

Wenn ein Satz nur wenige ganzzahlige Elemente enthält, verwendet Redis den ganzzahligen Satz intset. Schauen Sie sich zunächst die Datenstruktur von Intset an:
typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; } intset;
Tatsächlich ist die Datenstruktur von Intset relativ einfach zu verstehen. Bei einem Datenspeicherelement speichert die Länge die Anzahl der Elemente, also die Größe des Inhalts, und die Kodierung ist die zum Speichern von Daten verwendete Kodierungsmethode.
Aus dem Code können wir erkennen, dass der Codierungstyp Folgendes umfasst:
#define INTSET_ENC_INT16 (sizeof(int16_t)) #define INTSET_ENC_INT32 (sizeof(int32_t)) #define INTSET_ENC_INT64 (sizeof(int64_t))
Tatsächlich können wir es sehen. Die Art der Redis-Codierung bezieht sich auf die Größe der Daten. Als In-Memory-Datenbank wird dieses Design übernommen, um Speicherplatz zu sparen.
Da es drei Datenstrukturen von klein bis groß gibt, verwenden Sie möglichst kleine Datenstrukturen, um beim Einfügen von Daten Speicherplatz zu sparen. Wenn die eingefügten Daten größer als die ursprüngliche Datenstruktur sind, wird die Erweiterung ausgelöst.
Es gibt drei Schritte zur Erweiterung:
Ändern Sie je nach Typ der neuen Elemente den Datentyp des gesamten Arrays und weisen Sie den Platz neu zu.
Ersetzen Sie die Originaldaten durch den neuen Datentyp und ersetzen Sie sie Es sollte an der Position sein und die Reihenfolge beibehalten
, bevor neue Elemente eingefügt werden
Die Integer-Sammlung unterstützt keine Downgrade-Vorgänge. Nach dem Upgrade kann kein Downgrade durchgeführt werden.
Die Sprungliste ist eine Art verknüpfte Liste, eine Datenstruktur, die Raum zum Zeitaustausch nutzt. Die Sprungliste unterstützt die durchschnittliche O(logN)-Suche und die O(N)-Komplexitätssuche im ungünstigsten Fall.
Die Sprungliste besteht aus einer zskiplist und mehreren zskiplistNode. Schauen wir uns zunächst ihre Struktur an:
/* ZSETs use a specialized version of Skiplists *//* * 跳跃表节点 */ typedef struct zskiplistNode { // 成员对象 robj *obj; // 分值 double score; // 后退指针 struct zskiplistNode *backward; // 层 struct zskiplistLevel { // 前进指针 struct zskiplistNode *forward; // 跨度 unsigned int span; } level[]; } zskiplistNode; /* * 跳跃表 */ typedef struct zskiplist { // 表头节点和表尾节点 struct zskiplistNode *header, *tail; // 表中节点的数量 unsigned long length; // 表中层数最大的节点的层数 int level; } zskiplist;
Auf der Grundlage dieses Codes können wir also das folgende Strukturdiagramm zeichnen:
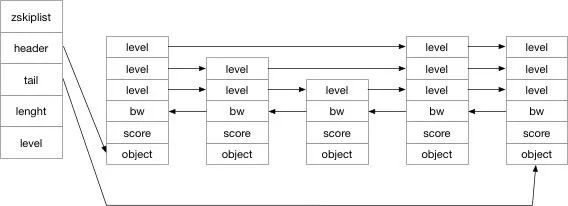
Tatsächlich handelt es sich bei der Sprungliste um eine Datenstruktur, die Raum zum Zeitaustausch nutzt und Ebenen als verwendet Der Index der verknüpften Liste.
Jemand hat den Autor von Redis schon einmal gefragt, warum er zum Erstellen von Indizes Sprungtabellen anstelle von Bäumen verwendet? Die Antwort des Autors lautet:
Speicher sparen.
Bei der Verwendung von ZRANGE oder ZREVRANGE handelt es sich um ein typisches Operationsszenario für verknüpfte Listen. Die Leistung der Zeitkomplexität ähnelt der von ausgeglichenen Bäumen.
Der wichtigste Punkt ist, dass die Implementierung der Sprungtabelle sehr einfach ist und das O(logN)-Niveau erreichen kann.
Komprimierte verknüpfte Liste Der Autor von Redis führt sie als doppelt verknüpfte Liste ein, die so viel Speicherplatz wie möglich sparen soll.
Die in den Kommentaren im Code für eine Komprimierungsliste angegebene Datenstruktur lautet wie folgt:
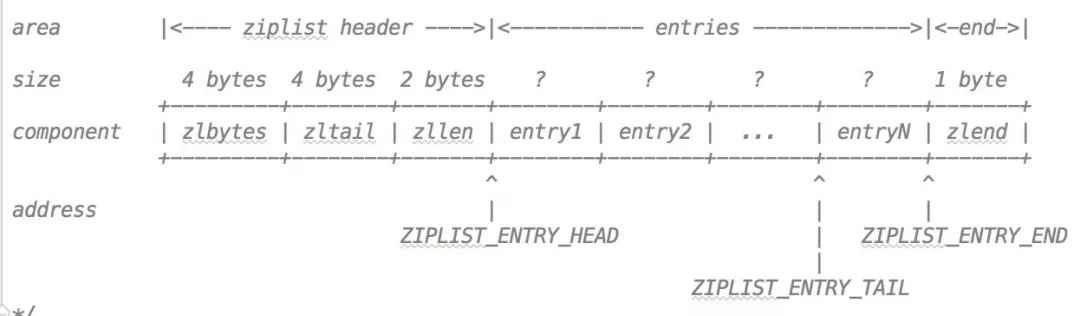
zlbytesstellt die Anzahl der von der gesamten Komprimierungsliste verwendeten Speicherbytes darzlbytes表示的是整个压缩列表使用的内存字节数
zltail指定了压缩列表的尾节点的偏移量
zllen是压缩列表 entry 的数量
entry就是 ziplist 的节点
zlend标记压缩列表的末端
这个列表中还有单个指针:
ZIPLIST_ENTRY_HEAD列表开始节点的头偏移量
ZIPLIST_ENTRY_TAIL列表结束节点的头偏移量
ZIPLIST_ENTRY_END列表的尾节点结束的偏移量
再看看一个 entry 的结构:
/* * 保存 ziplist 节点信息的结构 */ typedef struct zlentry { // prevrawlen :前置节点的长度 // prevrawlensize :编码 prevrawlen 所需的字节大小 unsigned int prevrawlensize, prevrawlen; // len :当前节点值的长度 // lensize :编码 len 所需的字节大小 unsigned int lensize, len; // 当前节点 header 的大小 // 等于 prevrawlensize + lensize unsigned int headersize; // 当前节点值所使用的编码类型 unsigned char encoding; // 指向当前节点的指针 unsigned char *p; } zlentry;
依次解释一下这几个参数。
prevrawlen前置节点的长度,这里多了一个 size,其实是记录了 prevrawlen 的尺寸。Redis 为了节约内存并不是直接使用默认的 int 的长度,而是逐渐升级的。
同理len记录的是当前节点的长度,lensize记录的是 len 的长度。headersize就是前文提到的两个 size 之和。encoding就是这个节点的数据类型。这里注意一下 encoding 的类型只包括整数和字符串。p
zltailGibt den Offset des Endknotens der komprimierten Liste an.
zllenist die Anzahl der Einträge in der komprimierten Liste.
entryist der Knoten der ziplist
zlendcode> Markiert das Ende der komprimierten Liste In dieser Liste gibt es auch einen einzelnen Zeiger:
ZIPLIST_ENTRY_HEADDer Kopfoffset des Startknotens der Liste
ZIPLIST_ENTRY_TAILDer Kopf des Endknotens der Liste Offset
ZIPLIST_ENTRY_ENDDer Offset des Endes des Endknotens der ListeSehen Sie sich die Struktur von an wieder ein Eintrag: rrreeeErklären Sie diese Parameter der Reihe nach.
prevrawlenDie Länge des vorhergehenden Knotens. Hier gibt es eine zusätzliche Größe, die tatsächlich die Größe von prevrawlen aufzeichnet. Um Speicher zu sparen, verwendet Redis nicht direkt die standardmäßige int-Länge, sondern aktualisiert sie schrittweise.
lendie Länge des aktuellen Knotens auf und
lensizezeichnet die Länge von len auf.
headersizeist die Summe der beiden oben genannten Größen.
encodingist der Datentyp dieses Knotens. Beachten Sie hier, dass Codierungstypen nur Ganzzahlen und Zeichenfolgen umfassen.
pDer Zeiger des Knotens, es ist nicht nötig, zu viel zu erklären. Zu beachten ist, dass jeder Knoten die Länge des vorherigen Knotens speichert. Wenn ein Knoten aktualisiert oder gelöscht wird, müssen auch die Daten nach diesem Knoten geändert werden Der Grenzpunkt, der erweitert werden muss, führt dazu, dass die Knoten nach diesem Knoten den Größenparameter ändern und so eine Kettenreaktion auslösen. Zu diesem Zeitpunkt beträgt die schlechteste Zeitkomplexität beim Komprimieren der verknüpften Liste O (n ^ 2). Allerdings liegen alle Knoten auf kritischen Werten, so dass man sagen kann, dass die Wahrscheinlichkeit relativ gering ist.
Das obige ist der detaillierte Inhalt vonWas ist die grundlegende Datenstruktur von Redis?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken? Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis? So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher? Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen? Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?

























