


Ein Index ist eine spezielle Datei, die Referenzzeiger auf alle Datensätze in der Datentabelle enthält. Sie können einen Index für eine oder mehrere Spalten in der Tabelle erstellen und den Indextyp angeben. Jeder Indextyp verfügt über eine eigene Datenstrukturimplementierung.
Die Beziehung zwischen Tabellen, Daten und Indizes in einer Datenbank ähnelt der Beziehung zwischen Büchern, Buchinhalten und Buchkatalogen in einem Bücherregal. Der Index spielt eine ähnliche Rolle wie ein Buchkatalog und kann zum schnellen Auffinden und Abrufen von Daten verwendet werden. Indizes können die Datenbankleistung erheblich verbessern.
Um die Erstellung eines Index für eine oder mehrere bestimmte Spalten einer Datenbanktabelle in Betracht zu ziehen, müssen Sie die folgenden Punkte berücksichtigen:
Die Datenmenge ist groß und häufig werden bedingte Abfragen für diese durchgeführt Spalten.
Die Häufigkeit von Einfügevorgängen und Änderungsvorgängen für diese Spalten in dieser Datenbanktabelle ist gering.
Indizes beanspruchen zusätzlichen Speicherplatz.
Getrennt von der Indexspeicherstruktur: BTree-Index, Hash-Index, FULLTEXT-Volltextindex, RTree-Index
Getrennt von der Anwendungsebene: gewöhnlicher Index, eindeutiger Index, Primärschlüssel Index, zusammengesetzter Index
Getrennt vom Indexschlüsselwerttyp, Primärschlüsselindex, Hilfsindex (Sekundärindex)
Getrennt von der logischen Beziehung zwischen Datenspeicherung und Indexschlüsselwert: Clustered-Index (Clustered-Index) nicht -Clustered-Index (Nicht-Clustered-Index) Index)
Dividiert durch die Anzahl der Indexspalten: Einzelspaltenindex, zusammengesetzter Index

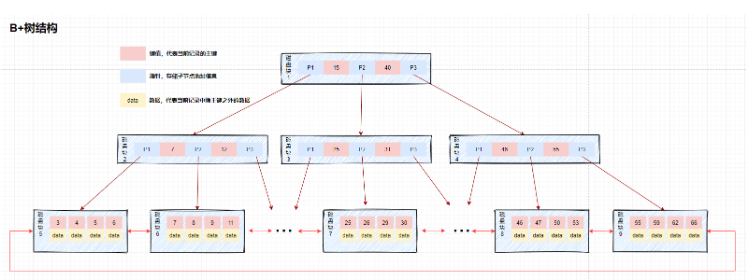
Unterschied:
Der Speicherort der Daten ist unterschiedlich: B+-Baumspeicherung Am Blattknoten wird der B-Baum in allen Knoten gespeichert, was die Vorteile des B+-Baums widerspiegelt: Der Knoten speichert keine Daten, also eins Der Knoten kann mehr Schlüssel speichern. Dadurch kann der Baum kürzer werden, sodass die Anzahl der E/A-Vorgänge geringer ist. Die Abfrageleistung ist stabil: Jede Abfrage verläuft vom Wurzelknoten zum Blattknoten. Die Länge des Abfragepfads ist gleich, dh die Effizienz jeder Abfrage ist gleichwertig. Die Zeitkomplexität ist auf O (log (n)) festgelegt
Zeigen von Blattknoten: B+-Baum Benachbarte Blattknoten sind durch Zeiger verbunden. Der B-Baum bietet nicht die Vorteile eines B+-Baums: Alle Blattknoten bilden eine geordnete verknüpfte Liste, was die Bereichssuche erleichtert. Erstellen eines Primärschlüssels Index-- 在创建表的时候,直接在字段名后指定 primary key create table user1(id int primary key, name varchar(30)); -- 在创建表的最后,指定某列或某几列为主键索引 create table user2(id int, name varchar(30), primary key(id)); -- 创建表以后再添加主键 create table user3(id int, name varchar(30)); alter table user3 add primary key(id);
Es gibt höchstens einen Primärschlüsselindex in einer Tabelle. Dies kann natürlich dazu führen, dass der Primärschlüsselindex hocheffizient ist (der Primärschlüssel kann nicht wiederholt werden) Erstellen Sie die Spalte des Primärschlüsselindex. Ihr Wert darf nicht null sein und kann nicht wiederholt werden. Die Spalten des Primärschlüsselindex sind grundsätzlich int. Erstellen eines eindeutigen Index
In einer Tabelle können mehrere eindeutige Indizes vorhanden sein.
Abfrageeffizienz hoch. Wenn Sie einen eindeutigen Index für eine bestimmte Spalte erstellen, müssen Sie sicherstellen, dass diese Spalte keine doppelten Daten enthalten kann. Wenn Wenn Sie für einen eindeutigen Index nicht null angeben, entspricht dies der Erstellung eines Primärschlüsselindex werden häufiger in der tatsächlichen Entwicklung verwendet
Wenn eine Spalte indiziert werden muss, die Spalte jedoch doppelte Werte enthält, dann sollten wir normale Indizes verwenden
Abfrageindex
********** 1. Zeile **** *******
Tabelle: Waren <= TabellennameSeq_in_index: 1
Spaltenname: waren_id <= Wo ist die Indexspalte? Indextyp: BTREE <= Index in binärer BaumformIndex aus Tabellennamen anzeigen;
-- 在表定义时,在某列后直接指定unique唯一属性。 create table user4(id int primary key, name varchar(30) unique); -- 创建表时,在表的后面指定某列或某几列为unique create table user5(id int primary key, name varchar(30), unique(name)); -- 创建表以后再添加unique create table user6(id int primary key, name varchar(30)); alter table user6 add unique(name);
Drop-Index-Indexname auf Tabellennamen
--在表的定义最后,指定某列为索引 create table user8(id int primary key, name varchar(20), email varchar(30), index(name) ); --创建完表以后指定某列为普通索引 create table user9(id int primary key, name varchar(20), email varchar(30)); alter table user9 add index(name); -- 创建一个索引名为 idx_name 的索引 create table user10(id int primary key, name varchar(20), email varchar(30)); create index idx_name on user10(name);
IndexerstellungsprinzipFelder, die nicht in der where-Klausel erscheinen, sollten keinen Index erstellen
Felder, die häufig als Abfragebedingungen verwendet werden, sollten indiziert werden
Felder mit schlechter Eindeutigkeit eignen sich nicht zum Erstellen eines Index allein, auch wenn Sie werden häufig als Abfragebedingungen verwendet
Felder, die sehr häufig aktualisiert werden, eignen sich nicht zum Erstellen eines Indexes
Das obige ist der detaillierte Inhalt vonWas ist das Indexierungsprinzip und die Optimierungsstrategie der MySQL-Datenbank?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



