


Lassen Sie uns über die häufig verwendeten Bereitstellungslösungen in MySQL sprechen.
MySQL-Replikation ist eine offiziell bereitgestellte Master-Slave-Synchronisationslösung, die zum Synchronisieren einer MySQL-Instanz mit einer anderen Instanz verwendet wird. Die Replikation hat wichtige Garantien zur Gewährleistung der Datensicherheit gegeben und ist derzeit die am weitesten verbreitete MySQL-Disaster-Recovery-Lösung. Bei der Replikation werden zwei oder mehr Instanzen verwendet, um einen MySQL-Master-Slave-Replikationscluster aufzubauen, der Einzelpunkt-Schreib- und Mehrpunkt-Lesedienste bereitstellt und eine skalierbare-Skalierung des Lesens ermöglicht. MySQL Replication 是官方提供的主从同步方案,用于将一个 MySQL 的实例同步到另一个实例中。Replication 为保证数据安全做了重要的保证,是目前运用最广的 MySQL 容灾方案。Replication 用两个或以上的实例搭建了 MySQL 主从复制集群,提供单点写入,多点读取的服务,实现了读的 scale out。
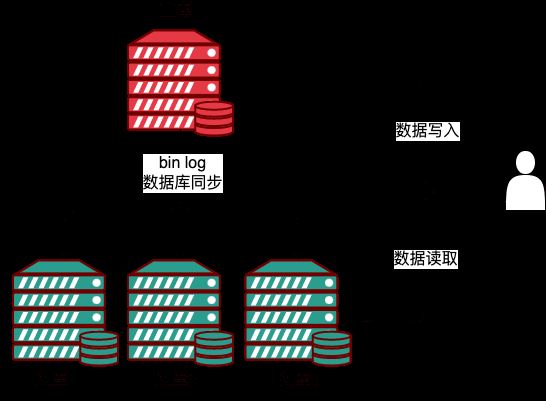
上面的栗子,一个主库(M),三个从库(S),通过 replication,Master 生成 event 的 binlog,然后发给 slave,Slave 将 event 写入 relaylog,然后将其提交到自身数据库中,实现主从数据同步。
对于数据库之上的业务层来说,基于 MySQL 的主从复制集群,单点写入 Master ,在 event 同步到 Slave 后,读逻辑可以从任何一个 Slave 读取数据,以读写分离的方式,大大降低 Master 的运行负载,同时提升了 Slave 的资源利用。
优点:
1、通过读写分离实现横向扩展的能力,写入和更新操作在源服务器上进行,从服务器中进行数据的读取操作,通过增大从服务器的个数,能够极大的增强数据库的读取能力;
2、数据安全,因为副本可以暂停复制过程,所以可以在副本上运行备份服务而不会破坏相应的源数据;
3、方便进行数据分析,可以在写库中创建实时数据,数据的分析操作在从库中进行,不会影响到源数据库的性能;
实现原理
在主从复制中,从库利用主库上的 binlog 进行重播,实现主从同步,复制的过程中蛀主要使用到了 dump thread,I/O thread,sql thread 这三个线程。
IO thread: 在从库执行 start slave 语句时创建,负责连接主库,请求 binlog,接收 binlog 并写入 relay-log;
dump thread:用于主库同步 binlog 给从库,负责响应从 IO thread 的请求。主库会给每个从库的连接创建一个 dump thread,然后同步 binlog 给从库;
sql thread:读取 relay log 执行命令实现从库数据的更新。
来看下复制的流程:
1、主库收到更新命令,执行更新操作,生成 binlog;
2、从库在主从之间建立长连接;
3、主库 dump_thread 从本地读取 binlog 传送刚给从库;
4、从库从主库获取到 binlog 后存储到本地,成为 relay log(中继日志);
5、sql_thread 线程读取 relay log 解析、执行命令更新数据。
不过 MySQL Replication
Im obigen Beispiel gibt es eine Master-Bibliothek (M) und drei Slave-Bibliotheken (S). Durch Replikation generiert der Master das Binlog des Ereignisses und sendet es dann an den Slave. Der Slave schreibt das Ereignis in das Relaylog Anschließend wird es an seine eigene Datenbank übermittelt, um eine Master-Slave-Datensynchronisierung zu erreichen. Für die Geschäftsschicht über der Datenbank verfügt der auf MySQL basierende Master-Slave-Replikationscluster über einen einzigen Schreibpunkt zum Master. Nachdem das Ereignis mit dem Slave synchronisiert wurde, kann die Leselogik Daten von jedem Slave in einem Lesevorgang lesen -Schreibtrennung, wodurch die Betriebslast des Masters erheblich reduziert und die Ressourcennutzung des Slaves verbessert wird. Vorteile: 1. Die Möglichkeit, durch Lese- und Schreibtrennung horizontale Erweiterungen zu erreichen, erfolgt durch Erhöhen der Anzahl der Slave-Server kann die Lesefähigkeit der Datenbank erheblich verbessern 2 Bei der Datenanalyse können Sie Echtzeitdaten in der Schreibdatenbank erstellen, und der Datenanalysevorgang wird in der Slave-Datenbank ausgeführt, was keinen Einfluss auf die Leistung der Quelldatenbank hat. ImplementierungsprinzipBei der Master-Slave-Replikation; Die Slave-Datenbank verwendet das Binlog in der Master-Datenbank für die Wiedergabe. Um eine Master-Slave-Synchronisation zu erreichen, werden während des Kopiervorgangs hauptsächlich die drei Threads
Dump-Thread, E/A-Thread und SQL-Thread verwendet.
IO-Thread: Wird erstellt, wenn die Slave-Bibliothek die start-slave-Anweisung ausführt. Er ist für die Verbindung mit der Hauptbibliothek, das Anfordern von Binlog, den Empfang von Binlog und das Schreiben in das Relay verantwortlich. log;
dump thread: wird verwendet, um binlog von der Hauptbibliothek mit der Slave-Bibliothek zu synchronisieren, verantwortlich für die Beantwortung von Anfragen vom IO-Thread. Die Hauptbibliothek erstellt einen Dump-Thread für jede Slave-Bibliotheksverbindung und synchronisiert dann das Binlog mit der Slave-Bibliothek
SQL-Thread: Relay-Log code> Führen Sie den Befehl aus, um die Slave-Daten zu aktualisieren. <p></p>Sehen wir uns den Replikationsprozess an: <p></p>1 Die Hauptbibliothek empfängt den Aktualisierungsvorgang und generiert ein Binlog. <p></p> Die Slave-Bibliothek stellt eine lange Verbindung zwischen Master und Slave her <p>3. Die Hauptbibliothek dump_thread liest das Binlog lokal und sendet es an die Slave-Bibliothek. </p>
<p>4 Die Slave-Bibliothek ruft das Binlog von der Hauptbibliothek ab und speichert es lokal. </p>
<p>5. sql_thread-Thread-Lesung Holen Sie sich <code>relay log, um Befehle zum Aktualisieren von Daten zu analysieren und auszuführen.
Allerdings hat MySQL Replication einen gravierenden Nachteil, nämlich die Verzögerung bei der Master-Slave-Synchronisation.
Da die Daten zwischen Master und Slave synchronisiert werden, kommt es zu Verzögerungen bei der Master-Slave-Synchronisierung.
🎜Warum kommt es zur Master-Slave-Verzögerung? 🎜🎜1. Die Leistung der Slave-Datenbank ist schlechter als die der Hauptdatenbank. 🎜🎜Der Druck auf die Slave-Datenbank ist hoch Dadurch wird die Leistung der Slave-Datenbank beeinträchtigt und es kommt zu Verzögerungen zwischen Master und Slave. 🎜🎜3. Ausführung großer Transaktionen; 🎜🎜Wenn eine Transaktion stattfindet, muss die Master-Datenbank warten, bis die Transaktion abgeschlossen ist, bevor sie in das Binlog geschrieben werden kann Die Übertragung der Daten in die Slave-Datenbank dauert ebenfalls eine gewisse Zeit, was zu Datenverzögerungen auf dem Slave-Knoten führt. 🎜🎜4. Die Replikationskapazität der Slave-Bibliothek ist schlecht. 🎜🎜Wenn die Replikationskapazität der Slave-Bibliothek geringer ist als die der Master-Bibliothek, kann ein hoher Schreibdruck auf die Master-Bibliothek zu langen Datenverzögerungen in der Slave-Bibliothek führen. 🎜🎜Wie kann man es lösen? 🎜🎜1. Optimieren Sie die Geschäftslogik, um Parallelitätsszenarien bei großen Multithread-Transaktionen zu vermeiden 3. Stellen Sie sicher, dass die Hauptbibliothek mit der Slave-Bibliothek verbunden ist, um durch Netzwerkverzögerungen verursachte Verzögerungen zu vermeiden. 🎜🎜5 -sync halbsynchrone Replikation 🎜🎜MySQL hat drei Die drei Synchronisationsmodi sind: 🎜🎜1. Die Standardreplikation in MySQL ist asynchron. Die Hauptbibliothek gibt die Ergebnisse sofort an den Client zurück, nachdem sie die Transaktion ausgeführt hat Client, und es ist ihm egal, ob die Slave-Bibliothek bereits über Empfang und Verarbeitung verfügt. Das Problem besteht darin, dass, wenn die Protokolle der Master-Datenbank nicht rechtzeitig mit der Slave-Datenbank synchronisiert werden und die Master-Datenbank dann ausfällt, ein Failover durchgeführt wird und der Master aus der Slave-Datenbank ausgewählt wird möglicherweise unvollständig;2. Vollständig synchrone Replikation: Wenn die Hauptbibliothek eine Transaktion abschließt und wartet, bis alle Slave-Bibliotheken die Transaktion ebenfalls abgeschlossen haben, übermittelt die Hauptbibliothek die Transaktion und gibt die Daten an den Client zurück. Da Sie warten müssen, bis alle Slave-Datenbanken mit den Daten in der Master-Datenbank synchronisiert sind, bevor Sie die Daten zurückgeben, kann die Konsistenz der Master-Slave-Daten garantiert werden, die Leistung der Datenbank wird jedoch zwangsläufig beeinträchtigt
3 . Halbsynchrone Replikation: Es handelt sich um eine Art vollständig asynchrone Synchronisation. Die Hauptbibliothek muss darauf warten, dass mindestens eine Slave-Bibliothek die Datei Relay Log empfängt Die Bibliothek muss nicht darauf warten, dass alle Slave-Bibliotheken ACK an die Hauptbibliothek zurücksenden. Die Hauptbibliothek empfängt eine Bestätigung, die angibt, dass die Transaktion abgeschlossen ist, und gibt die Daten an den Client zurück. Relay Log 文件即可,主库不需要等待所有从库给主库返回 ACK。主库收到 ACK ,标识这个事务完成,返回数据给客户端。
MySQL 中默认的复制是异步的,所以主库和从库的同步会存在一定的延迟,更重要的是异步复制还可能引起数据的丢失。全同步复制的性能又太差了,所以从 MySQL 5.5 开始,MySQL 以插件的形式支持 semi-sync 半同步复制。
半同步复制潜在的问题
在传统的半同步复制中,主库写数据到 binlog,并且执行 commit 提交事务后,会一直等待一个从库的 ACK。从库会在写入 Relay Log 后,将数据落盘,然后回复给主库 ACK,主库收到这个 ACK 才能给客户端事务完成的确认。
这样会存在问题就是,主库已经将该事务的 commit 存储到了引擎层,应用已经可以看到数据的变化了,只是在等待从库的返回,如果此时主库宕机,可能从库还没有写入 Relay Log,就会发生主从库数据不一致。
为了解决这个问题,MySQL 5.7 引入了增强半同步复制。主库写入数据到 binlog 后,就开始等待从库的应答 ACK,直到至少一个从库写入 Relay Log 后,并将数据落盘,然后返回给主库 ACK,通知主库可以进行 commit 操作,然后主库再将事务提交到事务引擎,应用此时才能看到数据的变化。
不过看下来增强半同步复制,在同步给从库之后,因为自己的数据还没有提交,然后宕机了,主库中也是会存在数据的丢失,不过应该想到的是,这时候主库宕机了,是会重新在从库中选主的,这样新选出的主库数据是没有发生丢失的。
MySQL Group Replication 组复制,又称为 MGR。是 Oracle MySQL 于 2016 年 12 月发布 MySQL 5.7.17 推出的一个全新高可用和高扩展的解决方案。
引入复制组主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。
MGR 由若干个节点共同组成一个复制组,一个事务的提交,必须经过组内大多数节点 (N / 2 + 1) 决议并通过,才能得以提交。
当客户端发起一个更新事务时,该事务先在本地执行,执行完成之后就要发起对事务的提交操作。需要在实际提交之前,将所产生的复制写集广播给其他成员进行复制。组中的成员只有在接收到事务广播时,才能全部接收或全部不接收,因为事务是原子性广播。如果组中的所有成员收到了该广播消息(事务),那么他们会按照之前发送事务的相同顺序收到该广播消息。因此,所有的组成员都会按照相同的顺序接收事务的写集,并为该事务建立全局顺序。因此,所有的组成员都会按照相同的顺序接收事务的写集,并为该事务建立全局顺序。
在不同组成员并发执行的事务可能存在冲突。冲突是通过检查和比较两个不同并发事务的 write set
MySQL 5.5 die halbsynchrone halbsynchrone Replikation in Form eines Plug-Ins. Potenzielle Probleme bei der halbsynchronen Replikation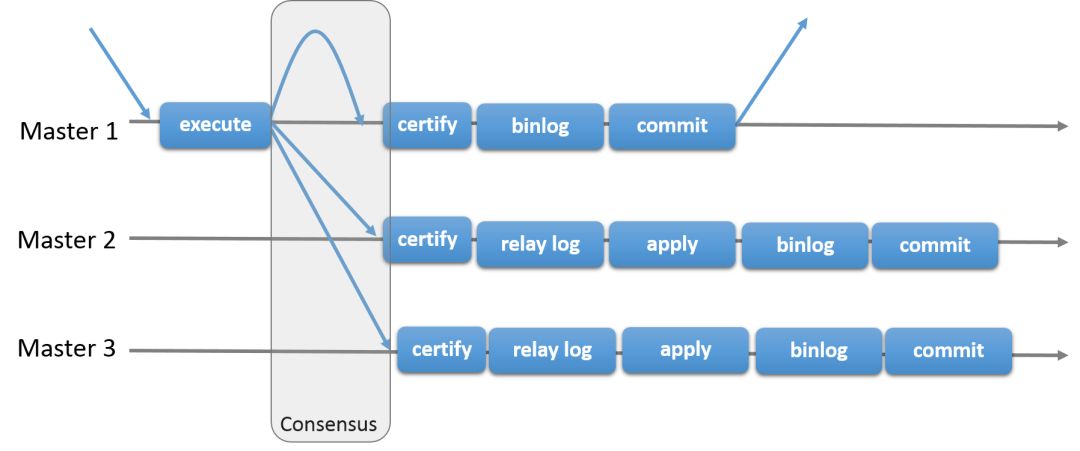 Bei der herkömmlichen halbsynchronen Replikation schreibt die Master-Bibliothek Daten in Binlog und führt einen Commit aus, um die Transaktion festzuschreiben. Sie wartet immer auf eine Bestätigung von der Slave-Bibliothek. Die Slave-Bibliothek schreibt die Daten auf die Festplatte, nachdem sie
Bei der herkömmlichen halbsynchronen Replikation schreibt die Master-Bibliothek Daten in Binlog und führt einen Commit aus, um die Transaktion festzuschreiben. Sie wartet immer auf eine Bestätigung von der Slave-Bibliothek. Die Slave-Bibliothek schreibt die Daten auf die Festplatte, nachdem sie Relay Log geschrieben hat, und antwortet dann der Master-Bibliothek mit einer Bestätigung. Erst wenn die Master-Bibliothek diese Bestätigung erhält, kann sie den Abschluss der Transaktion bestätigen der Kunde.
Das Problem dabei ist, dass die Hauptbibliothek den Commit der Transaktion bereits in der Engine-Ebene gespeichert hat. Die Anwendung kann die Datenänderungen bereits sehen und wartet nur auf die Rückgabe von der Slave-Bibliothek Zu diesem Zeitpunkt kann es sein, dass die Slave-Bibliothek vor dem Schreiben des Relay-Protokolls eine Dateninkonsistenz zwischen der Master- und der Slave-Datenbank aufweist.
Um dieses Problem zu lösen, führt MySQL 5.7 eine verbesserte halbsynchrone Replikation ein. Nachdem die Master-Bibliothek Daten in das Binlog geschrieben hat, beginnt sie auf die Antwort ACK von der Slave-Bibliothek zu warten, bis mindestens eine Slave-Bibliothek das Relay Log schreibt, die Daten auf die Festplatte schreibt und dann zurückkehrt Senden Sie die Bestätigung an die Hauptbibliothek, um sie zu benachrichtigen. Die Hauptbibliothek kann einen Festschreibungsvorgang ausführen. Anschließend sendet die Hauptbibliothek die Transaktion an die Transaktions-Engine. Erst dann kann die Anwendung die Datenänderungen sehen.
MySQL-Gruppenreplikation Gruppenreplikation, auch bekannt als MGR. Es handelt sich um eine neue hochverfügbare und hochskalierbare Lösung, die von Oracle MySQL mit MySQL 5.7.17 im Dezember 2016 eingeführt wurde. 🎜🎜Die Einführung von Replikationsgruppen dient hauptsächlich dazu, das Problem der Dateninkonsistenz zu lösen, die bei der herkömmlichen asynchronen Replikation und halbsynchronen Replikation auftreten kann. 🎜🎜MGR besteht aus mehreren Knoten, die zusammen eine Replikationsgruppe bilden. Die Übermittlung einer Transaktion muss von der Mehrheit der Knoten in der Gruppe (N / 2 + 1) gelöst und genehmigt werden, bevor sie durchgeführt werden kann eingereicht. 🎜🎜Wenn der Client eine Aktualisierungstransaktion initiiert, wird die Transaktion zunächst lokal ausgeführt und nach Abschluss der Ausführung wird der Transaktions-Commit-Vorgang initiiert. Der resultierende replizierte Schreibsatz muss vor dem eigentlichen Commit zur Replikation an andere Mitglieder gesendet werden. Mitglieder der Gruppe können nur dann alle oder keine Transaktionen empfangen, wenn sie den Transaktions-Broadcast empfangen, da es sich bei der Transaktion um einen atomaren Broadcast handelt. Wenn alle Mitglieder der Gruppe die Broadcast-Nachricht (Transaktion) erhalten, erhalten sie diese in der gleichen Reihenfolge, in der die zuvor gesendeten Transaktionen gesendet wurden. Daher erhalten alle Gruppenmitglieder die Schreibsätze der Transaktion in derselben Reihenfolge, wodurch eine globale Reihenfolge für die Transaktion festgelegt wird. Daher erhalten alle Gruppenmitglieder die Schreibsätze der Transaktion in derselben Reihenfolge, wodurch eine globale Reihenfolge für die Transaktion festgelegt wird. 🎜🎜Transaktionen, die gleichzeitig von Mitgliedern verschiedener Gruppen ausgeführt werden, können zu Konflikten führen. Konflikte werden überprüft, indem der Schreibsatz zweier verschiedener gleichzeitiger Transaktionen untersucht und verglichen wird, ein Prozess, der als Authentifizierung bezeichnet wird. Während der Authentifizierung wird die Konflikterkennung auf Zeilenebene durchgeführt: Wenn zwei gleichzeitige Transaktionen, die auf verschiedenen Gruppenmitgliedern ausgeführt werden, dieselbe Datenzeile aktualisieren, liegt ein Konflikt vor. Gemäß dem Konfliktauthentifizierungserkennungsmechanismus wird die erste übermittelte Transaktion normal ausgeführt, die zweite übermittelte Transaktion wird auf das ursprüngliche Gruppenmitglied zurückgesetzt, bei dem die Transaktion initiiert wurde, und andere Mitglieder in der Gruppe löschen die Transaktion. Wenn zwei Transaktionen häufig in Konflikt geraten, ist es am besten, die beiden Transaktionen im selben Gruppenmitglied auszuführen, damit sie unter der Koordination des lokalen Sperrmanagers erfolgreich festgeschrieben werden können, und nicht, weil sie sich in zwei Transaktionen befinden wird aufgrund widersprüchlicher Authentifizierung zwischen verschiedenen Gruppenmitgliedern häufig zurückgesetzt. 🎜🎜Schließlich erhalten alle Gruppenmitglieder die gleichen Transaktionen in der gleichen Reihenfolge. Um eine starke Datenkonsistenz innerhalb der Gruppe sicherzustellen, müssen die Mitglieder der Gruppe dieselben Änderungsvorgänge in derselben Reihenfolge ausführen. 🎜🎜🎜🎜🎜hat die folgenden Eigenschaften:🎜🎜1. Split-Brain-Phänomen vermeiden: Bei MGR tritt kein Split-Brain-Phänomen auf;🎜2. Datenkonsistenzgarantie: MGR verfügt über sehr gute Redundanzfähigkeiten und kann sicherstellen, dass Binlog Event auf mindestens mehr als die Hälfte der Mitglieder kopiert wird Gleichzeitig wird es nicht dazu führen, dass Daten verloren gehen. MGR stellt außerdem sicher, dass lokale Mitglieder das Binlog Event der Transaktion nicht in die Binlog-Datei schreiben, solange Binlog Event nicht an mehr als die Hälfte der Mitglieder übertragen wird Übertragen Sie die Transaktion und stellen Sie so sicher, dass keine Daten auf dem Server vorhanden sind, die nicht auf den Online-Mitgliedern der Gruppe vorhanden sind. Daher ist nach dem Neustart des heruntergefahrenen Servers keine spezielle Verarbeitung mehr erforderlich, um der Gruppe beizutreten. Binlog Event 至少被复制到超过一半的成员上,只要同时宕机的成员不超过半数便不会导致数据丢失。MGR还保证只要 Binlog Event 没有被传输到半数以上的成员,本地成员不会将事务的 Binlog Event 写入 Binlog 文件和提交事务,从而保证宕机的服务器上不会有组内在线成员上不存在的数据。因此,宕机的服务器重启后,不再需要特殊的处理就可以加入组;
3、多节点写入支持:多写模式下支持集群中的所有节点都可以写入。
组复制的应用场景
1、弹性复制:需要非常灵活的复制基础设施的环境,其中MySQL Server的数量必须动态增加或减少,并且在增加或减少Server的过程中,对业务的副作用尽可能少。例如,云数据库服务;
2、高可用分片:分片是实现写扩展的一种流行方法。基于 组复制 实现的高可用分片,其中每个分片都会映射到一个复制组上(逻辑上需要一一对应,但在物理上,一个复制组可以承载多个分片);
3、替代主从复制:在某些情况下,使用一个主库会造成单点争用。在一些场景下,将数据同时写入组中多个成员,能给应用程序带来更好的可扩展性
4、自治系统:可以利用组复制内置的自动故障转移、数据在不同组成员之间的原子广播和最终数据一致性的特性来实现一些运维自动化。
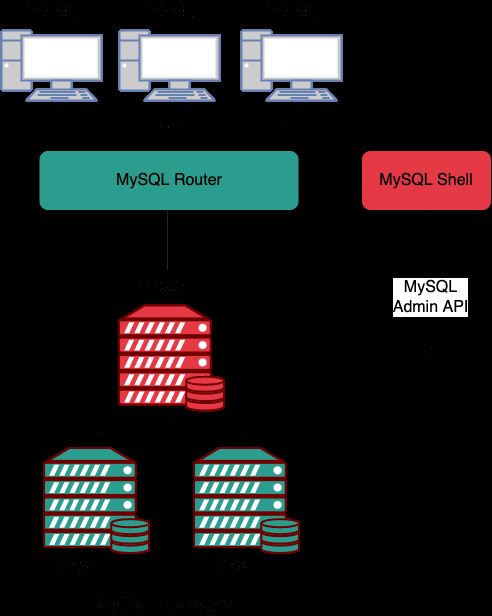
InnoDB Cluster 是官方提供的高可用方案,是 MySQL 的一种高可用性(HA)解决方案,它通过使用 MySQL Group Replication 来实现数据的自动复制和高可用性,InnoDB Cluster 通常包含下面三个关键组件:
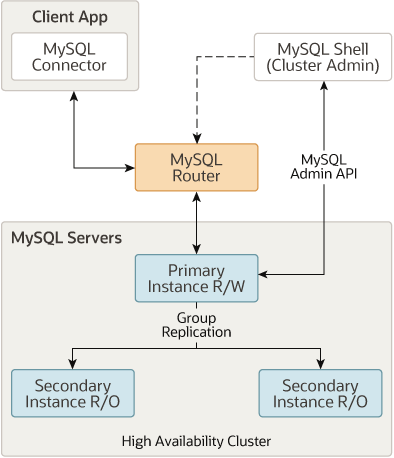
1、MySQL Shell: 它是 MySQL 的高级管理客户端;
2、MySQL Server 和 MGR,使得一组 MySQL 实例能够提供高可用性,对于 MGR,Innodb Cluster 提供了一种更加易于编程的方式来处理 MGR;
3、MySQL Router,一种轻量级中间件,主要进行路由请求,将客户端发送过来的请求路由到不同的 MySQL 服务器节点。
MySQL Server 基于 MySQL Group Replication 构建,提供自动成员管理,容错,自动故障转移动能等。InnoDB Cluster 通常以单主模式运行,一个读写实例和多个只读实例。不过也可以选用多主模式。
优点:
1、高可用性:通过 MySQL Group Replication,InnoDB Cluster 能够实现数据在集群中的自动复制,从而保证数据的可用性;
2、简单易用:InnoDB Cluster 提供了一个简单易用的管理界面,使得管理员可以快速部署和管理集群;
3、全自动故障转移: InnoDB Cluster 能够自动检测和诊断故障,并进行必要的故障转移,使得数据可以继续可用。
缺点:
1、复杂性:InnoDB Cluster 的部署和管理比较复杂,需要对 MySQL 的工作原理有一定的了解;
2、性能影响:由于自动复制和高可用性的要求,InnoDB Cluster 可能对 MySQL 的性能造成一定的影响;
3、限制:InnoDB Cluster 的功能对于一些特殊的应用场景可能不够灵活,需要更多的定制。
MySQL InnoDB ClusterSet 通过将主 InnoDB Cluster 与其在备用位置(例如不同数据中心)的一个或多个副本链接起来,为 InnoDB Cluster 部署提供容灾能力。
InnoDB ClusterSet 使用专用的 ClusterSet 复制通道自动管理从主集群到副本集群的复制。如果主集群由于数据中心损坏或网络连接丢失而变得无法使用,用户可以激活副本集群以恢复服务的可用性。
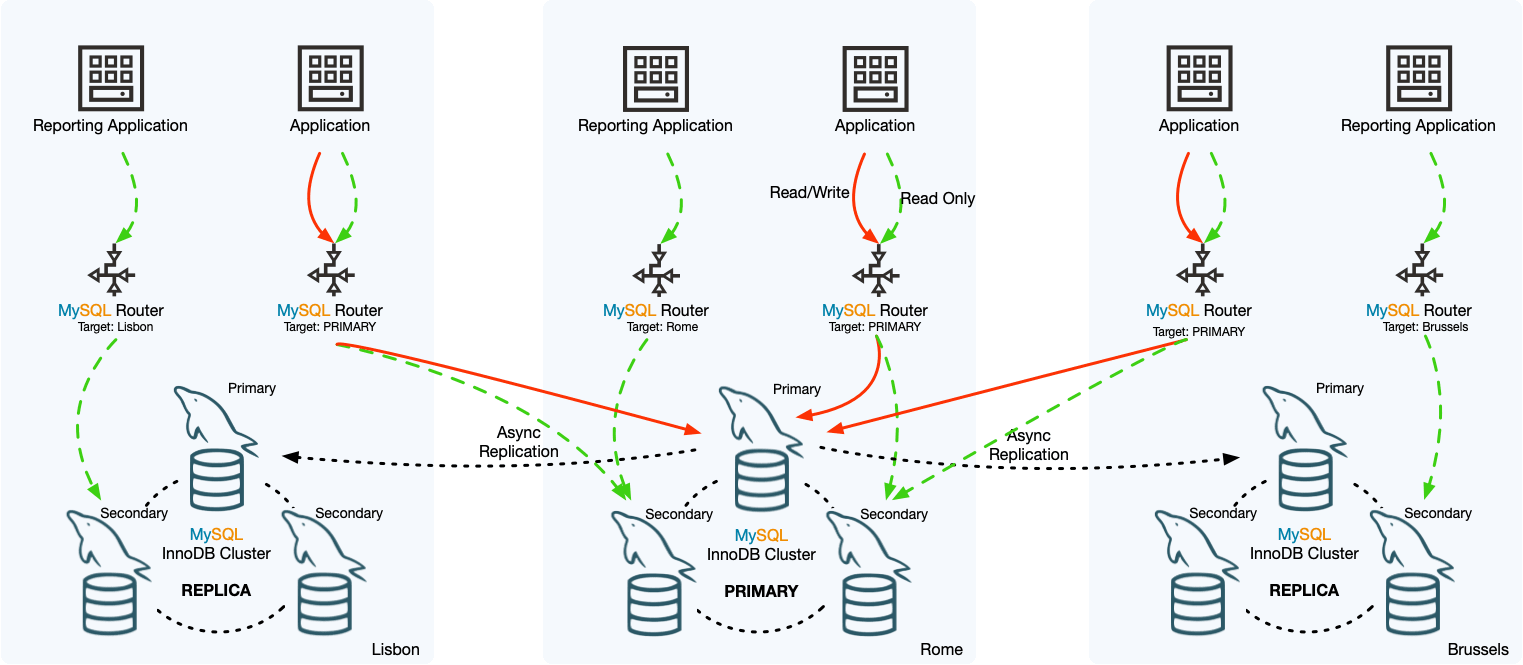
InnoDB ClusterSet 的特点:
1、主集群和副本集群之间的紧急故障转移可以由管理员通过 MySQL Shell
InnoDB Cluster ist eine offizielle Hochverfügbarkeitslösung (HA) für MySQL. Sie verwendet MySQL Group Replication Um eine automatische Datenreplikation und hohe Verfügbarkeit zu erreichen, enthält <code>InnoDB-Cluster normalerweise die folgenden drei Schlüsselkomponenten: 🎜🎜 🎜 🎜 Funktionen von InnoDB ClusterSet: 🎜🎜1. Ein Notfall-Failover zwischen dem primären Cluster und dem Replikatcluster kann vom Administrator über die AdminAPI durchgeführt werden. 🎜🎜2 Es gibt keine definierte Grenze für die Anzahl der Replikatcluster 🎜
🎜 🎜 Funktionen von InnoDB ClusterSet: 🎜🎜1. Ein Notfall-Failover zwischen dem primären Cluster und dem Replikatcluster kann vom Administrator über die AdminAPI durchgeführt werden. 🎜🎜2 Es gibt keine definierte Grenze für die Anzahl der Replikatcluster 🎜3. Der asynchrone Replikationskanal repliziert Transaktionen vom Primärcluster zum Replikatcluster. clusterset_replication Während des Erstellungsprozesses von InnoDB ClusterSet wird auf jedem Cluster ein Replikationskanal namens ClusterSet eingerichtet. Wenn es sich bei dem Cluster um eine Replik handelt, verwendet er diesen Kanal, um Daten von zu erhalten Primärcluster. Kopieren Sie die Transaktion. Die zugrunde liegende Gruppenreplikationstechnologie verwaltet den Kanal und stellt sicher, dass die Replikation immer zwischen dem Master-Server des Master-Clusters (als Sender) und dem Master-Server des Replikat-Clusters (als Empfänger) erfolgt;clusterset_replication 在 InnoDB ClusterSet 创建过程中,在每个集群上都设置了名为 ClusterSet 的复制通道,当集群是副本时,它使用该通道从主集群复制事务。底层组复制技术管理通道并确保复制始终在主集群的主服务器(作为发送方)和副本集群的主服务器(作为接收方)之间进行;
4、每个 InnoDB ClusterSet 集群,只有主集群能够接收写请求,大多数的读请求流量也会被路由到主集群,不过也可以指定读请求到其他的集群;
InnoDB ClusterSet 的限制:
1、InnoDB ClusterSet 只支持异步复制,不能使用半同步复制,无法避免异步复制的缺陷:数据延迟、数据一致性等;
2、InnoDB Cluster Set只支持单主模式的Cluster实例,不支持多主模式。 即只能包含一个读写主集群, 所有副本集群都是只读的, 不允许具有多个主集群的双活设置,因为在集群发生故障时无法保证数据一致性;
3、已有的 InnoDB Cluster 不能用作 InnoDB ClusterSet 部署中的副本集群。为了创建一个新的 InnoDB 集群,副本集群必须从单个服务器实例启动
4、只支持 MySQL 8.0。
InnoDB ReplicaSet 是 MySQL 团队在 2020 年推出的一款产品,用来帮助用户快速部署和管理主从复制,在数据库层仍然使用的是主从复制技术。
InnoDB ReplicaSet 由单个主节点和多个辅助节点(传统上称为 MySQL 复制源和副本)组成。
与 InnoDB cluster 类似, MySQL Router 支持针对 InnoDB ReplicaSet 的引导, 这意味着可以自动配置 MySQL Router 以使用 InnoDB ReplicaSet, 而无需手动配置文件. 这使得 InnoDB ReplicaSet 成为一种快速简便的方法, 可以启动和运行 MySQL 复制和 MySQL Router, 非常适合扩展读取, 并在不需要 InnoDB 集群提供高可用性的用例中提供手动故障转移功能。
InnoDB ReplicaSet 的限制:
1、没有自动故障转移,在主节点不可用的情况下,需要使用 AdminAPI 手动触发故障转移,然后才能再次进行任何更改。但是,辅助实例仍可用于读取;
2、由于意外停止或不可用,无法防止部分数据丢失:在意外停止时未完成的事务可能会丢失;
3、在意外退出或不可用后无法防止不一致。如果手动故障转移提升了一个辅助实例,而前一个主实例仍然可用,例如,由于网络分区,裂脑情况可能会导致数据不一致;
4、InnoDB ReplicaSet 不支持多主模式。允许写入所有成员的经典复制拓扑无法保证数据一致性;
5、读取横向扩展是有限的。InnoDB ReplicaSet 基于异步复制,因此无法像 Group Replication 那样调整流量控制;
6、一个 ReplicaSet 最多由一个主实例组成。支持一个或多个辅助。尽管可以添加到 ReplicaSet 的辅助节点的数量没有限制,但是连接到 ReplicaSet 的每个 MySQL Router 都必须监视每个实例。因此,一个 ReplicaSet 中加入的实例越多,监控就越多。
使用 InnoDB ReplicaSets 的主要原因是你有更好的写性能。使用 InnoDB ReplicaSets 的另一个原因是它们允许在不稳定或慢速网络上部署,而 InnoDB Cluster 则不允许。
MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。MMM 使用 Perl 语言开发,主要用来监控和管理 MySQL Master-Master

InnoDB ReplicaSet ist ein Produkt, das 2020 vom MySQL-Team eingeführt wurde, um Benutzern die schnelle Bereitstellung und Verwaltung der Master-Slave-Replikation zu erleichtern. Die Slave-Replikationstechnologie wird immer noch auf der Datenbankebene verwendet. InnoDB ReplicaSet besteht aus einem einzelnen Primärknoten und mehreren Sekundärknoten (traditionell als MySQL-Replikationsquellen und Replikate bezeichnet).
InnoDB-Cluster unterstützt MySQL Router das Booten für InnoDB ReplicaSet, was bedeutet, dass es automatisch konfiguriert werden kannMySQL Router, um InnoDB ReplicaSet zu verwenden, ohne dass manuelle Konfigurationsdateien erforderlich sind. Dadurch ist InnoDB ReplicaSet eine schnelle und einfache Möglichkeit, MySQL zum Laufen zu bringen und MySQL Router eignen sich ideal für die Skalierung von Lesevorgängen und die Bereitstellung manueller Failover-Funktionen in Anwendungsfällen, die nicht die hohe Verfügbarkeit eines InnoDB-Clusters erfordern. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#InnoDB ReplicaSet: #🎜🎜##🎜🎜#1. Es gibt kein automatisches Failover. Es muss verwendet werden, wenn der Master Der Knoten ist nicht verfügbar. AdminAPI löst manuell ein Failover aus, bevor erneut Änderungen vorgenommen werden können. Die Hilfsinstanz kann jedoch weiterhin zum Lesen verwendet werden ## 🎜🎜#3. Inkonsistenzen nach unerwartetem Beenden oder Nichtverfügbarkeit können nicht verhindert werden. Wenn ein manuelles Failover eine sekundäre Instanz hochstuft, während die vorherige primäre Instanz noch verfügbar ist, beispielsweise aufgrund von Netzwerkpartitionen, kann eine Split-Brain-Situation zu Dateninkonsistenz führen. #🎜🎜##🎜🎜#4 Multi-Master-Modus. Klassische Replikationstopologien, die Schreibzugriffe auf alle Mitglieder ermöglichen, können die Datenkonsistenz nicht garantieren. #🎜🎜##🎜🎜#5 Die horizontale Leseerweiterung ist begrenzt. InnoDB ReplicaSet basiert auf asynchroner Replikation und kann daher die Flusskontrolle nicht wie Group Replication anpassen Beispiel. Unterstützt ein oder mehrere Hilfsmittel. Obwohl die Anzahl der sekundären Knoten, die einem ReplicaSet hinzugefügt werden können, nicht begrenzt ist, muss jeder mit dem ReplicaSet verbundene MySQL-Router jede Instanz überwachen. Je mehr Instanzen einem ReplicaSet hinzugefügt werden, desto mehr Überwachung ist daher erforderlich. #🎜🎜##🎜🎜#Der Hauptgrund für die Verwendung von InnoDB ReplicaSets ist, dass Sie eine bessere Schreibleistung haben. Ein weiterer Grund für die Verwendung von InnoDB ReplicaSets besteht darin, dass sie die Bereitstellung in instabilen oder langsamen Netzwerken ermöglichen, was bei InnoDB Cluster nicht der Fall ist. #🎜🎜#MySQL Master-Master-Replikation (Dual-Master) verwendet. Man kann sagen, dass es sich um den MySQL-Master-Master-Replikationsmanager handelt. #🎜🎜##🎜🎜#Dual-Master-Modus: Im Geschäftsleben kann nur eine Master-Datenbank gleichzeitig Daten schreiben. Die andere aktive und Standby-Datenbank führt eine aktive und Standby-Umschaltung und ein Failover durch, wenn der Hauptserver ausfällt. #🎜🎜##🎜🎜#MMM verwendet einen VIP-Mechanismus (virtuelle IP), um die hohe Verfügbarkeit des Clusters sicherzustellen. Im gesamten Cluster stellt der Masterknoten eine VIP-Adresse bereit, um Datenlese- und -schreibdienste bereitzustellen. Wenn ein Fehler auftritt, wird die VIP vom ursprünglichen Masterknoten an andere Knoten übertragen und die anderen Knoten stellen Dienste bereit. #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜#MMM kann die Datenkonsistenz nicht vollständig garantieren und eignet sich daher für Szenarien, in denen die Anforderungen an die Datenkonsistenz nicht sehr hoch sind. (Da die Daten auf dem primären und sekundären Server nicht unbedingt die neuesten sind, dürfen sie nicht neuer als die Slave-Datenbank sein. Lösung: Aktivieren Sie die Halbsynchronisierung.) #🎜🎜#Vor- und Nachteile von MMM
Vorteile: hohe Verfügbarkeit, gute Skalierbarkeit, automatische Umschaltung im Fehlerfall, für die Master-Master-Synchronisation ist nur ein Datenbank-Schreibvorgang gleichzeitig vorgesehen Gewährleistung der Datenkonsistenz.
Nachteile: Die Datenkonsistenz kann nicht vollständig garantiert werden. Es wird empfohlen, eine halbsynchrone Replikation zu verwenden, um die Wahrscheinlichkeit eines Ausfalls zu verringern. Derzeit gibt es in der MMM-Community keine Wartung und sie unterstützt keine GTID-basierte Replikation.
Anwendbare Szenarien:
MMM eignet sich für Szenarien mit großem Datenbankzugriff, schnellem Geschäftswachstum und einer Lese- und Schreibtrennung.
Master High Availability Manager und Tools für MySQL, bezeichnet als MHA. Hierbei handelt es sich um einen hervorragenden Satz Hochverfügbarkeitssoftware für Failover und Master-Slave-Förderung in einer MySQL-Hochverfügbarkeitsumgebung.
Dieses Tool wird speziell zur Überwachung des Status der Hauptbibliothek verwendet. Wenn festgestellt wird, dass der Master-Knoten fehlerhaft ist, wird der Slave-Knoten automatisch zum neuen Master-Knoten hochgestuft In diesem Zeitraum durchläuft MHA andere Slave-Knoten, um zusätzliche Informationen zu erhalten, um Probleme mit der Datenkonsistenz zu vermeiden. MHA bietet auch eine Funktion zum Online-Schalten von Master-Slave-Knoten, die bei Bedarf umgeschaltet werden können. MHA kann ein Failover innerhalb von 30 Sekunden implementieren und gleichzeitig die Datenkonsistenz weitestgehend gewährleisten.
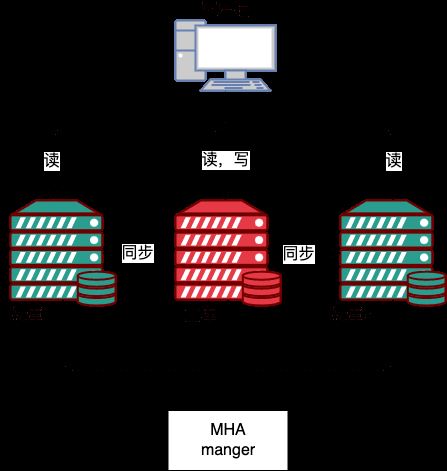
MHA besteht aus zwei Teilen;
MHA-Manager (Verwaltungsknoten) und MHA-Knoten (Datenknoten).
MHA Manager kann auf einem unabhängigen Computer bereitgestellt werden, um mehrere Master-Slave-Cluster zu verwalten, oder er kann auf einem Slave-Knoten bereitgestellt werden. MHA-Knoten wird auf jedem MySQL-Server ausgeführt. MHA-Manager erkennt regelmäßig den Master-Knoten im Cluster. Wenn der Master ausfällt, kann er den Slave automatisch mit den neuesten Daten hochstufen. zum neuen Master und leiten Sie dann alle anderen Slaves zum neuen Master um. MHA Manager 可以单独部署在一台独立的机器上管理多个 master-slave 集群,也可以部署在一台 slave节点上。MHA Node 运行在每台 MySQL 服务器上,MHA Manager 会定时探测集群中的 master 节点,当 master 出现故障时,它可以自动将最新数据的 slave 提升为新的 master,然后将所有其他的 slave 重新指向新的 master。
整个故障转移过程对应用程序完全透明。
在 MHA 自动故障切换过程中,MHA 试图从宕机的主服务器上最大限度的保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,主服务器硬件故障或无法通过 ssh 访问,MHA 没法保存二进制日志,只进行故障转移而丢失了最新的数据。
使用 MySQL 5.5 开始找支持的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个 slave 已经收到了最新的二进制日志,MHA 可以将最新的二进制日志应用于其他所有的 slave 服务器上,因此可以保证所有节点的数据一致性。
目前 MHA 主要支持一主多从的架构,要搭建 MHA,要求一个复制集群中必须最少有三台数据库服务器 ,一主二从,即一台 master,一台充当备用 master,另外一台充当从库,因为至少需要三台服务器。
MHA 工作原理总结如下:
1、从宕机崩溃的 master 保存二进制日志事件(binlog events);
2、识别最新更新的 slave;
3、应用差异的中继日志(relay log) 到其他slave;
4、应用从master保存的二进制日志事件(binlog events);
5、提升一个 slave 为新master;
6、使用其他的 slave 连接新的 master 进行复制。
优点:
1、可以支持基于 GTID 的复制模式;
2、MHA 在进行故障转移时更不易产生数据丢失;
3、同一个监控节点可以监控多个集群。
缺点:
1、需要编写脚本或利用第三方工具来实现 Vip 的配置;
2、MHA 启动后只会对主数据库进行监控;
3、需要基于 SSH 免认证配置,存在一定的安全隐患。
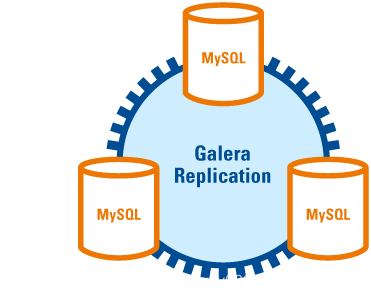
Galera Cluster 是由 Codership 开发的MySQL多主集群,包含在 MariaDB 中,同时支持 Percona xtradb、MySQL,是一个易于使用的高可用解决方案,在数据完整性、可扩展性及高性能方面都有可接受的表现。
其本身具有 multi-master 特性,支持多点写入,Galera Cluster
 Während des automatischen MHA-Failover-Prozesses versucht MHA, das Binärprotokoll des ausgefallenen Hauptservers so weit wie möglich zu retten, um sicherzustellen, dass Daten nicht im größtmöglichen Umfang verloren gehen. Dies ist jedoch nicht immer machbar. Wenn beispielsweise die Hardware des Master-Servers ausfällt oder nicht über SSH darauf zugegriffen werden kann, kann MHA das Binärprotokoll nicht speichern und führt lediglich einen Failover durch und verliert die neuesten Daten.
Während des automatischen MHA-Failover-Prozesses versucht MHA, das Binärprotokoll des ausgefallenen Hauptservers so weit wie möglich zu retten, um sicherzustellen, dass Daten nicht im größtmöglichen Umfang verloren gehen. Dies ist jedoch nicht immer machbar. Wenn beispielsweise die Hardware des Master-Servers ausfällt oder nicht über SSH darauf zugegriffen werden kann, kann MHA das Binärprotokoll nicht speichern und führt lediglich einen Failover durch und verliert die neuesten Daten.
Verwenden Sie MySQL 5.5, um nach einer unterstützten halbsynchronen Replikation zu suchen, die das Risiko eines Datenverlusts erheblich reduzieren kann. MHA kann mit halbsynchroner Replikation kombiniert werden. Wenn nur ein Slave das neueste Binärprotokoll erhalten hat, kann MHA das neueste Binärprotokoll auf alle anderen Slave-Server anwenden und so die Datenkonsistenz auf allen Knoten sicherstellen.
Derzeit unterstützt MHA hauptsächlich eine Ein-Master-Mehrfach-Slave-Architektur. Um MHA aufzubauen, muss ein Replikationscluster mindestens drei Datenbankserver haben, einen Master und zwei Slaves, also einen Master und Einer dient als Backup-Master und der andere fungiert als Slave-Datenbank, da mindestens drei Server erforderlich sind.
Das Funktionsprinzip von MHA lässt sich wie folgt zusammenfassen:
1 Speichern Sie binäre Protokollereignisse (Binlog-Ereignisse) vom abgestürzten Master; . Identifikation Der zuletzt aktualisierte Slave;
4. Übernehmen Sie das vom Master gespeicherte Binärprotokoll 🎜#5. Befördern Sie einen Slave zum neuen Master;
6. Verwenden Sie andere Slaves, um eine Verbindung zum neuen Master herzustellen.
Vorteile:
1. Kann den GTID-basierten Replikationsmodus unterstützen;
#🎜🎜#2. MHA ist weniger anfällig für Datenverlust während des Failovers; 🎜##🎜🎜#3. Derselbe Überwachungsknoten kann mehrere Cluster überwachen. #🎜🎜##🎜🎜#Nachteile: #🎜🎜##🎜🎜#1. Sie müssen Skripte schreiben oder Tools von Drittanbietern verwenden, um die VIP-Konfiguration zu implementieren. es wird nur die Hauptdatenbank überwacht; #🎜🎜##🎜🎜#3 Es erfordert eine authentifizierungsfreie Konfiguration auf Basis von SSH, was gewisse Sicherheitsrisiken birgt. #🎜🎜##🎜🎜#Galera Cluster#🎜🎜##🎜🎜#Galera Cluster ist ein von Codership entwickelter MySQL-Multi-Master-Cluster, der in MariaDB enthalten ist und auch Percona xtradb unterstützt , MySQL, ist eine benutzerfreundliche Hochverfügbarkeitslösung mit akzeptabler Leistung in Bezug auf Datenintegrität, Skalierbarkeit und hohe Leistung. #🎜🎜##🎜🎜#Es verfügt über die Multi-Master-Funktion und unterstützt Multi-Point-Schreiben. Jede Instanz im Galera-Cluster ist Peer-to-Peer, Master-Slave zueinander. Wenn der Client Daten liest und schreibt, kann er eine beliebige MySQL-Instanz auswählen. Für Lesevorgänge sind die von jeder Instanz gelesenen Daten dieselben. Wenn bei Schreibvorgängen Daten auf einen Knoten geschrieben werden, synchronisiert der Cluster diese mit anderen Knoten. Diese Architektur teilt keine Daten und ist eine hochredundante Architektur. #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜#Hauptfunktionen#🎜🎜##🎜🎜#1. Synchrone Replikation; #🎜🎜##🎜🎜#2. Das heißt, alle Knoten können gleichzeitig die Datenbank lesen und schreiben. #🎜🎜##🎜🎜#3 Daten und automatisch kopieren;# 🎜🎜##🎜🎜#5. Echte parallele Replikation, Zeilenebene; . #🎜🎜##🎜🎜#Vorteil#🎜🎜#1. Datenkonsistenz: Die synchrone Replikation stellt die Datenkonsistenz des gesamten Clusters sicher. Das Ergebnis ist dasselbe.
2 Es kommt nicht zu einem Absturz eines einzelnen Knotens, ohne dass es zu Datenverlust oder Dienstausfällen kommt.
3. Durch die synchrone Replikation können Transaktionen parallel ausgeführt werden. Dadurch wird die Lese- und Schreibleistung verbessert
4. Geringere Client-Latenz
5.
Analyse des Prinzips
Die synchrone Replikation wird hauptsächlich im Galera-Cluster verwendet. Eine einzelne Aktualisierungstransaktion in der Hauptbibliothek muss in allen Slave-Bibliotheken synchron aktualisiert werden. Alle Knotendaten im Cluster seien konsistent. Galera Cluster 中主要用到了同步复制,主库中的单个更新事务需要在所有从库中同步更新,当主库提交事务,集群中的所有节点数据保持一致。
异步复制,主库将数据更新传播给从库后立即提交事务,而不论从库是否成功读取或重放数据变化,所以异步复制会存在短暂的,主从数据同步不一致的情况出现。
不过同步复制的缺点也是很明显的,同步复制协议通常使用两阶段提交或分布式锁协调不同节点的操作,也及时说节点越多需要协调的节点也就越多,那么事务冲突和死锁的概率也就会随之增加。
我们知道 MGR 组复制的引入也是为了解决传统异步复制和半同步复制可能产生数据不一致的问题,MGR 中的组复制,基于 Paxos 协议,原则上事务的提交,主要大多数节点 ACK 就可以提交了。
Galera Cluster 中的同步需要同步数据到所有节点,保证所有节点都成功。基于专有通信组系统 GCommon ,所有节点都必须有 ACK。
Galera 复制是一种基于验证的复制,基于验证的复制使用通信和排序技术实现同步复制,通过广播并发事务之间建立的全局总序来协调事务提交。简单的讲就是事务必须以相同的顺序应用于所有实例。
事务现在本地执行,然后发送的其他节点做冲突验证,没有冲突的时候所有节点提交事务,否则在所有节点回滚。
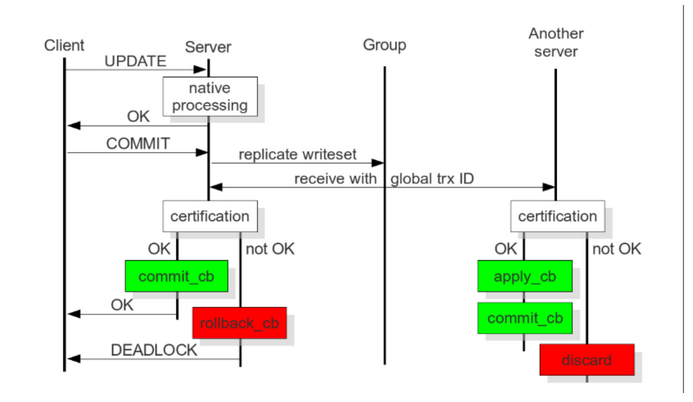
当客户端发出 commit 命令时,在实际提交之前,对数据所做的更改都会收集到一个写集合中,写集合中包含事务信息和所更改行的主键,数据库将写集发送到其它节点。
节点用写集中的主键与当前节点中未完成事务的所有写集的主键比较,确定节点是否可以提交事务,同时满足下面三个条件会被任务存在冲突,验证失败:
1、两个事务来源于不同节点;
2、两个事务包含相同的主键;
3、老事务对新事务不可见,即老事务未提交完成。新老事务的划定依赖于全局事务总序,即 GTID。
每个节点独立进行验证,如果验证失败,该节点将删除写集并回滚原始事务,所有节点都会执行相同的操作。所有节点按照相同顺序接收事务,导致它们都做出相同的结果决定,要么全部成功,要么全部失败。成功后自然就提交了,所有的节点又会重新达到数据一致的状态。节点之间不交换“是否冲突”的信息,各个节点独立异步处理事务。
MySQL Cluster 是一个高度可扩展的,兼容 ACID 事务的实时数据库,基于分布式架构不存在单点故障,MySQL Cluster 支持自动水平扩容,并能做自动的读写负载均衡。
MySQL Cluster 使用了一个叫 NDB 的内存存储引擎来整合多个 MySQL 实例,提供一个统一的服务集群。
NDB是一种采用不共享的Sharding-Nothing架构的内存存储引擎。Sarding-Nothing 指的是每个节点有独立的处理器,磁盘和内存,节点之间没有共享资源完全独立互不干扰,节点之间通过告诉网络组在一起,每个节点相当于是一个小型的数据库,存储部分数据。这种架构的好处是可以利用节点的分布性并行处理数据,调高整体的性能,还有就是有很高的水平扩展性能,只需要增加节点就能增加数据的处理能力。
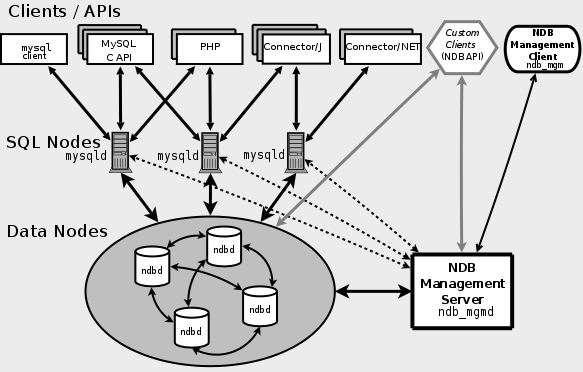
MySql Cluster 中包含三种节点,分别是管理节点(NDB Management Server)、数据节点(Data Nodes)和 SQL查询节点(SQL Nodes) 。
SQL Nodes 是应用程序的接口,像普通的 mysqld 服务一样,接受用户的 SQL 输入,执行并返回结果。Data Nodes 是数据存储节点,NDB Management Server
Galera-Cluster erfordert die Synchronisierung von Daten mit allen Knoten, um sicherzustellen, dass alle Knoten erfolgreich sind. Basierend auf dem proprietären Kommunikationsgruppensystem GCommon müssen alle Knoten über ACK verfügen. 🎜🎜Galera-Replikation ist eine Art verifizierungsbasierte Replikation. Die verifizierungsbasierte Replikation nutzt Kommunikations- und Sortiertechnologie, um eine synchrone Replikation zu erreichen, und koordiniert die Transaktionseinreichung durch Übertragung der globalen Gesamtreihenfolge zwischen gleichzeitigen Transaktionen. Einfach ausgedrückt müssen Transaktionen auf alle Instanzen in derselben Reihenfolge angewendet werden. 🎜🎜Die Transaktion wird nun lokal ausgeführt und dann zur Konfliktüberprüfung an andere Knoten gesendet. Wenn kein Konflikt vorliegt, wird die Transaktion von allen Knoten festgeschrieben, andernfalls wird sie auf allen Knoten zurückgesetzt. 🎜🎜🎜 🎜 Wenn der Client einen Commit-Befehl ausgibt, werden die an den Daten vorgenommenen Änderungen vor dem eigentlichen Commit in einem Schreibsatz gesammelt. Der Schreibsatz enthält Transaktionsinformationen und den Primärschlüssel der geänderten Zeile, und die Datenbank sendet den Schreibsatz an andere Knoten. 🎜🎜Der Knoten vergleicht den Primärschlüssel im Schreibsatz mit den Primärschlüsseln in allen Schreibsätzen nicht abgeschlossener Transaktionen im aktuellen Knoten, um festzustellen, ob der Knoten die Transaktion gleichzeitig senden kann Es kommt zu einem Konflikt und die Überprüfung schlägt fehl: 🎜🎜1. Die beiden Transaktionen stammen von verschiedenen Knoten. 🎜🎜3 Die alte Transaktion ist für die neue Transaktion nicht sichtbar Das heißt, die alte Transaktion wurde nicht übermittelt. Die Abgrenzung neuer und alter Transaktionen hängt von der globalen Transaktionsgesamtreihenfolge, also der GTID, ab. 🎜🎜Jeder Knoten führt die Überprüfung unabhängig durch. Wenn die Überprüfung fehlschlägt, löscht der Knoten den Schreibsatz und setzt die ursprüngliche Transaktion zurück. Alle Knoten führen den gleichen Vorgang aus. Alle Knoten empfangen Transaktionen in der gleichen Reihenfolge, was dazu führt, dass sie alle die gleiche Ergebnisentscheidung treffen: entweder alle erfolgreich oder alle fehlschlagen. Nach Erfolg wird es auf natürliche Weise übermittelt und alle Knoten erreichen wieder einen datenkonsistenten Zustand. Es werden keine Informationen über „Konflikte“ zwischen Knoten ausgetauscht und jeder Knoten verarbeitet Transaktionen unabhängig und asynchron. 🎜MySQL-Cluster ist eine hoch skalierbare, mit ACID-Transaktionen kompatible Echtzeitdatenbank. Es gibt keinen Single Point of Failure, der auf einer verteilten Architektur basiert MySQL Cluster unterstützt die automatische horizontale Erweiterung und kann einen automatischen Lese- und Schreiblastausgleich durchführen. 🎜🎜MySQL-Cluster verwendet eine In-Memory-Speicher-Engine namens NDB, um mehrere MySQL-Instanzen zu integrieren und einen einheitlichen Service-Cluster bereitzustellen. 🎜🎜NDB ist eine Speicher-Engine, die die Sharding-Nothing-Architektur nutzt. Sarding-Nothing bedeutet, dass jeder Knoten über einen unabhängigen Prozessor, eine Festplatte und einen unabhängigen Speicher verfügt. Die Knoten sind vollständig unabhängig und stören sich nicht gegenseitig eine kleine Datenbank, speichert einige Daten. Der Vorteil dieser Architektur besteht darin, dass sie die Verteilung von Knoten nutzen kann, um Daten parallel zu verarbeiten und die Gesamtleistung zu verbessern. Außerdem kann durch das Hinzufügen von Knoten die Datenverarbeitungsfähigkeit erhöht werden. 🎜🎜🎜 🎜 MySql Cluster enthält drei Arten von Knoten, nämlich Verwaltungsknoten (NDB Management Server), Datenknoten (Data Nodes) und SQL-Abfrageknoten (SQL Nodes). 🎜🎜SQL Nodes ist die Schnittstelle des Anwendungsprogramms. Wie der gewöhnliche mysqld-Dienst akzeptiert er die SQL-Eingaben des Benutzers, führt sie aus und gibt die Ergebnisse zurück. Datenknoten sind Datenspeicherknoten, und NDB-Verwaltungsserver wird zur Verwaltung jedes Knotens im Cluster verwendet. 🎜Der Datenknoten speichert die Datenpartitionen und Partitionskopien im Cluster. Schauen wir uns an, wie MySql-Cluster Sharding-Vorgänge für Daten durchführt. Lassen Sie uns zunächst die folgenden Konzepte verstehen: Eine Sammlung von Datenknoten. Die Anzahl der Knotengruppen = Anzahl der Knoten / Anzahl der Replikate MySql Cluster 是如何对数据进行分片的操作的,首先来了解下下面几个概念
节点组(Node Group): 一组数据节点的集合。节点组的个数=节点数 / 副本数;
比如有集群中 4 个节点,副本数为 2(对应 NoOfReplicas 的设置),那么节点组个数为2。
另外,在可用性方面,数据的副本在组内交叉分配,一个节点组内只有要一台机器可用,就可以保证整个集群的数据完整性,实现服务的整体可用。
分区(Partition):MySql Cluster 是一个分布式的存储系统,数据按照 分区 划分成多份存储在各数据节点中,分区个数由系统自动计算,分区数 = 数据节点数 / LDM 线程数;
副本(Replica):分区数据的备份,有几个分区就有几个副本,为了避免单点,保证 MySql Cluster 集群的高可用,原始数据对应的分区和副本通常会保存在不同的主机上,在一个节点组内进行交叉备份。
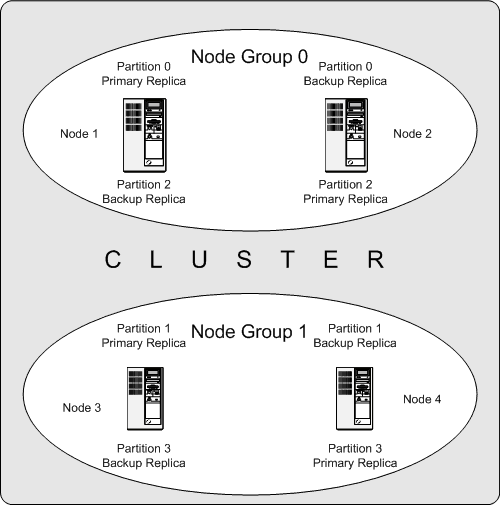
栗如,上面的例子,有四个数据节点(使用ndbd),副本数为2的集群,节点组被分为2组(4/2),数据被分为4个分区,数据分配情况如下:
分区0(Partition 0)保存在节点组 0(Node Group 0)中,分区数据(主副本 — Primary Replica)保存在节点1(node 1) 中,备份数据(备份副本,Backup Replica)保存在节点2(node 2) 中;
分区1(Partition 1)保存在节点组 1(Node Group 1)中,分区数据(主副本 — Primary Replica)保存在节点3(node 3) 中,备份数据(备份副本,Backup Replica)保存在节点4(node 4) 中;
分区2(Partition 2)保存在节点组 0(Node Group 0)中,分区数据(主副本 — Primary Replica)保存在节点2(node 2) 中,备份数据(备份副本,Backup Replica)保存在节点1(node 1) 中;
分区3(Partition 2)保存在节点组 1(Node Group 1)中,分区数据(主副本 — Primary Replica)保存在节点4(node 4) 中,备份数据(备份副本,Backup Replica)保存在节点3(node 3) 中;
这样,对于一张表的一个 Partition 来说,在整个集群有两份数据,并分布在两个独立的 Node 上,实现了数据容灾。同时,每次对一个 Partition 的写操作,都会在两个 Replica 上呈现,如果 Primary Replica 异常,那么 Backup Replica 可以立即提供服务,实现数据的高可用。
mysql cluster 的优点
1、99.999%的高可用性;
2、快速的自动失效切换;
3、灵活的分布式体系结构,没有单点故障;
4、高吞吐量和低延迟;
5、可扩展性强,支持在线扩容。
mysql cluster 的缺点
1、存在很多限制,比如:不支持外键,数据行不能超过8K(不包括BLOB和text中的数据);
2、部署、管理、配置很复杂;
3、占用磁盘空间大,内存大;
4、备份和恢复不方便;
5、重启的时候,数据节点将数据 load 到内存需要很长时间。
MySQL Fabric 会组织多个 MySQL 数据库,将大的数据分散到多个数据库中,即数据分片(Data Shard),同时同一个分片数据库中又是一个主从结构,Fabric 会挑选合适的库作为主库,当主库挂掉的时候,又会重新在从库中选出一个主库。
MySQL Fabric 的特点:
1、高可用;
2、使用数据分片的横向功能。
MySQL Fabric-aware 连接器把从 MySQL Fabric 获取的路由信息存储到缓存中,然后凭借该信息将事务或查询发送给正确的 MySQL 服务器。
同时,每一个分片组,可以又多个一个服务器组成,构成主从结构,当主库挂掉的时候,又会重新在从库中选出一个主库。保证节点的高可用。
HA Group 保证访问指定 HA Group 的数据总是可用的,同时其基础的数据复制是基于 MySQL Replication
 Außerdem werden im Hinblick auf die Verfügbarkeit Kopien von Daten innerhalb der Gruppe verteilt. Nur eine Maschine in einer Knotengruppe ist verfügbar, um die Datenintegrität des gesamten Clusters sicherzustellen und eine allgemeine Serviceverfügbarkeit zu erreichen.
Außerdem werden im Hinblick auf die Verfügbarkeit Kopien von Daten innerhalb der Gruppe verteilt. Nur eine Maschine in einer Knotengruppe ist verfügbar, um die Datenintegrität des gesamten Clusters sicherzustellen und eine allgemeine Serviceverfügbarkeit zu erreichen.
Partition: MySql-Cluster ist ein verteiltes Speichersystem, das in mehrere Teile unterteilt und in jedem Datenknoten gespeichert wird Anzahl = Anzahl der Datenknoten / Anzahl der LDM-Threads;
Replikat: Es werden mehrere Kopien für so viele Partitionen wie möglich erstellt. Stellen Sie sicher, dass MySql-Cluster vorhanden ist Für eine hohe Verfügbarkeit des Clusters werden die den Originaldaten entsprechenden Partitionen und Kopien in der Regel auf verschiedenen Hosts gespeichert und innerhalb einer Knotengruppe kreuzweise gesichert.
🎜 🎜 Li Ru, im obigen Beispiel gibt es vier Datenknoten (mit ndbd), einen Cluster mit 2 Replikaten, die Knotengruppe ist in 2 Gruppen (4/2) unterteilt, die Daten sind in 4 Partitionen unterteilt und die Daten Die Verteilung ist wie folgt: 🎜🎜Partition 0 (Partition 0) wird in Knotengruppe 0 (Knotengruppe 0) gespeichert, Partitionsdaten (Primäres Replikat) werden in Knoten 1 (Knoten 1) gespeichert und Sicherungsdaten (Sicherungsreplikat) wird in Knoten 2 (Knoten 2) gespeichert. 🎜🎜Partition 1 (Partition 1) wird in Knotengruppe 1 (Knotengruppe 1) gespeichert, Partitionsdaten (primäre Kopie – primäres Replikat) werden in Knoten 3 (Knoten) gespeichert 3) Sicherungsdaten (Backup-Replikat) werden in Knoten 4 (Knoten 4) gespeichert. 🎜🎜Partition 2 (Partition 2) wird in Knotengruppe 0 (Knotengruppe 0) und Partitionsdaten (primäres Replikat) gespeichert ) wird in Knoten 2 (Knoten 2) gespeichert, die Sicherungsdaten (Backup Replica) werden in Knoten 1 (Knoten 1) gespeichert. 🎜🎜Partition 3 (Partition 2) wird in Knotengruppe 1 (Knotengruppe) gespeichert 1) und die Partitionsdaten (Das primäre Replikat – Primary Replica) werden in Knoten 4 (Knoten 4) und die Sicherungsdaten (Backup Replica) werden in Knoten 3 (Knoten 3) gespeichert Auf diese Weise gibt es für eine Partition einer Tabelle zwei Kopien der Daten im gesamten Cluster, die auf zwei unabhängige Knoten verteilt werden, wodurch eine Datenwiederherstellung im Katastrophenfall erreicht wird. Gleichzeitig wird jeder Schreibvorgang auf einer Partition auf zwei Replikaten dargestellt. Wenn das Primäre Replikat abnormal ist, kann das Sicherungsreplikat sofort Dienste bereitstellen, um eine hohe Dateneffizienz zu erreichen . Verfügbar. 🎜🎜mysql Vorteile🎜🎜1. Schnelles automatisches Failover; 🎜🎜4 geringe Latenz; 🎜🎜5. Starke Skalierbarkeit, unterstützt die Online-Erweiterung. 🎜🎜mysql-cluster Nachteile🎜🎜1 Es gibt viele Einschränkungen, wie zum Beispiel: Es werden keine Fremdschlüssel unterstützt und die Datenzeile darf 8 KB nicht überschreiten (ausgenommen Daten in BLOB und Text); Bereitstellung, Verwaltung und Konfiguration sind sehr kompliziert. 🎜🎜4. Sicherung und Wiederherstellung sind unpraktisch um Daten in den Speicher zu laden. 🎜MySQL Fabric organisiert mehrere MySQL-Datenbanken und verteilt große Datenmengen auf mehrere Datenbanken, d. h. Daten-Sharding (Data Shard), Gleichzeitig gibt es eine Master-Slave-Struktur in derselben Shard-Datenbank. Wenn die Master-Bibliothek ausfällt, wählt sie erneut eine Master-Bibliothek aus. 🎜🎜<code>MySQL Fabric Funktionen: 🎜🎜1. Horizontale Funktion mit Daten-Sharding. 🎜🎜Der MySQL Fabric-fähige-Connector speichert die von MySQL Fabric erhaltenen Routing-Informationen im Cache und verwendet diese Informationen dann, um die Transaktion oder Abfrage an den richtigen MySQL-Server zu senden. 🎜🎜Gleichzeitig kann jede Sharding-Gruppe aus mehreren Servern bestehen, um eine Master-Slave-Struktur zu bilden. Wenn die Master-Datenbank auflegt, wird erneut eine Master-Datenbank aus der Slave-Datenbank ausgewählt. Stellen Sie eine hohe Knotenverfügbarkeit sicher. 🎜🎜HA-Gruppe stellt sicher, dass der Zugriff auf die Daten der angegebenen HA-Gruppe immer verfügbar ist, und ihre grundlegende Datenreplikation basiert auf MySQL-Replikation . 🎜🎜🎜🎜🎜Nachteile🎜🎜Transaktionen und Abfragen werden nur innerhalb desselben Shards unterstützt. Die in der Transaktion aktualisierten Daten können nicht Shards überschreiten, und die von der Abfrageanweisung zurückgegebenen Daten können nicht Shards überschreiten. 🎜Das obige ist der detaillierte Inhalt vonWas sind die gängigen Bereitstellungslösungen für Hochverfügbarkeitsarchitekturen in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



