


Das Aufkommen von Konversations-KI wie ChatGPT hat die Menschen an solche Dinge gewöhnt: Geben Sie einen Text, einen Code oder ein Bild ein, und der Konversationsroboter gibt Ihnen die gewünschte Antwort. Doch hinter dieser einfachen Interaktionsmethode muss das KI-Modell sehr komplexe Datenverarbeitungen und Berechnungen durchführen, und die Tokenisierung ist weit verbreitet.
Im Bereich der Verarbeitung natürlicher Sprache bezieht sich die Tokenisierung auf die Aufteilung der Texteingabe in kleinere Einheiten, sogenannte „Tokens“. Diese Token können Wörter, Unterwörter oder Zeichen sein, abhängig von der spezifischen Wortsegmentierungsstrategie und den Aufgabenanforderungen. Wenn wir beispielsweise eine Tokenisierung für den Satz „Ich esse gerne Äpfel“ durchführen, erhalten wir eine Folge von Token: [„Ich“, „Gefällt mir“, „Essen“, „Apfel“]. Einige Leute übersetzen Tokenisierung mit „Wortsegmentierung“, aber andere denken, dass diese Übersetzung irreführend ist. Schließlich ist das segmentierte Token möglicherweise nicht das „Wort“, das wir jeden Tag verstehen. Der Zweck der Tokenisierung besteht darin, Eingabedaten in etwas umzuwandeln dass der Computer das Formular verarbeiten und eine strukturierte Darstellung für das anschließende Modelltraining und die Analyse bereitstellen kann. Diese Methode erleichtert die Deep-Learning-Forschung, bringt aber auch viele Probleme mit sich. Andrej Karpathy, der erst vor einiger Zeit OpenAI beigetreten ist, hat auf einige davon hingewiesen.
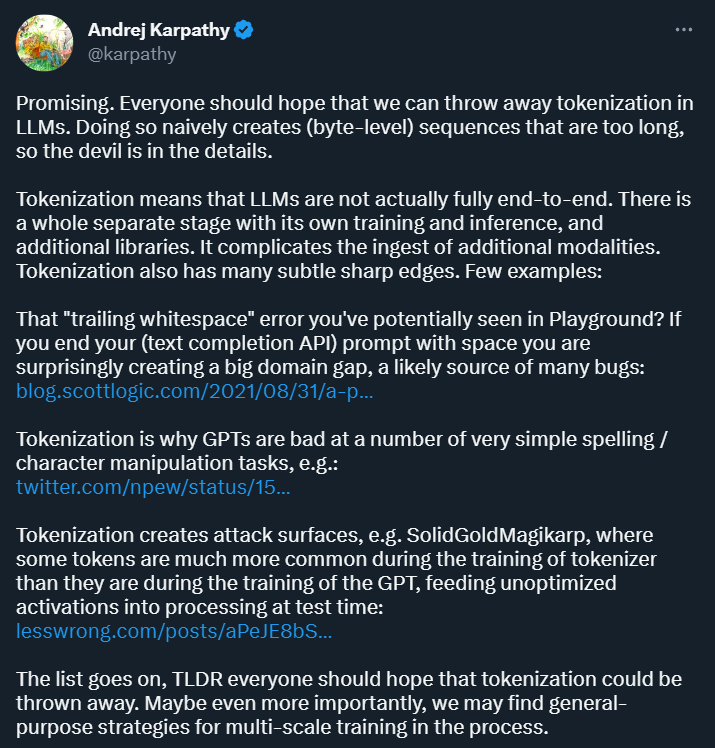
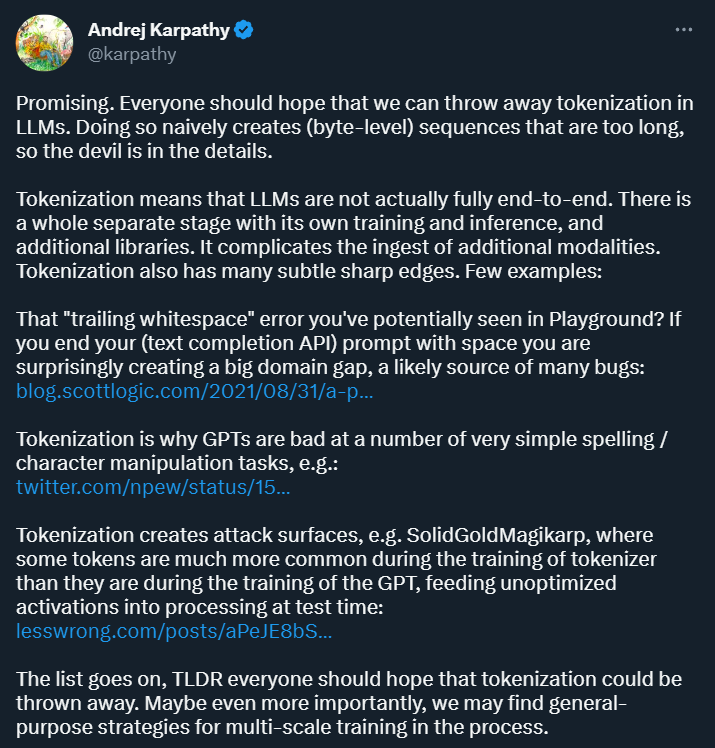
Karpathy glaubt zunächst einmal, dass die Tokenisierung Komplexität mit sich bringt: Durch die Verwendung der Tokenisierung ist das Sprachmodell kein vollständiges End-to-End-Modell. Es erfordert eine separate Stufe für die Tokenisierung, die über einen eigenen Trainings- und Inferenzprozess verfügt und zusätzliche Bibliotheken erfordert. Dies erhöht die Komplexität der Eingabe von Daten aus anderen Modalitäten. 
Darüber hinaus macht die Tokenisierung das Modell in einigen Szenarien auch fehleranfällig. Wenn Ihre Eingabeaufforderung beispielsweise mit einem Leerzeichen endet, sind die Ergebnisse möglicherweise sehr hoch anders. . Wieder einmal Aufgrund der Tokenisierung schreibt das leistungsstarke ChatGPT beispielsweise keine Wörter rückwärts (die folgenden Testergebnisse stammen von GPT 3.5).
Es kann sein, dass es noch viele weitere solcher Beispiele gibt. Karpathy glaubt, dass wir zur Lösung dieser Probleme zunächst die Tokenisierung aufgeben müssen.
 Ein neuer von Meta AI veröffentlichter Artikel geht dieser Frage nach. Konkret schlugen sie eine Multi-Scale-Decoder-Architektur namens „MEGABYTE“ vor, die eine durchgängig differenzierbare Modellierung von Sequenzen mit mehr als einer Million Bytes durchführen kann.
Ein neuer von Meta AI veröffentlichter Artikel geht dieser Frage nach. Konkret schlugen sie eine Multi-Scale-Decoder-Architektur namens „MEGABYTE“ vor, die eine durchgängig differenzierbare Modellierung von Sequenzen mit mehr als einer Million Bytes durchführen kann.

Wichtig ist, dass dieses Papier die Machbarkeit eines Verzichts auf die Tokenisierung zeigt und von Karpathy als „vielversprechend“ bewertet wurde ".
Im Folgenden finden Sie die Details des Papiers.
Papierübersicht
Wie im Artikel über maschinelles Lernen erwähnt, liegt der Grund, warum maschinelles Lernen in der Lage zu sein scheint, viele komplexe Probleme zu lösen, darin, dass es diese Probleme in mathematische Probleme umwandelt.
Alle Texte sind „unstrukturierte Daten“. Dann können wir die strukturierten Daten in mathematische Probleme umwandeln der erste Schritt der Transformation.
Aufgrund der hohen Kosten sowohl für Selbstaufmerksamkeitsmechanismen als auch für große Feed-Forward-Netzwerke verwenden große Transformer-Decoder (LLM) normalerweise nur Tausende von Kontext-Tokens. Dies schränkt den Umfang der Aufgaben, auf die LLM angewendet werden kann, erheblich ein.
Auf dieser Grundlage schlugen Forscher von Meta AI eine neue Methode zur Modellierung langer Bytesequenzen vor – MEGABYTE. Diese Methode unterteilt die Bytesequenz in Patches fester Größe, ähnlich wie beim Token.
Megabyte Modell besteht aus drei Teilen:
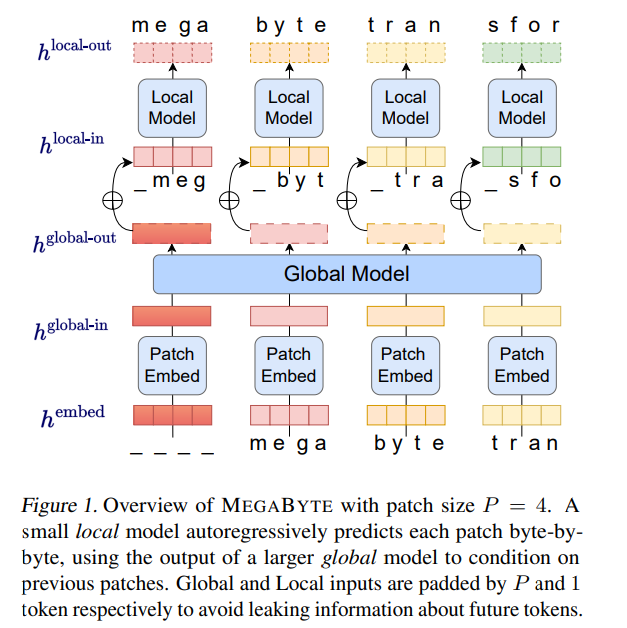 Feedforward-Schicht pro Patch
Feedforward-Schicht pro Patch
3.
Parallele Dekodierung. Der Transformator muss während der Generierung alle Berechnungen seriell durchführen, da die Eingabe jedes Zeitschritts die Ausgabe des vorherigen Zeitschritts ist. Durch die parallele Generierung von Patch-Repräsentationen erreicht MEGABYTE eine größere Parallelität im Generierungsprozess. Beispielsweise generiert ein MEGABYTE-Modell mit 1,5 Milliarden Parametern Sequenzen 40 % schneller als ein standardmäßiger 350-M-Parametertransformator und verbessert gleichzeitig die Verwirrung, wenn es mit derselben Berechnung trainiert wird. Insgesamt ermöglicht uns MEGABYTE, größere, leistungsstärkere Modelle mit demselben Rechenbudget zu trainieren, sehr lange Sequenzen zu bewältigen und die Generierungsgeschwindigkeit während der Bereitstellung zu erhöhen. MEGABYTE steht auch im Gegensatz zu bestehenden autoregressiven Modellen, die typischerweise eine Form der Tokenisierung verwenden, bei der Bytesequenzen in größere diskrete Token abgebildet werden (Sennrich et al., 2015; Ramesh et al., 2021; Hsu et al., 2021). Die Tokenisierung erschwert die Vorverarbeitung, die multimodale Modellierung und die Übertragung auf neue Domänen, während nützliche Strukturen im Modell verborgen bleiben. Das bedeutet, dass die meisten SOTA-Modelle keine echten End-to-End-Modelle sind. Die am weitesten verbreiteten Tokenisierungsmethoden erfordern den Einsatz sprachspezifischer Heuristiken (Radford et al., 2019) oder den Verlust von Informationen (Ramesh et al., 2021). Daher wird der Ersatz der Tokenisierung durch ein effizientes und leistungsstarkes Byte-Modell viele Vorteile haben. Die Studie führte Experimente mit MEGABYTE und einigen leistungsstarken Basismodellen durch. Experimentelle Ergebnisse zeigen, dass MEGABYTE bei der Langkontext-Sprachmodellierung eine mit Subwortmodellen vergleichbare Leistung erbringt, auf ImageNet eine hochmoderne Dichteschätzungs-Perplexität erreicht und Audiomodellierung aus rohen Audiodateien ermöglicht. Diese experimentellen Ergebnisse zeigen die Machbarkeit einer tokenisierungsfreien autoregressiven Sequenzmodellierung in großem Maßstab. #? Einbetter Der Patch-Embedder der Größe P kann Byte-Sequenz 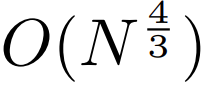

.
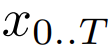 Zuerst wird jedes Byte mit einer Nachschlagetabelle eingebettet
Zuerst wird jedes Byte mit einer Nachschlagetabelle eingebettet
#🎜 🎜#
, Bilden einer Einbettung der Größe D_G mit hinzugefügter Positionseinbettung. 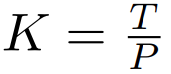
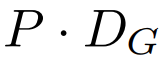
Dann erfolgt die Byte-Einbettung Formen Sie es in eine Folge von K-Patch-Einbettungen mit den Abmessungen
um. Um eine autoregressive Modellierung zu ermöglichen, wird die Patch-Sequenz mit Fülleinbettungen aus der trainierbaren Patch-Größe (#) aufgefüllt und dann der letzte Patch aus der Eingabe entfernt. Diese Sequenz ist die Eingabe für das globale Modell, dargestellt als
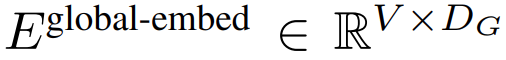
#🎜 🎜#
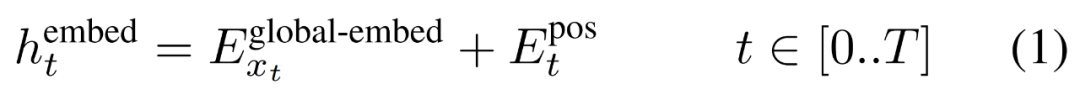
Das globale Modul ist ein P・D_G-dimensionales Transformatormodell mit reiner Decoder-Architektur, das mit k Patch-Sequenzen arbeitet. Das globale Modul kombiniert Selbstaufmerksamkeitsmechanismus und Kausalmaske, um die Abhängigkeiten zwischen Patches zu erfassen. Das globale Modul gibt die Darstellungen von k Patch-Sequenzen
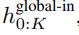
ein und gibt eine aktualisierte Darstellung
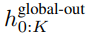
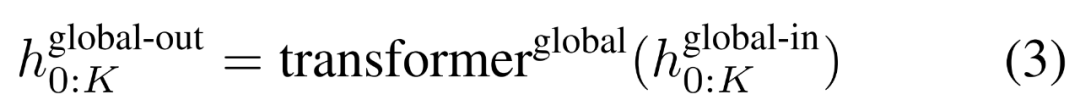
durch Selbstaufmerksamkeit auf die vorherigen Patches aus. Die Ausgabe des Das letzte globale Modul
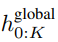
enthält K-Patch-Darstellungen von P・D_G-Dimensionen. Für jede davon haben wir sie in eine Folge der Länge P und der Dimension D_G umgeformt, wobei die Position p die Dimension p·D_G zu (p + 1)·D_G verwendet. Jede Position wird dann der lokalen Moduldimension mit der Matrix
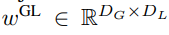
zugeordnet, wobei D_L die lokale Moduldimension ist. Diese werden dann mit einer Byte-Einbettung der Größe D_L für den nächsten
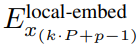
Token kombiniert.
Die lokale Byte-Einbettung wird über eine trainierbare lokale Pad-Einbettung (E^local-pad ∈ R^DL) um 1 versetzt, was eine autoregressive Modellierung im Pfad ermöglicht. Der letzte Tensor
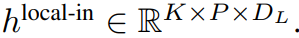
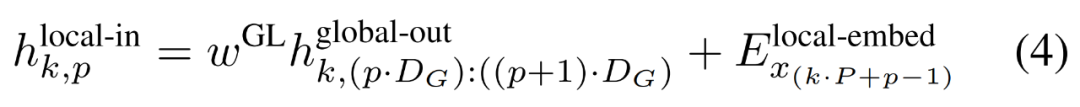
Das lokale Modul
ist ein kleineres D_L-dimensionales Transformatormodell nur mit Decoder-Architektur Führen Sie einen einzelnen Patch k aus von P Elementen, wobei jedes Element die Summe einer globalen Modulausgabe und der Einbettung des vorherigen Bytes in der Sequenz ist. K Kopien des lokalen Moduls werden unabhängig auf jedem Patch ausgeführt und während des Trainings parallel ausgeführt, um die Darstellung zu berechnen. Das p-te Element des k-ten Patches entspricht dem Element t der vollständigen Sequenz, wobei t = k·P + p.
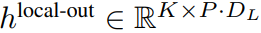
Effizienzanalyse
Trainingseffizienz
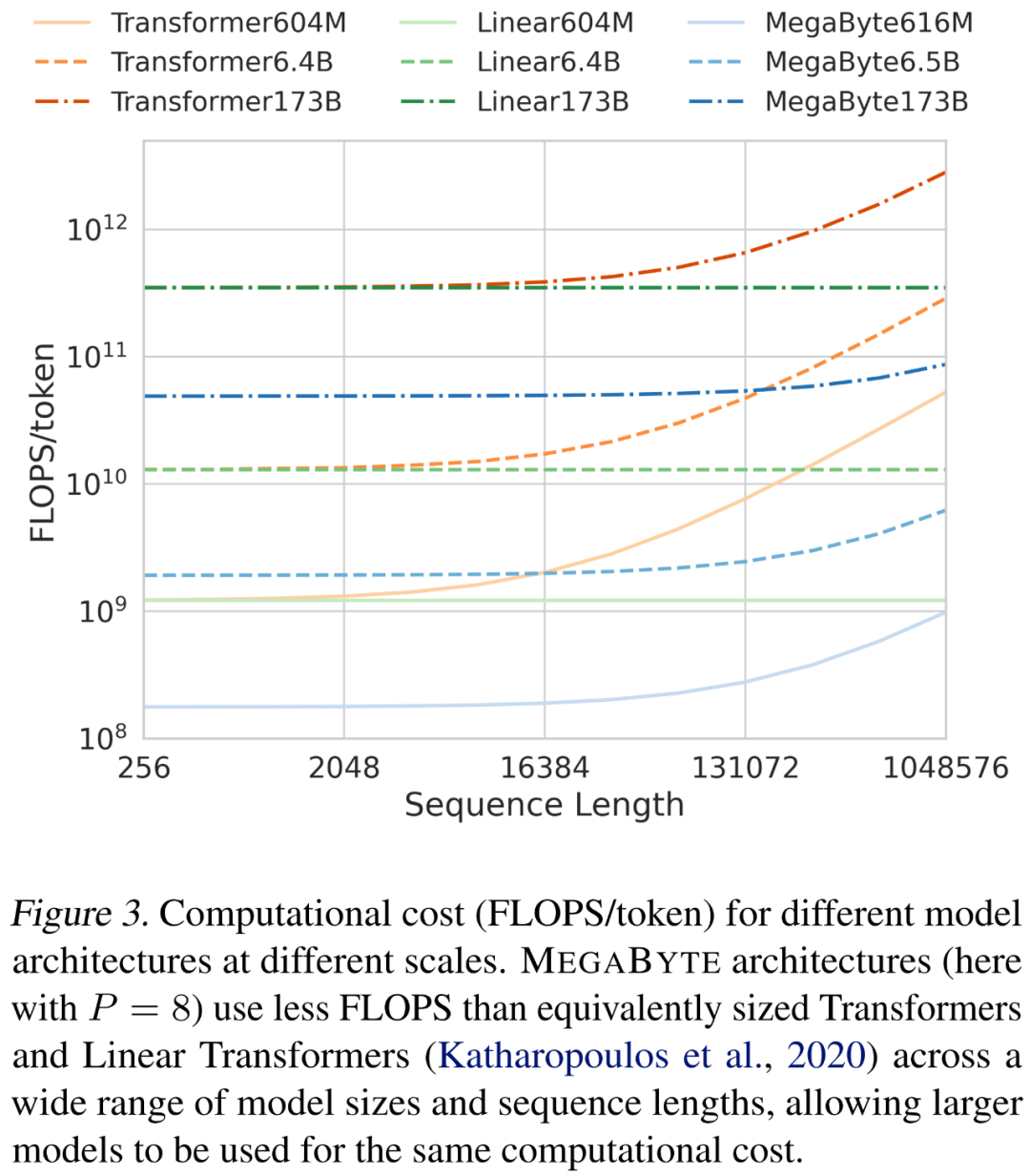
Die Forscher analysierten die Kosten verschiedener Architekturen bei der Skalierung von Sequenzlänge und Modellgröße. Wie in Abbildung 3 unten dargestellt, verwendet die MEGABYTE-Architektur über eine Vielzahl von Modellgrößen und Sequenzlängen hinweg weniger FLOPS als Transformatoren vergleichbarer Größe und lineare Transformatoren, was die Verwendung größerer Modelle bei gleichen Rechenkosten ermöglicht.
Generation. Effizienz#🎜🎜 #
Stellen Sie sich ein solches MEGABYTE-Modell vor, das eine L_global-Schicht im globalen Modell, eine L_local-Schicht im lokalen Modul, eine Patchgröße von P und eine Transformatorarchitektur mit L_local + L_global hat Ebenen Machen Sie einen Vergleich. Das Generieren jedes Patches mit MEGABYTE erfordert eine O-Sequenz (L_global + P・L_local) serieller Operationen. Wenn L_global ≥ L_local (das globale Modul hat mehr Schichten als das lokale Modul), kann MEGABYTE die Inferenzkosten um fast das P-fache reduzieren.
Experimentelle ErgebnisseSprachmodellierung
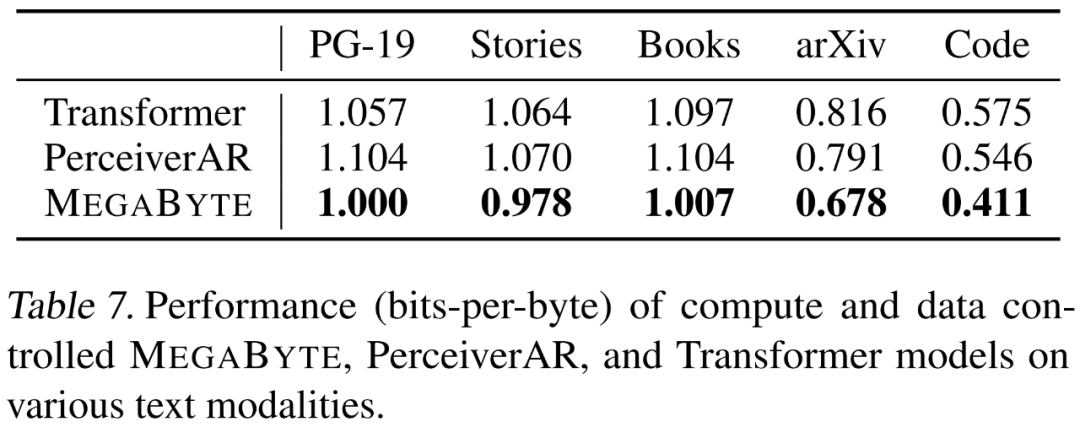
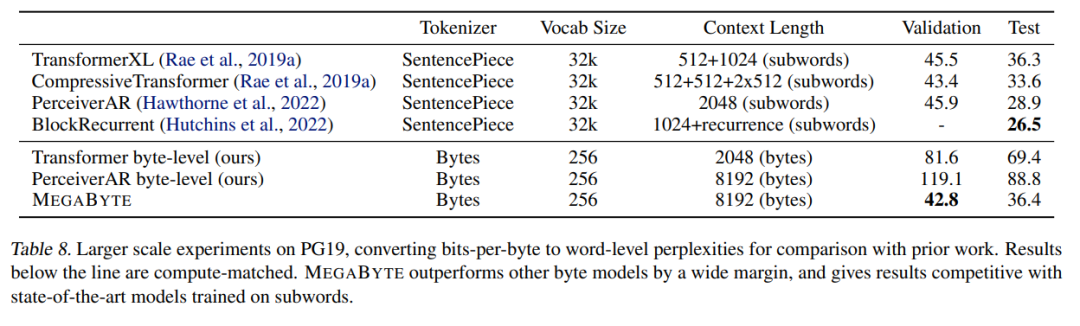
# 🎜 🎜#Die Forscher bewerteten die Sprachmodellierungsfunktionen von MEGABYTE anhand von fünf verschiedenen Datensätzen, die langfristige Abhängigkeiten betonen, nämlich Project Gutenberg (PG-19), Books, Stories, arXiv und Code. Die Ergebnisse sind in Tabelle 7 unten dargestellt. MEGABYTE übertrifft den Basistransformator und PerceiverAR bei allen Datensätzen durchweg. Die Forscher erweiterten auch die Trainingsdaten zu PG-19. Die Ergebnisse sind in Tabelle 8 unten aufgeführt. MEGABYTE übertrifft andere Byte-Modelle deutlich und ist mit dem auf Unterwörtern trainierten SOTA-Modell vergleichbar. #? #Der Forscher trainierte ein großes MEGABYTE-Modell auf dem ImageNet 64x64-Datensatz, in dem die Parameter der globalen und lokalen Module 2,7 B bzw. 350 MB betragen und es 1,4 T-Token gibt. Sie schätzen, dass das Training des Modells weniger als die Hälfte der GPU-Stunden dauert, die erforderlich sind, um das beste PerceiverAR-Modell im Artikel von Hawthorne et al., 2022, zu reproduzieren. Wie in Tabelle 8 oben gezeigt, weist MEGABYTE eine vergleichbare Leistung wie SOTA von PerceiverAR auf, nutzt jedoch nur die Hälfte der Berechnungen des letzteren.
 Die Forscher verglichen drei Transformer-Varianten, nämlich Vanilla, PerceiverAR und MEGABYTE, um die Skalierbarkeit langer Sequenzen bei immer größeren Bildauflösungen zu testen. Die Ergebnisse sind in Tabelle 5 unten aufgeführt. Unter dieser rechnerischen Steuerungseinstellung übertrifft MEGABYTE das Basismodell bei allen Auflösungen. Die genauen Einstellungen, die von jedem Basismodell verwendet werden, sind in Tabelle 14 unten zusammengefasst, einschließlich Kontextlänge und latenter Anzahl.
Die Forscher verglichen drei Transformer-Varianten, nämlich Vanilla, PerceiverAR und MEGABYTE, um die Skalierbarkeit langer Sequenzen bei immer größeren Bildauflösungen zu testen. Die Ergebnisse sind in Tabelle 5 unten aufgeführt. Unter dieser rechnerischen Steuerungseinstellung übertrifft MEGABYTE das Basismodell bei allen Auflösungen. Die genauen Einstellungen, die von jedem Basismodell verwendet werden, sind in Tabelle 14 unten zusammengefasst, einschließlich Kontextlänge und latenter Anzahl.
Audio hat sowohl die Sequenzstruktur von Text als auch die kontinuierlichen Eigenschaften von Bildern, was eine interessante Anwendung für MEGABYTE darstellt. Das Modell in diesem Artikel erreichte einen bpb von 3,477, was deutlich niedriger ist als das PercepterAR-Modell (3,543) und das Vanilla-Transformer-Modell (3,567). Weitere Ablationsergebnisse sind in Tabelle 10 unten aufgeführt.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier .
Das obige ist der detaillierte Inhalt vonIst es notwendig, „Partizip' zu bilden? Andrej Karpathy: Es ist Zeit, diesen historischen Ballast wegzuwerfen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



