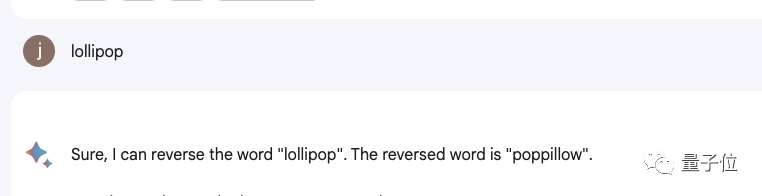
Und das ist kein zufälliger Fehler. Netizens haben festgestellt, dass ChatGPT diese Aufgabe tatsächlich nicht abschließen kann, und auch unsere persönlichen Testergebnisse sind dieselben.

Auch viele Produkte, darunter Bard, Bing, Wen Xinyiyan usw., funktionieren nicht.

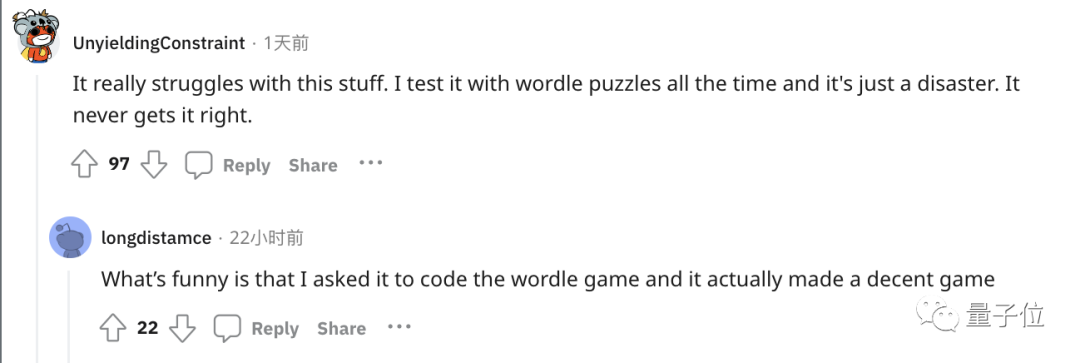
Zum Beispiel war das Spielen des beliebten Wortspiels Wordle eine Katastrophe und hat nie alles richtig gemacht.
Der Schlüssel liegt im Token
Es kann ein ganzes Wort oder ein Fragment eines Wortes sein. Große Modelle kennen die statistischen Beziehungen zwischen diesen Token und können geschickt den nächsten Token generieren.
Wenn es also um die kleine Aufgabe der Wortumkehr geht, könnte es sein, dass man einfach jedes Plättchen umdreht und nicht den Buchstaben.


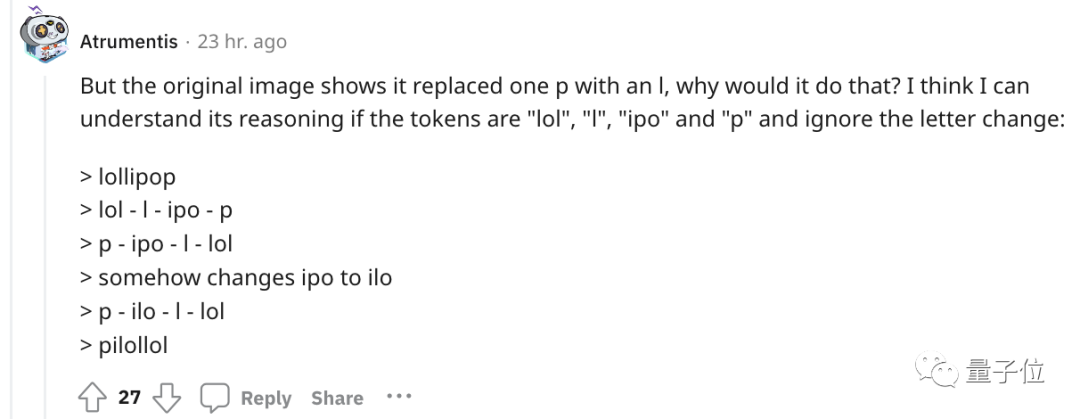
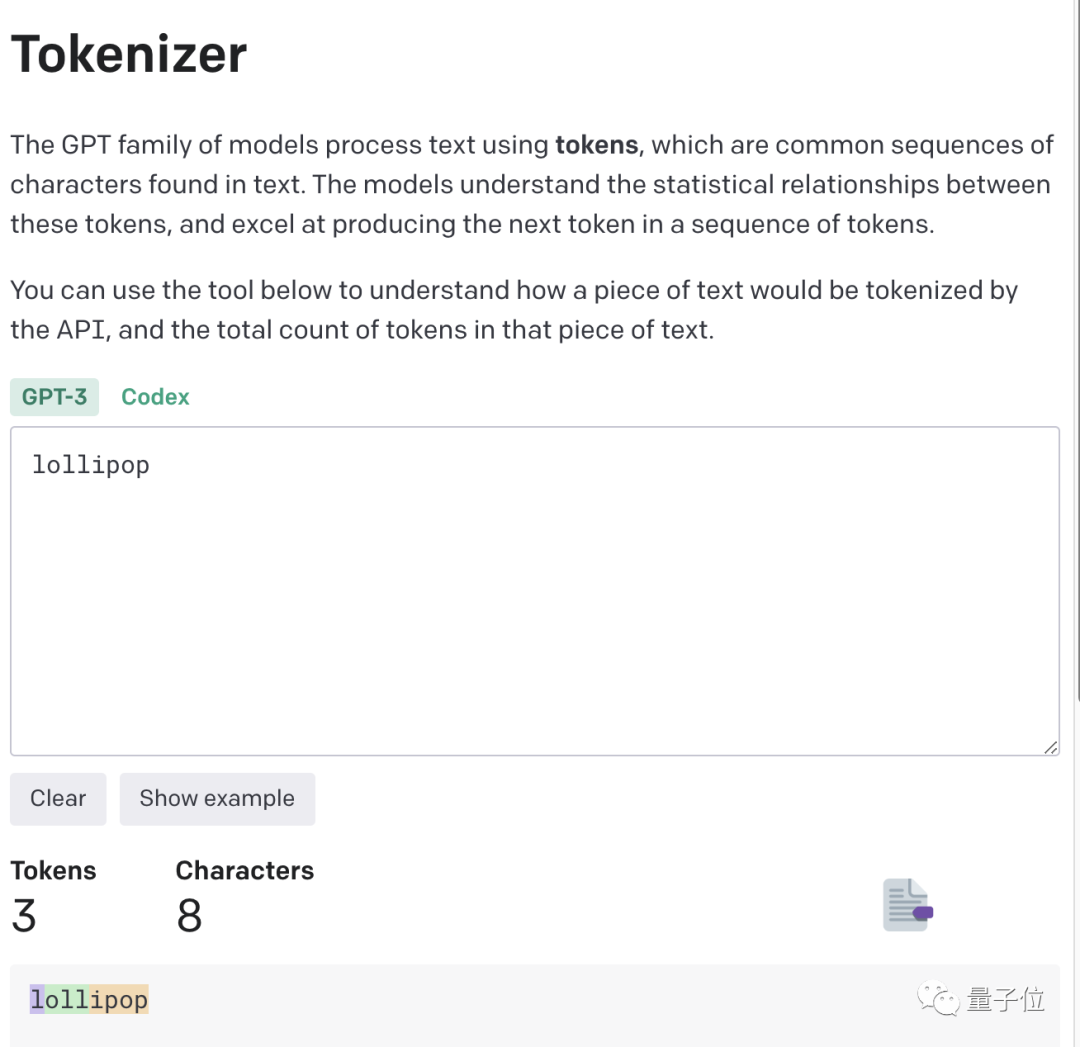
Aufgrund der Erfahrung wurden einige ungeschriebene Regeln geboren.
1 Token≈4 englische Zeichen≈dreiviertel eines Wortes;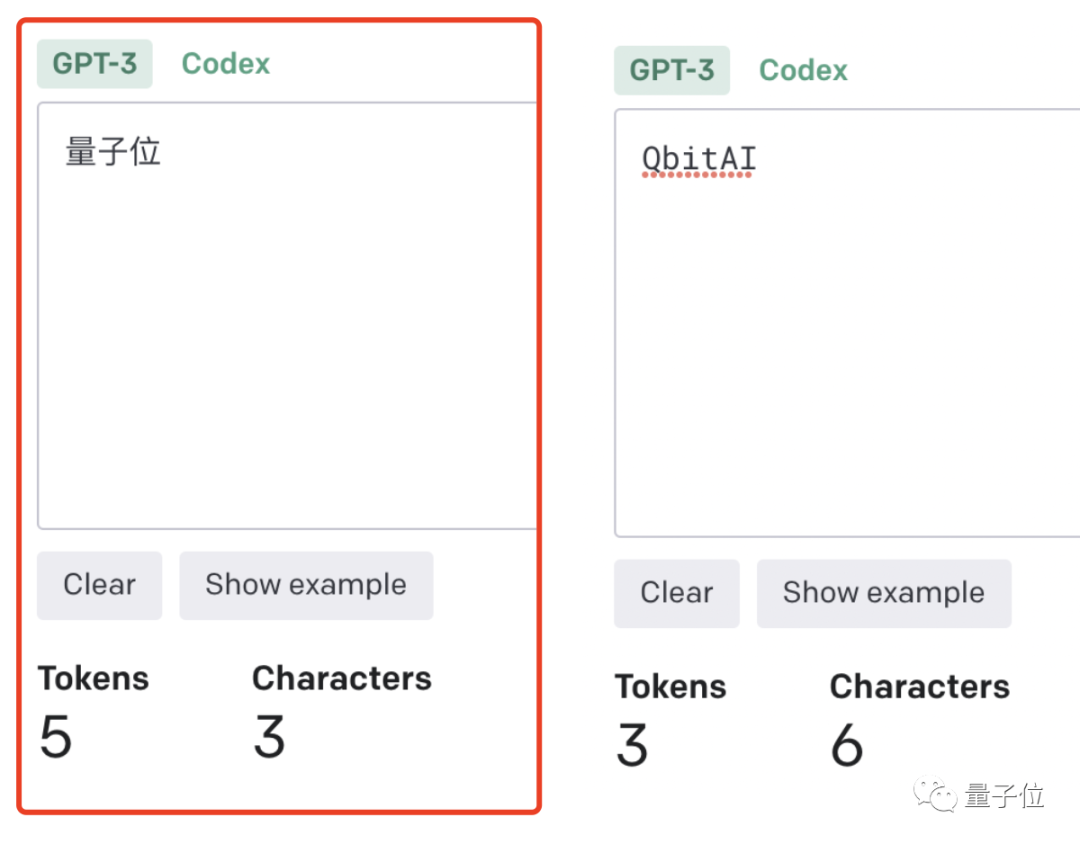
Je höher das Verhältnis von Token zu Zeichen (Token zu Wort), desto höher sind die Verarbeitungskosten. Daher ist die Verarbeitung von chinesischen Tokenisierungen teurer als die von englischen.
Sie können es so verstehen: Token ist eine Möglichkeit für große Modelle, die reale Welt der Menschen zu verstehen. Es ist sehr einfach und reduziert den Speicher- und Zeitaufwand erheblich.
Aber es gibt ein Problem mit der Tokenisierung von Wörtern, was es für das Modell schwierig macht, sinnvolle Eingabedarstellungen zu lernen. Die intuitivste Darstellung besteht darin, dass es die Bedeutung der Wörter nicht verstehen kann.
Transformers wurden damals entsprechend optimiert. Beispielsweise wurde ein komplexes und ungewöhnliches Wort in einen bedeutungsvollen Token und einen unabhängigen Token unterteilt.
So wie „nervigly“ in zwei Teile unterteilt ist: „nervig“ und „ly“, behält ersteres seine eigene Bedeutung, während letzteres häufiger vorkommt.
Dies hat heute auch zu den erstaunlichen Effekten von ChatGPT und anderen großen Modellprodukten geführt, die die menschliche Sprache sehr gut verstehen können.
Für die Unfähigkeit, eine so kleine Aufgabe wie die Wortumkehr zu bewältigen, gibt es natürlich eine Lösung.
Der einfachste und direkteste Weg besteht darin, die Wörter zuerst selbst zu trennen~

Oder Sie können ChatGPT dies Schritt für Schritt erledigen lassen und jeden Buchstaben zuerst tokenisieren.

Oder lassen Sie es ein Programm schreiben, um Buchstaben umzukehren, und dann wird das Ergebnis des Programms korrekt sein. (Hundekopf)

GPT-4 kann jedoch auch verwendet werden, und bei tatsächlichen Tests gibt es kein solches Problem.

Kurz gesagt, Token sind der Grundstein für das Verständnis natürlicher Sprache durch KI.
Als Brücke für die KI zum Verständnis der menschlichen natürlichen Sprache wird die Bedeutung von Token immer deutlicher.
Es ist zu einem entscheidenden Faktor für die Leistung von KI-Modellen und den Abrechnungsstandard für große Modelle geworden.
Wie oben erwähnt, können Token dem Modell die Erfassung feinkörnigerer semantischer Informationen wie Wortbedeutung, Wortreihenfolge, grammatikalische Struktur usw. erleichtern. Bei Sequenzmodellierungsaufgaben (z. B. Sprachmodellierung, maschinelle Übersetzung, Textgenerierung usw.) sind Position und Reihenfolge für die Modellbildung sehr wichtig.
Nur wenn das Modell die Position und den Kontext jedes Tokens in der Sequenz genau versteht, kann es den Inhalt besser vorhersagen und eine vernünftige Ausgabe liefern.
Daher haben Qualität und Quantität der Token einen direkten Einfluss auf den Modelleffekt.
Ab diesem Jahr, wenn immer mehr große Modelle veröffentlicht werden, wird der Schwerpunkt auf der Anzahl der Token liegen. In den Details der Veröffentlichung von Google PaLM 2 wurde beispielsweise erwähnt, dass 3,6 Billionen Token für das Training verwendet wurden.
Und viele große Namen der Branche haben auch gesagt, dass Token wirklich entscheidend sind!
Andrej Karpathy, ein KI-Wissenschaftler, der dieses Jahr von Tesla zu OpenAI wechselte, sagte in seiner Rede:
Mehr Token können das Modell besser denken lassen.

Und er betonte, dass die Leistung des Modells nicht nur durch die Parametergröße bestimmt wird.
Zum Beispiel ist die Parametergröße von LLaMA viel kleiner als die von GPT-3 (65B vs. 175B), aber da mehr Token für das Training verwendet werden (1,4T vs. 300B), ist LLaMA leistungsfähiger.
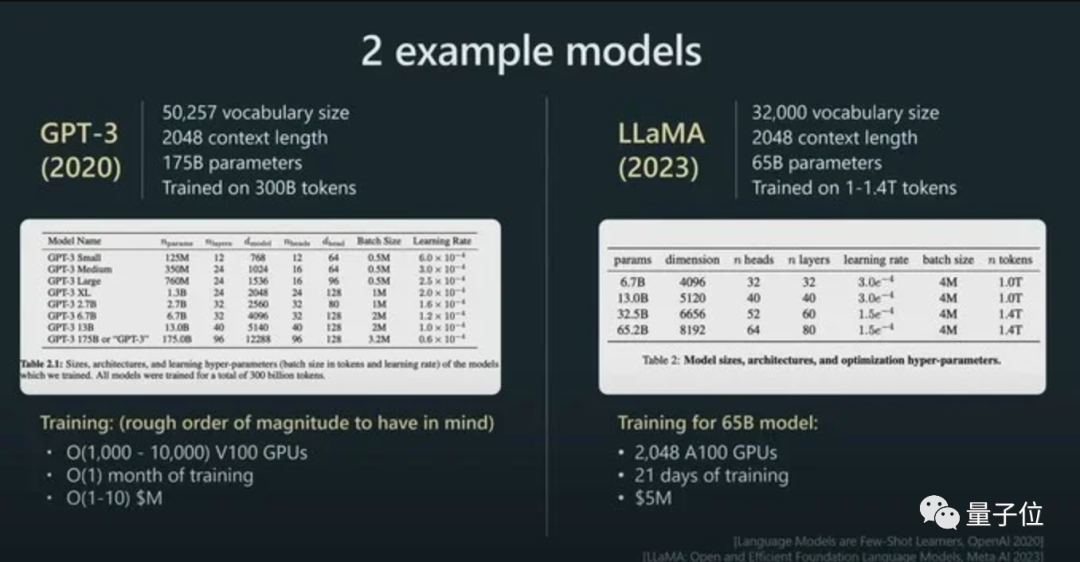
Und mit seinem direkten Einfluss auf die Modellleistung ist Token auch der Abrechnungsstandard für KI-Modelle.
Nehmen Sie den Preisstandard von OpenAI. Sie berechnen in Einheiten von 1K-Tokens. Verschiedene Modelle und verschiedene Arten von Tokens haben unterschiedliche Preise.
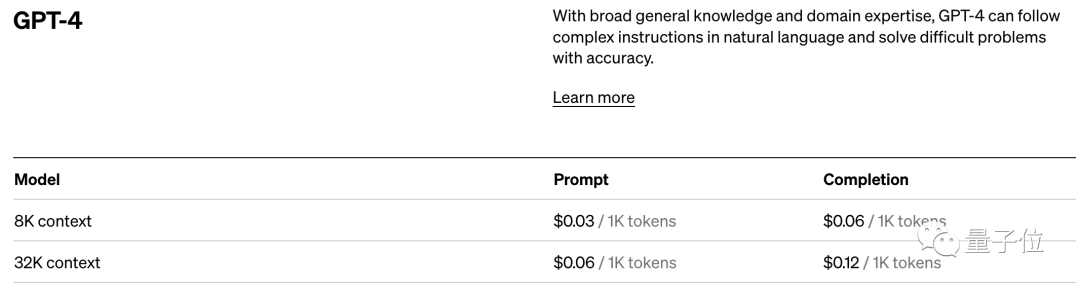
Kurz gesagt: Sobald Sie den Bereich der großen KI-Modelle betreten, werden Sie feststellen, dass Token ein unvermeidlicher Wissenspunkt sind.
Nun, es wurde sogar Token-Literatur abgeleitet...
Es ist jedoch erwähnenswert, dass die Übersetzung von Token in der chinesischen Welt noch nicht vollständig geklärt ist.
Die wörtliche Übersetzung von „Token“ ist immer etwas seltsam.
GPT-4 meint, es sei besser, es „Wortelement“ oder „Tag“ zu nennen, was denken Sie?

Referenzlink:
[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/
[2]https://help.openai.com/en/ Articles/4936856-what-are-tokens-and-how-to-count-them
[3]https://openai.com/pricing
Das obige ist der detaillierte Inhalt vonDer ChatGPT-Kurs von Andrew Ng ging viral: Die KI verzichtete darauf, Wörter rückwärts zu schreiben, verstand aber die ganze Welt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



