


Der Index kann entsprechend der zugrunde liegenden Implementierung in B-Tree-Index und Hash-Index unterteilt werden. Meistens verwenden wir den B-Tree-Index, da seine gute Leistung und Eigenschaften besser für Build geeignet sind Systeme mit hoher Parallelität.
Unterteilt nach der Speichermethode des Index kann der Index in Clustered-Index und Nicht-Clustered-Index unterteilt werden. Die Blattknoten eines nicht gruppierten Index enthalten nur alle Felder und Primärschlüssel-IDs, während die Blattknoten eines gruppierten Index vollständige Datensatzzeilen enthalten.
Je nach Clustered-Index und Non-Clustered-Index kann er weiter in gewöhnliche Indizes, abdeckende Indizes, eindeutige Indizes und gemeinsame Indizes unterteilt werden.
Der nicht gruppierte Index wird auch als Hilfsindex und gewöhnlicher Index bezeichnet. Seine Blattknoten enthalten nur einen Primärschlüsselwert. Um Datensätze über den nicht gruppierten Index zu finden, müssen Sie zuerst den Primärschlüssel finden Der entsprechende Datensatz im Clustered-Index wird als Tabellenrückgabe bezeichnet.
Zum Beispiel eine Datentabelle mit Benutzernamen und Alter, vorausgesetzt, der Primärschlüssel ist die Benutzer-ID, die Struktur des Clustered-Index ist (orange stellt die ID dar, grün ist der Zeiger auf den untergeordneten Knoten):
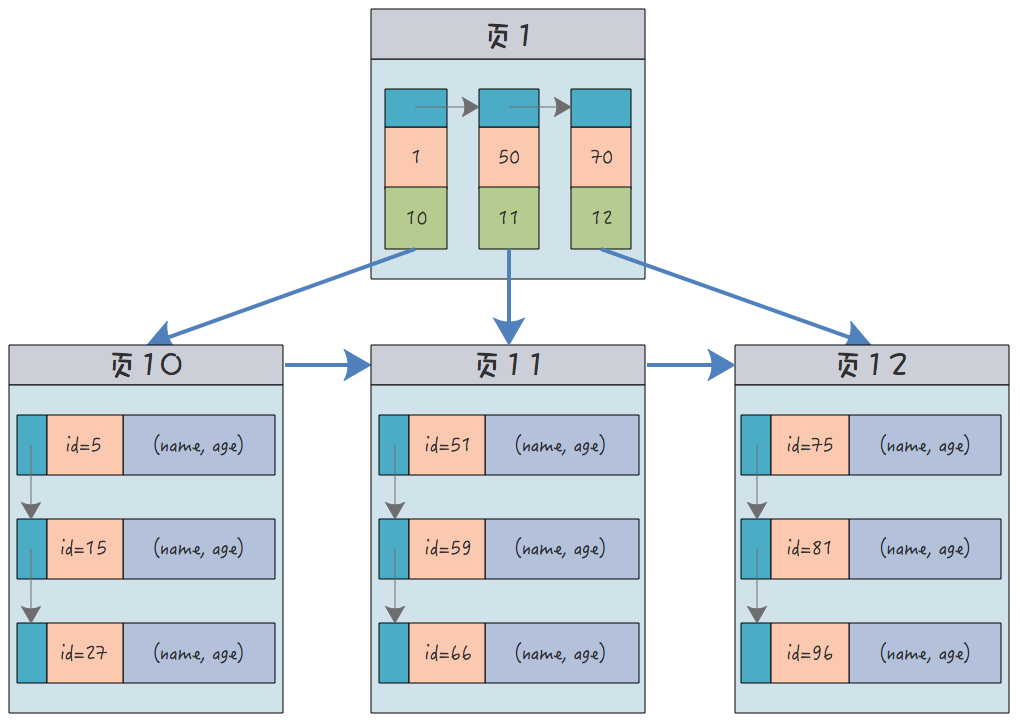 Im Blattknoten wird
Im Blattknoten wird
(id, name, age)Die Struktur eines nicht gruppierten Index (indiziert nach Alter) ist:
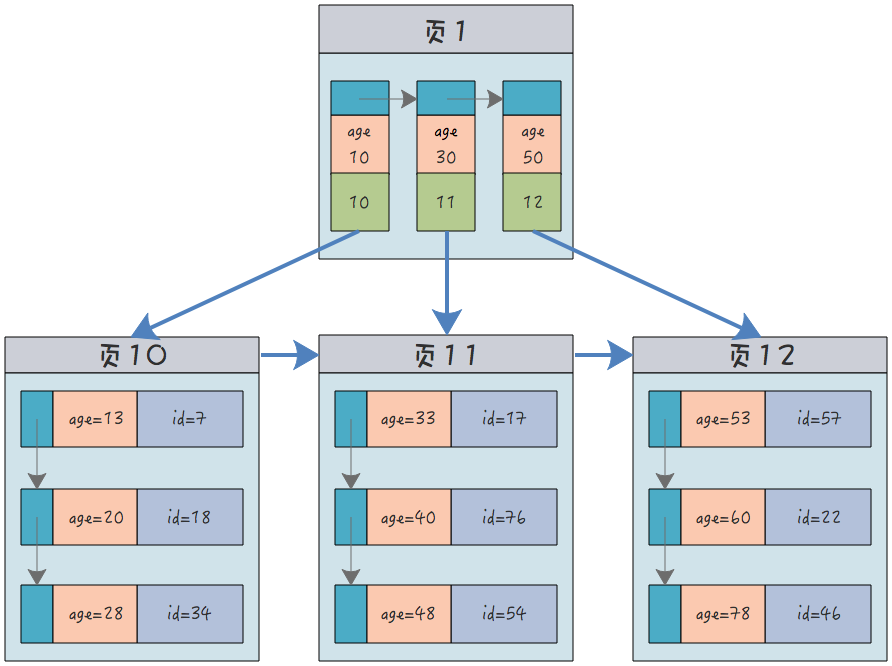 Zusätzlich zum Altersfeld selbst ist in den Blattknoten dieses Knotens nur die Primärschlüssel-ID des aktuellen Datensatzes enthalten. nicht die vollständig aufgezeichneten Informationen. Sie müssen den Clustered-Index anhand der ID-Nummer abfragen, um die gesamte Datensatzdatenzeile zu erhalten.
Zusätzlich zum Altersfeld selbst ist in den Blattknoten dieses Knotens nur die Primärschlüssel-ID des aktuellen Datensatzes enthalten. nicht die vollständig aufgezeichneten Informationen. Sie müssen den Clustered-Index anhand der ID-Nummer abfragen, um die gesamte Datensatzdatenzeile zu erhalten.
In InnoDB muss jede Tabelle über einen Clustered-Index verfügen, der standardmäßig basierend auf dem Primärschlüssel erstellt wird. Wenn in der Tabelle kein Primärschlüssel vorhanden ist, wählt InnoDB eine geeignete Spalte als Clustered-Index aus. Wenn keine geeignete Spalte gefunden wird, wird eine versteckte Spalte DB_ROW_ID als Clustered-Index verwendet.
3. Abdeckungsindex
Nehmen Sie den Altersindex oben als Beispiel. Es handelt sich um einen nicht gruppierten Index. Wenn ich die ID des Benutzers nach Alter abfragen möchte, führe ich die folgende Anweisung aus:
Ist es in diesem Fall trotzdem notwendig, die Uhr zurückzugeben? Da ich nur den Wert der ID benötige, kann ich die ID bereits über den Altersindex abrufen. Wenn ich noch einmal zur Tabelle zurückgehe, wäre das nicht eine nutzlose Operation? Tatsächlich ist es nicht nötig. Wenn der Hilfsindex bereits alle für die Abfrage erforderlichen Informationen enthält, kann der Tabellenrückgabevorgang in der Indexabfrage vermieden werden. Dies ist ein abdeckender Index.
Der gemeinsame Index bezieht sich auf einen Index, der für mehrere Spalten gleichzeitig erstellt wird. Nach der Erstellung eines gemeinsamen Index enthalten die Blattknoten gleichzeitig den Wert jeder Indexspalte und werden entsprechend sortiert Diese Sortierung ist die gleiche wie bei uns. Die lexikografische Reihenfolge ist ähnlich.
Zum Beispiel die Indexstruktur, die gleichzeitig für die oben genannten Namen und Altersgruppen erstellt wurde:
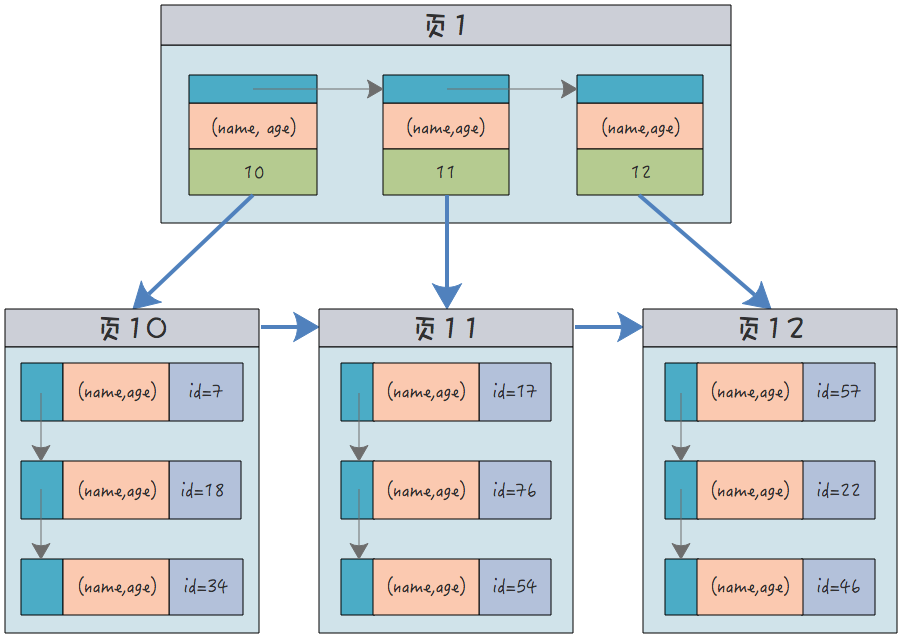
(name, age)sind alles Abkürzungen, und mir fallen nicht mehr als ein Dutzend Namen ein.
Jeder Blattknoten speichert alle Indexspalten gleichzeitig. Außerdem enthält er weiterhin nur die Primärschlüssel-ID.
Wenn ein Index für mehrere Spalten erstellt wird, kann der Index nicht verwendet werden, solange er die Spalten enthält, für die der Index erstellt wurde. Die Verwendung des Index muss dem Prinzip der Übereinstimmung des Präfixes ganz links folgen.
Angenommen, Sie erstellen einen Index für Spalten (A, B, C), dann können nur die folgenden Szenarien den Index verwenden:
Abfrage für Spalten (A, B, C)/(A, C) oder (A , B) Entspricht dem Index, der Index kann nicht für (C, A) oder (B, C) verwendet werden.
Platzhalter können nur die Form LIKE 'val%' verwenden, nicht die Form LIKE '%VAL%', was zu einem vollständigen Tabellenscan führt.
Die Indexspalte kann nicht bedient werden. Beispielsweise führt WHERE A + 1 = 5 dazu, dass der Index fehlschlägt.
Indexspalten dürfen keine Bereichswertabfragen wie LIKE/BETWEEN/>/
Indexspalten dürfen keine NULL-Werte enthalten.
Die neue Version von MySQL (5.6 und höher) hat einen Index-Pushdown-Mechanismus eingeführt: Während des Indexdurchlaufprozesses können zuerst die im Index enthaltenen Felder beurteilt werden und die Felder, die dies nicht erfüllen Bedingungen können direkt herausgefiltert werden. Erfassen und reduzieren Sie die Anzahl der Tabellenrückgaben.
Führen Sie beispielsweise einen gemeinsamen Index für (Name, Alter) in der obigen Tabelle durch. Die Abfragelogik lautet unter normalen Umständen:
Suchen Sie die entsprechende Primärschlüssel-ID anhand des Namens.
Passen Sie die Altersbedingung an Die Spalte des ID-Datensatzes
Dieser Ansatz führt zu vielen unnötigen Tabellenrückgaben. Beispielsweise gibt es zwei Datensätze (Zhang San, 10) und (Zhang San, 15). Der Datensatz von (Zhang San, 20) muss abgefragt werden. Suchen Sie bei der Abfrage zunächst alle Primärschlüssel-IDs, die die Bedingungen erfüllen, über Zhang San und durchlaufen Sie dann die Zeilen, die die Bedingungen im Clustered-Index erfüllen, um festzustellen, ob Datensätze vorhanden sind, die mit Alter = 20 übereinstimmen. In tatsächlichen Situationen gibt es keine Datensätze, die die Bedingungen erfüllen, sodass dieser Tabellenrückgabeprozess als vergeblicher Schritt angesehen werden kann.
Die Hauptfunktion des Index-Pushdowns besteht darin, dies zu verbessern. Im gemeinsamen Index werden Datensätze, die nicht an die Tabelle zurückgegeben werden müssen, nach Name und Alter herausgefiltert, und dann wird der Index an die Tabelle zurückgegeben, um die Anzahl zu reduzieren der Tabellenrückgaben.
Ein eindeutiger Index ist ein Index, der nicht den gleichen Indexwert zulässt. Das System prüft beim Erstellen des Index, ob es doppelte Schlüsselwerte gibt. Dies wird jedes Mal überprüft, wenn ein Datensatz aktualisiert oder hinzugefügt wird . Der Primärschlüsselindex ist der eindeutige Index.
| select id from Benutzerinfo, wobei Alter = 10; |
Das obige ist der detaillierte Inhalt vonWas sind Clustered-Indizes, Nicht-Clustered-Indizes, Joint-Indizes und Unique-Indizes in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde MySQL-Datenbank erstellen
MySQL-Datenbank erstellen MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL mysqlPasswort vergessen
mysqlPasswort vergessen
























