


In der Bibel gibt es eine Geschichte über den Turmbau zu Babel. Es heißt, dass Menschen sich zusammenschlossen, um den Bau eines hohen Turms zu planen, in der Hoffnung, in den Himmel zu führen, aber Gott verwirrte die menschliche Sprache und die Der Plan wurde daher geändert. Heute wird erwartet, dass die KI-Technologie die Barrieren zwischen menschlichen Sprachen niederreißt und der Menschheit dabei hilft, einen zivilisierten Turmbau zu Babel zu errichten.
Kürzlich hat eine Studie von Meta einen wichtigen Schritt in Richtung dieses Aspekts gemacht. Sie nennen die neu vorgeschlagene Methode Massively Multilingual Speech (Super Multilingual Speech/MMS). die Bibel als Teil der Trainingsdaten und erhielt die folgenden Ergebnisse:
Wie löst Meta das Problem der Datenknappheit in vielen seltenen Sprachen? Die Methode, die sie verwendeten, ist interessant, nämlich die Verwendung religiöser Korpora, da Korpora wie die Bibel die am besten „ausgeglichenen“ Sprachdaten enthalten. Obwohl dieser Datensatz auf religiöse Inhalte ausgerichtet ist und hauptsächlich männliche Stimmen enthält, zeigt die Arbeit, dass das Modell auch in anderen Bereichen gute Ergebnisse erzielt, wenn weibliche Stimmen verwendet werden. Dies ist das Emergenzverhalten des Basismodells und es ist wirklich erstaunlich. Noch erstaunlicher ist, dass Meta alle neu entwickelten Modelle (Spracherkennung, TTS und Spracherkennung) kostenlos veröffentlicht hat!
Um ein Sprachmodell zu erstellen, das Tausende von Wörtern erkennen kann, besteht die erste Herausforderung darin Sammeln Sie Audiodaten in verschiedenen Sprachen, da der größte vorhandene Sprachdatensatz nur höchstens 100 Sprachen umfasst. Um dieses Problem zu lösen, verwendeten Meta-Forscher religiöse Texte wie die Bibel, die in viele verschiedene Sprachen übersetzt wurden, und diese Übersetzungen wurden eingehend untersucht. Diese Übersetzungen enthalten Audioaufnahmen von Menschen, die sie in verschiedenen Sprachen lesen, und diese Audios sind auch öffentlich verfügbar. Mithilfe dieser Audioaufnahmen erstellten die Forscher einen Datensatz mit Audioaufnahmen von Menschen, die das Neue Testament in 1.100 Sprachen lasen, mit einer durchschnittlichen Audiolänge von 32 Stunden pro Sprache.
Sie fügten dann unkommentierte Aufnahmen vieler anderer christlicher Lesungen hinzu, wodurch sich die Zahl der verfügbaren Sprachen auf über 4.000 erhöhte. Obwohl das Feld dieses Datensatzes ein einzelnes Feld ist und hauptsächlich aus männlichen Stimmen besteht, zeigen die Analyseergebnisse, dass Metas neu entwickeltes Modell bei weiblichen Stimmen gleichermaßen gut abschneidet und das Modell nicht besonders auf die Produktion religiöserer Sprache ausgerichtet ist. Die Forscher gaben im Blog an, dass dies hauptsächlich auf die von ihnen verwendete Methode der konnektionistischen zeitlichen Klassifizierung zurückzuführen sei, die großen Sprachmodellen (LLM) oder eingeschränkteren Sequenz-zu-Sequenz-Spracherkennungsmodellen weit überlegen sei.
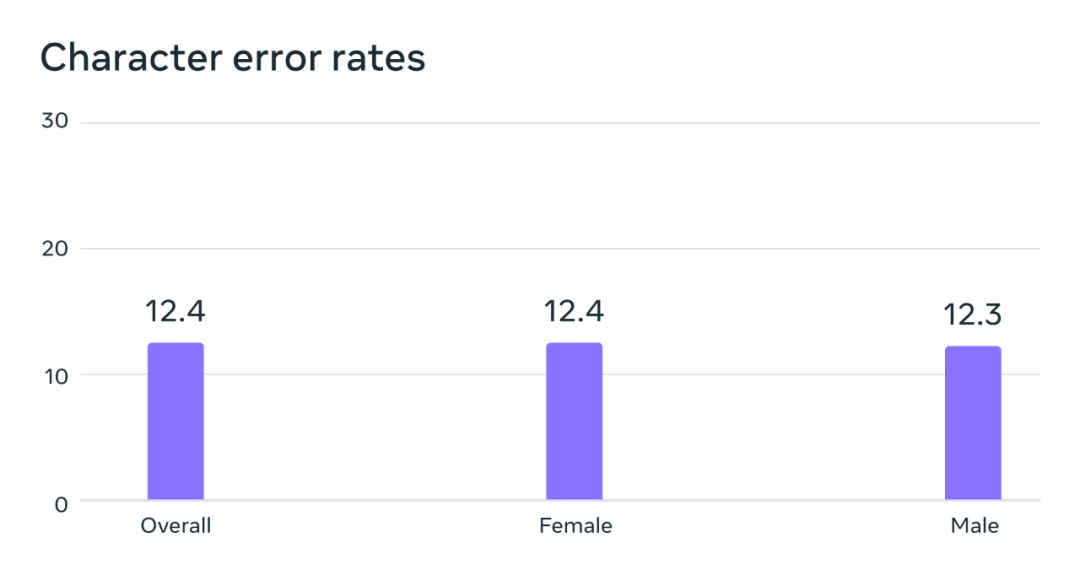
Analyse potenzieller geschlechtsspezifischer Vorurteile. Beim FLEURS-Benchmark weist dieses auf dem Multilingual Speech (MMS)-Datensatz trainierte automatische Spracherkennungsmodell ähnliche Fehlerraten für männliche und weibliche Stimmen auf.
Um die Qualität der Daten zu verbessern, damit sie von Algorithmen für maschinelles Lernen verwendet werden können, haben sie auch einige Vorverarbeitungsmethoden übernommen. Zuerst trainierten sie ein Ausrichtungsmodell auf vorhandenen Daten aus mehr als 100 Sprachen und kombinierten es dann mit einem effizienten erzwungenen Ausrichtungsalgorithmus, der sehr lange Aufzeichnungen von mehr als 20 Minuten verarbeiten kann. Anschließend, nach mehreren Runden von Ausrichtungsprozessen, wird ein letzter Schritt der Kreuzvalidierungsfilterung durchgeführt, um potenziell falsch ausgerichtete Daten basierend auf der Modellgenauigkeit zu entfernen. Um anderen Forschern die Erstellung neuer Sprachdatensätze zu erleichtern, hat Meta den Ausrichtungsalgorithmus zu PyTorch hinzugefügt und das Ausrichtungsmodell veröffentlicht.
Um ein universell einsetzbares überwachtes Spracherkennungsmodell zu trainieren, reichen nur 32 Stunden Daten pro Sprache nicht aus. Daher wird ihr Modell auf der Grundlage von wav2vec 2.0 entwickelt, einer früheren Forschung zum selbstüberwachten Lernen der Sprachdarstellung, wodurch die Menge der für das Training erforderlichen gekennzeichneten Daten erheblich reduziert werden kann. Konkret trainierten die Forscher ein selbstüberwachtes Modell mit etwa 500.000 Stunden Sprachdaten in mehr als 1.400 Sprachen – mehr als fünfmal mehr Sprachen als in jeder früheren Studie. Anschließend verfeinern die Forscher das resultierende Modell anhand spezifischer Sprachaufgaben (z. B. Erkennung mehrsprachiger Sprache oder Spracherkennung).
Die Forscher bewerteten das neu entwickelte Modell anhand einiger vorhandener Benchmarks.
Das Training seines mehrsprachigen Spracherkennungsmodells verwendet das wav2vec 2.0-Modell mit 1 Milliarde Parametern, und der Trainingsdatensatz enthält mehr als 1.100 Sprachen. Die Modellleistung nimmt zwar mit zunehmender Anzahl von Sprachen ab, der Rückgang ist jedoch sehr gering: Wenn die Anzahl von Sprachen von 61 auf 1107 erhöht wird, steigt die Zeichenfehlerrate nur um 0,4 %, aber die Sprachabdeckung nimmt um mehr zu als 18 Mal.
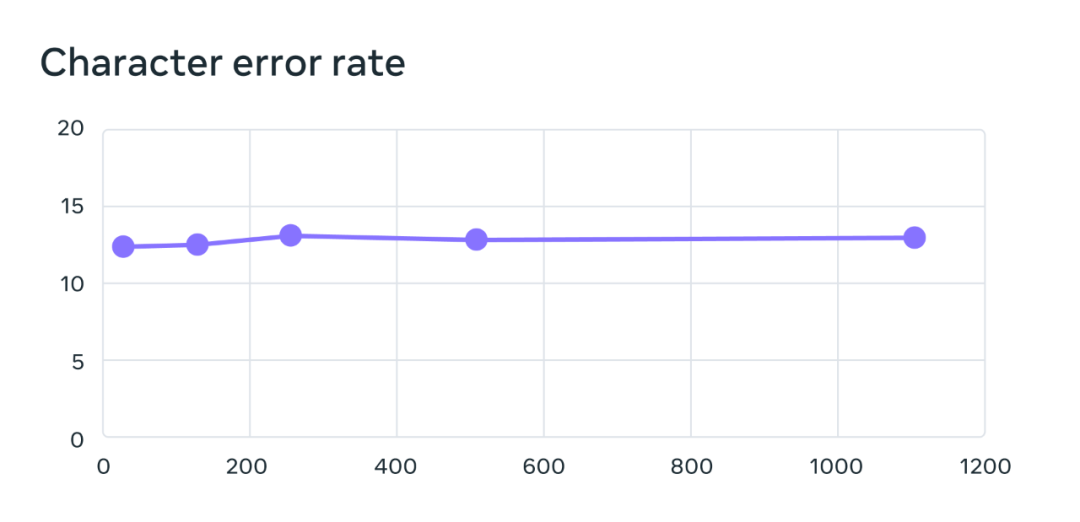
Beim Benchmark-Test von 61 FLEURS-Sprachen ändert sich die Zeichenfehlerrate mit zunehmender Anzahl der Sprachen. Je höher die Fehlerrate, desto schlechter das Modell.
Durch den Vergleich des Whisper-Modells von OpenAI stellten die Forscher fest, dass die Wortfehlerrate ihres Modells nur halb so hoch war wie die von Whisper, während das neue Modell elfmal mehr Sprachen unterstützte. Dieses Ergebnis zeigt die überlegenen Fähigkeiten der neuen Methode.
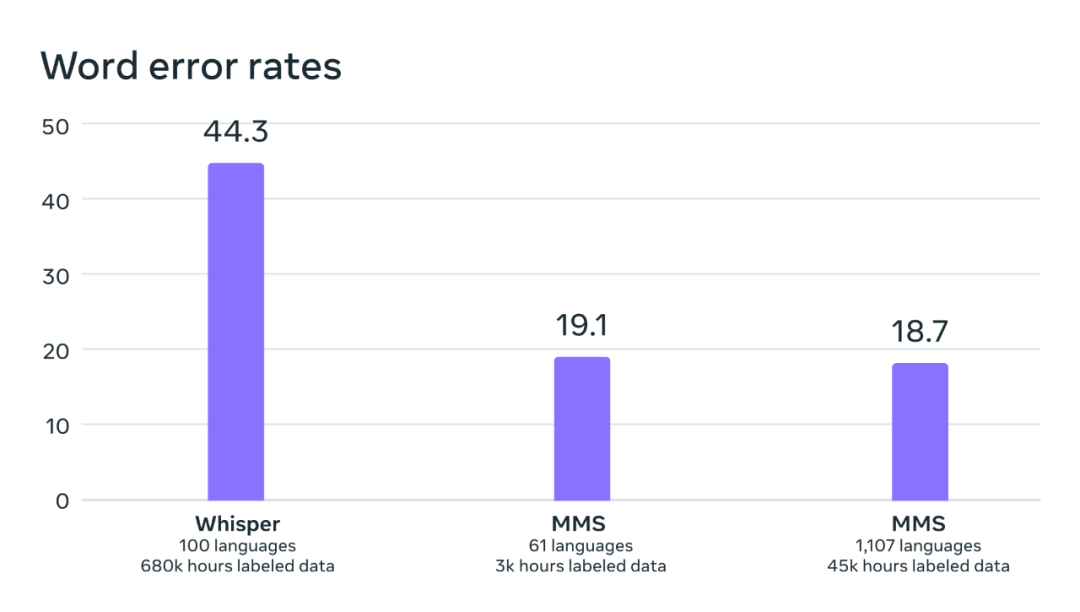
Vergleich der Wortfehlerraten zwischen OpenAI Whisper und MMS anhand eines direkt vergleichbaren Benchmarks von 54 FLEURS-Sprachen.
Als nächstes trainierten Meta-Forscher unter Verwendung bereits vorhandener Datensätze (wie FLEURS und CommonVoice) und neuer Datensätze auch ein Spracherkennungsmodell (LID) und evaluierten es anhand der FLEURS-LID-Aufgabe. Die Ergebnisse zeigen, dass das neue Modell nicht nur eine hervorragende Leistung erbringt, sondern auch 40-mal mehr Sprachen unterstützt.
Frühere Untersuchungen unterstützten auch nur mehr als 100 Sprachen im VoxLingua-107-Benchmark, während MMS mehr als 4000 Sprachen unterstützt.
Darüber hinaus hat Meta auch ein Text-to-Speech-System entwickelt, das 1100 Sprachen unterstützt. Die Trainingsdaten für aktuelle Text-to-Speech-Modelle sind normalerweise Sprachkorpus eines einzelnen Sprechers. Eine Einschränkung der MMS-Daten besteht darin, dass viele Sprachen nur eine geringe Anzahl von Sprechern haben, oft sogar einen einzigen Sprecher. Dies erwies sich jedoch beim Aufbau eines Text-to-Speech-Systems als Vorteil, weshalb Meta ein TTS-System entwickelte, das mehr als 1.100 Sprachen unterstützt. Forscher sagen, dass die Qualität der von diesen Systemen erzeugten Sprache tatsächlich recht gut ist. Nachfolgend werden einige Beispiele aufgeführt.
Demonstration des MMS-Text-to-Speech-Modells für die Sprachen Yoruba, Iroko und Maithili.
Forscher sagen jedoch, dass die KI-Technologie immer noch nicht perfekt ist, und das Gleiche gilt auch für MMS. Beispielsweise kann es bei MMS vorkommen, dass ausgewählte Wörter oder Phrasen während der Sprachausgabe falsch transkribiert werden. Dies kann zu einer anstößigen und/oder ungenauen Sprache in der Ausgabe führen. Die Forscher betonten, wie wichtig es sei, mit der KI-Community für eine verantwortungsvolle Entwicklung zusammenzuarbeiten.
Viele Sprachen auf der ganzen Welt stehen kurz vor dem Aussterben, und die Einschränkungen der aktuellen Spracherkennungs- und Sprachgenerierungstechnologie werden diesen Trend nur noch beschleunigen. Der Forscher stellte sich im Blog vor: Vielleicht kann Technologie Menschen dazu ermutigen, ihre eigene Sprache beizubehalten, denn mit guter Technologie können sie ihre Lieblingssprache verwenden, um Informationen zu erhalten und Technologie zu nutzen.
Sie glauben, dass das MMS-Projekt ein wichtiger Schritt in diese Richtung ist. Sie sagten auch, dass das Projekt weiterentwickelt wird und in Zukunft mehr Sprachen unterstützen und sogar die Probleme von Dialekten und Akzenten lösen wird.
Das obige ist der detaillierte Inhalt vonMeta verwendet die Bibel, um ein Super-Mehrsprachenmodell zu trainieren: 1107 Sprachen erkennen und 4017 Sprachen identifizieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



